绑定手机号
确认绑定









在工业制造和物流领域,各种工业机器人可用于优化货物的流转,其中物料的拆垛是常见应用之一。“机器人拆垛”通常指利用机械臂将物料按顺序从托盘上卸载的过程,可以用于替代简单但繁重的体力劳动。在物流领域中,存在将不同品规的货物(即不同尺寸、重量或纹理的商品)装在箱子内进行交付的场景,如图1所示。
图1
然而,早期的机器人拆垛系统主要通过人工控制来完成机器人抓取,只适用于单一货物的卸载,且要求货物按照固定顺序排列,机器人并不具备感知能力,无法对外界的变化做出反应。然而,多品规物料拆垛系统的待卸载物体尺寸多变,且码放不规整,因而要求机器人具备实时的环境感知能力以引导抓取动作。
随着各类光学传感器的发展,人们逐渐将计算机视觉技术引入机器人抓取任务中,以提高机器人获取外界信息的能力。基于视觉引导的机器人拆垛系统通常包含五个模块,分别为视觉信息获取模块、物体定位与分析模块、抓取位置计算模块、手眼坐标转换模块和运动规划模块,如图2所示。其中,前三个模块为视觉系统的主体部分,负责获取、处理视觉信息,提供物体位姿。后两个模块主要用于向机器人提供控制信息,完成抓取功能。下面我们将对每个模块、常用方法及实施案例进行介绍。
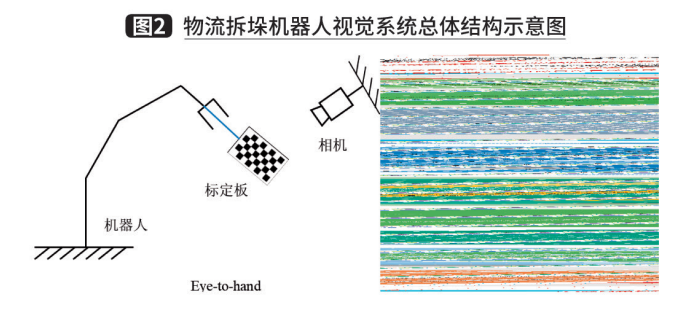
视觉信息获取模块的作用是捕获视觉信息,为后续步骤提供输入。目前较为常用的视觉输入包括2D RGB图像、3D点云图像和2D与3D组合的RGB-D图像等。其中,基于2D RGB图像的视觉辅助机械臂抓取是目前工业上比较成熟的方案,其将机器人抓取的问题转化为对RGB图像做物体的目标检测或图像分割的问题。然而,2D视觉缺乏物体的绝对尺度信息,只能在特定的条件下使用,如垛型固定、物料尺寸已知的场景。对于物料品规未知的场景,要求视觉模块为机器人提供准确的待抓取物体的绝对尺寸信息,因此只能使用3D点云图像或2D与3D组合的RGB-D图像。相比于RGB信息,RGB-D信息包含了相机到物体的空间距离信息;相比于3D点云图像,RGB-D信息则包含丰富的彩色纹理信息。因此,可以采用RGB-D图像作为多品规物料拆垛系统的视觉信息输入。
物体定位与分析模块接收视觉信息获取模块输入的数据,分析出场景中存在的物料,并获取其位置、姿态等关键信息,之后再将这些关键信息输入抓取位姿计算模块。通常来说,机器人拆垛系统中的物料定位问题可以转化为视觉领域的目标检测或图像分割问题。基于RGB-D视觉的机器人抓取方案,可以先在RGB图像上对物料进行二维目标检测或二维图像分割,然后融合深度图输出物体的绝对尺寸与抓取位姿;或者直接对三维点云图做目标检测或分割。下面将对相关工作进行简单介绍。
1.二维目标检测
二维目标检测的输入是场景的RGB图像,输出为图像中物体的类别和位置,位置以边框或中心的形式给出。目标检测的方法可以分为传统方法和基于深度学习的方法。传统的目标检测方法一般使用滑动窗口的方式遍历整张图片,每个窗口成为一个候选区域。对于每个候选区域,首先使用SIFT、HOG等方法进行特征提取,然后训练一个分类器来对提取的特征进行分类。比如经典的DPM算法就是使用SVM对改良后的HOG特征进行分类,从而达到目标检测的效果。传统方法有两个明显的缺陷:首先是用滑动窗口来遍历整张图片十分耗时,使得算法的时间复杂度很高,难以应用于大规模或有实时性要求的场景;其次,所使用的特征往往需要人工设计,使得此类算法较为依赖经验,鲁棒性较差。
2.二维图像分割
图像分割可以看作像素级别的图像分类任务。根据分割结果含义的不同,又可以将图像分割分为语义分割(semantic segmentation)和实例分割(instance segmentation)。语义分割对图像中的每个像素都划分出对应的类别;而实例分割不但要进行像素级别的分类,还需要在具体类别基础上区别开不同的实例。相对目标检测的边界框,实例分割可精确到物体的边缘;相对语义分割,实例分割需要标注出图上同类物体的不同个体。在拆垛应用中,我们需要精确提取物料的边缘以计算抓取位置,因此需要采用实例分割技术。现有的图像分割技术可以分为传统方法和基于深度学习的方法。
传统的图像分割方法大多基于图片中灰度值的相似或突变来判断像素是否属于同一类别。常用的方法包括基于图论的方法、基于聚类的方法和基于边缘检测的方法。
