绑定手机号
确认绑定









相对于一种(矢量量化)制造(AR)模型将发布自Q的图像,该模型将特征图通过VQ量化,再网格技术等示例,基本实现表示为序列。模型对后, AR 可以生成图像中的序列的图像,而不是整个模型中的全部模型。
我们编码的序列长度对于图像的 AR 建模很重要。短序列可以显着降低 AR 模型的预测计算成本,因为 AR 通常使用先前位置的编码来预测下一个编码。然而,以前的研究由于图像问题的长度在波动率 - 错误率序列)不能的特征图。然而,巨大的编码簿会带来参数和耳机的突然变化,智能VQ-VAE的训练不稳定。
韩国浦项科技使用更多的方法提出了一种方法的残差微距,它的残差(RQ)来精确近特征图并降低规格。在 RQ 的 D 表示次次之后,特征图为 D 个编码的大小组成图。簿大小一样多的相对,因此 RQ-VAE 可以合理地逼近特征图,同时保留编码图像的信息,而没有不同的编码簿。由于合理的近似,RQ-VAE 可以比以前的研究 [14,37, 45] 进一步降低对特征图的接收特征图的空间应该是 8×8 的特征图。例如,RQ 已经使用 25×8PR 的特征图进行了 25×256 的图像 AR 模型。论文被 CV22 接收。

论文地址:https://arxiv.org/pdf/2203.01941.pdf
此外,该研究预测还提出了 RQ-Transformer 提取的编码。由于,以估计下一个 RQ-Transformer 的特征的不同特征,RQ-Transform 可以降低计算成本,轻松学习输入为 RQ-Transformer 的 RQ-Transformer。提出了训练技术,软标签)和用于 RQ-VAE 编码的测量。通过 AR 模型中标签解决(曝光偏差)进一步提高了 RQ-Transformer 的性能。
值得一提的是,该研究最近发布了 30M 文本对上训练的 3.9B 参数的 RQ-Transformer。据了解,这是图像公共模型中最大的文本到图像 (T2I) 模型。没有出现在该论文中。具体内容可参考GitHub。

代码地址:https://github.com/kakaobrain/rq-vae-transformer
如下图所示,该模型可以生成高质量的图像。

论文中生成图像的例子
3.9B参数的RQ-Transformer 生成结果,画框里眼镜的猫:

生成沙漠上的埃菲尔铁塔:

将接下来的脚本表示出来的图像 AR 建模 RQ-VAE 和编码表 2 显示阶段。RQ-使用RQ-图,使用两台VAE的框架图表示为D个。然后,使用RQ -Transformer自回归预测下一个空间位置的下一个D码。他们还解释了使用RQ-Transformer解决AR模型训练中的曝晒问题。

第一阶段:残差量化VAE
它可以解释在表达VQ和VQ的大小的方式,然后提出RQ-VAE的特征值,编码的情况下精确地逼近。
VQ 和 VQ-VAE 的表达方式。令编码簿C为一个有限集 ,它包含了成的代码k和嵌入代码
,它包含了成的代码k和嵌入代码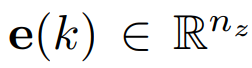 ,其中K是编码簿大小,n_z是代码嵌入的维数。
,其中K是编码簿大小,n_z是代码嵌入的维数。
考虑到一个 z ϵ^nz, 表示的 VQ,这个 z 嵌入的离 z 表示最近,如下公式(1)。
表示的 VQ,这个 z 嵌入的离 z 表示最近,如下公式(1)。

