绑定手机号
确认绑定









作为一个在自动驾驶感知领域摸爬滚打几年的老兵,准备在平台上分享一些自己对这个领域的理解。这样既可以帮助我自己建立起一个更系统的知识体系,同时希望借此能认识到更多优秀的同行,所以欢迎大家相互交流、互助互进。文章的信息来源主要是公开信息、其他创作者的分享和我结合日常工作的心得,再次非常感谢引用文章的同仁。
数据闭环
今天第一章想要分享的就是数据闭环,目前在自动驾驶领域,数据闭环概念可谓热火朝天。借助数据闭环概念和理想的滚动迭代模型,自动驾驶这个看似无法实现的愿景,逐步具备可落地性。一方面科技公司因此获得资本的青睐,不断提高自身的估值;另一方面车企又特别满意这种数据为王的逻辑,它们掌握着第一手的数据来源稳坐钓鱼台。那么首先,我们要需要解释下什么是“数据闭环”。
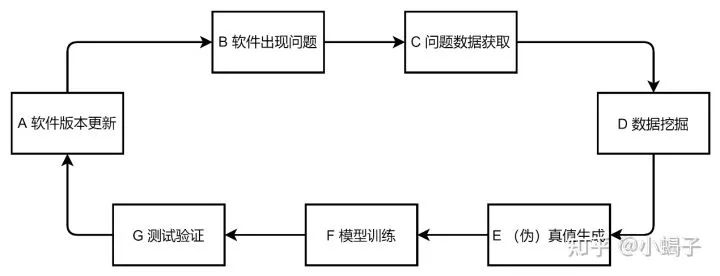
数据闭环又称数据分析闭环,其核心思想是一个非常朴素的分析方法:当我们遇到一个软件(或算法)问题时,采集相关数据并进行复现,对产生的问题进行针对性解决,更新软件(或算法)版本后进行测试确认,最后发布新的版本。
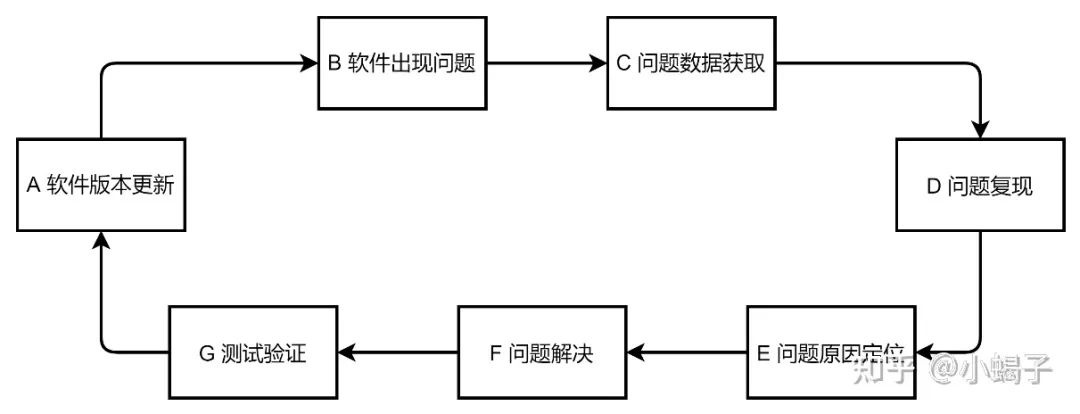
当这个环路中每一个步骤都是有技术实现手段时,则整个闭环形成,可以根据这个闭环完成软件(或算法)的迭代升级。
在软件开发阶段,即版本尚未正式发布时,整个环路一般来说都是可控和可实现的:由软件开发(含自测)团队完成A、D、E、F、G的分析步骤,当版本确认后由系统测试人员进行测试,测试过程发现问题(步骤B)会详细记录问题表现、时间等信息(步骤C),并提供给开发人员。但是软件版本正式发布后,步骤B和C是缺失的,这也是很多公司或者文章在描述数据闭环时都是关注在信息收集这块。通常来说这两个步骤的缺失是因为以下几种原因:
软件中没有合适的问题反馈机制
软件使用者没有相关能力提供有效问题信息
软件出问题涉及到自身的操作信息,软件使用者不愿意提供
由于问题数据是价值最高的数据,所以所有的软件商都会在数据闭环上做大量的工作,比如大家在使用电脑时一定会遇到类似的弹框:
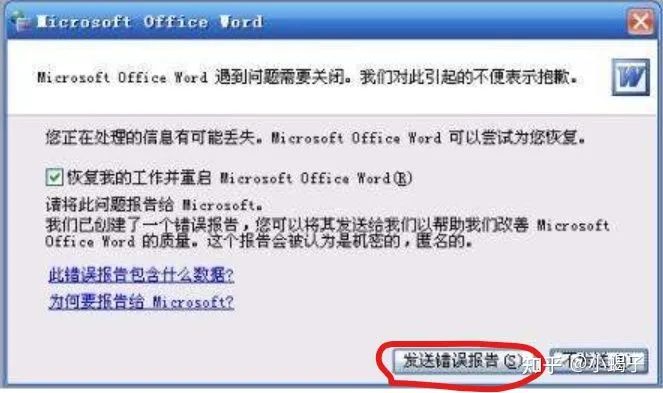
这里面这个弹框的响应就是一个有效的数据闭环,并且完美解决了上面三个问题:首先出问题时软件主动弹框,客户只需要进行确认即可;软件后台将需要的信息打包好,客户无法知道上传了什么,所以规避了2和3。但这个是传统的PC端软件,自动驾驶相关软件遇到的问题将会比PC端更复杂。相对于PC端软件:
驾驶员应尽量避免驾驶分心、在软件出错时做额外操作,如点击等;
智能驾驶软件发布时就应该极大降低概率影响到驾驶员的软件问题,所以大量驾驶员无法感知的软件问题无法被记录;
