绑定手机号
确认绑定









新华社北京2022年2月17日电,记者了解到,国家发展改革委、中央网信办、工业和信息化部、国家能源局近日联合印发文件,同意在京津冀、长三角、粤港澳大湾区、成渝、内蒙古、贵州、甘肃、宁夏启动建设国家算力枢纽节点,并规划了张家口集群等10个国家数据中心集群。至此,全国一体化大数据中心体系完成总体布局设计,“东数西算”工程正式全面启动。
当前,算力已成为全球战略竞争新焦点,是国民经济发展的重要引擎,全球各国的算力水平与经济发展水平呈现显著的正相关。在2020年全球算力中,美国占36%,中国占31%,欧洲和日本分别占11%及6%。近年来,美国、欧洲、日本纷纷制定行动计划,不断运用算力助推经济增长。
“数据、算法、算力”是数字经济时代核心的三个要素,其中算力是数字经济的物理承载。这里,我们通过“预见·第四代算力革命”系列文章(共四篇),从微观到宏观,详细分析跟性能和算力相关的各个因素以及主流的算力平台,尽可能地直面当前算力提升面临的诸多挑战和困难,展望面向未来的算力发展趋势。这四篇文章为:
预见·第四代算力革命(三):面向未来十年的新一代计算架构;
预见·第四代算力革命(四):宏观算力建设。
本文为第三篇,欢迎关注公众号,阅读历史以及后续精彩文章。
参考文献:
http://www.xinhuanet.com/tech/20220218/ca65a9090bb64c1a8ab9b004f290b17d/c.html,正式启动!“东数西算”工程全面实施
《2020全球计算力指数评估报告》,IDC & 浪潮
面向未来十年的新一代计算架构
算力,成为整个数字信息社会发展的关键。通过“东数西算”能缓解一些问题,但没有根本解决问题:当前要想提升算力,更多的是靠“摊大饼”的方式构建更加规模庞大的现代化数据中心。
这是算力提升的Scale out(增大规模),那么,我们如何能够做到算力的Scale up(提升单个计算节点的性能)?或者说,我们如何显著(数量级)的提高单个处理器的性能?
云计算,是从IaaS、PaaS到SaaS的丰富多彩的分层服务体系。云计算具有很多本质的、显著的特点,这些特点决定了云计算的内在发展规律:
超大的规模。AWS拥有超过400万台服务器,分布在全球22个地理区域和69个可用区。受规模的影响,数据中心需要自动化运维;因为VM/容器高可用,软件实体需要在硬件平台无缝迁移。这些需求,都需要软硬件具有非常好的交互接口一致性。同样,受规模的影响,任何一点细微的性能/成本优化,在百万级服务器的加持下,都会起到非常显著的效果。例如,单个服务器系统优化减少一个CPU核的消耗,对AWS来说,就意味着400万个CPU核的成本降低,这会直接转换成AWS的净利润。
大量的数据。2025年全球数据量175ZB,复合增长率27%,云端数据存储占比超过50%。数据量爆炸式的增长,这么多数据的产生、传输、处理、存储、分析、安全等等,都将对硬件的性能、带宽、延时、空间、功耗、成本等构成庞大的挑战。
复杂的网络。网络最关键的参数是带宽和延迟,但在超大规模的加持下,集中管理的快速网络变更成为一个关键的需求。并且,域间隔离和跨域访问等网络处理,都对网络处理的性能提出了更高的要求。