在将图像编码为离散码图后,VQ-VAE从编码图重建图像。
对于残差表示为一个标准,Q没有增加数字大小,采用残差数字(RQ)来化z。 3)展示。
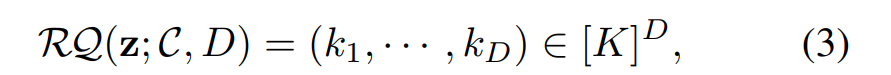
RQ-VAE的编解码器架构组成,在上面的VQ模块上被RQ模块所组成。
具体代码,深度为将特征图 Z 为 M ϵ [K]^H×W×D 的图形表示,并展开了 ,成为 ϵ [D] 的为 D 的特征图图,变成公式(5)。
,成为 ϵ [D] 的为 D 的特征图图,变成公式(5)。
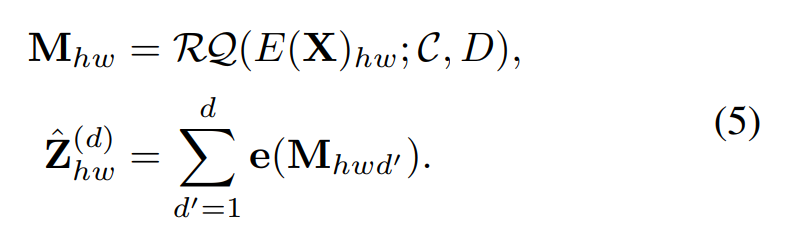
RQ-VAE 可以生成比 VAE 更准确的重构结果,这是确定 RQ-VAE 使用给定的计算成本的模型的编码簿大小合理地逼近特征图。
第二阶段:RQ-Transformer
RQ-Transformer 的 RQ-Transformer 自回归模型展示了 RQ-VAE 对 RQ-Transformer 的预测。 RQ-Transformer的训练技术,以防止AR模型训练中暴露的解释。
在 R-VAE 提取扫描代码的顺序为 M ϵ [K] H×W×D 后,光栅扫描顺序(光栅 S ϵ)将 M 的空间重新排列为代码 [ K]^t的二维码,其中T = HW公式。T代码(T×D)是S的第8行,并包含D个,如下所示。

如上图 2 所示,RQ-由空间变压器和深度变压器组成。空间变压器是掩码自标注块的位置变压器的信息,采集一个先前的时间点。给定时间用于 h_t,深度变压器自回归预测位置t处的D个代码(S_t1,····,S_tD)。
软标签和随机代码。乐意对来自 RQ-VAE 的进行软标签和随机调用,以解决显示偏差。
无条件图像生成
该研究在 LSUN-{猫、卧室、教堂}和 FFHQ 数据集上评估了无生成的质量。表 1 显示,RQ-Transformer 模型在无条件生成图像方面的其他 AR 模型。对于小规模数据集,比如 LSurchHQ,以及小 RQ-Transformer 的卧室模型和 DCT-Q GAN。对于其他更详细的 LSUN 集,例如 -{RQ-Transformer 模拟和基础的模型。

该研究的性能研究可以很容易地展示出用于 RQ-R 之间的性能测试,因为 SQ-Former 可以在适当的时间内使用 Q-Q-R 的性能测试。无条件生成高质量图像。