驾驶信息包含道路、交通参与人员等信息,法律法规会有相关监管。
其中3是政策问题,不是技术方案瓶颈。自动驾驶相关公司通过静默(影子)运行方式和OTA来解决问题1和2。总体而言,在自动驾驶这个软件领域,已经完成步骤B和C这两块技术实现,从而打通整个数据闭环链路。
厂商数据闭环模式
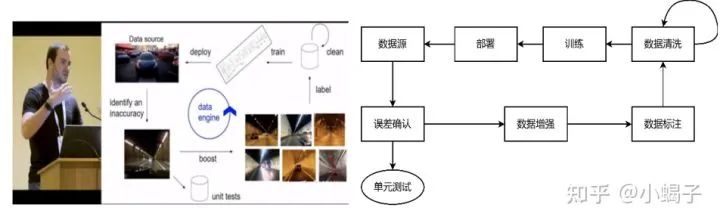
特斯拉:下图是特斯拉公开的数据闭环滚动模型框架:获得数据来源后,通过单元测试确认模型误差,通过数据增强扩增技术获得大量有效数据并进行数据标注,经过多轮数据清洗,完成模型训练,最终完成部署。
waymo:下图是谷歌waymo报告提到的数据闭环平台:获得数据来源后,通过人工标定和自动标定获得数据真值,这步骤中涉及到数据筛选、挖掘和主动学习。迭代完成模型优化后,完成测试和版本发布;再持续获取数据。
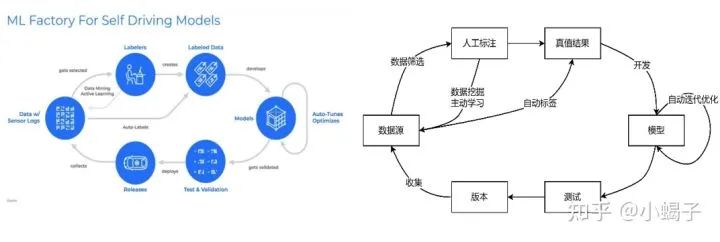
Nvidia:下图是英伟达公司在自动驾驶开发建立的机器学习平台MAGLEV,也是基于闭环的模型迭代:从实车获得数据来源后,以此完成智能数据筛选、数据标注、模型搜索、训练、评估、调试和部署。

momenta:下图是momenta公司2019年开始提出的“飞轮模式”,本质上也是数据闭环的滚动模式,包含三个关键因子:

数据驱动:打造全流程内的数据驱动,相比基于人工驱动,各模块性能将有跨数量级的提升;
海量数据:目标收集数十亿的公路道路真实场景,并完成L4与L2的数据流统一,形成技术与数据双轨提升;
闭环自动化:对数据具备高度自动化的挖掘能力和标注能力,实现晒下、标注、迭代的全流程闭环自动化
毫末智行:其自动驾驶数据智能体系 MANA如下图所示。MANA 包括感知、认知、标注、仿真、计算五大方面能力;在数据、算法之间,通过知识挖掘、仿真验证完成算法迭代的闭环和滚动。
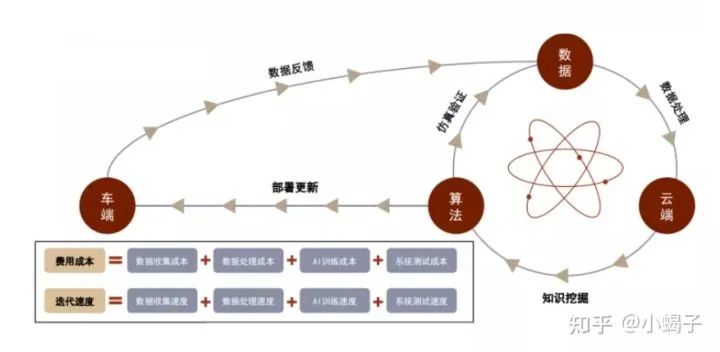
数据闭环趋势
结合竞品分析可以看到,数据闭环本身是一个固定的分析模式,但是各个步骤都是随着任务变化和技术革新在不断发展的。数据闭环中,如果每个算法问题都由人工去复现和debug,将带来巨大的成本:在软件开发中,假设100个问题可以由100个工程师1天内解决,那如果是1万个问题,则要么1万个工程师1天解决,要么100个工程师100天内解决,这种人力成本或者是软件开发周期都是无法接受的,而在自动驾驶领域,算法人员需要面对的将是远超万计的算法问题。因此数据与算法双轮驱动才能实现更成熟的自动驾驶技术,这也是自动驾驶技术落地的必然选择。
那么为了打造一个健全、完整和低成本的理想软件迭代模型,将要从数据和算法两个方向进行准备:
在数据侧,围绕海量和高质量两个要素进行样本收集。理想的数据收集包含实车数据和仿真数据,实车数据量=实车数量*采集时间。高质量体现在两个维度:传感器的丰富程度和样本稀缺性:

