绑定手机号
确认绑定









为了交付和部署基于Chiplet的百亿亿次超级计算机,来自不同国家的公司正积极抢先布局,展开激烈的正面交锋。与当今现存的超级计算机相比,此新型计算系统速度提高了1,000倍。
在设计最新百亿亿次超级计算机的CPU和GPU时,在先进封装中混合和匹配了复杂的芯片,为超级计算机进一步提升了灵活性和专用性。由于其优势远远超出了超级计算机本身,多年来,各个国家一直在争夺这一领域的领导地位。这些庞大而昂贵的系统为人工智能、生物学、国防、能源和科学领域的巨大突破铺平了道路。
当前的超级计算机,以及全新百亿亿次系统,都是基于传统计算原理,这与量子计算机完全不同。在传统计算中,数据信息以位(bit)为基本存储单元,每个0或1就是一个位。在量子计算中,信息存储在量子位中,可以是0、1或两者兼有。叠加态使量子计算机能够胜过传统系统,但量子系统距离实际应用还有几年的时间。
最先进的传统超级计算机每秒可以执行超过1015次浮点运算(petaFLOPS或Pflop/s)。如今,由Riken和Fujitsu构建的超级计算机Fugaku是世界上最快的系统,其高性能Linpack(HPL)基准测试得分为442 Pflop/s。HPL分数反映了系统在求解某些线性方程时的性能,并不反映系统的整体性能。
速度高达百亿亿次级
与此同时,来自中国、欧洲、日本和美国的几个实体一直在开发百亿亿次级超级计算机,每秒执行1018次计算或更多(exaFLOPS或Eflop/s)。
最近,中国的两台超级计算机声称已经突破了Eflop/s障碍,尽管这些结果仍未得到证实。今年晚些时候,预计美国将部署其第一台百亿亿级超级计算机,该计算机是一个1.5Eflop/s或更快的系统,称为Frontier。Frontier基于AMD服务器处理器和GPU加速器,位于Oak Ridge国家实验室。
美国还在开发另外两台百亿亿级超级计算机,包括正在阿贡国家实验室建造的Aurora。Aurora是围绕英特尔的服务器处理器和GPU构建的。
从架构的角度来看,所有超级计算机都是相似的。这些系统由大量机架组成,每个机架都包含许多计算节点。每个计算节点都有多个CPU和GPU。传统上,大部分这些芯片都是大型且复杂的片上系统(SoC),所有功能都集成在一个单片芯片上。
但这种方案逐渐发生了变化。一些(但不是全部)百亿亿级超级计算机正在使用Chiplet解决方案,尤其是美国的系统。这些系统中的CPU和GPU不是SoC,而是包含更小的芯片或单元,然后将其制造并重新集成到先进封装中。简而言之,与大型SoC相比,制造具有更高良率的小型芯片相对容易。
在一个封装中集成多个芯片的想法并不新鲜,尤其是在高性能计算(HPC)中。“将多个芯片放在一个封装中的想法已经存在了很长时间。IBM在1980年代初期使用多芯片载体来构建其大型主机,”Hyperion Research研究高级副总裁Bob Sorensen表示。“所以从理论上讲,Chiplet只是单个封装中多个芯片的最新化身。但是Chiplet可以让HPC设计人员构建最适合HPC预期的工作负载,且具有精确计算、内存和I/O功能的处理器。”
在此领域市场中,中国正在部署百亿亿级超级计算机;美国也正在准备其首个百亿亿次系统;AMD和英特尔披露了有关其在百亿亿次计算时代的芯片的详细信息。此外,该行业还发布了一项新标准UCIe,用于封装中Chiplet的高速互连。

图1:Frontier超级计算机计划在今年晚些时候部署,目标性能达1.5Eflops/s(图源:Oak Ridge National Laboratory)
超级计算机之战
据Hyperion Research数据显示,整体而言,超级计算机市场预计将从2021年的66亿美元增长到2022年的78亿美元。该机构将超级计算机市场分为三个部分,即领导级/百亿亿级、大型(每个300万美元及以上)和入门级(50万至300万美元)。每个百亿亿次系统的售价约为6亿美元。
多年来,超级计算机已被广泛应用于诸多市场领域。“很多工作都需要超级计算,包括天气预报等海量模拟任务、加密货币挖掘等海量算术计算任务、卫星图像处理等海量图像处理任务,以及用于深度学习训练的海量神经网络计算,”D2S的Aki Fujimura表示。“该技术广泛用于半导体制造领域,用来解决逆光刻技术、掩模工艺校正、掩模和晶圆基于模拟的验证以及掩模和晶圆检测等问题。”
