绑定手机号
确认绑定









智猩猩AI整理
编辑:没方
随着大语言模型(LLM)规模的快速增长以及对长上下文推理需求的日益增加,内存已成为GPU加速LLM服务中的关键瓶颈。尽管GPU上的高带宽内存(HBM)提供了快速访问能力,但其有限容量使得系统必须依赖主机内存(CPU DRAM)来支持大规模KVCache。然而,DRAM的最大容量受限于每个CPU插槽有限的内存通道数量。为突破这一限制,现有系统通常采用基于RDMA的分离式内存池方案(disaggregated memory pools),但这带来了高访问延迟、复杂通信协议和同步开销等严峻挑战。
为此,来自阿里云的研究团队提出一种新颖的内存架构Beluga,使GPU和CPU能够通过CXL交换机访问共享的大规模内存池。基于Beluga架构,研究团队设计了优化LLM推理过程大规模KVCache管理的Beluga-KVCache系统。实验表明,与基于RDMA的MoonCake相比,Beluga-KVCache的首Token延迟(TTFT)降低了89.6%,vLLM吞吐量提升了7.35倍。Beluga是首个支持GPU通过CXL交换机直接访问大规模内存池的系统,标志着GPU实现低延迟访问海量内存共享资源的重要一步。

论文标题:
Beluga: A CXL-Based Memory Architecture for Scalable and Efficient LLM KVCache Management
论文链接:https://arxiv.org/pdf/2511.20172
