绑定手机号
确认绑定









在先前的文章中《近距离看GPU计算(2)》我们介绍了GPU SM单元以Thread Block为单位的调度方法,这些的Block属于同一个kernel任务,当然处于相同的进程上下文(CUDA Context),针对的是任务内线程级别并行执行。我们知道现代GPU计算能力与日俱增,不断挑战新高。随之而来的问题是,单凭一个Kernel任务很能占满GPU,来自相同进程,甚至不同的进程的任务在时间上、空间上如何共享GPU,又是如何调度的呢?笔者曾经就这些问题求教于GPU公司专门的同事,给出的解释往往含混不清,很难有确定的答案。这里笔者不是自不量力要祭出终极大杀器,而是就一些文献浅见,尝试梳理下思路提出问题,望有识见的朋友能给与指正。主题内容大概分三个部分,第一部分我们讨论来自同一进程的任务的调度,第二部分会涉及来自不同进程上下文的任务如何共享GPU以及可能抢占的行为,第三部分会谈下GPU驱动框架对调度行为的一些支持。第一二部分主要讨论硬件的行为,第三部分从软件的视角分析。本文为其中第一部分。
Stream的概念
在正式开始介绍之前,我们先回顾下CUDA框架跟任务调度关系密切的stream的概念。Stream表示一个GPU任务队列,该队列中的任务将按照添加到Stream中的顺序先后而依次执行。所有的CUDA任务(包括kernel运行和数据搬运)都显式或隐式通过stream得到执行,stream也就两种类型,分别是:默认stream(defaut stream, 或者说stream 0)和其它stream。CUDA任务没有显式的指定stream就运行在默认stream上。stream任务的执行遵守下面规则。
以下代码表示如何创建使用默认stream和其它stream 的情形。

凡规则必有例外,在目前版本的Cuda通过nvcc选项--default-stream,可以使得CPU线程采用的默认stream跟其它stream一般无二。另外创建其它stream的时候可以通过传递cudaStreamNonBlocking标记告诉runtime该stream和默认stream不会互相隐式阻塞。为方便起见,接下来的讨论我们不涉及上述两种情形。
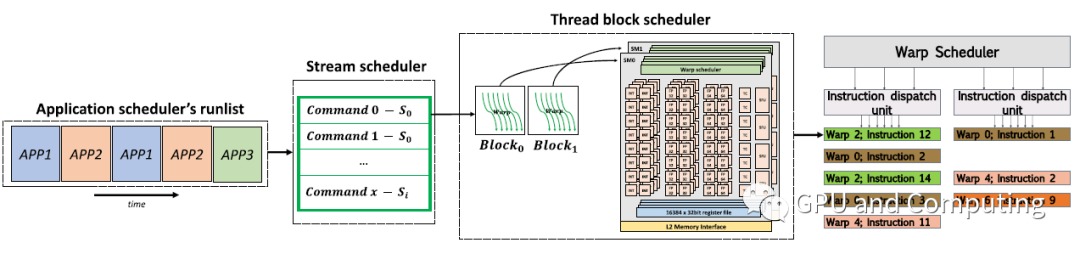
图1
如果考虑stream,CUDA任务运行调度过程如图1所示,应用程序的各种任务分发到不同的stream上,按任务分发时的thread block大小定义再由硬件层次上的thread block调度器以thread block为单位分配给不同的SM运行,在SM内部,thread block由warp组成,warp为最小的执行调度单位,thread block->warp阶段的调度过程我们前面的文章已经涉及,这里不再赘述,在本文中,我们主要关注的是stream->thread block阶段的调度,另外因为暂且不考虑跨进程上下文,所以图示中stream S0...Si都来自同一个应用程序。
文献1的工作
在这小节里,我们介绍一下文献《GPU Scheduling on the NVIDIA TX2: Hidden Details Revealed》的工作。目前车载平台也大量利用GPU来加速绘制和计算工作,有些应用在关键路径上有实时的要求,比如里程计的绘制和障碍物检测等等,但是GPU内部任务如何调度一直是个黑盒子,各个GPU厂商都讳莫如深,更别提有公开文档记录了,这给实时任务的执行预测带来了困难,也影响相关产品的安全认证。基于此出现了一些通过Microbench或者反向工程来了解GPU调度行为的工作,下面涉及的文献就是其中一些例子。

文献1做了很多microbench的工作,来推测CUDA GPU任务调度的行为,并试图扩展到不同系列的GPU硬件。该文预设整个CUDA平台存有以下硬件队列,(a)对应硬件Copy Engine(以下简称CE)FIFO队列,CE负责在Host和GPU设备之间搬运数据,(b)对应硬件Kernel Execution Engine(以下简称EE)的FIFO队列,EE负责Kernel的执行。另外每个CUDA stream分别对应一个软件意义上的FIFO队列。这些队列的整体层次如图2所示。

图2
根据microbench的结果,文献1总结了如下GPU任务调度规则,并在文献2中进一步验证,这些规则也适用于Nvidia Maxwell、Pascal、Volta系列GPU。而对较老Kepler版本,规则G2需要变更为当kernel到达其stream队列头部的时候, 它会被排入EE队列并从stream队列出列。

文献1的工作基于NVIDIA TX2平台,配置的GPU是Pascal版本,一共有两个SM,每个SM的硬件资源如下表。

根据以下kernel的分发序列和其对应的的资源要求,我们有了图3的调度结果。有心的读者不妨对照规则列表以及上表SM的资源能力推敲下,比如分别来自stream2和stream3的k4以及k5,按照其它条件,应该可以差不多同时刻得到执行,但是因为每个SM的shared memory大小限制,只能满足一个kernel的运行。