从发展历程来看,计算领域已经取得了巨大的进步。1945年,宾夕法尼亚大学研制出第一台通用电子数字计算机ENIAC。ENIAC使用真空管处理数据,每秒执行5,000次加法。
从1950年代开始,在许多系统中,晶体管已经取代了真空管,从而实现了更快的计算机。晶体管是芯片中的关键组成部分,作为器件中的开关。
1964年,现已停产的Control Data推出了世界上第一台超级计算机CDC 6600。6600采用60位处理器,使用性能为2MIPS的晶体管。从那时起,超级计算机变得更加强大。与此同时,各个国家继续在性能领先地位上相互超越。
例如,2008年,IBM的Roadrunner以1.026 Pflop/s的性能成为世界上最快的超级计算机。它成为第一台达到这一里程碑的超级计算机。然后,在2010年,中国凭借性能水平为2.57Pflop/s的超级计算机天河一号跃居领先地位。
自2020年以来,日本富岳一直保持着超级计算第一的位置。IBM的Summit排名第二,是美国最快的超级计算机
Fugaku系统由158,976个计算节点组成,共有7,630,848个Arm处理器内核。“每个节点都配备了一个名为A64FX的处理器,它由48个通用处理器核心和四个辅助核心组成。A64FX采用7nm工艺制造,”富士通/Riken的研究员ShujiYamamura在最近的ISSCC活动上的一篇论文中表示。
Fugaku使用定制的ARM处理器,而不是Chiplet架构。相比之下,中国的超级计算机倾向于使用定制处理器。许多非百亿亿级超级计算机使用商用芯片。
“对于更主流的HPC领域,硬件决策主要基于更主流的大规模组件可用性,”Hyperion的Sorensen认为。“这些可能包括英特尔CPU、英伟达GPU和InfiniBand互连。它们可能被配置为最适合HPC工作负载环境,或者可能具有一些激进的封装和冷却功能来处理电源问题。”
CPU和GPU在HPC中都发挥着关键作用。“对于顺序数据处理类型的编程,CPU往往比GPU更具成本效益。但是对于为任何给定数据单元进行大量计算的任务,GPU可以更高效,特别是如果计算任务可以转换为单指令多数据(SIMD)问题。这是并行处理大部分数据并在不同数据上以相同指令执行的地方,”D2S的Fujimura表示。
迈入百亿亿次时代
展望未来,超级计算正在进入百亿亿次时代,有望给生物学、国防、科学等领域带来新的突破。
百亿亿次系统的开发成本很高。“对于百亿亿次计算系统,超过5亿美元的HPC可能会将其总预算20%以上专门用于开发定制芯片、互连和其他组件等特殊功能,以满足某些目标工作负载要求。”Hyperion的Sorensen指出。
一些公司正在开发百亿亿级超级计算机。中国似乎以微弱优势领先,美国紧随其后,欧洲则略微落后。今年早些时候,欧洲高性能计算联合企业(Euro HPC)启动了几个新项目,包括一个百亿亿级项目计划。目前尚不清楚欧盟何时会启动该系统。
据Hyperion Research称,中国正在开发三台百亿亿级超级计算机,分别是神威太湖之光、天河三号和曙光。神威太湖之光安装在无锡国家超级计算机中心,于2021年完工。去年,研究人员声称其峰值性能达到了1.3 Eflop/s。该系统基于内部设计的SW39010 CPU。据Hyperion称,该系统总共由超过3,800万个CPU内核组成。
去年年底完成的天河三号已经展示了1.7 Eflop/s的性能。与此同时,曙光系统则被推迟了。
虽然中国倾向于使用传统的定制处理器,但美国的百亿亿次系统正在采取另一种方法。CPU和GPU正在利用Chiplet方案,在其中混合和匹配芯片并将其集成至封装中。
迄今为止,AMD、英特尔、Marvell等已经开发了基于Chiplet的设计,主要用于服务器和其他高端应用。这个概念也是超级计算的理想选择。
“小芯片将在多个受益于其特性的应用中实施,包括显着减小尺寸、降低功耗和更好的高速性能。”QP Technologies的母公司Promex总裁兼首席执行官Richard Otte表示。“例如,DoD和DARPA正在努力将最快的超级计算机带入其实验室,而Chiplet将有助于实现这一目标。”
