绑定手机号
确认绑定









导读
近年来,Transformer在视觉领域吸引了越来越多的关注,随之也自然的产生了一个疑问:到底CNN和Transformer哪个更好?当然是强强联手最好。华为诺亚实验室的研究员提出一种新型视觉网络架构CMT,通过简单的结合传统卷积和Transformer,获得的网络性能优于谷歌提出的EfficientNet,ViT和MSRA的Swin Transformer。论文以多层次的Transformer为基础,在网络的层与层之间插入传统卷积,旨在通过卷积+全局注意力的方式层次化提取图像局部和全局特征。简单有效的结合证明在目前的视觉领域,使用传统卷积是提升模型性能的最快方法。在ImageNet图像识别任务,CMT-Small在相似计算量情况下Top-1正确率达83.5%,远高于Swin的81.3%和EfficientNet的82.9%。

论文链接:https://arxiv.org/abs/2107.06263
PyTorch代码:https://github.com/huawei-noah/Efficient-AI-Backbones/tree/master/cmt_pytorch
MindSpore代码:https://gitee.com/mindspore/models/tree/master/research/cv/CMT
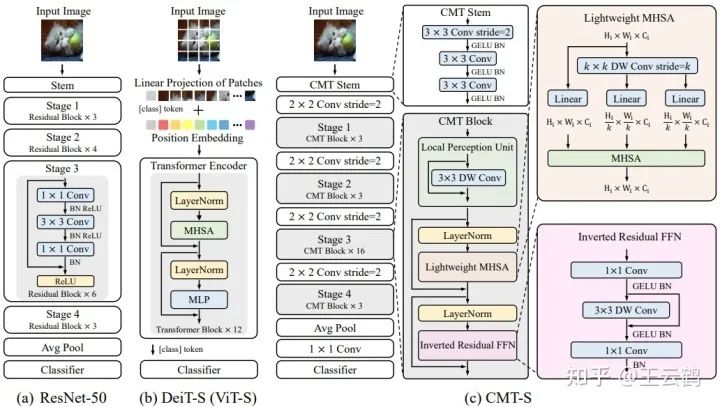
Transformer的诞生推动自然语言处理网络的进步和发展,受此启发,transformer近年来开始在计算机视觉领域崭露头角。谷歌学者提出的Vision Transformer(ViT)模型是一个经典的用于视觉任务的纯transformer技术方案。它将输入图片切分为若干个图像块(patch),每个patch利用一个向量(vector/tensor)来表示,用transformer来处理图像patch序列,最终输出的特征可以直接用来进行图像识别、检测等。例如DETR使用基于transformer的图1 ResNet-50/ViT/CMT架构对比
编码-解码器来进行目标检测,IPT利用单个transformer模型同时处理多个底层视觉任务。与之前的传统CNN模型(如ResNet)相比,transformer依靠其全局的注意力机制能够捕获patch间的长距离依赖关系,在需要大感受野的检测、分割等视觉任务中表现出色。
但相比于NLP任务,视觉任务的输入因其特有的2D结构,输入表征变化更加复杂,patch间的局部空间信息也非常重要。因此现有的视觉transformer的缺点也十分明显,在将输入图像patch化的过程中,图像块内部结构信息将被破坏,而且长程的注意力机制很容易忽略图像的局部特有性质,导致现有的transformer的效果不如SOTA的传统卷积网络。
本文的目标就是将CNN的优点结合到Transformer中,以解决上述问题。我们提出了一个全新的架构CMT,基于层级结构(stage-wise)的transformer,引入卷积操作进行细粒度特征提取,同时也设计了独特的模块层次化提取局部和全局特征。既提高了性能,也节省了计算开销。在ImageNet基准测试和下游任务上的实验表明了该方法在精度和计算复杂度方面的优越性。例如,CMT-Small仅用4.0B FLOPs就达到了83.5%的ImageNet top-1正确率,这比计算量更大的Swin Transformer高出了2.2%。