01 方法
为了克服RDMA的局限性,研究团队提出 Beluga,这是一种利用CXL交换机构建可扩展共享内存池的架构。该架构使GPU能够通过简单的加载/存储操作访问共享内存池,从而解决了RDMA方法中存在的性能瓶颈和编程复杂性问题。
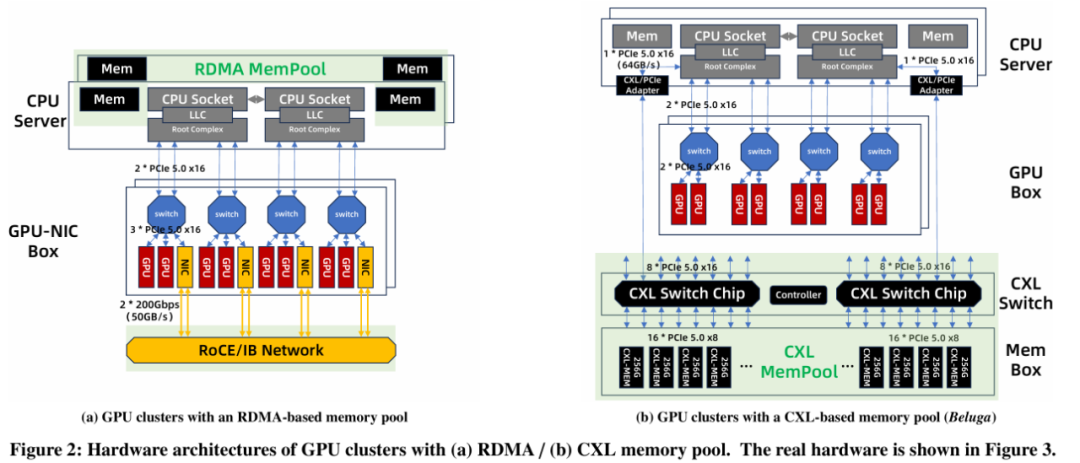
如图2b所示,该架构将原本的四个专用RDMA网卡替换为两个PCIe/CXL适配器,Beluga的硬件部署结构如图3所示。
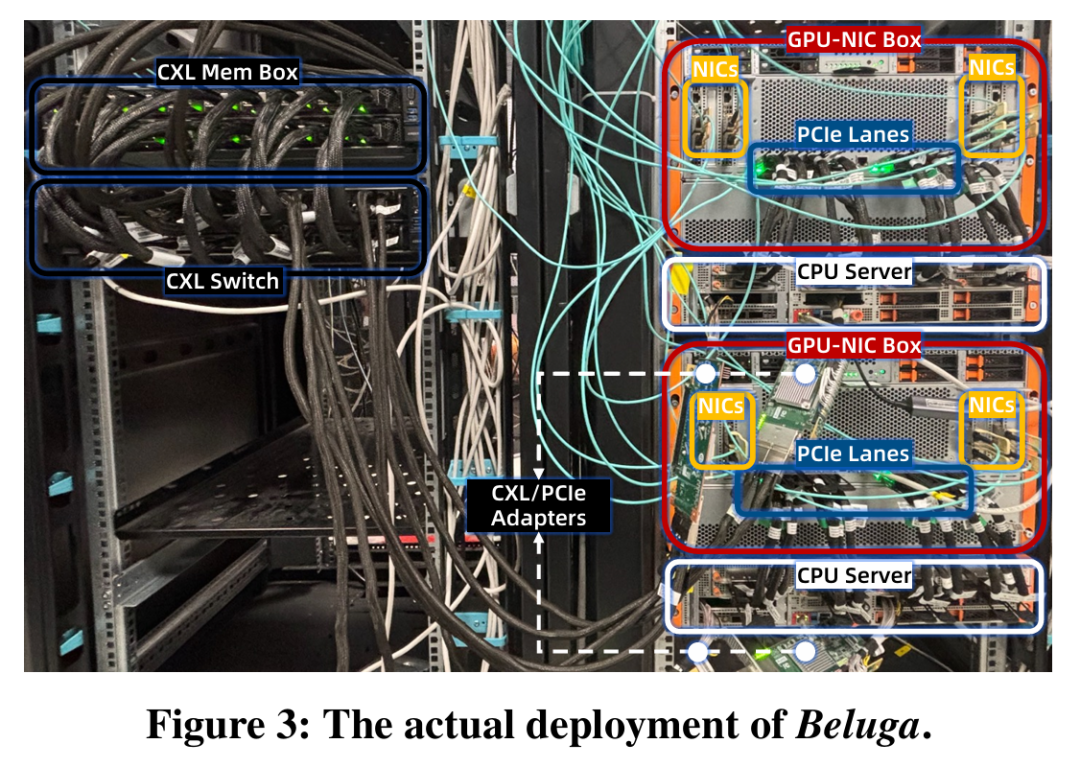
每台服务器配备两个CPU 插槽(NUMA 架构),每个插槽通过一个PCIe 5.0x16的PCIe/CXL适配器连接到CXL交换机。CXL内存池本身由一个交换节点和一个独立的内存盒组成。交换机的核心部分配备了两颗芯片(XConn XC50256),每颗芯片通过256条PCIe 5.0通道提供2TB/s 的转发能力。这些通道通常在CXL内存设备与计算服务器之间均匀分配。底层的CXL交换机最多可连接16台服务器,形成一个总带宽达1TB/s的8TB内存池。这种连接方式使Beluga能够通过其内部地址映射和转发逻辑支持多主机并发访问。
通过将内存访问范式从网络协议RDMA转变为具有内存语义的接口CXL,Beluga相比基于RDMA的方法提供了若干优势:
(1)性能提升
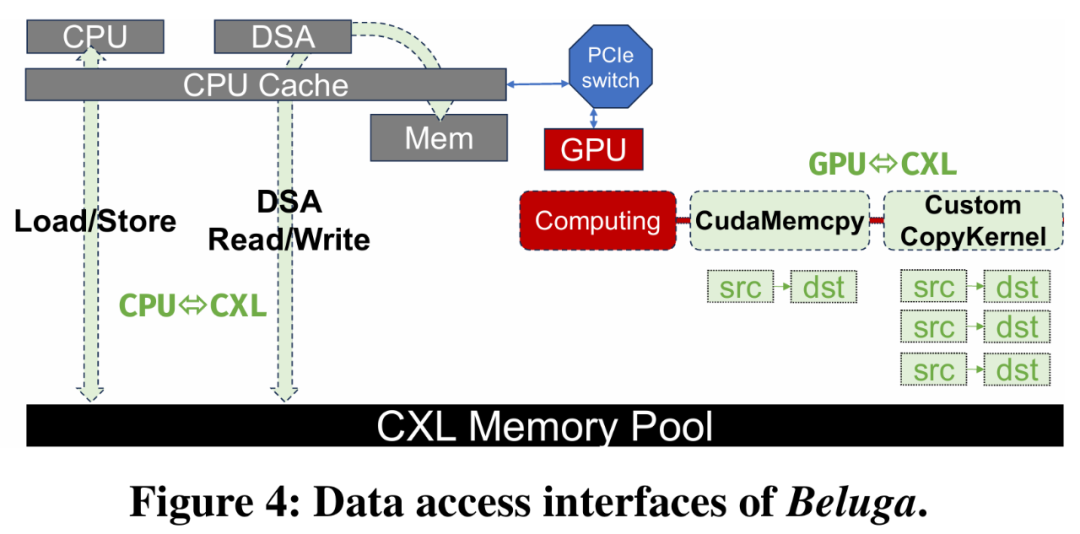
如图4所示,Beluga为CPU和GPU提供了标准的数据访问接口。
对于CPU,Beluga支持:
