绑定手机号
确认绑定









【GaintPandaCV导语】
二值神经网络 (BNN)指的是weight和activation都用1-bit来表示的模型架构,相比FP32的浮点神经网络,它可以实现约32倍的内存减少,并且在推理过程中可以用xnor和popcount这样的位运算来替代复杂的乘法和累加操作,从而大大加快模型的推理过程,所以BNN在模型压缩与优化加速领域存在着巨大的潜力
在之前的两篇文章中我也对其进行过比较详细的介绍:
二值化神经网络(BNN)综述:https://zhuanlan.zhihu.com/p/270184068
二值神经网络(BNN)若干篇论文总结:https://zhuanlan.zhihu.com/p/365636375
不过虽然BNN在2016年就被正式提出,但在落地应用方面一直没有得到很好的重视,众多人认为这是因为在相同架构下的BNN相比于浮点的神经网络精度相差太多导致无法应用到真实场景,而目前应用最广泛的8-bit量化基本可以做到精度无损,甚至近两年4-bit量化也可以达到非常不错的效果,然而实际上一个模型架构能否落地应用应该从以下两方面进行考虑:
速度-精度平衡(SAT, speed-accuracy tradeoff):目前的BNN研究主要集中于如何在相同架构下,尽可能地减少1-bit和32-bit 神经网络的精度gap,除此之外,BNN整体的实际加速效益也远没有理论上64×(XNOR-Net提出)那么高,并且目前的研究实验基本上把第一层和最后一层仍然保持为FP32,进一步削弱了加速效益,如下图所示,BNN相比FP32大概是7倍加速,相比INT8大概是4倍。但在实际应用中,架构是可以根据任务进行修改的,更好的SAT才是真正应该追求的目标,而不是仅仅看精度这一个指标,如果一个1-bit的架构和8-bit的架构精度相近,但前者可以节省大量内存,显著降低延时,即可以达到很好的SAT,那就是一个好架构;
泛化性(Generality):BNN目前的研究基本集中在图像分类上,对其他任务泛化的很不好,比如1-bit目标检测领域大概只有不到10篇论文,精度还都不怎么行,因为BNN带来的信息损失实在太大了,而像图像分割,超分辨率这类对信息损失敏感的任务就更难了,也很少看到相关论文的实验;

针对上述两点问题,近期大疆创新 (DJI)在论文《Binary Neural Networks as a general-propose compute paradigm for on-device computer vision》中提出了一种BNN的新架构BiNeal networks (with Binary weights and No real-valued activations)
在常见的计算机视觉任务,如图像分类,目标检测,语义分割,超分辨率和图像匹配任务上进行了广泛测试,均可以得到很好的效果,同时也在特定硬件上进行了延时测试,可以获得比8-bit更好的SAT,从而证明了二值神经网络可以成为端侧计算机视觉的一种新的通用范式,原论文链接如下:
https://arxiv.org/abs/2202.03716arxiv.org

作者团队如上所示,里面还有几个前Google MobileNet系列的大佬,目前都是DJI机器学习部门的负责人。
下面将详细阐述一下相关亮点,基础内容请移步上面的综述。
过参数化即在训练过程中引入额外的对提升精度有益的参数,比如XNOR++提出的可学习的scale factor,ReAct-Net提出的RSign和RPReLU,这种额外增加的浮点参数在我之前的二值神经网络综述中提到过,我们把这些统一称为增益项 (Gain term),对于weight和activation,本文提出采用不同的过参数化方式:
Weight的过参数化

其中的额外参数有两个,分别是α和λ,α的维度可以像XNOR++中的scale factor一样有多种选择(N, N×C或N×C×K×K),而λ的维度为N,和输出通道相同。
之前的方法通常将α设置为1,λ设置为浮点weight的L1-Norm/N,而在本文中均设置为可学习参数,随着weight一起训练。在推理过程中α可以直接和浮点weight进行融合,只需要存储最终二值化之后的即可,λ可以和其他参数融合,后续会再提到。
Activation的过参数化
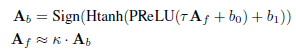
其中τ,b0, b1和k均为额外的参数,前三个参数是per-channel的,k是标量,这些参数和ReActNet的RSign和RPReLU一样,可以重塑activation的分布,从而帮助BNN的训练。虽然参数很多,但可以和sign函数和其他参数进行融合。
**增益项的融合:**对于α,可以在训练完直接和浮点weight融合,仅存储w_b,对于activation的第n个通道,二值activation可以通过如下形式获得:
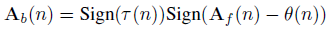
其中θ(n)可以通过b0(n), b1(n)和τ(n)计算得到,感兴趣同学可以看原文的附录,有详细解释。最终的卷积计算如下:
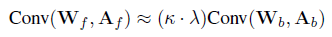
其中k和λ可以和PReLU进行融合,所以也不需要在前向推理过程中进行计算。
Batch Normalization融合:

由此,所有过参数技巧带来的增益项都可以被融合掉,由于这个输出进入下一层需要被二值化掉,所以这些参数又可以和sign进行融合,最终转换为不同通道的阈值,浮点activation大于这个阈值activation为+1,小于这个阈值为-1。
basic block如下所示,这里应该是BNN中常见的ResNet-18的basic block:

三点修改:
输入输出通道数量相比原始架构都扩大m倍,后面验证generality的实验基本上设置为2;
skip connection一直配备一个binary convolution,而不是单纯的residual connetion,无论是不是下采样层都有,这块感觉会增加不少计算量;
element-wise add的输入编码为INT4,求和输出为1-bit;
虽然channel数x2,但我感觉增加的计算量接近x3了,因为skip connection的binary convolution会带来不少的开销。这个basic block相比于Bi-Real Net,有三点优势:
BiNeal的输入为1-bit,这样就不需要频繁地进行精度的转换,也减少了数据搬移的次数;
不包含PReLU,sign (这里指的应该是BiReal中每次和浮点connection加完再转化为1-bit的操作)和其他非线性操作;
skip connection很高效,额外的卷积是1-bit,输出也都是1-bit;
此外,传统的BOPs和模型大小过于粗糙,并没有考虑数据搬移带来的延时开销,从而不能真实地反映复杂性指标,为了证明这个架构的高效性,作者描述了一个基于经典收缩阵列的1位ASIC加速器设计,并推导出一个公式来计算不同块所需的计算周期,具体细节可以见原文和附录的推导,此处不做详细介绍。
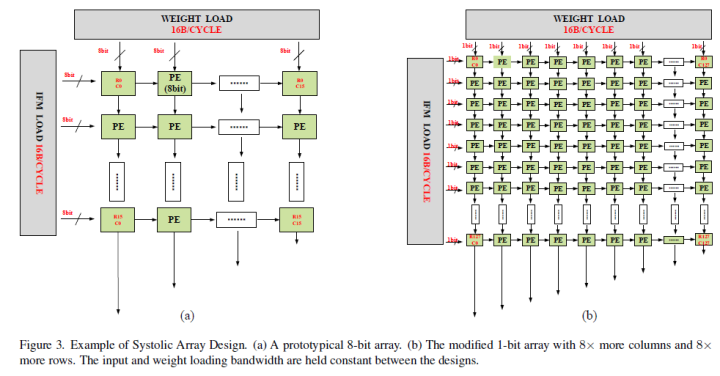
本文的出发点就是原始BNN的speed-accuracy tradeoff和generality做的不好,作者也是从这两个方面进行的对比实验来验证这个BiNeal架构的先进性。
所有的模型都是在Snapdragon 845 CPU(Cortex-A75@2.8GHz)平台上进行的测试,为了更好地对比,对于不同bit都选取其最好的engine,即FP32和8bit采用TFLite,而BNN采用Bolt,结果如下:
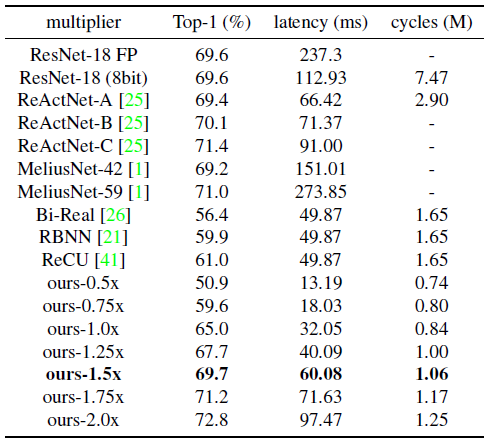
可以看出,在1.5倍通道扩增的情况下,BiNeal可以达到和8-bit相近的精度,但在Bolt上可以实现1.9倍的加速效果,同时在cycle指标下实现7倍的加速(即如果设计BNN专用的ASIC可以实现7倍的加速效果),同时相比目前最有竞争力的架构ReActNet-A的延时和cycle指标快1.1和2.7,从而证明BiNeal架构确实可以达到更好的SAT。
这里的实验,通道倍数m均采用2,Cosine Annealing的学习率更新方式,wd为1e-5,下面的baseline都是8-bit的结果,延时都是使用Bolt在Snapdragon 845 CPU(Cortex-A75@2.8GHz)平台上测试的,前面图像分类不是说8-bit在TFLite更好吗,这里咋还换了engine。
目标检测任务
输入图像尺寸为448×672×3,主干网络为ResNet-18,将其替换为BiNeal,并且复用前面分类模型的训练参数作为pretrained。第一个CenterNet是原文结果,第二个CenterNet是mmdetection复现的结果,ours是仅将backbone换成BNN,ours*是将BNN和head均替换为BNN,可以看出BiNeal均可以达到更好的SAT。