现阶段,美国正在开发三个百亿亿次系统:Aurora、El Capitan和Frontier。Frontier预计将于2022年底投入运营,随后Aurora和El Capitan将于2023年投入运营。
2019年,美国能源部(DOE)授予Cray在Oak Ridge国家实验室建造Frontier百亿亿次超级计算机的合同。2019年,Cray被惠普企业(HPE)收购。
HPE为Frontier构建了平台,该平台支持大量计算节点。每个计算节点都支持AMD的一个服务器CPU和四个AMDGPU加速器。
AMD的新型GPU加速器基于台积电的6nm工艺,包含两个芯片,总共由580亿个晶体管组成。该架构的峰值性能超过了380 teraflops。
GPU架构被整合在一个2.5D封装中。在大多数2.5D/3D封装中,芯片堆叠或并排放置在中介层顶部,中介层包含硅通孔(TSV)。TSV提供从芯片到电路板的电气连接。
“TSV是3D-IC的使能技术,提供堆叠芯片之间的电气连接。采用TSV的3D-IC技术,其主要优势在于,为不同组件之间提供了更短的互连,从而降低了阻容延迟和更小的器件占用空间,”UMC研究员LukeHu在最近的一篇论文中表示。
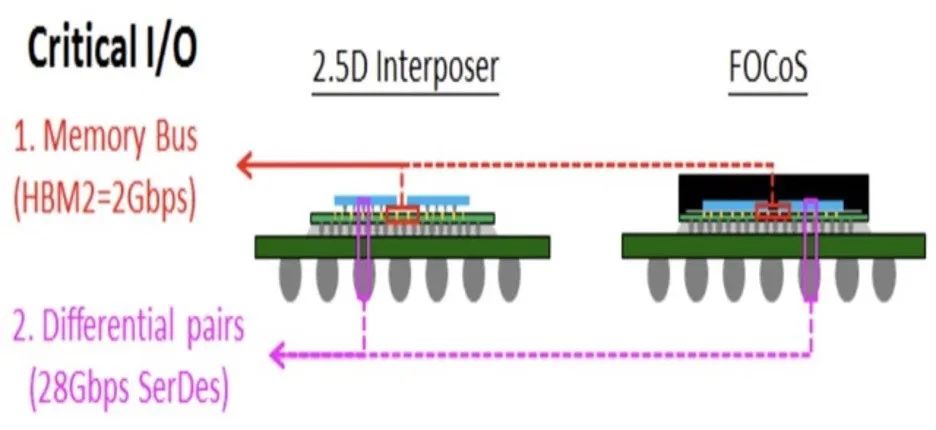
图2:高性能计算封装的不同选择,基于中介层的2.5D与基板上扇出芯片(FOCoS)(图源:ASE)
在2.5D/3D封装中,虽然中介层有效,但结构上会浪费空间。因此,几家公司开发了一种称为硅桥的替代方法。桥接器是带有路由层的一小块硅片,它将一个芯片连接到封装中的另一个芯片。在一个示例中,英特尔开发了嵌入式多芯片互连桥(EMIB),这是一种通常嵌入在基板中的硅桥。
同时,在AMD的GPU中,该公司将GPU和高带宽内存(HBM)并排堆叠在硅桥上。HBM基本上是一个DRAM内存堆栈。
与嵌入基板中的EMIB不同,AMD将桥接器置于基板之上。AMD将此称为2.5D高架扇出桥(EFB)。

图3:基于基板的桥与AMD的2.5D高架扇出桥(EFB)(图源:AMD)
其他百亿亿级超级计算机也正在开发中。不久前,Lawrence Livermore国家实验室、HPE和AMD发布了El Capitan,这是一个预计将超过2 Eflop/s的百亿亿次计算系统。该系统采用了AMD基于Chiplet方案的CPU和GPU。
与此同时,2019年,美国能源部、英特尔和HPE宣布计划构建一个大于2 Eflop/s的系统Aurora。最初,Aurora预计将于2021年交付给Argonne,但由于英特尔的芯片延迟,该计划被推迟。
Aurora基于HPE的超级计算机平台,拥有9,000多个计算节点。每个节点由两个英特尔Sapphire Rapids处理器、六个英特尔GPU加速器(代号为Ponte Vecchio)和一个统一的内存架构组成。它由10 PB的内存和230 PB的存储空间组成。
Sapphire Rapids是下一代Xeon处理器,它在一个封装中集成了4个较小的CPU芯片。基于英特尔的7nm finFET工艺,芯片使用EMIB连接。
该处理器由超过100MB的共享三级缓存、8个DDR5通道和32 GT/s PCIe/CXL通道组成。“新技术包括英特尔高级矩阵扩展(AMX),一种用于加速AI工作负载的矩阵乘法功能,以及用于解决新兴工作负载的新虚拟化技术,”英特尔首席工程师Nevine Nassif在最近的ISSCC上的一次演讲中表示。
在Aurora中,CPU与Ponte Vecchio配合使用,这是一种基于英特尔Xe-HPC微架构的GPU。这种复杂设备在一个封装的五个工艺节点上包含47个单元。该设备总共由超过1,000亿个晶体管组成。
基本上,Ponte Vecchio将两个基础芯片堆叠在一个基板上。在每个基础芯片上,英特尔堆叠了一个内存结构,然后是计算和SRAM单元。该设备还具有8个HBM2E块。为了使芯片能够相互通信,英特尔使用了专有的die-to-die互连。
基于Intel的7nm工艺,两个基础芯片为GPU提供了通信网络。这些芯片包括内存控制器、稳压器、电源管理和16个PCIe Gen5/CXL主机接口通道。
在每个基础芯片上,英特尔堆叠8个计算单元和4个SRAM单元。计算单元基于台积电的5nm工艺,而SRAM则围绕英特尔的7nm技术构建。