基于深度学习的方法相比于传统方法大幅度提高了二维图像分割的准确性。典型的深度神经网络框架,如AlexNet、VGGNet、GoogleNet等在网络的最后加入全连接层进行特征整合,随后通过softmax来判断整张图片的类别。为了解决图像分割问题,FCN框架将这些全连接层替换成了反卷积层,使得网络的输出结果从一个一维概率变成了一个和输入分辨率相同的矩阵,是将深度学习应用于语义分割的开山之作。
3.三维目标检测
三维目标检测通过直接计算物体的3D位置,使机器人可以准确地预判和规划自己的行为和路径,避免碰撞和违规。三维目标检测按照传感器类型分为单目相机、双目相机、多目相机、线面激光雷达扫描、深度相机和红外相机目标检测。一般而言,由多目相机组成的立体/多目视觉系统或者激光雷达可以实现更准确地3D点云测量,其中基于多视图的方法可以使用从不同视图的图像中得到的视差来获得深度图;基于点云的方法从点云获取目标信息。相比较而言,由于点的深度数据可以直接测量,基于点云的三维目标检测本质上是三维点的划分问题,因此更为直观和准确。
抓取位姿计算模块利用第二个模块输出的目标物体的位置姿态信息来计算机器人的抓取位姿。由于在多品规物料拆垛系统中经常同时存在多个可抓取目标,因此该模块应解决“抓哪个”和“怎么抓”两个问题。
第一步解决“抓哪个”的问题。该问题的目标是在众多抓取目标中选取一个最佳的抓取目标,这里的“最佳”往往需要通过实际需求来定义。具体地,可以根据实际情况量化一些对抓取判断有影响的指标,然后对这些指标进行优先级调度。
第二步解决“怎么抓”的问题。我们可以选择通过力学分析的方式解析计算出抓取的位姿,也可以通过学习的方法先对物体进行分类,再根据分类选择抓取点,或者直接回归出抓取位姿。
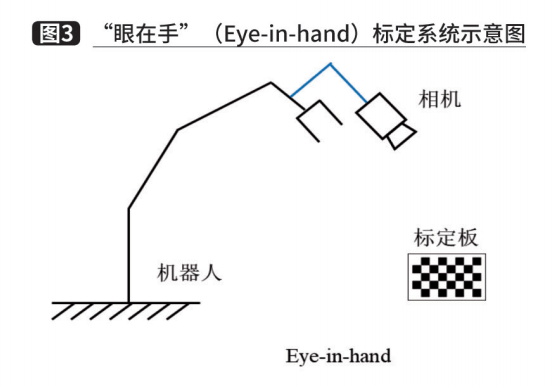
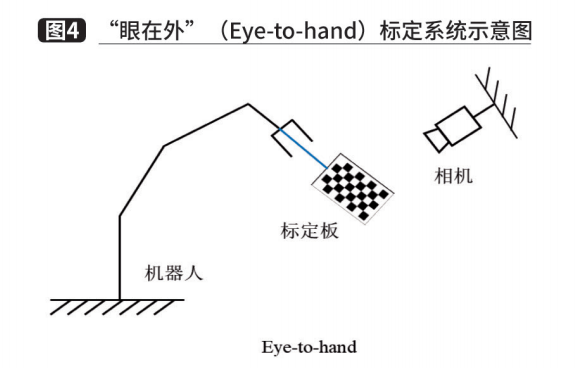
通过第三个模块,我们已经获得了一个可行的抓取位姿。然而,该抓取位姿是基于相机坐标系下的位姿,在进行运动规划之前,还需要将抓取位姿转化到机器人坐标系下。在拆垛系统中,通常使用手眼标定来解决这个问题。根据相机固定位置不同,手眼标定方法可以分为两种情况。一种是相机固定在机械臂上,相机随着机械臂一起移动,称为“眼在手”(Eye-in-hand),如图 3所示。在这种关系下,机械臂的两次运动中,机器人底座和标定板的位姿关系始终不变,求解的量为相机和机器人末端坐标系的位姿关系。另一种是相机固定在独立支架上,称为“眼在外”(Eye-to-hand),如图 4所示。这种关系下,机械臂的两次运动中,机器人末端和标定板的位姿关系始终不变,求解的量为相机和机器人底座坐标系之间的位姿关系。两种情况最终都转化为一个AX=XB的求解问题,可以利用李群和李代数将该方程转化为线性方程以分别求解旋转量和平移量。
该模块主要考虑机器人的运动学、动力学、力学分析、运动规划等,规划出一条与环境不碰撞的可行运动路径。通过将抓取位姿计算模块获得的相机坐标系下的抓取位姿乘以手眼坐标转换模块标定的转换矩阵,我们可以得到机械臂坐标系下的抓取位姿。根据这个位姿可以进行运动规划,最终引导机械臂完成拆码垛任务。因此,运动规划模块的输入为机械臂运动的起始位姿和目标位姿,输出为机械臂的运动路径。
完整的运动规划算法可以拆分成以下三个步骤:
步骤一:逆运动学求解。为避免出现奇异点等问题,机械臂运动规划一般在关节空间下进行。所以我们首先应根据输入的位姿进行逆运动学求解,得到位姿对应的关节值。
步骤二:路径规划。通过路径规划算法,我们可以得到机械臂的运动路径。该步骤的目标有两点:一是避障,保证机械臂在运动过程中不与场景中的其他物体发生碰撞;二是提升运行速度,以提高系统的运行效率。通过规划合理的运动路径,可以让机械臂单次抓取的运行时间更短,从而提升效率。
步骤三:时间插值。尽管通过路径规划我们已经可以得到一条可行的运动路径,然而这条路径是由一个个位置点构成的。机械臂在沿着这条路径运行时,需要不停加减速,因此会对运行速度造成影响。为此,我们需要进行时间插值,对路径上的每个点求取机械臂运动到该点时的速度、加速度、时间信息等。这样,机械臂便可以连续、平滑地运行,从而提升效率。
基于上述研究,在件箱物料识别场景中,可采用由3D深度相机、光照系统、计算机、以及视觉处理软件组成的一个完整的视觉系统,获得现实物体的一些特殊信息,而通过这套系统获得的信息,可以被用于完成一些特殊的任务,例如通过视觉系统获得箱子位置,可以引导机器人抓取,获得箱子数量信息,作为任务的校验。这套系统的主要组成部分,如图5所示。

