绑定手机号
确认绑定









情感识别是人工智能一项重要的研究方向,在人机交互、心理健康等多个领域都有重要应用价值。而传统的视觉大语言模型(VLLMs)在情感识别方面仍面临着诸多挑战。在情绪识别时需要通过裁剪人脸的方式实现,这种方式可能丢失重要的上下文信息,从而影响识别准确率。
为此,澳大利亚国立大学联合耶鲁大学等提出一种基于视觉提示的多模态情感识别方法Set-of-Vision(SoV),该方法通过整合空间信息(如人脸关键点和边界框)来增强零样本情绪识别,从而提高人脸检测的准确性和情绪分类能力。与SoV相关的论文成果收录于EMNLP Main 2024。其中,澳大利亚国立大学工程与计算机科学学院在读博士王志丰为论文共同一作,。

相较于传统方法需要剪裁人脸,SoV方法直接标注人脸区域,能够保留背景信息并增强情绪分析。该方法专注于零样本情感识别,即在没有大量标注数据的情况下,也能通过视觉提示直接引导模型进行情感分类。
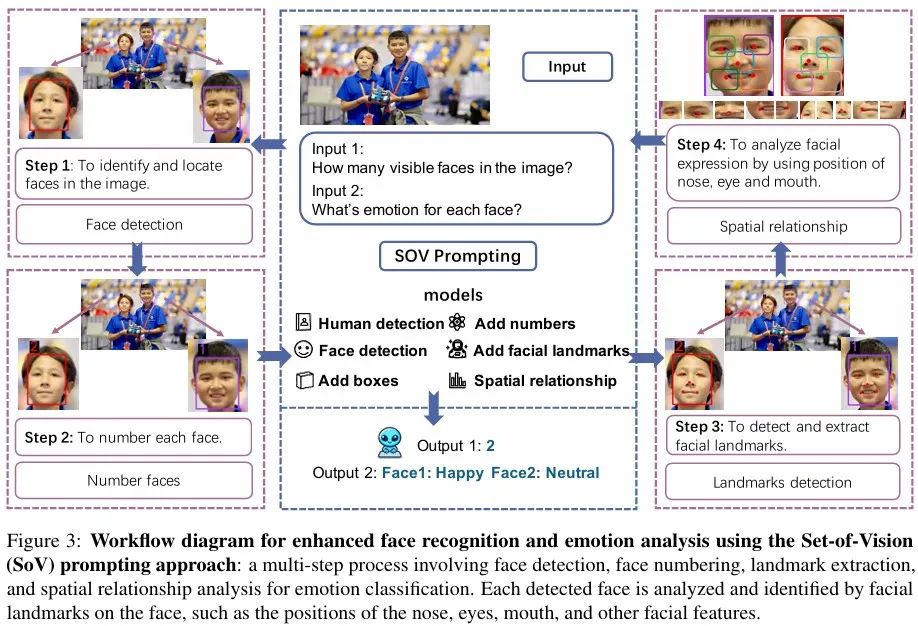
通过在多个情感识别数据集上进行实验,包括文本情感分析数据集多模态情感识别数据集。实验结果表明,视觉提示显著提升了情感识别的准确性,与仅使用文本信息的基线模型相比,在情感分类任务中的准确率提高了5%-10%;且多模态融合效果优于单一模态。该项研究有望显著提升情绪识别系统在自然环境中的表现,为 VLLMs 在现实世界应用中开辟新的可能性。
2月21日晚7点,智猩猩邀请到论文共一、澳大利亚国立大学在读博士王志丰参与「智猩猩AI新青年讲座」第263讲,以《SoV视觉提示方法增强VLLMs情感识别能力》为主题带来直播讲解。
讲者
王志丰,澳大利亚国立大学在读博士
2021 年毕业于澳大利亚国立大学,获得计算机视觉与机器学习硕士学位。目前,我正在澳大利亚首都领地堪培拉的澳大利亚国立大学工程与计算机科学学院攻读博士学位,研究方向为计算机视觉与机器学习。我的研究旨在探索和推进计算机视觉与自然语言处理的交叉领域,特别是在视觉大语言模型(VLLMs)方面。我开发了一种 Set-of-Vision(SoV)提示方法,这项研究有望显著提升情绪识别系统在自然环境中的表现,为 VLLMs 在现实世界应用中开辟新的可能性。
第 263 讲
主 题
《SoV视觉提示方法增强VLLMs情感识别能力》
提 纲
1、视觉大语言模型在CV与NLP中的应用
2、大语言模型在情感识别任务中面临的挑战
3、基于视觉提示的多模态情感识别方法SoV
4、在不同VLLMs上验证SoV方法情绪识别的准确率
直 播 信 息
直播时间:2月21日19:00
成果
论文标题
《Visual Prompting in LLMs for Enhancing Emotion Recognition》
论文链接
https://arxiv.org/abs/2410.02244
项目地址
https://wangzhifengharrison.github.io/sov_prompts_emnlp
收录情况
EMNLP Main 2024
如何报名
有讲座直播观看需求的朋友,可以添加小助手“小双”进行报名。已添加过“小双”的老朋友,可以给“小双”私信,发送“ANY263”进行报名。对于通过报名的朋友,之后将邀请入群进行观看和交流。