该器件总共包含16个计算单元和8个SRAM单元。每个计算单元有8个内核。“每个内核包含8个向量引擎,处理512位浮点/整数操作数,以及8个矩阵引擎,其中包含执行4096位向量运算的深度为8的脉冲阵列,”英特尔研究员Wilfred Gomes在ISSCC的论文中表示。
对于供电,英特尔在基础芯片上实施了所谓的完全集成稳压器(FIVR)。“基础芯片上的FIVR在0.7V电源中为每个基础芯片提供高达300W的功率,”Gomes称。“3D堆叠FIVR可实现对多个电压域的高带宽细粒度控制并降低输入电流。”
热管理对先进封装提出了重大挑战。为了解决这个问题,英特尔在GPU上放置了一个散热器。然后,将热界面材料(TIM)应用到顶部管芯上。
“TIM消除了由不同芯片堆叠高度引起的气隙,以降低热阻。除了47个功能单元外,还有16个额外的热屏蔽芯片堆叠,以在裸露的基础芯片区域提供散热解决方案以传导热量,”Gomes指出。
如何开发Chiplet
超级计算只是Chiplet的众多应用之一。最近,一些供应商已经为服务器开发了类似Chiplet的设计。未来的Chiplet架构正在开发中。
开发类似Chiplet的设计很有吸引力,但也存在一些挑战。开发Chiplet需要资源和几个要素。
如前所述,在Chiplet中,无需设计大型SoC,而是从头开始使用较小的芯片设计芯片。然后制造芯片并将其重新组装成一个封装。
“从某种意义上说,这种先进封装或先进产品需要高密度互连,”JCET首席技术官Choon Lee说。“因此,在这种情况下,封装本身不再只是将单个封装中的单个芯片。在更先进的封装中,必须考虑布局、芯片和封装的交互以及如何对这些层进行布线。问题是如何真正优化布局以在封装中获得最佳性能或最大性能。”
这不是唯一的问题。在封装中,芯片被堆叠在一起。因此需要通过die-to-die互连将一个芯片连接到另一个芯片。
如今的Chiplet设计使用专有总线和接口连接芯片,这限制了该技术的采用。一些组织始终在研究开放总线和接口标准。
在最新的努力中,ASE、AMD、Arm、谷歌、英特尔、Meta、微软、高通、三星和台积电最近成立了一个联盟,正在建立一个支持Chiplet的芯片到芯片互连标准。该组织还批准了UCIe规范,这是一种封装级别的开放式行业互连标准。UCIe 1.0规范涵盖die-to-die I/O物理层、die-to-die协议和软件堆栈。
“Chiplet时代已经真正到来,推动行业从以硅为中心的思维发展到系统级规划,并将重点放在IC和封装的协同设计上,” ASE的营销工程技术总监Lihong Cao表示。“我们相信,UCIe将通过多供应商生态系统中各种IP之间接口的开放标准以及先进封装级互连的利用来降低开发时间和成本,从而在提高生态系统效率方面发挥关键作用。”
这并不能解决所有问题。在所有封装中,热预算都是一个大问题。“功耗和电源使用是巨大的挑战,”在Amkor高级封装开发和集成副总裁Michael Kelly看来,“由于封装级别的集成,它在封装行业受到欢迎。不幸的是,硅会产生大量废热。它的热效率不高,需要进行散热。对于在最终产品中进行散热,无论是在手机壳中还是在数据中心的水冷却器中,我们都必须使其尽可能具有热效率。还需要注意应该为高性能封装提供多少实际电流。功率没有下降,但电压正在下降。为了提供相同的总功率或更多功率,我们的电流正在上升。需要解决诸如电迁移之类的问题。可能需要在封装中进行更多的电压转换和电压调节。这样,我们可以将更高的电压带入封装,然后将它们分成更低的电压。这意味着我们不必将尽可能多的总电流拖入封装。因此,功率以两种方式受到关注,散发热量,但也在管理电力输送网络。这迫使更多的芯片集成至封装内,同时也不断优化热功耗方面的问题。”
结论
显然,Chiplet构成了一种使能技术,并逐渐进入服务器设计。最近,Apple推出了全新Mac台式机,搭载以Chiplet为基础设计的处理器。现在,基于Chiplet的百亿亿级超级计算机已经出现。
对于百亿亿级超级计算机,Frontier、El Capitan和Aurora系统已经开始采用基于Chiplet的解决方案。Fugaku和神威太湖之光等其他产品继续沿用传统的基于SoC的方法。两种方法均行之有效,激烈的市场竞争也正式开始。