虚拟化和可迁移性。虚拟化是云计算的基础,虚拟化包括主机虚拟化、容器虚拟化以及函数虚拟化。虚拟化的本质目的是为了更好地资源隔离,以及提高资源利用率。目前,处理器平台只有CPU做到了足够好的硬件虚拟化支持,GPU和DSA的虚拟化能力还比较弱。为了实现VM/容器/函数的高可用,系统需要支持可迁移性,软件运行实体和硬件运行环境解耦。在性能要求极高的同时,要求硬件IO设备和加速器等的接口一致性。需要“抽象层”硬件加速技术来屏蔽硬件差异,使得VM高性能的同时,可在不同服务器间平滑迁移。
可扩展性和复杂系统解构。受限于单台服务器的处理能力,云计算通常通过横向扩展来提升系统的服务能力;并且各种云服务的架构逐渐微服务化,这些因素,都促使数据中心的东西向流量激增。云计算场景,是复杂系统解构的同时,多租户的更多系统共存。这些服务之间、租户之间、系统之间需要非常安全的隔离,避免相互干扰以及数据访问泄露等风险。
上面列出的云计算的鲜明特点,可以明显看出,云计算场景对软件系统运行的硬件平台,提出了非常多的高标准要求。总结来说,就是:越是复杂的场景,对灵活性的要求越高。而当前,只有CPU能够提供云场景所需的灵活性。CPU提供了灵活的软件可编程能力、硬件级别的通用性、更好的虚拟化支持以及更好的软硬件交互接口一致性等,这使得CPU成为了云计算等复杂计算场景的主力算力平台。
然而,很不幸的是,算力需求依然在提升,而CPU却遇到了摩尔定律失效。随着CPU的性能瓶颈,我们不得不采用GPU、DSA等计算平台,在这些计算平台,如何提供如CPU一样的软件灵活性,是软件和硬件的设计者需要核心关注的事情。
CPU是完全通用的处理器,通过最基本细分的简单指令组成的程序,可以完成几乎所有领域的任务处理。GPU,由于其并行计算的鲜明特点,在科学计算、图形图形处理、AI等领域具有非常大的优势。而DSA,则是要针对性能敏感场景,去定制处理器,只能覆盖单一的领域。这样,灵活性越高的处理器,其可以覆盖的领域也就越多。而覆盖的领域越多,也就意味着其可以实现更大规模的使用。
另一方面,即使在同一领域,不同用户的差异化(横向差异)以及用户系统的长期快速迭代(纵向差异),都对硬件的灵活性提出了很高的要求。而芯片的研发周期2-3年,生命周期4-5年。在长达6-8年的周期里,要想覆盖这么多的横向和纵向的差异化功能需求,就必然需要相对灵活可编程的平台。反过来说,要是提供了相对灵活可编程的平台,就可以覆盖尽可能多的用户需求和用户的长期迭代,这也就意味着处理芯片可以被更多的用户使用,从而形成更大的规模。
因此,灵活性和规模是基本正比的关系。越高的灵活性,就意味着处理芯片可以得到更大规模的商业化落地。

从“指令”复杂度的观点,我们可以得到:CPU最灵活但性能差,DSA相对固定但性能最好,GPU则位于两者之间。单个处理引擎,其性能和灵活性是矛盾的两面。获得了性能就会失去灵活性,获得了灵活性,就不得不损失性能。如上图,我们进行详细的说明:
需要特别强调的是,这里说的性能指的是同等资源规模情况下的相对性能。
Baseline,最低要求。Baseline的两条虚线代表了复杂计算场景对性能和灵活性的最低要求。这意味着,CPU能满足灵活性的要求,但无法满足性能的要求。而DSA/ASIC能够满足性能的要求,但无法满足灵活性的要求。GPU,相对均衡的设计,其性能和灵活性都无法满足复杂计算场景的需要。
Ideal,理想化的(可以接近,但难以完全达到)要求。最理想的结果是鱼和熊掌我们都要,既要CPU般极致的灵活性,又要DSA/ASIC般极致的性能。
CASH(Converged Architecture of Software and Hardware,软硬件融合架构)。这里我们定义软硬件融合架构CASH,其目标是实现接近于CPU一样灵活性的同时,又能够实现DSA/ASIC一样极致的性能。其基本原理是“物尽其用”,通过把CPU、GPU、FPGA、DSA、ASIC等多种计算引擎混合集成在一起,让“专业的人做专业的事”,分工协作,从而实现性能和灵活性的统一。
算力,是数字经济时代的核心生产力,是支撑数字经济发展的坚实基础。算力对推动科技进步、促进行业数字化转型以及支撑经济社会发展发挥重要的作用。算力与国家经济发展紧密相关,《2020全球计算力指数评估报告》中指出,算力指数平均提高1个点,数字经济和GDP将分布增长0.33%和0.18%。
根据IDC的报告,2018年中国产生的数据占全球23%,美国占21%。根据OpenAI的报告,全球AI训练对算力的需求扩大了30万倍。大数据、人工智能、物联网、区块链、元宇宙等新兴技术应用,是未来算力发展的核心推动力。正是因为数字经济时代,上层越来越丰富的应用场景,对算力源源不断的渴求,这样就需要:
持续不断的增加单个计算芯片/设备的性能(Scale up);
持续不断地增加云计算、边缘计算、自动驾驶车辆、智能终端等多层次计算设备的部署规模(Scale out和算力分层体系Hierarchy)。
前面我们提到,DSA的性能最好,虽然其灵活性差一些。但为了极致的性能,就不得不尽可能地选择DSA架构处理引擎。当然,为了确保灵活性,我们需要针对性地把系统进行拆解。
复杂的系统通常是个分层的体系。其底层工作任务相对固定,上层工作任务相对灵活。可以把底层的工作任务尽可能的运行在DSA,然后把上层的工作任务运行在CPU/GPU。
不过,把一些底层任务放在DSA,需要针对性地设计DSA引擎或芯片。而数据中心等场景超大的规模,使得任何一点细微的优化,在规模的影响下,都会产生非常大的效益。因此,这种针对性的DSA设计是值得的。
比较理想的状况,就是通过系统软硬件架构的优化设计,把90%以上(算力占比)的基础层工作任务都运行在DSA(DSA负责性能敏感但功能确定的任务),而把应用层少于10%的工作任务运行在CPU/GPU(CPU负责更高价值,性能不那么敏感,但需要更多灵活可编程性的任务)。这样,整个系统就可以很好地实现性能和灵活性的兼顾。
在《预见·第四代算力革命》的第一篇的时候,我们就已经提到了跟性能相关的四个因素(“指令复杂度”、运行频率、并行度和I/O),也讲到了通过工艺、存算一体、以及架构创新三类主要的手段来提升性能。三类手段和四个因素是垂直交叉的关系,通过多个不同视角,综合地阐述如何提升芯片的性能。
站在架构设计的角度:
我们要考虑整个系统的输入和输出,通过什么样的硬件接口,接口传输什么样的内容,以及通过什么样的上层接口协议;
还要考虑整个系统的分层分块,以及每个任务/模块间的交互;
还要考虑每个任务/模块的软硬件划分以及这些任务的运行平台;
并且要考虑内部总线互联和软件之间的接口调用。
业务需求、系统架构设计和半导体工艺/封装进步是相互驱动和影响的:
半导体工艺进步的价值,需要通过架构设计来“变现”。以CPU多核设计为例,一开始,多核只有2/4个,通过(相对)简单的Crossbar总线即可连接。当工艺进步,可以有很多的晶体管资源可以使用时,我们可以集成16甚至32核的时候,这个时候,CPU芯片的内部互联就通过Ring或者Mesh总线。
为了满足业务场景更高的要求,我们需要构建更大规模的系统架构设计;Chiplet封装技术的进步,这也使得我们有能力构建更大规模的系统架构设计。我们不但要定义Chiplet之间的互联总线,如何更好地实现把多个Chiplet芯粒连接成一个更大的芯片系统,还需要重新定义全新的系统架构。
因为存储分层体系越来越冗繁,访问数据的代价越来越高。不得不对存储分层进行优化,从而产生了存算一体化,存算一体化通过工艺、封装、架构设计等方式全方位的优化处理的性能以及处理和I/O的匹配。
等等。
总结一下,我们有很多性能优化的手段,但大多只能优化性能相关的部分因素。并且这些优化手段跟我们提供给软件开发者所可以用的更高性能的计算平台还有很大的距离。而系统架构则处于两者之间,负责统筹这些措施,把各种各样的性能优化措施,整合成用户可以方便使用的计算平台,从而实现计算平台的大规模化落地。
计算机发展到现在,其架构已经是非常的成熟。软件和硬件基本上是完全解耦,甚至形成了清晰而稳定的交互边界:
CPU是通过ISA来解耦软件和硬件,并且把软硬件之间的“接口”ISA标准化,所以才有x86、ARM和RISC-v三大架构之说;
GPU通过CUDA解耦了GPU软件开发和硬件设计,并且GPU和CUDA能够实现向前兼容。因为GPU CUDA的强大生态,NVIDIA才有了AI时代全球市值最高IC公司的成就。
而ASIC则几乎是一个纯硬件的设计,只是通过控制面实现简单的控制,并且这个控制面的接口还难以形成标准。可以认为ASIC设计没有做到软硬件划分的标准化。
有了先进工艺和先进封装,有了AI对算力的极度渴求,有了元宇宙整合虚拟和现实的各种先进的技术,等等。随着技术和需求的发展,使得整个系统变得更加的复杂,以元宇宙为例,其系统复杂度会是当前系统的千倍万倍。量变引起质变,如此高复杂度的系统,当前已有的软硬件体系肯定难以满足要求。要做的,就是打破已有的体系和边界,重新定义系统软硬件,通过再一次的软硬件相互“博弈”,形成新的架构和软硬件划分。并且,形成的新的架构和软硬件划分,依然有可能会快速地演进。
这个新的系统,一定是由很多个子系统构成的宏系统,一定是多种处理引擎混合共存。软件里有硬件,硬件里有软件,软硬件组成的子系统再整合成一个更大的宏系统。我们把这种情况定义为软硬件“融合”。
软硬件融合,不改变系统层次结构和组件交互关系,但打破软硬件的界限,通过系统级的协同,达到整体最优。
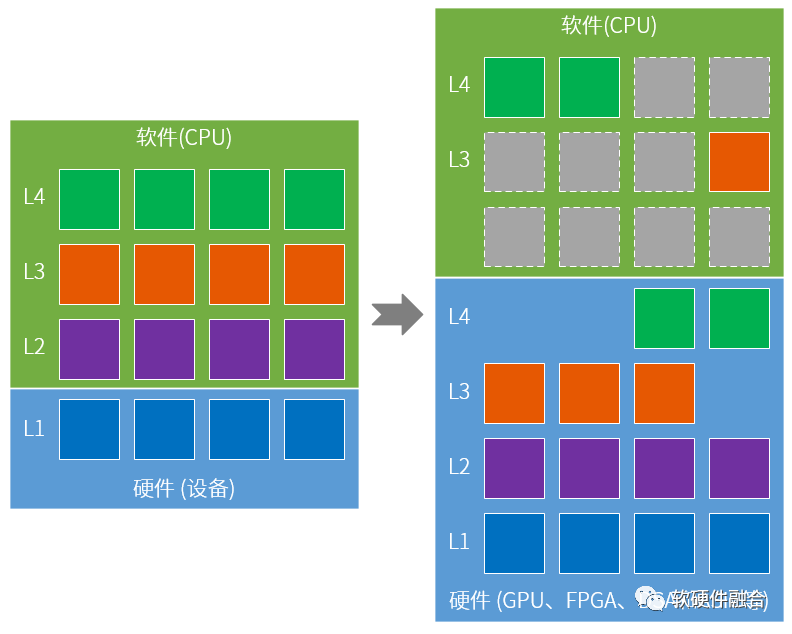
复杂的系统分层,越上层越灵活软件成分越多,越下层越固定硬件成分越多。为了持续的提升性能,则需要把系统中的任务尽可能的从CPU软件运行,转移到基于DSA更高效的硬件加速方式运行。复杂系统的底层任务逐渐稳定,并且宏观的超大规模,使得系统底层的任务适合逐步转移到硬件DSA。通过软硬件融合的优化设计,可以使得“硬件”更加灵活,功能也更加强大,可以让更多的层次功能加速向底层“硬件”转移。

(a) CPU组成的同构并行 | (b) CPU + GPU/FPGA/DSA的异构并行 |
当前,并行计算的主流架构上图所示,上图(a)为CPU同构并行:
常见的多核CPU和多路CPU通过板级互联组成的服务器,即是同构并行计算。CPU由于其灵活通用性好,是最常见的并行计算架构。但由于单个CPU核的性能已经到达瓶颈,并且单颗芯片所能容纳的CPU核数也逐渐到头。CPU同构并行已经没有多少性能挖潜的空间。
上图(b)为CPU+xPU的异构加速并行架构。一般情况下,GPU、FPGA及DSA加速器都是作为CPU的协处理加速器的形态存在,不是图灵完备的。因此,这些加速器都需要CPU的控制,CPU+xPU成为了典型架构。
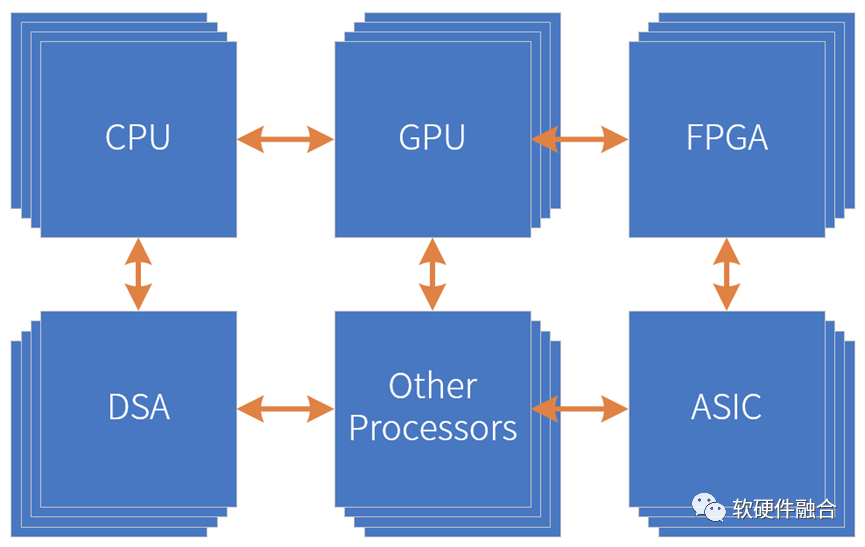
芯片工艺带来的资源规模越来越大,所能支撑的设计规模也越来越大,这给架构创新提供了非常坚实的基础。我们可以采用多种处理引擎共存,“专业的人做专业的事情”,来共同协作的完成复杂系统的计算任务。并且,CPU、GPU、FPGA、一些特定的算法引擎,都可以作为IP,被集成到更大的系统中。这样,构建一个更大规模的芯片设计成为了可能。这里,我们称之为“超异构计算”。如上图所示,超异构指的是由CPU、GPU、FPGA、DSA、ASIC以及其他各种形态的处理器引擎共同组成的超大规模的复杂芯片系统。
超异构计算本质上是系统芯片SOC(System on Chip),但准确的定义应该是宏系统芯片MSOC(Macro-System on Chip)。站在系统的角度,传统SOC是单系统,而超异构宏系统,即多个系统整合到一起的大系统。传统SOC和超异构系统芯片的区别和联系:
单系统还是多系统。传统的SOC,有一个基于CPU的核心控制程序,来驱动CPU、GPU、外围其他模块以及接口数据IO等的工作,整个系统的运行是集中式管理和控制的。而超异构DPU由于其规模和复杂度,每个子系统其实就是一个传统SOC级别的系统,整个系统呈现出分布式的特点。
以计算为中心还是以数据为中心。传统SOC是计算为中心,CPU是由指令流(程序)来驱动运行的,然后CPU作为一切的“主管”再驱动外围的GPU、其他加速模块、IO模块运行。而在超异构芯片系统中,由于数据处理带宽性能的影响,必须是以数据为中心,靠数据驱动计算。

GPU和CUDA都是硬件定义软件时代的产物。GPU平台,硬件的GPGPU提供接口给CUDA,CUDA再提供接口给应用。CUDA框架有特定的驱动和HAL屏蔽不同GPU的实现细节;并且CUDA为了向前兼容和维护生态,最终映射到标准的库。这些标准的库,提供了标准的接口给上层的CUDA应用程序。

当前,进入了软件定义硬件的时代。以云计算场景为例,许多用户场景的服务已经存在,只是这些服务以软件的形式运行在CPU。受限于CPU的性能瓶颈,使得软件的性能无法进一步提升,因此需要通过硬件加速的方式来继续提升性能。
但是,服务已经稳定运行很久的时间,并且已经服务成千上万的上层用户。云计算提供商肯定很难把整个服务从CPU迁移到DSA等加速处理引擎。另外一方面,不同厂家的DSA呈现的都是不同的访问接口,如果迁移,这也会导致对芯片供应商的依赖。因此,需要硬件通过软件(或者硬件)的方式,给云计算提供商提供一致的标准访问接口。
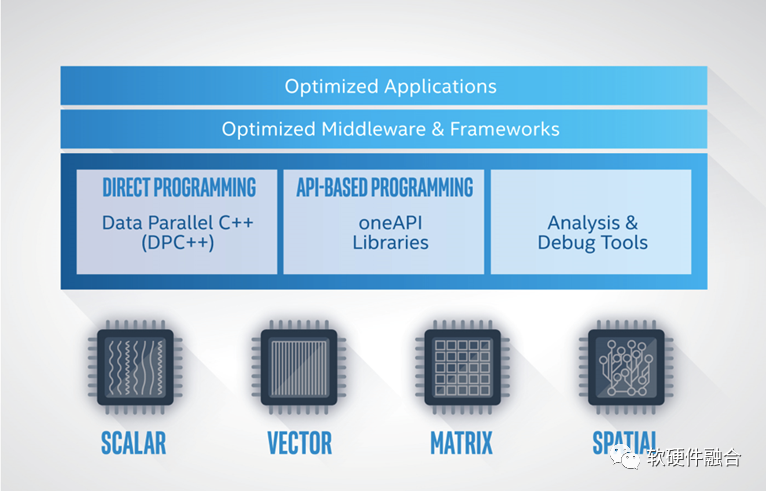
英特尔oneAPI是一个开放、可访问且基于标准的编程系统,支持开发人员跨多种硬件架构参与和创新,包括 CPU、GPU、FPGA、AI 加速器等。这些处理引擎具有非常不同的属性,因此用于各种不同的处理——oneAPI试图通过将它们统一在同一个模型下来简化这些操作。
即使在今天,开发人员面临的一个持续问题是我们日益数字化的世界提供的编程环境的数量。不同的编程环境使代码重用等节省时间的策略失效,并成为软件开发人员的真正障碍。作为其软件优先战略的一部分,英特尔在 2019 年的超级计算活动中推出了oneAPI。该模型标志着英特尔的雄心是拥有统一的编程框架作为限制专有编程平台的解决方案。oneAPI 使开发人员能够在不厌倦使用不同语言、工具、库和不同硬件的情况下工作。
Intel oneAPI可以实现:设计一套应用,根据需要,非常方便地把程序映射到CPU、GPU、FPGA或者AI-DSA/其他DSA等不同的处理器平台。

我们把oneAPI模型框架再增强一下,如上图所示。这样,跨平台,不仅仅是在CPU、GPU、FPGA和DSA的跨平台,更在于是不同Vendor的不同处理器的跨平台。
在终端场景,软件通常附着在硬件之上,两者是绑定的。我们可以通过如HAL一样的抽象层来实现平台的标准化,然后再部署操作系统和应用软件。而在云端,VM、容器和函数都是一个个软件运行实体,可以在不同的硬件上迁移,这就使得软件和硬件是完全分开的。这也就需要硬件提供非常好的平台一致性。
不同厂家,不同处理引擎,给软件抽象出一致的接口,使得软件可以非常方便地在不同处理引擎之间迁移。从而,大家合作,共建出标准的、开放的一整套软硬件生态。
在《预见·第四代算力革命》的第二篇里,我们从性能、资源效率、灵活性和软件生态四个方面,分析总结了CPU、GPU和DSA的优劣势。在本篇里,我们经过上述各种分析之后,我们给出面向未来十年的新一代计算架构的一些设计目标——基于软硬件融合架构(CASH,Converged Architecture of Software and Hardware)的超异构计算:
性能。让摩尔定律继续,性能持续不断地提升。相比GPGPU,性能再提升100+倍;相比DSA,性能再提升10+倍。
资源效率。实现单位晶体管资源消耗下的最极致的性能,极限接近于DSA/ASIC架构的资源效率。
灵活性。给开发者呈现出的,是极限接近于CPU的灵活性、通用性及软件可编程性。
设计规模。通过软硬件融合的设计理念和系统架构,驾驭10+倍并且仍持续扩大的更大规模设计。
架构。基于软硬件融合的超异构计算:CPU + GPU + DSA + 其他各类可能的处理引擎。
生态。开放的平台及生态,开放、标准的编程模型和访问接口,融合主流开源软件。

计算 范式 | 核心 器件 | 算力 比较 | 通用性 比较 | 优势 | 问题 |
第一代 | CPU | x1 | 100 | 极度灵活可编程。 | 效率最低,性能已经瓶颈。 |
第二代 | GPU | x10+ | 10 | 相比CPU的性能优势,相比DSA/ASIC的通用灵活性,应用领域更加广泛。 | 效率相比DSA/ASIC不高,性能即将到顶。 |
—— | ASIC | x100+ | 1 | 极致性能 | 灵活性最低,完全定制的方案,用户难以差异化,难以大规模。 |
第三代 | DSA | x100+ | 5 | 接近于ASIC的极致性能,并且具有一定的可编程能力。 | 同一领域,应用的算法依然多种多样,并且快速迭代,应用层(如AI)DSA难以大规模落地。 |
第四代 | CASH | x1000+ | 100 | l超异构:CPU+GPU+DSA+其他;更大规模,更大算力。 l软硬件融合架构:CPU软件一样灵活可编程,DSA/ASIC硬件一样极致的性能。 l开放的平台及生态:开放、标准的编程模型和访问接口,融合主流开源软件。 | |