通过加载/存储指令能够直接访问内存;
使用英特尔数据流加速器(Intel Data Streaming Accelerator, DSA)进行硬件加速传输。
对于GPU,Beluga支持:
通过cudaMemcpy API进行直接点对点(P2P)传输;
通过自定义CUDA内核实现细粒度、非连续访问。
与RDMA相比,这些方法在数据和控制路径上都提供了直接的性能增益。
在数据路径上,Beluga允许GPU直接访问全局内存池,消除了由 CPU 驱动的 RDMA 所需的多级数据路径和跳转缓冲区,从而显著降低了延迟。
在控制路径上,Beluga中的数据传输内核可无缝集成到GPU原生的CUDA流,消除了CPU驱动和GPU驱动RDMA所固有的昂贵跨组件同步,从而避免了与外部CPU协调或内部GPU轮询相关的开销。
(2)系统简化除了性能提升外,Beluga还简化了系统。这些优势体现在更易访问的编程模型、简化的内存管理以及降低的硬件成本上。
在编程模型上,数据访问接口类似于本地DRAM的接口。因此,开发人员无需管理基于RDMA内存池所需的低级网络栈、复杂的工作请求准备及性能优化。此外,消除GPU跨组件同步开销简化了数据传输与计算之间的协调。
在内存管理上,Beluga提供了简化空间控制的统一地址空间。启动期间,每个主机上的BIOS检测到连接的CXL设备,并为它们保留一个连续的物理地址空间。随后,Beluga让每个主机以直接访问(DAX)模式管理CXL内存池。在这种模式下,CXL内存被暴露为块设备,允许用户空间进程使用mmap()直接将其整个内存区域映射到其虚拟地址空间。