在算法侧,在保障性能的前提下提高自动化将是未来算法方案的主要趋势。在数据闭环的应用方向上,算法主要落脚在三个领域:海量数据的挖掘算法、高精度的伪真值生成算法、功能算法量产方案(尽可能做到端到端):

基于此一个较为理想的数据驱动的闭环模型就演化成:
整个闭环系统的核心是在数据和量产算法方案的滚动,那在后面的分享中先分享一下数据采集的相关内容。
公共数据集
在算法研究的初期,大家都会使用公共数据来做初步验证。公共数据集做为数据集的质量标杆,可以借助其来分析采集设备需求。其中宣称能达到厘米级别定位精度的常用数据有Kitti、Nuscenes、AplloScape、Waymo、Lyft Level5等。
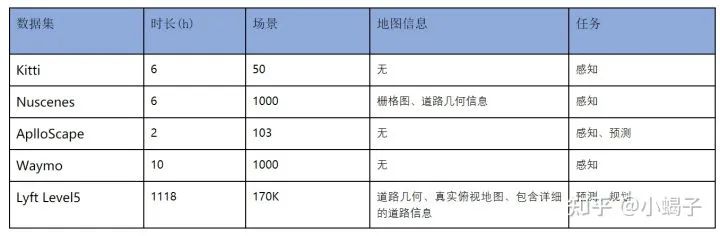
对于感知任务来说,主要的信息是目标的bounding box(含2D、3D)或原图上的逐像素语义信息。Kitti数据集是当前感知任务中最通用的数据集,几乎所有的CV公司都在使用这个数据,Kitti数据采集车的主要传感器包含:
1惯性导航系统(GPS/IMU):OXTS RT3003
1台激光雷达:Velodyne HDL-64E
2台灰度相机,1.4百万像素:Point Grey Flea2(FL2-14S3M-C)
2个彩色摄像头,1.4百万像素:Point Grey Flea2(FL2-14S3C-C)
4个变焦镜头,4-8毫米:Edmund Optics NT59-917
Nuscenes和Waymo数据集与Kitti的结构和信息相似,提供基于融合感知的的3D bounding box标签真值。ApolloScape数据集包含两种,有的侧重目标感知,有的则标注了目标轨迹,可用于预测任务。
2020年公开的Lyft Level5数据集与上述数据集有较大差异,它没有提供bounding box信息,但其提供了一段道路上每个点的详细地图信息,这个地图中既包含了详细的静态道路信息,也包含了采集时刻的目标信息、(已俯视图包络提供),所以这个数据集对常见的移动目标感知任务可能帮助不大,但可以有效的提供静态目标信息,且能排除掉动态目标的干扰,这个是其它数据所不具备的。这个数据是当前BEV相关算法最佳的基础数据。
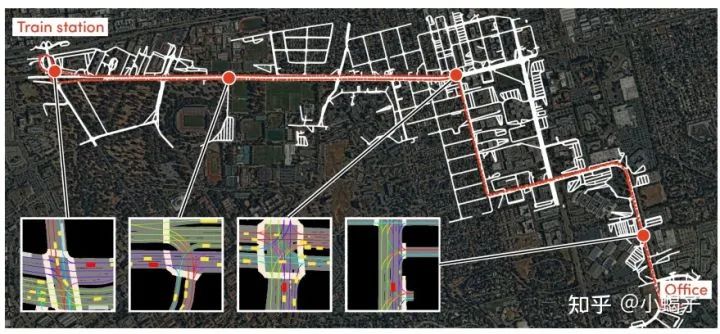
Lyft Levels5数据集的采集车装载了3颗激光雷达、5颗毫米波雷达和7个相机,其中车顶激光(64线@10HZ)、四颗毫米波雷达和7个相机均安装在车辆顶部,车前保险杠装配两颗40线激光雷达和1颗毫米波雷达(如下图)。

Lyft Level5采集车中并未给出车辆定位传感器的信息,借助高德地图采集车的信息,可以了解到这种制作高精度地图的传感器精度需求:
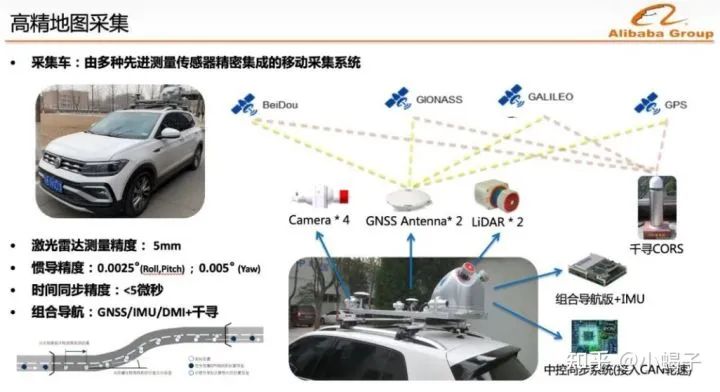

激光、惯导精度一般由激光硬件决定。而为了在激光和相机之间实现良好的跨模态数据对齐,当顶部激光扫过相机FV的中心时,将触发相机的曝光。图像的时间戳是曝光触发时间;激光扫描的时间戳是当前激光帧完全旋转的时间。考虑到相机的曝光时间几乎是瞬时的,因此这种方法通常可以实现良好的数据对齐。当然相机尽量选择卷帘式快门,这样可以将曝光时间固定,目前用于采集高精地图和公共数据集的都是卷帘式快门相机。
在定位精度上,现行在纯车端的方案上,最理想的精度就是组合导航定位:GPS\IMU\DMI,高德宣传中的千寻是一家独立的定位算法公司,其应该是结合自研和外购算法得到更稳定的定位精度。
GPS或GNSS;指全球定位系统。用户设备通过接收卫星信号,得到用户设备和卫星的距离观测值,经过特定算法处理得到用户设备的三维坐标、航向等信息。使用不同类型的观测值和算法,定位精度为厘米级到10米级不等。其优点是精度高、误差不随时间发散,缺点是要求通视,定位范围无法覆盖到室内。
IMU(Inertial measurement unit):指惯性测量单元。包括陀螺仪和加速度计。陀螺仪测量物体三轴的角速率,用于计算载体姿态;加速度计测量物体三轴的线加速度,可用于计算载体速度和位置。M心的优点是不要求通视,定位范围为全场景;缺点是定位精度不高,且误差随时间发散。GPS和IMU是两个互补的定位技术。
DMI(可量测影像):是一种新兴的地面立体景影像信息产品,包含时空序列上绝对外方位元素信息,可以支持对环境实景的直接浏览、对目标地物高度、宽度、面积等信息的相对测量,以及绝对位置解析测量和目标属性信息挖掘等应用。利用车辆导航系统采集实时影像(real-time image),并与预先获取的可量测影像进行匹配,将匹配上的可量测影像空间位置信息传递至实时影像,通过空间坐标变换推算出运动载体的当前位置。其实可以简单理解为结合视觉信息进行辅助定位。
国内厂商数据采集情况
目前网上各个公司对开发的样本来集披露较少,一方面这些信息涉及开发隐私,同时开发数据和测试数据一般而言是同源的,路测数据是开发数据的一个重要子集。所以我们可以根据国内研发Robotaxi的路测信息来侧面评估数据采集情况。这些路测数据在有效处理后都是可以转换为开发样本,而且L4级别的高精度传感器对L2级别量产方案来说也会有显著的正向收益:
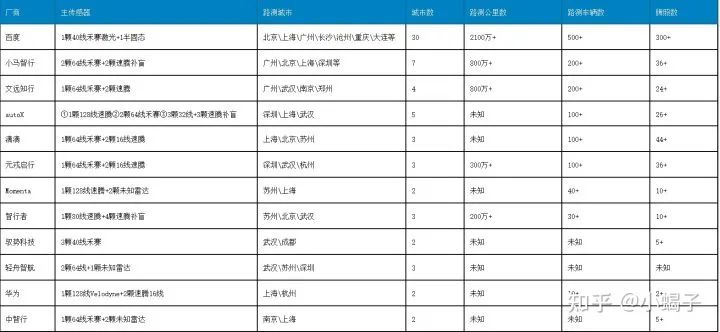