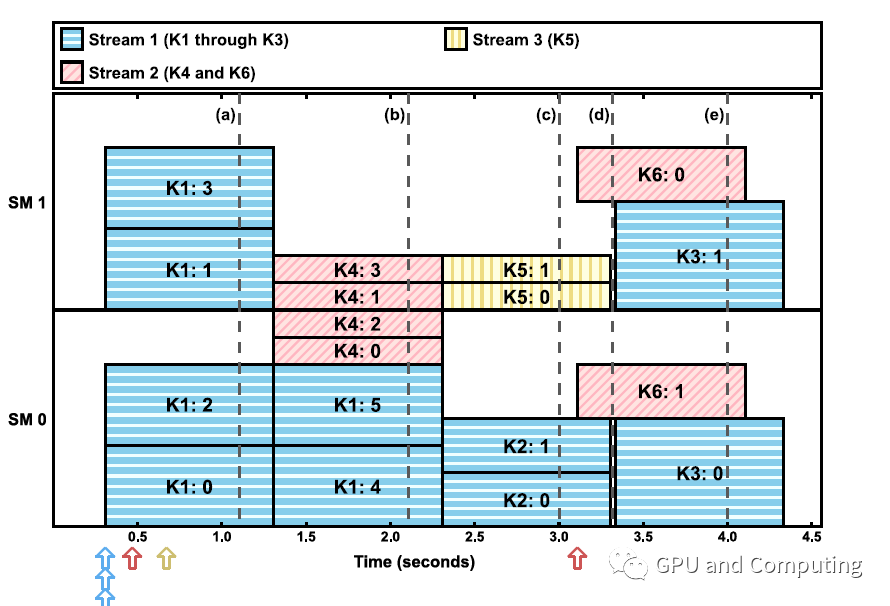
图3
从Maxwell版本硬件开始,CUDA提供接口函数cudaStreamCreateWithPriority,使得创建stream的时候我们可以指定其优先级。文献1也考虑到了这种情况,认为调度硬件除普通EE队列,还有一个容纳高优先级任务的EE队列,并定义了如下额外规则来匹配,
Hyper-Q的改进
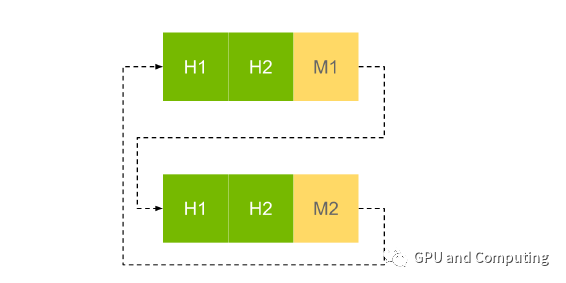
文献1有个较大的硬伤,其立论的基础是调度硬件只有一个EE队列,但是其试验的平台是TX2,配置有Pascal版本的GPU,按道理应该能支持Hyper-Q,也就是存在多个独立的EE队列,不知道是不是为简化起见,文章作者没有考虑Hyper-Q的因素。之前Fermi版本GPU在支持多个stream的时候,它们会被导入到同一个硬件队列,由于同一stream内任务的依赖关系,本来不需要同步的stream之间的任务不能真正同时运行,如下图所示,只有不同stream边界处的任务X和R,以及P和C才能并发执行。

另外一个显而易见的问题是不同的任务分发顺序会影响GPU执行的并发水平。如下图所示,假设stream1有ka1和kb1两个任务,stream2有ka2和kb2两个任务,以深度优先和广度优先发送任务其调度有截然不同的行为。

为克服这些问题,减轻CUDA程序并发优化的负担,Kepler版本GPU引入了Hyper-Q特性,使得可利用的硬件队列达到32个,每个stream都有对应的硬件工作队列,只要资源条件允许,可以实现不相关任务的充分并发。

那么当有多个硬件队列的时候,调度硬件实际上又是如何运作的呢?文献3提供了一些线索,我们这里提下,可以结合文献1验证过的现象一起来琢磨。应用程序的stream们会映射到硬件队列,这些映射信息会组织成一个runlist,每个硬件队列根据interleaving level在其中占据一个或多个slot,映射信息包括stream对应的Command Push Buffer以及时间片或者抢占策略等其它调度辅助信息。调度硬件会round robin扫描这个runlist,查看slot对应的command buffer有没有任务需要执行,如果这个slot被标记为不可抢占,就会等队列任务执行完成,否则时间片一过,当前的任务队列会被抢占,而切换到下个slot,等到再次运转到该任务队列的slot时候再恢复执行。抢占的粒度跟GPU硬件能力有关系,可能是block或者thread甚至是instruction级别,不一定跟时间片完全吻合。Interleaving level设置使得高优先级的stream有更多机会被执行到,如下图优先级高的stream在runlist可以有更多slot。
文献4来自AMD,探讨了HSA Queue或者说stream的数目超过硬件队列时如何处理,也可以一并参考下,这里就不再展开。
再补个后记,因前段时间个人工作有调整,有了个偷懒的理由,一晃大半年时间没有正式的更新了。本来准备春节假期写就的文章,也拖到二月份最后一天才发出来,不过还好还是在农历正月里,但愿是个好的开始,后面计划的内容不要烂尾。也希望关注的朋友们能多提宝贵建议,共同切磋。
主要参考资料:
~~~~~~~~~~~~~~~~~~~~~~~~~~~~
如果觉着内容有帮助,请帮忙关注、点赞、在看并分享给更多的朋友。谢谢!