这种直接映射机制是资源分区和数据共享的关键。建立在Beluga之上的应用程序可以为不同的主机分配不同的内存偏移量以实现逻辑资源分区,或者让多个主机映射同一区域以实现高效的数据共享。重要的是,这种方法提供了所有服务器之间统一的内存视图,便于简单高效的内存管理。
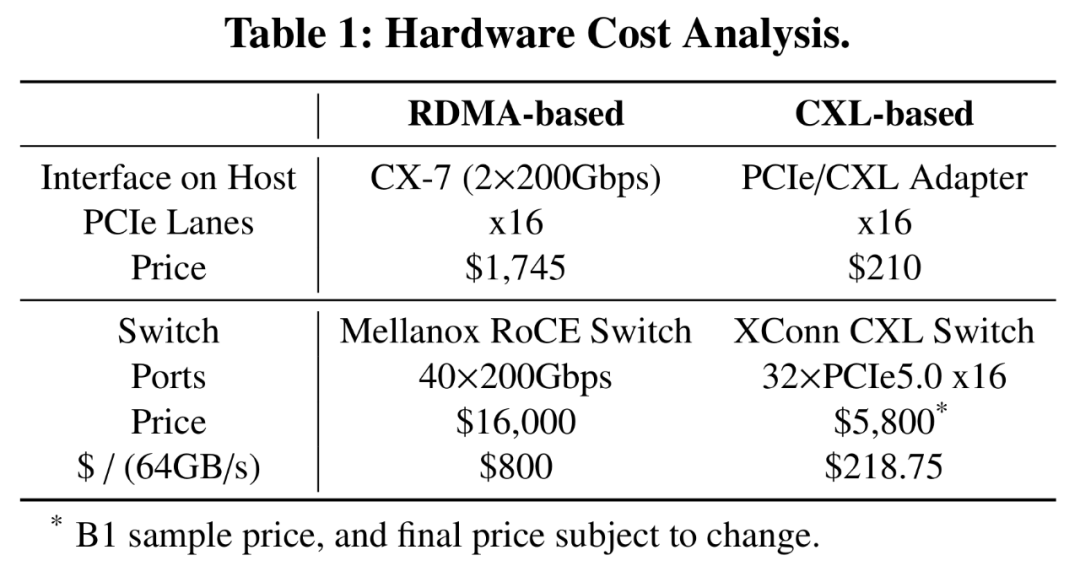
在硬件成本上,高速网络硬件(例如400Gbps网卡)常为了LLM推理的典型带宽需求而过度配置。因此,用更具成本效益的CXL组件替换昂贵的RDMA网卡可以显著降低总成本。如表1所示,
基于CXL的方法在设备级别降低了主机接口卡和交换机的成本。
对于内存设备,不同于主机中的传统DIMM内存,CXL内存设备可以使用密度较低的芯片,从而减少每GB的成本。
在系统层面,CXL内存池将内存与CPU资源分离,允许多台服务器共享内存并提高云环境中的利用率。
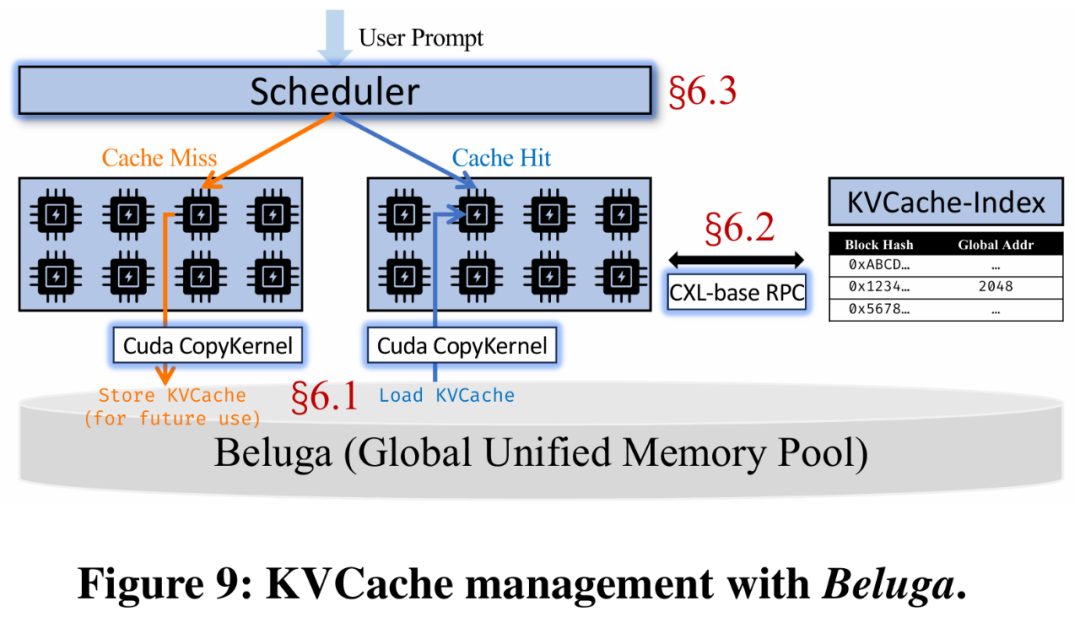
研究团队将Beluga集成至主流的LLM推理框架vLLM,并高效管理相应的KVCache。如图9所示,典型的LLM推理系统包含三个核心组件:
用于存储 KVCache 的大型共享内存池;
将token块映射到该内存池中的物理地址全局索引;
用于将请求分发到不同LLM实例的中央调度器。
Beluga-KVCache 集成了上述所有组件。首先,它将Beluga引入KVCache管理组件,通过CXL提供的直接内存访问接口大幅简化KVCache的访问流程。其次,Beluga-KVCache 利用基于CXL的远程过程调用(Remote Procedure Call,RPC)替代原有 LLM 实例与索引服务之间的网络通信。最后,得益于Beluga-KVCache 中更扁平的内存层次结构,调度器无需再关注 KVCache 的局部性,可专注于计算资源分配优化。
02 评估
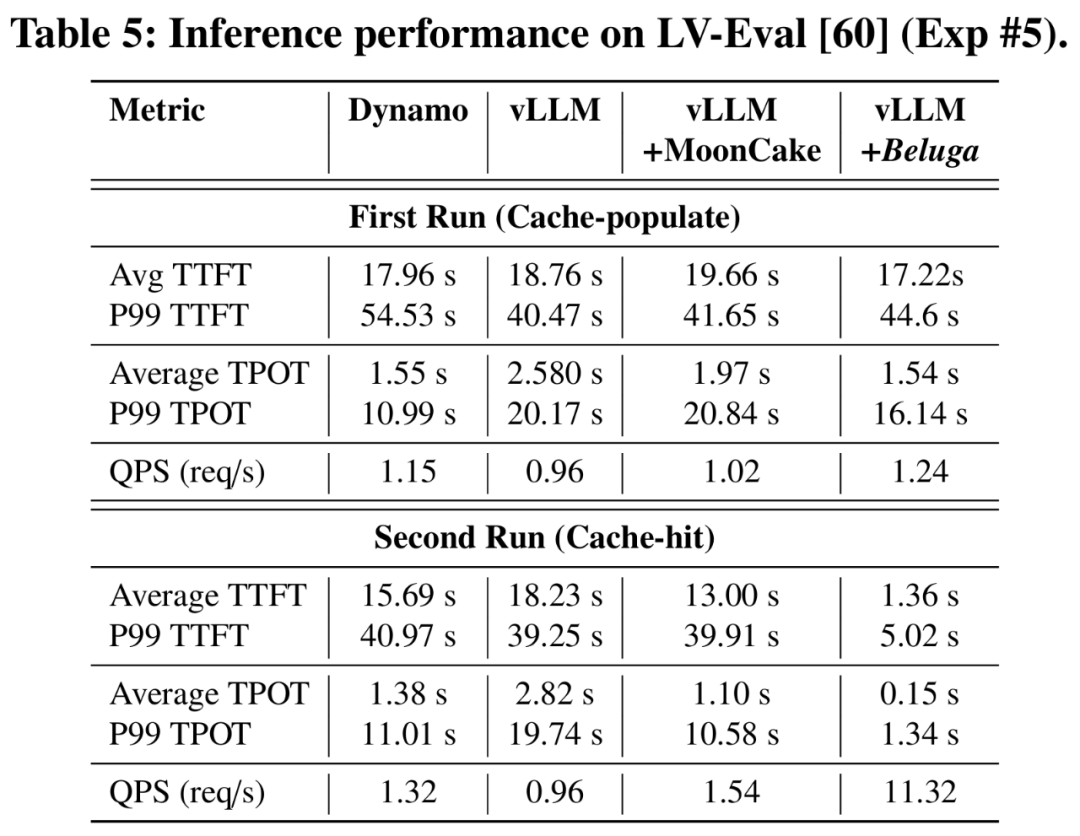
如表5所示,Beluga-KVCache在所有指标上均稳定优于基于RDMA的方案。在缓存填充(cache-populate)场景下(工作负载的缓存命中率为 30%),MoonCake和Beluga-KVCache均优于原始vLLM。值得注意的是,Beluga-KVCache相较于MoonCake进一步提升了性能,平均TTFT降低了12.4%,并将QPS提高了21.5%。在缓存命中(cache-hit)场景下性能优势更明显,Beluga-KVCache将平均TTFT降低了89.6%,并实现了 7.35倍的QPS提升。
为评估Beluga在真实场景下的性能,研究团队设计了两种测试工作负载,分别改变了请求到达速率和输入长度。
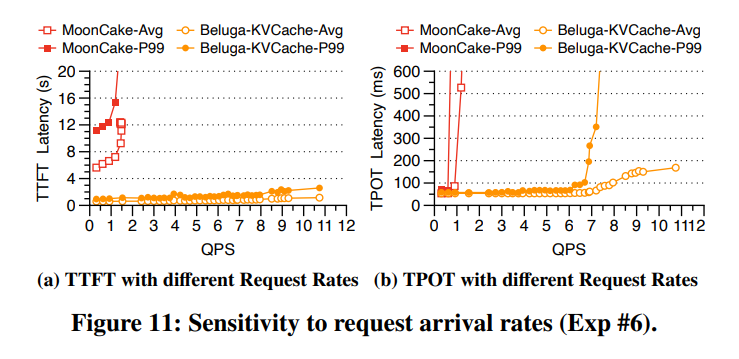
图11展示了TTFT和TPOT(每输出 token 时间)的结果。可以观察到,Beluga-KVCache 始终优于MoonCake,两项指标的延迟均更低。这是因为在第二次运行时所有请求均命中缓存,KVCache的读取时间成为系统的主要瓶颈。在此缓存受限场景下,Beluga基于CXL的数据访问方式显著优于MoonCake所采用的基于RDMA的访问方式。