从能收集到的信息看,百度在数据采集上处于明显的领先地位。路测城市、公里数和采集车辆都要远远超出其它公司;小马智行、文远知行、autoX(2022年2月,autoX宣称其有1000辆以上的Robotaxi车队)大概处于第二梯队状态,公里数大概在800万左右;滴滴、元戎、momenta、智行者预计相差不大,200~500W的测试量。其它公司披露的信息不是很全,不好评估。需要再次强调的是,这个是以Robotaxi的路测信息来评估,实际中各个公司特别是那些布局多个赛道的厂商来说,肯定是有额外的数据来源的:比如华为,在2020年公开了自动驾驶数据集ONCE Dataset,包含100万帧3D点云场景,每个3D场景有7个相机拍摄覆盖360度视角的图片,共计700万张图片。
量产数据回收
上述讨论的都是开发阶段的数据采集能力建立,另一种数据收集能力也就是打通数据闭环系统的关键能力就是量产数据回收。首先说明当前主要还是讨论将自动驾驶汽车作为数据收集端口和应用输出,并不扩展到车端直接处理高密集训练任务的情况(后续可以逐步扩展)。
OTA(Over-the-Air Technology):是通过移动通信的空中接口实现对移动终端设备及M卡数据进行远程管理的技术,其原先的主要目的是使用户能够通过下载和更新获取增值业务。但随着网络传输通道的打通,用户使用信息的上传也将使软件提供商获得大量有效信息,从而有能力提供更有竞争力的功能。首先在自动驾驶领域使用OTA技术可以追溯Mobileye和特斯拉的合作期间(2014年前),在两家公司分开后,各自都在大力借助OTA提升产品力:Mobileye首创Road Experience Management路网采集管理系统,将所有搭载Mobileye设备的感知设备上传并在云端生成感知地图、再将感知地图升级到各个车端提升感知能力。
而特斯拉在这块就更加激进,一方面将车辆逐渐软件化,通过逐步付费解锁的方式新增各类驾驶功能,另一方面通过数据回传收集了几百亿公里的实车数据。对比前文中各个国内L4的路测数据,可以看出这种数据收集方式的能量和效率的恐怖之处了。所以国内相关自动驾驶OTA技术都是在模仿和改进特斯拉的相关方案。
特斯拉在数据回收上的最大技术亮点就是影子模式,影子模式完美解决数据收集的质和量的矛盾。因为受限当前自动驾驶功能还不成熟,驾驶员使用自动驾驶功能的次数不会特别频繁,那在未开启时数据只能是简单通过采样方式去回收大量的传感器原始数据。而一辆装载摄像机、激光和雷达的数据的驾驶车,每天能产生80T的数据,这种数据量传输在5G建设成熟之前是不可能完成的。
另一个问题是驾驶员为自身安全考虑,更多的是在自己熟悉的道路开启自动驾驶功能,所以如果只在这些时侯开启数据回收,那么只能收到一些固定场景的数据,而且很多都不会出现什么突发状况,导致数据价值降低。特斯拉「影子模式」的核心就在于在有人驾驶状态下,系统包括传感器仍然运行但并不参与车辆控制,只是对决策算法进行验证一一系统的算法在「影子模式」下做持续模拟决策,并且把决策与驾驶员的行为进行对比,一旦两者不一致,该场景便被判定为「极端工况」,进而触发数据回传。这种模式相当于将驾驶员的操作当做驾驶真值,将大量算法已覆盖的场景过滤掉,保留高质量的问题样本回传。
