绑定手机号
确认绑定










基于PETR,PETRv2探索了时域建模的有效性,其利用前一帧的时间信息来增强3D目标检测。更具体地说,将PETR中的3D位置嵌入(3D PE)扩展为时域建模。3D PE实现了不同帧目标位置的时间对齐。
为了提高3D PE的数据适应性,进一步引入特征引导的位置编码器。为了支持高质量的BEV分割,PETRv2添加一组分割query,提供了一个简单而有效的解决方案。每个分割query负责分割BEV地图的一个特定patch。
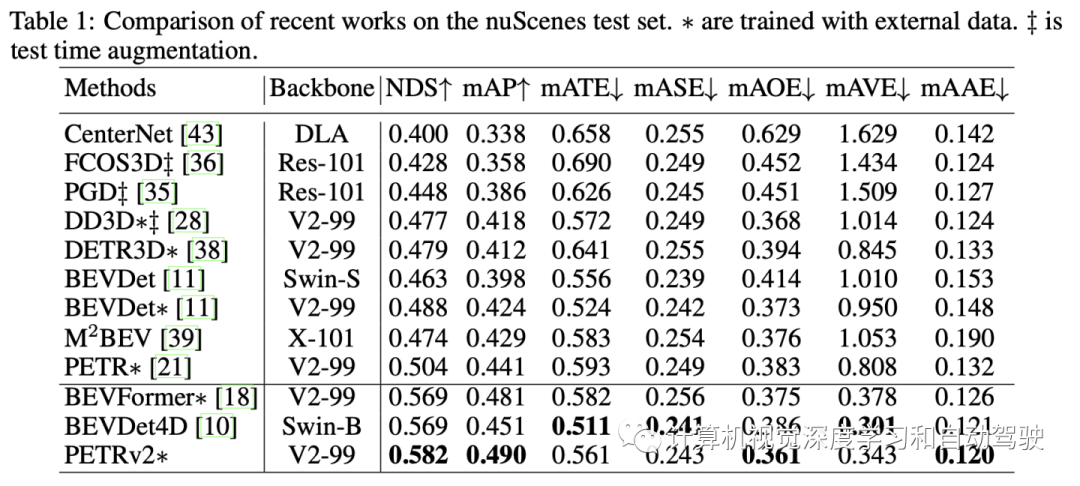
PETRv2在3D目标检测和BEV分割方面实现了最先进的性能。代码位于https://github.com/megvii-research/PETR。
近年来,基于多摄像机图像的自动驾驶系统3D感知技术受到了广泛的关注。多摄像机3D目标检测方法可分为基于BEV的方法和基于DETR的方法。基于BEV的方法(例如,BEVDet)通过LSS将多视图特征显式转换为鸟瞰图(BEV)表示。与这些基于BEV的算法不同,基于DETR的方法将每个3D目标建模为目标query,并使用匈牙利算法实现端到端建模。
PETR(“Petr: Position embedding transformation for multi-view 3d object detection“. arXiv 2203.05625, 2022)是DETR的一种,其工作是多视图3D目标检测的位置嵌入变换(PETR)。PETR将3D坐标的位置信息编码为图像特征,生成3D位置-觉察的特征。目标query可以感知3D位置-觉察特征并执行端到端的目标检测。
如图是PETR的架构图:将多视图图像输入主干网络(如ResNet),提取多视图2D图像特征。在3D坐标生成器中,所有视图共享的摄像头截锥(frustum)空间被离散为3D网格。采用不同的摄像头参数网格坐标被变换到3D世界空间坐标。然后将2D图像特征和3D坐标注入到3D位置编码器中,生成3D位置-觉察特征。query生成器生成的目标query通过与transformer解码器中的3D位置-觉察特征交互进行更新。更新后的query进一步用于预测3D边框和目标类。