有条件生成图像
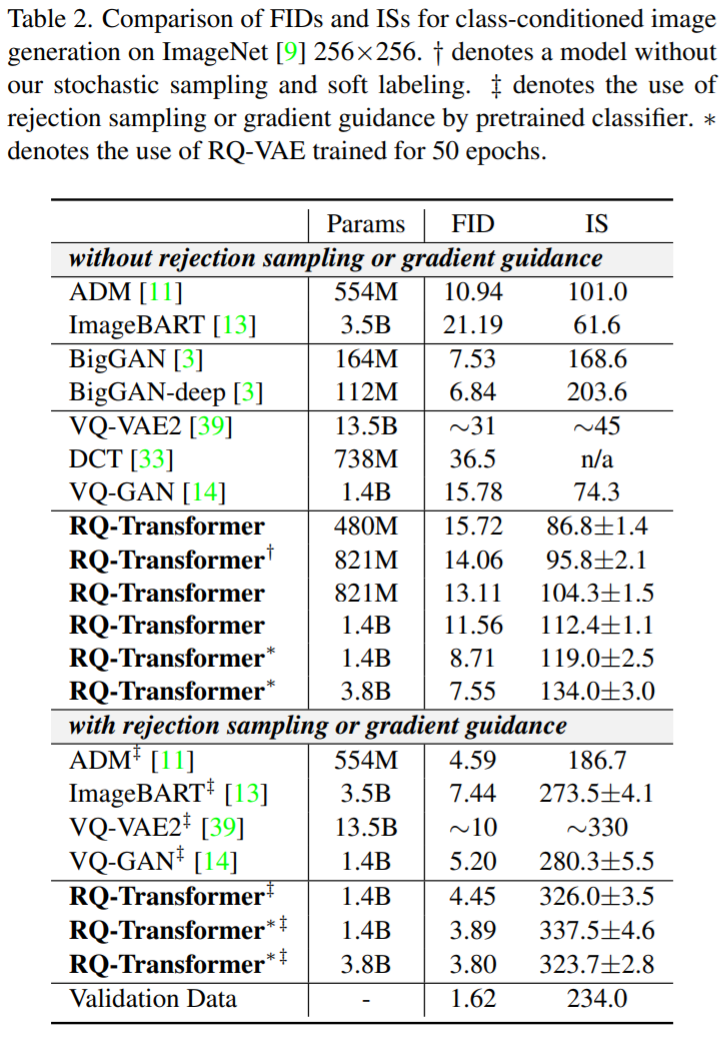
该研究分别使用 CC-3 进行类的生成生成。如 2 表所示,R-Q-Q-Transformer 在 Image 上的图像和以前的图像和以前的模型。具有比VQ-VAE2,DCT,和VQ-GAN的参数少3倍的参数。另外,具有821M的RQ-Transformer在没有参数的下参数的情况下增强现实模型。
具有1.4B参数的RQ-Transformer在没有接受的参数下达到11.56的FID分数。当将RQ-VAE的训练时间从10点到50时,1.4B的RQ-Transformer参数进一步提高,达到了8. 8. B 将分派分数。另外,R 进一步参数选择与 F 当 5 大 GAN 3. 7. 5 和 7 的 FID 分派时,可以。
RQ-Transformer 可以在 CC-3M 的各种文本条件下生成高质量的图像。 Transformer 可以使用各种文本条件生成高质量的图像。
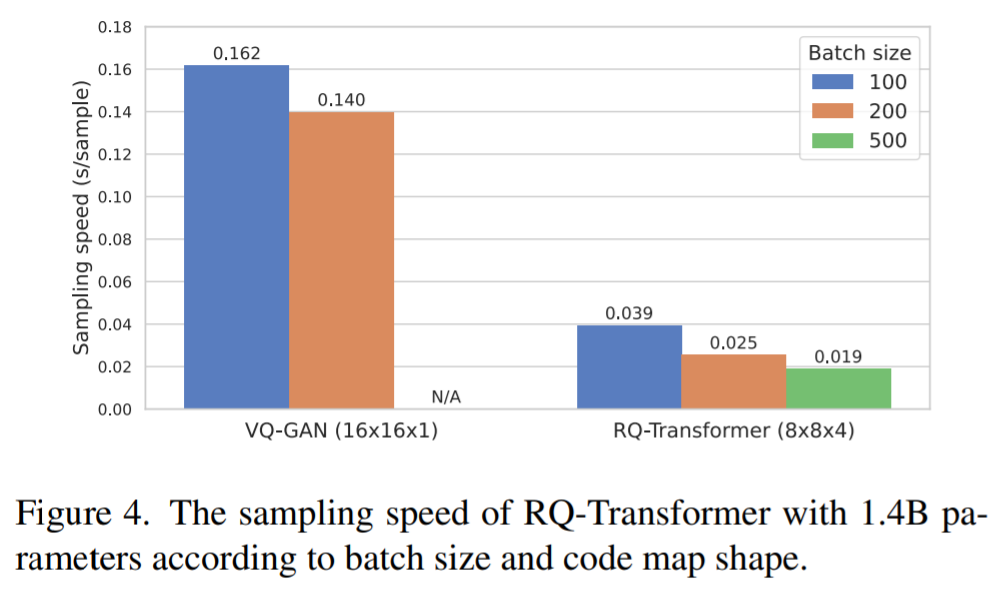
RQ-Transformer 的计算效率
分别为 16Q-4B 和 RQ-Transformer 的 RQ-Transformer 的输入,速度参数与 VQ-GAN 进行了比较,并设置了模型 1.4B。VQ-4 和 RQ-Transformer 分别为 16×16×1 和 8×8 ×4。每个模型使用单块NVIDIA A100 GPU生成一个样品,50个和50个大小分别为10、200、500。
对于 100 和 200 的显示大小和大小,与 VQ-GAN 相比,RQ-Transformer 出 4.1 倍 5.6 倍。此外,RQ-VAE 的短序列显示,RQ-Transformer 的长度可以增加到 50 秒,而 GAN 是允许的 50 秒。因此,RQ-Transformer 可以进一步提升梯级图像为 002 02 ,因此每一个 VQ-Transformer 的速度为 20 秒,VQ-GAN 的速度为 20 秒。,RQ-Transformer 比以前的分辨率更高。的 AR 计算上更高效,同时模型实现在图像生成基准的最新结果。