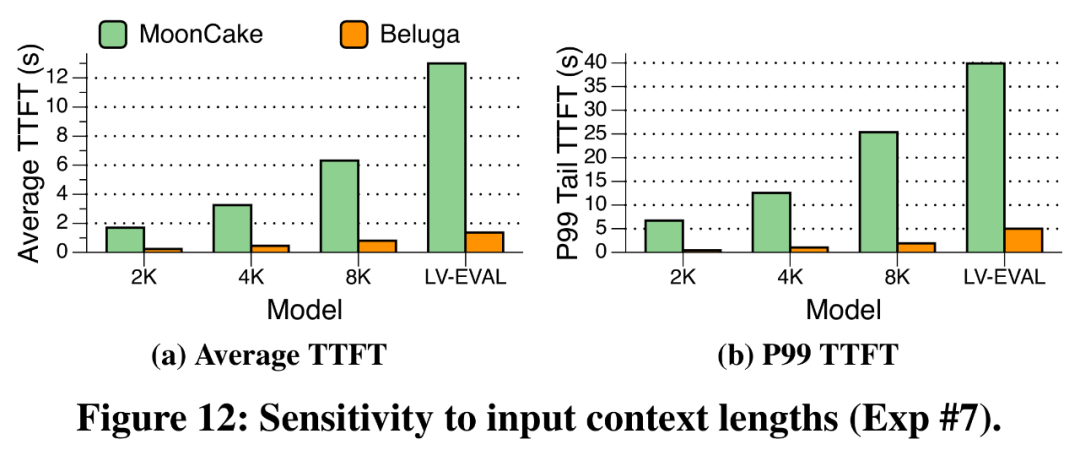
研究团队通过限制原始LV-EVAL数据集的输入长度,构建了上下文长度分别为 2K、4K 和 8K 的工作负载来评估系统。图12展示了 Beluga-KVCache 与 MoonCake 的平均 TTFT 和 P99 TTFT。可以发现,随着输入 token 数量的增加,Beluga 的性能优势更加明显。这是因为在长上下文场景,KVCache 的写入/读取时间在端到端延迟中所占比例更大。
Beluga 在不同推理框架配置下的性能如图13所示,重点关注两个方面:Prefill-Decode 解耦部署和 KVCache 块大小配置。
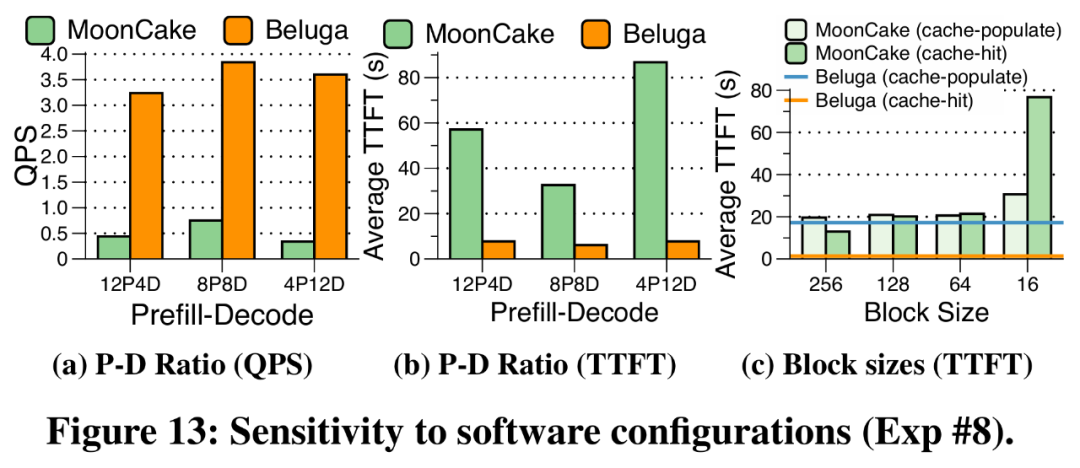
在 Prefill-Decode 解耦架构中,KVCache首先经过预填充后写入共享内存池,随后由解码节点加载。如图13a 和 13b 所示,由于Beluga优化了KVCache加载/存储路径,相比MoonCake的QPS提升了3.41×至9.47×。
如图13c 所示,MoonCake 在使用较大块(256 tokens)时,缓存命中的TTFT为13.0 秒;但若使用较小的16 token块时,TTFT则增至76.8 秒,甚至超过了第一次运行时的重计算延迟。相比之下,Beluga直接使用vLLM原生的 16 token块大小,无需操作批处理。