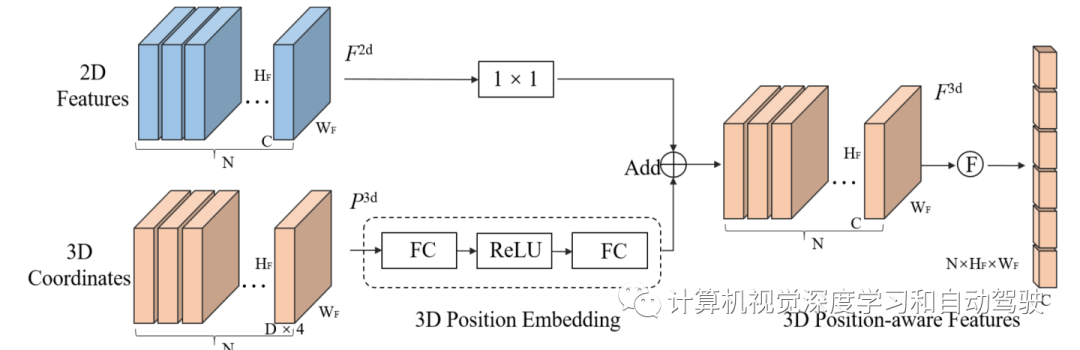
这个3D位置编码器架构如图:将多视图2D图像特征输入到1×1卷积层进行降维。通过多层感知将3D坐标生成器生成的3D坐标转换为3D位置嵌入。3D位置嵌入的形状与2D图像特征相同。3D位置嵌入与同一视图的2D图像特征加一起,生成3D位置-觉察特征。最后,将3D位置-觉察特征扁平化,用作transformer解码器的输入。
对于时域建模,主要问题是如何在3D空间中对齐不同帧的目标位置。BEVDet4D通过姿态变换将前一帧的BEV特征与当前帧明确对齐。然而,PETR将3D位置隐式编码为2D图像特征,并且无法执行显式特征转换。由于PETR已经证明了3D PE在3D感知中的有效性,那么3D PE是否仍然适用于时间对齐?
在PETR中,通过摄像头参数将摄像头截锥空间的网格点(对不同视图共享)转换为3D坐标。然后将3D坐标输入到简单的多层感知(MLP)生成3D PE。在实践中发现,通过简单地将前一帧的3D坐标与当前帧对齐,PETR在时域条件下工作良好。
对于BEV分割的联合学习,BEVFormer提供了统一的解决方案,将BEV地图上的每个点定义为一个BEV query。因此,BEV query可用于3D目标检测和BEV分割。然而,当BEV地图的分辨率相对较大(比如 256×256)时,BEV query的数量(比如 >60000)往往会很大。由于transformer解码器采用的是全局注意机制,因此这种目标query定义显然不适合于PETR。
如图所示,PETRv2的总体架构建立在PETR的基础上,并通过时域建模和BEV分割进行扩展:2D图像特征是通过2D主干(例如ResNet-50)从多视图图像中提取的,3D坐标是从摄像头截锥空间生成的,如PETR一样。考虑到自运动,前一帧t-1的3D坐标首先通过姿态变换将变换为当前帧t的坐标系。然后,将相邻帧的2D特征和3D坐标分别串联在一起,并输入到特征引导的位置编码器(FPE)。然后,使用FPE为transformer解码器生成key和value组件。此外,从可学习的3D锚点和固定的BEV点,分别初始化检测query(det query)和分割query(seg query),并馈送到transformer解码器中,与多视图图像特征交互。最后,将更新后的query分别输入检测头和分割头进行最终预测。