3D相机和光照系统主要用于拍照成像,其中3D相机可以获得一定范围内的深度数据。而数字图像成像与光照系统相关。计算机则包括通用计算与存储设备,用于保存图像,通过专门的视觉软件处理图像,同时还要与其他系统进行网络通讯。图像显示器可以方便操作者操作视觉处理软件,监测系统运行情况。大容量储存用于永久或暂时存放图像或其他数据。而专门的视觉软件则包括数字图像处理,图像数据分析,以及一些特殊功能。
一般来说,一台3D深度相机帧率为1到30帧,RGB图像分辨率有640×480,1280×960,特殊的有1920×1080,2592×1944,深度范围为500mm左右到5000mm左右。
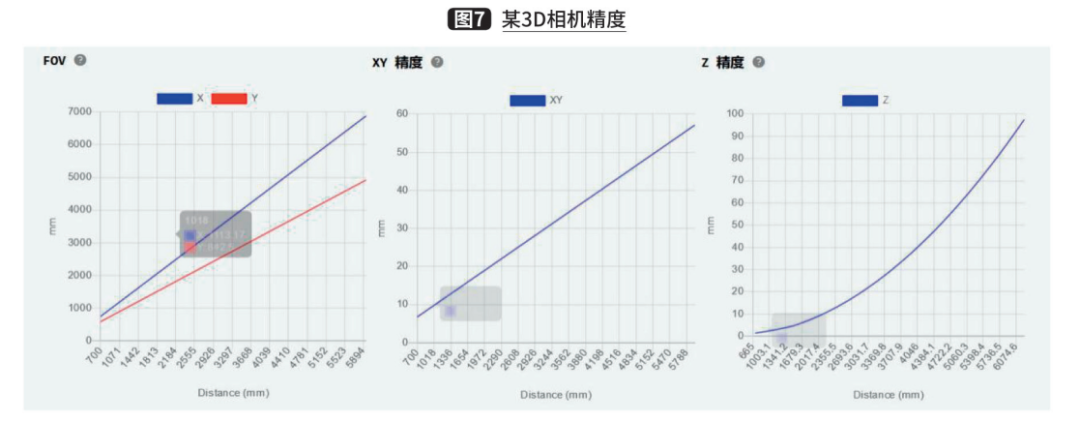
而根据价格不同,有不同的精度和范围。下面以某品牌的一款3D相机为例,参数如图6所示,精度如图7所示。

使用3D相机,可以获得特殊场景的RGB图像和深度图像,根据对这些图像(见图8)的处理和分析,可以获得一些关于场景里物体的位置、数量、信息。

图9的矩形框就是处理后识别出来的箱子抓取位置图。按左上、左下、右上、右下的顺序分别为“2、3、3、2”,即机器手会根据图像识别系统给的位置信息按左上两个箱子、左下三个箱子、右上三个箱子、右下两个箱子的顺序去抓取。

在本文中,我们对3D视觉引导的多品规物料机器人拆垛系统框架及常用方法进行了介绍,并定义了该框架需要具备的几个基本模块,即视觉信息获取模块、物体定位与分析模块、抓取位姿计算模块、手眼坐标转换模块、运动规划模块,并且对每个模块的主要任务和常用方法进行了说明。在实际应用中,可以根据需要使用不同的方法来实现这些模块,而不影响其他模块和系统整体的功能。