图像预处理
大多数以transformer为基础的模型会利用一个大卷积(如ViT中的16x16卷积核)直接将输入图像切成不重叠的patch,这种做法直接失去了patch中的2D空间特征以及很多细节和边缘等信息。因此CMT采用传统的Conv stem结构,利用多个3x3卷积堆叠而成的结构来达到下采样及提取细节特征的目的。为了提取到多尺度特征(契合目前主流的检测器),CMT的主体结构采用stage-wise的Transformer,每个stage前均使用2x2 stride2的卷积进行下采样和增加通道数。
CNN和Transformer结合的CMT模块
LPU(local perception unit)局部感知单元:
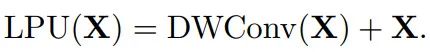
旋转和平移是CNN中常用的增广方法,然而在ViT中通常采用绝对位置编码,每个patch都对应一个唯一位置编码,因此无法给网络带来平移不变性。我们的局部感知单元采用3x3的深度分离卷积,将卷积的平移不变形引入Transformer模块,并利用残差连接稳定网络训练:
LMHSA(lightweight multi-head self-attention)轻量级多头注意力:
给定一个大小为Rn×d的输入,原始的多头注意力机制首先会生成相应的Query、Key和Value(和原始输入大小一致),再通过点Query和Key的点积,生成一个大小为Rn×n的权重矩阵:

这个过程往往会由于输入特征尺寸较大,而耗费大量的计算资源(显存),给网络的训练和部署带来难度。我们利用两个kxk的深度分离卷积分别对Key和Value的生成进行降采样处理,获得两个相对较小的特征K’和V’:
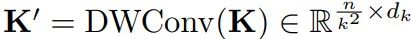
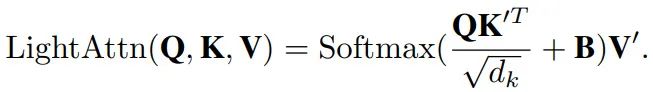
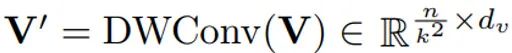
在Self-Attention模块中引入深度可分离卷积对特征图进行下采样,是一种节省计算量和显存的高效方法。
IRFFN(inverted residual feed-forward network)反向残差前馈网络:
该部分的前馈网络相比传统transformer的FFN,在两层全连接层之间加入了深度可分离卷积层,其中的设计类似MobileNetV2中的inverted residual block:
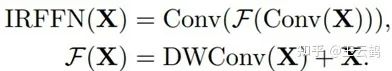
CMT整体架构
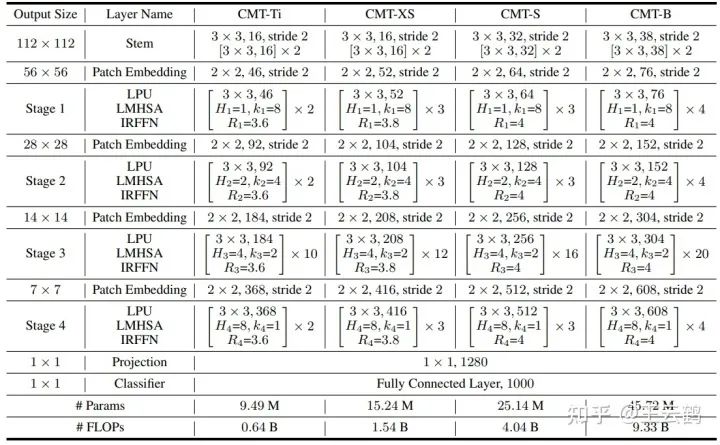
CMT网络主要由CMT(Conv) Stem,四个下采样层,四个Stage,池化层和全连接分类器组成,其中每个Stage由若干个CMT Block堆叠构成。具体结构如表1所示,其中Hi和ki 分别是轻量级多头注意力模块的头部数量和下采样率,Ri是反向残差前馈网络中间层通道的扩增倍数。
CMT系列网络族
类似EfficientNet的放缩模型的规则,我们针对CMT用亿点点grid search搜索了最佳的放缩系数,α=1.2, β=1.3, and γ=1.15,放缩公式如下:

我们以CMT-Small为基础,利用上述放缩公式得到了相应的CMT-Ti,,CMT-XS和CMT-B。这些模型对应的ImageNet输入大小分别为160x160,192x192,224x224(CMT-S)和256x256。
ImageNet实验
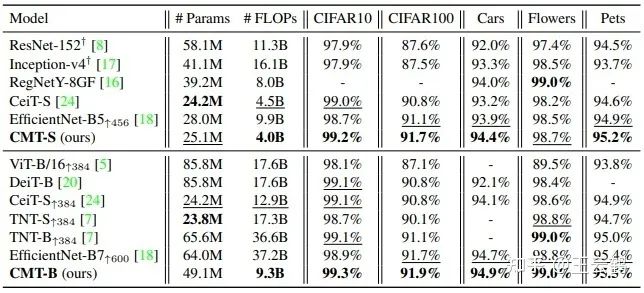
我们在ImageNet 2012数据集上训练和验证CMT模型。从表2可以看出,不论是新兴的transformer模型,或者是传统的CNN模型,CMT都有显著的性能优势。在只需要4.0B的计算量下,CMT-S达到83.5%的top-1精度,比基线模型Swin-T高2.2%,这表明在tranformer模型中引入传统卷积有利于模型更好的提取和保留局部结构信息。
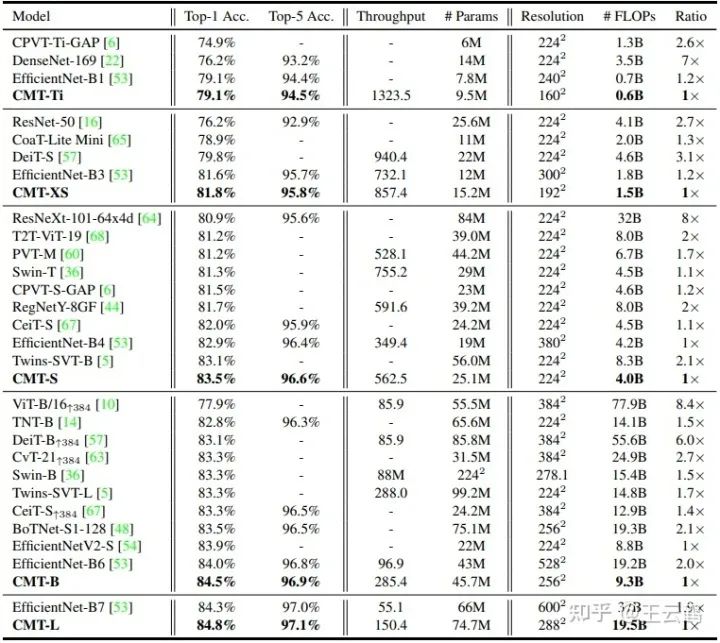 在ImageNet数据集和SOTA模型对比
在ImageNet数据集和SOTA模型对比迁移学习实验
 CMT在下游任务的表现
CMT在下游任务的表现为了证明CMT具有很强的泛化能力,我们将在ImageNet上训练的CMT-S、CMT-B模型迁移到其他数据集。更具体地说,在5个图像分类数据集上评估CMT模型,包括CIFAR-10、CIFAR-100、Stanford Cars、Oxford 102 Flowers和Oxford IIIT Pets。所有模型微调的图像分辨率为224x224。表3比较了CMT与EfficientNet、DeiT、TNT等网络的迁移学习结果。
目标检测和实例分割实验
表4和表5分别展示了CMT-S在不同框架(如RetinaNet和Mask R-CNN)不同检测任务上的结果。在相似的计算量约束下,CMT-S相比其他的网络在性能上有大幅度的提升。
 CMT在COCO数据集目标检测任务的表现
CMT在COCO数据集目标检测任务的表现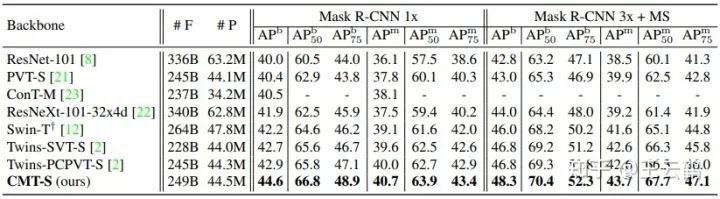 CMT在COCO数据集实例分割任务的表现
CMT在COCO数据集实例分割任务的表现本论文提出了一种CNN和Transformer结合的的通用视觉模型:CMT。在现在这个CNN、Transformer、MLP多种视觉基础框架如雨后春笋般被提出的年代,每当一种新型架构/模块被提出,研究员们不得不在各自的任务/领域上一个个试验这些结构是否能带来效果上的提升。本文简洁有效的证明:在视觉领域中传统卷积和Transformer结合有着1+1>2的效果。我们以目前火热的Transformer为基础,在经典的ViT结构上引入由3x3卷积组成的Conv Stem,以及由Depth-wise 卷积和自注意力机制组合而成的CMT模块,在几乎不增加FLOPs的情况下,大幅度提升视觉网络的现有精度。在ImageNet和下游任务上的大量实验都证明了所提出的CMT架构的优越性。