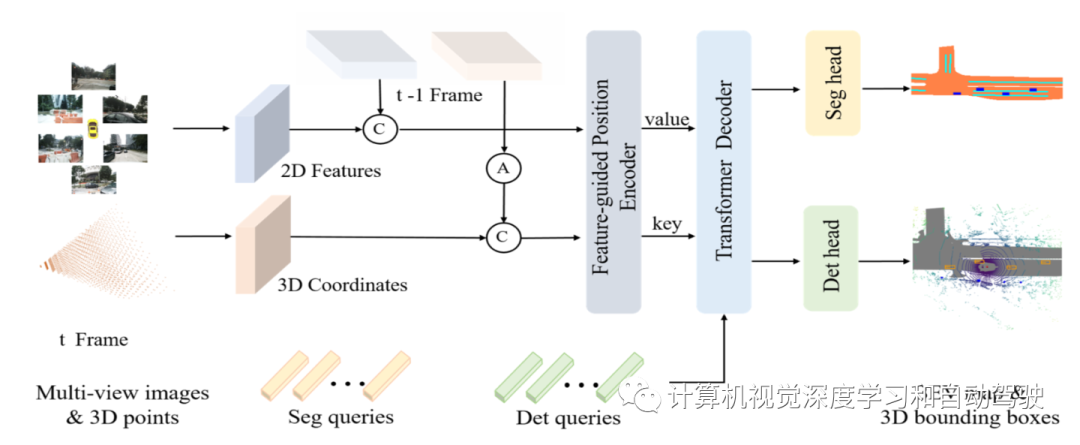
时间对齐是转换帧t-1的三维坐标到帧t的坐标系。为清晰起见,首先标记一些坐标系:相机坐标c(t),激光雷达坐标l(t),车辆坐标e(t);此外,全局坐标为g。将T定义为从源坐标系到目标坐标系的转换矩阵。用l(t)作为默认的3D空间来生成多视图摄像头3D位置-觉察特征。从第i个摄像头投影的3D点P-l-i(t)可以表示为:
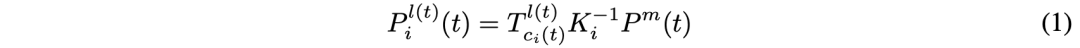
给定辅助帧t− 1,从帧t-1到帧t对齐3D点坐标:
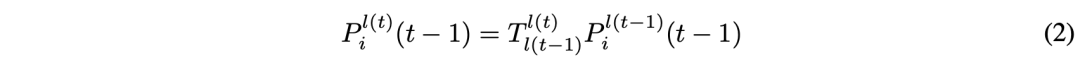
有全局坐标空间作为帧t-1和帧t之间的桥梁,变换T则易于计算:
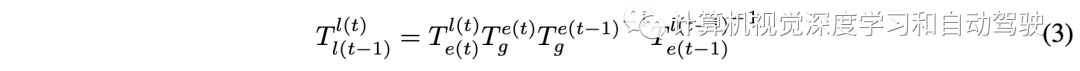
PETR将3D坐标转换为3D位置嵌入(3D PE),其生成可以表示为:
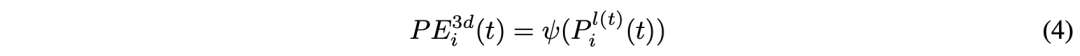
PETR中的3D PE与输入图像无关。3D PE应该由2D特征驱动,因为图像特征可以提供一些信息指导(例如深度)。作者采用一种特征引导的位置编码器,隐含地引入了视觉先验。这个特征引导的3D位置嵌入的生成可表示为:
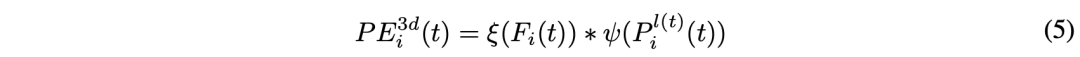
接着,将经1×1卷积投影的2D图像特征反馈到一个小MLP网络ξ和Sigmoid函数中,获得注意权重。3D坐标由另一个MLP网络ψ转换,并与注意权重相乘,生成3D PE。3D PE添加2D特征,获取transformer解码器的key组件。投影的2D特征用作transformer解码器的value组件。
下面为PETR配备seg query,支持高质量的BEV分割。高分辨率BEV地图可以划分为少量patch。对于用于BEV分割的seg query,每个seg query对应一个特定的patch(例如,BEV地图的左上16×16像素)。