当然随着自动驾驶功能逐步铺开,如何在自动驾驶功能开启阶段去收集有益信息也是一项重要工作。特斯拉在影子模式和算法自评这块共设计了221个触发器(截止2021年),其对外宣传的触发点信息如下图示:

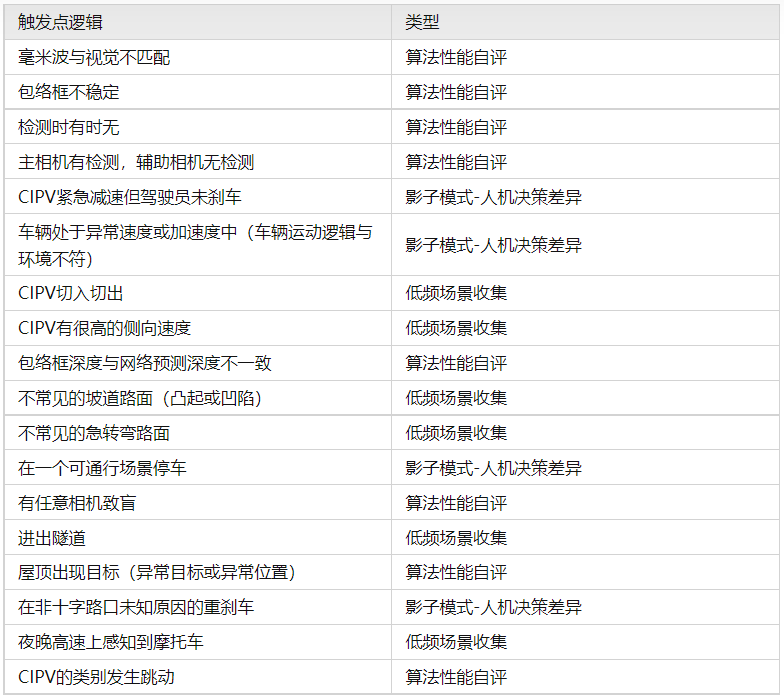
做个数据整理可以看到触发模式可以分为三个大的方向:
算法性能自评:最常见的方式是通过多传感器或前后帧的感知差异判断出至少有一路感知性能存在错误;
人机决策差异:当驾驶员的行为逻辑与当前感知结果不吻合时,有概率存在感知结果不符合预期的情况;
低频场景收集:结合开发经验,对一些指定场景进行针对性触发
仿真数据生成
在自动驾驶领域,还有一个重要的数据来源是依靠仿真模拟工具生成,要想自动驾驶的仿真平台能实际为自动驾驶发挥出相应的能力,必须要具备几种核心能力:真实还原测试场景、高效利用路采数据生成仿真场景、云端大规模并行加速等,使得仿真测试满足自动驾驶感知、决策规划和控制全栈算法的闭环。目前包括科技公司、车企、自动驾驶方案解决商、仿真软件企业、高校及科研机构等主体都在积极投身虚拟仿真平台的建设。
当前应用最广泛的仿真平台有:PreScan、Carmaker、CarSim、VIRES VTD、PTV、Vissim、TESS NG、CARLA等;在自研中以Waymo的投入最大,相较特斯拉,waymo没有那么庞大的真实数据回收机制,所以其绝大部分的算法测试都是基于仿真平台,截止到2021年12月,Waymo自主研发的仿真测试软件Carcraft已模拟了170亿公里的道路场景,且支持Waymo车型进行大规模测试。
但到目前来说,公开软件的仿真数据对感知的作用主要是体现在网络的预训练上,这块暂不展开,后续待相关研究日趋成熟时再做单独调研。
数据采集后的主要工作就是真值标定,下一章将聊一聊自动驾驶数据的预标定工作。
参考资料
<One Thousand and One Hours:Self-driving Motion Prediction Dataset> John Houston etc.
<面向自动驾驶的高精地图及数据采集生产体系> 知乎
<安波福数据集nuScens> CSDN weixin45032449
<影子模式,是不是被“神化”了?> 《九章智驾》 苏清涛
<自动驾驶汽车的数据将如何管理和传输?> 涅槃汽车
<特斯拉视觉自动驾驶进度展示> Andrej Karpathy(Tesla):CVPR2021 Workshop on Autonomous Vehicles
<7大国内外自动驾驶仿真平台汇总> 智能交通技术前沿