图像分割任务
输入图像尺寸为512×1024×3,主干网络仍然是ResNet-18,在ImageNet上预训练,原文貌似是说将FCN二值化了,结果可以看出相似的精度,可以达到1.4倍的Bolt延时加速和3.9倍的cycle加速。

超分辨率
对EDSR进行binarize,原始模型有点大,为了可以进行通道扩增使用了更小的模型,block数更少,通道数更小了,第一层和最后一层保持为8-bit,同样也是SAT更好。
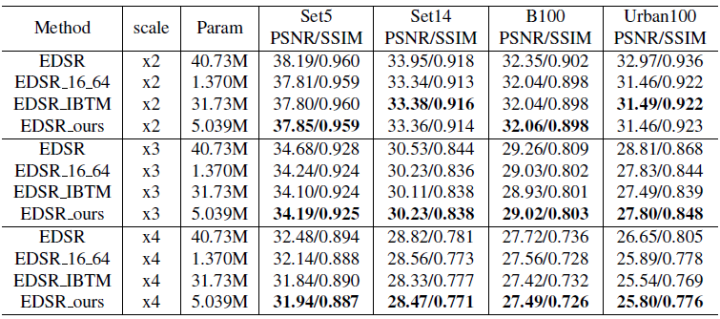

图像匹配
针对R2D2算法**,**将网络的大部分进行二值化,并保留最后两个输出层不变。每两个连续的卷积可以被视为一个没有skip connection的BasicBlock,在Web image (W), Aachen day-time images (A) and Aachen optical flow pairs (F)数据集上训练,在HPatches上进行测试,同样也是更好的SAT。

本文提出了一种新的BNN架构,可以在众多计算机视觉任务上达到和8-bit精度相近,但硬件效益更好的效果,ARM CPU上达到1.3~2.4倍加速,ASIC上的cycle达到2.8-7.0的加速,证明了BNN这种架构可以成为计算机视觉模型端侧部署的新的通用范式,感觉非常有意思,有空尝试复现一下这个图像分类的结果,不过有些结构细节描述的还是不太清楚,感觉会有点坑在里面。