如上图所示,seg query使用BEV空间中的固定锚点进行初始化,类似于在PETR中生成检测query(det query)。然后,通过具有两个线性层的简单MLP将这些锚点投影到seg query中。然后,seg query被输入到transformer解码器,并与图像特征交互。对于transformer解码器,用与检测任务相同的框架。
然后,将更新后的seg query最终输入分割头(一个简单的MLP网络,后跟一个Sigmoid层),以预测BEV嵌入。每个BEV嵌入被重塑为一个BEV patch(形状为16×16)。所有BEV patch在空间维度上连接在一起,产生分割结果(形状为256×256)。对于分割分支,用加权交叉熵损失对预测的BEV地图进行监督训练:
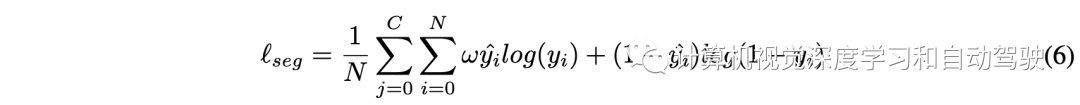
LSS显示了在测试时外部噪声和摄像头脱落情况下的性能。同样,BEVFormer证明了模型变化对摄像头外部特性的鲁棒性。在实践中,存在各种传感器错误和系统偏差。由于对安全性和可靠性的高要求,验证这些情况的影响非常重要。
如图所示,重点关注以下三种常见类型的传感器错误:

外部噪声:外部噪声在现实中很常见,例如汽车碰撞引起的摄像头抖动或环境外力引起的摄像头偏移。在这些情况下,系统提供的外部信息不准确,感知输出将受到影响。
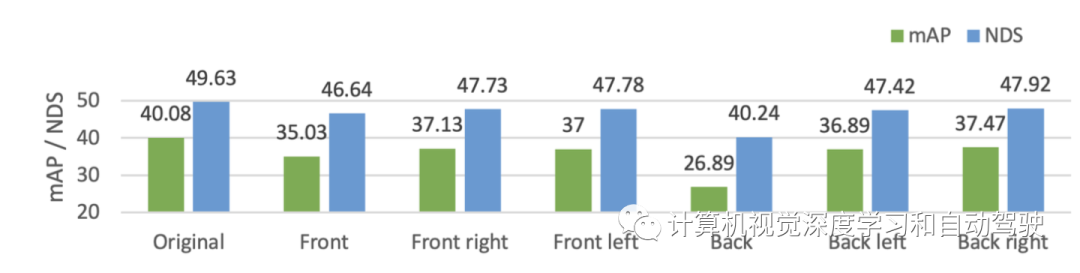
摄像头丢失:当一个摄像头发生故障或被遮挡时,会发生摄像头图像丢失。多视图图像提供全景视觉信息,但现实世界中可能缺少其中一个。有必要评估这些图像的重要性,以便提前制定传感器冗余策略。
摄像头延时:由于摄像头曝光时间的原因,延时也是一个挑战,尤其是在夜间。长曝光时间导致系统接收到前一时间的图像,并带来显著的输出偏移。
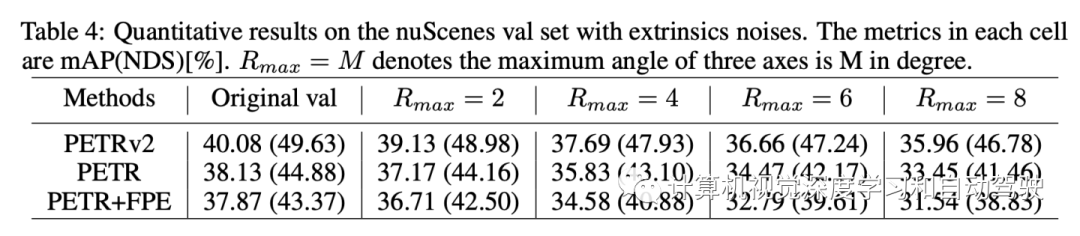
为了模拟外部噪声并评估效果,选择对摄像头外参矩阵随机应用3D旋转。忽略其他噪声模式,如平移,以避免多变量干扰。具体来说,从多个摄影头中随机选择一个来应用3D旋转。将α、β、γ分别表示为沿X、Y、Z轴的角度,研究几种最大振幅 αmax、βmax、γmax的旋转设置∈{2, 4, 6, 8},其中αmax = 2表示 α 从[−2,2]均匀取值。在实验中,用Rmax = M表示 αmax = βmax = γmax = M。
实验结果如下: