绑定手机号
确认绑定









2022年7月,YOLOv7来临,
论文链接:https://arxiv.org/abs/2207.02696
代码链接:https://github.com/WongKinYiu/yolov7
在v7论文挂出不到半天的时间,YOLOv3和YOLOv4的官网上均挂上了YOLOv7的链接和说明,由此看来大佬们都比较认可这款检测器:
官方版的YOLOv7相同体量下比YOLOv5精度更高,速度快120%(FPS),比 YOLOX 快180%(FPS),比 Dual-Swin-T 快1200%(FPS),比 ConvNext 快550%(FPS),比 SWIN-L快500%(FPS)。
在5FPS到160FPS的范围内,无论是速度或是精度,YOLOv7都超过了目前已知的检测器,并且在GPU V100上进行测试, 精度为56.8% AP的模型可达到30 FPS(batch=1)以上的检测速率,与此同时,这是目前唯一一款在如此高精度下仍能超过30FPS的检测器。
另外,YOLOv7所获得的成果不止于此,例如:
YOLOv7-e6 (55.9% AP, 56 FPS V100 b=1) by +500% FPS faster than SWIN-L Cascade R-CNN (53.9% AP, 9.2 FPS A100 b=1)
YOLOv7-e6 (55.9% AP, 56 FPS V100 b=1) by +550% FPS faster than ConvNeXt-RCNN (55.2% AP, 8.6 FPS A100 b=1)
YOLOv7-w6 (54.6% AP, 84 FPS V100 b=1) by +120% FPS faster than YOLOv5-X6-v6.1 (55.0% AP, 38 FPS V100 b=1)
YOLOv7-w6 (54.6% AP, 84 FPS V100 b=1) by +1200% FPS faster than Dual-Swin-RCNN (53.6% AP, 6.5 FPS V100 b=1)
YOLOv7 (51.2% AP, 161 FPS V100 b=1) by +180% FPS faster than YOLOX-X (51.1% AP, 58 FPS V100 b=1)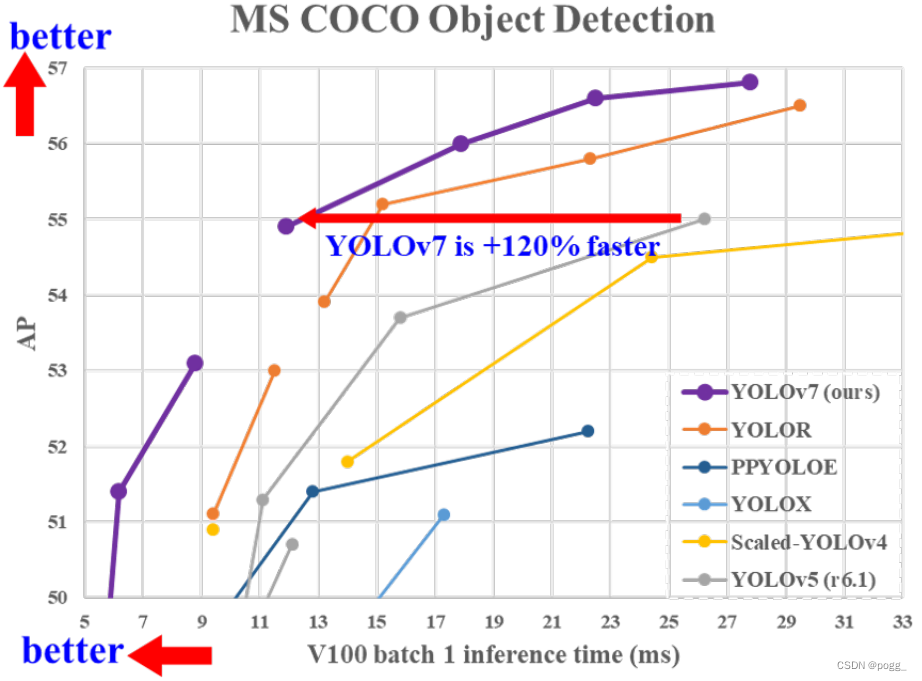
实时目标检测是计算机视觉中一个重要的课题,而运行实时检测器的计算设备通常是一些移动端CPU或GPU,以及由近几年由制造商研发的 神经处理单元(NPU)。上述提到的一些边缘设备针对不同的卷积结构有不同的加速效果,如普通卷积(npu/gpu)、深度卷积(cpu/npu)或MLP操(gpu/npu)。
GPU/NPU边缘架构: 在本文中,作者提出的实时目标探测器能够更好的支持边缘移动端GPU设备和高算力GPU设备。特别是近几年来,实时探测器处在大力适配边缘设备的潮流中。如MCUNet和NanoDet,专注于适配低功耗移动端,以提高边缘设备CPU的推理速度。对于YOLOX和YOLOR等算法,他们专注于提高检测器在GPU上的推理速度。近年来,实时探测器的发展主要集中在高效的结构设计上。
CPU边缘架构: 对于可以在CPU上使用的实时探测器,骨干设计主要基于MobileNet、Shufflenet或Ghostnet。
高算力GPU/NPU:另一些主流的实时检测器是为GPU开发的,它们主要使用ResNet、DarkNet或DLA,然后借鉴CSPNet中的跨级策略来优化架构。
Bag-of-freebies: 除了架构优化外,作者提出的方法还集中在训练过程的优化,以提高检测器的准确性,但不增加推理耗时。作者称所提出的模块和优化方法为可训练的免费礼包(bag-of-freebies)。
近年来,模型结构重参化和动态标签分配已成为网络训练和目标检测中的重要优化方向。在本文中,作者提出一些已经发现的问题,例如:
对于模型结构重参化,用梯度传播路径的概念分析了适用于不同网络中各层结构重参化策略,提出了规划的模型结构重参化。
当使用动态标签分配策略时,多输出层的模型在训练时会产生新的问题,比如怎样才能为不同分支更好的输出分配动态目标。针对这个问题,作者提出了一种新的标签分配方法,称为coarse-to-fine(由粗到细)引导标签分配策略。
本文做出的贡献如下:
设计了几种可训练的bag-of-freebies,使实时检测器可以在不提高推理成本的情况下大大提高检测精度;
对于目标检测的发展,作者发现了两个新的问题,即模块重参化如何高效替代原始模块,以及动态标签分配策略如何处理好不同输出层的分配。因此在本文中提出了方法进行解决。
作者为实时探测器提出了“扩展”和“复合缩放”(extend” and “compound scaling”)方法,可以更加高效地利用参数和计算量,同时,作者提出的方法可以有效地减少实时探测器50%的参数,并且具备更快的推理速度和更高的检测精度。(这个其实和YOLOv5或者Scale YOLOv4的baseline使用不同规格分化成几种模型类似,既可以是width和depth的缩放,也可以是module的缩放)

2.1 实时检测器
目前最先进的实时探测器主要基于YOLO和FCOS,如果需要研发更先进的实时检测器,通常需要具备以下特征:
(1)更快和更高效的网络架构;
(2)更有效的特征积分方法;
(3)更准确的检测方法;
(4)更鲁棒的损失函数;
(5)更有效的标签分配方法;
(6)更有效的训练方式。
2.2 模型重参化
模型重参化策略在推理阶段将多个模块合并为一个计算模块,可以看作是一种集成技术(model ensemble,其实笔者觉得更像是一种基于feature的distillation),可以将其分为模块级集成和模型级集成两类。对于模型级重新参数化有两种常见的操作:
一种是用不同的训练数据训练多个相同的模型,然后对多个训练模型的权重进行平均。
一种是对不同迭代次数下模型权重进行加权平均。
模块重参化是近年来一个比较流行的研究课题。这种方法在训练过程中将一个整体模块分割为多个相同或不同的模块分支,但在推理过程中将多个分支模块集成到一个完全等价的模块中。然而,并不是所有提出的重参化模块都可以完美地应用于不同的架构。考虑到这一点,作者开发了新的重参数化模块,并为各种架构设计了相关的应用程序策略。下图是作者使用重参化实现构建的多个module,按照分组数不同进行排列,为什么作者会选择32的分组数,应该搞过部署的佬们会清楚一些,模块参考:https://github.com/WongKinYiu/yolov7/blob/main/models/common.py~
2.3 模型缩放
模型缩放通过扩大或缩小baseline,使其适用于不同的计算设备。模型缩放方法通常包括不同的缩放因子,如:
input size(输入图像大小)
depth(层数)
width(通道数)
stage(特征金字塔数量)
从而在网络的参数量、计算量、推理速度和精度方面实现很好的权衡。网络架构搜索(NAS)也是目前常用的模型缩放方法之一。
3.1 高效的聚合网络
在大多数关于设计高效网络的论文中,主要考虑的因素是参数量、计算量和计算密度。但从内存访存的角度出发出发,还可以分析输入/输出信道比、架构的分支数和元素级操作对网络推理速度的影响(shufflenet论文提出)。在执行模型缩放时还需考虑激活函数,即更多地考虑卷积层输出张量中的元素数量。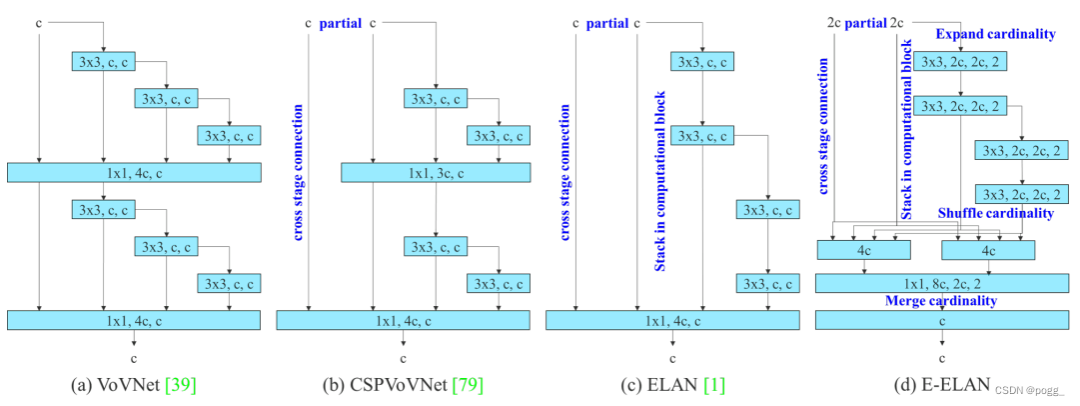
图2(b)中CSPVoVNet是VoVNet的一个变体。除了考虑上述几个设计问题外,CSPVoVNet的体系结构还分析了梯度路径,使不同层能够学习更多样化的特征。上面描述的梯度分析方法还能使推理速度更快、模型更准确(看下图!其实和Resnext有点像,但比它复杂一些)。
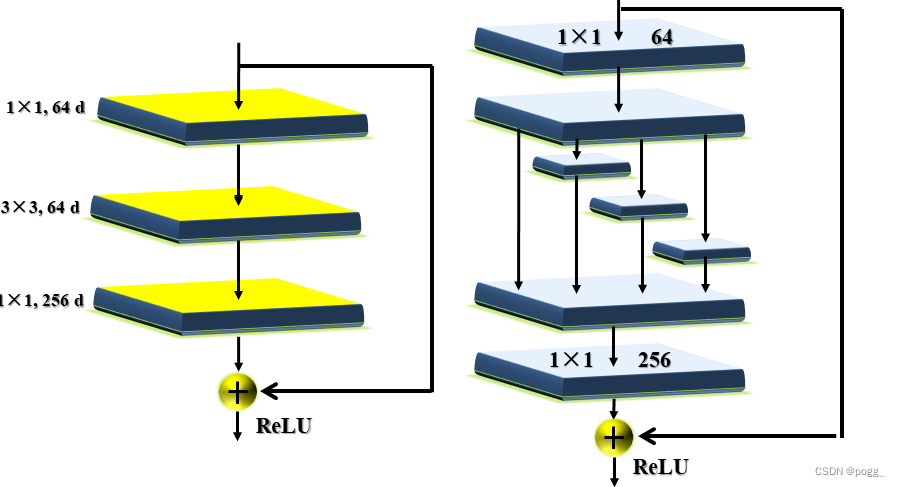
图2(c)中的ELAN出于以下设计考虑——“如何设计一个高效的网络?”得出结论是:通过控制最短最长梯度路径,更深的网络可以有效地进行学习并更好地收敛。
因此,在本文中,作者提出了基于ELAN的扩展版本E-ELAN,其主要架构如图2(d)所示。在大规模ELAN中,无论梯度路径长度和计算模块数量如何,都达到了稳定的状态。但如果更多计算模块被无限地堆叠,这种稳定状态可能会被破坏,参数利用率也会降低。本文提出的E-ELAN采用expand、shuffle、merge cardinality结构,实现在不破坏原始梯度路径的情况下,提高网络的学习能力。
在体系结构方面,E-ELAN只改变了计算模块中的结构,而过渡层的结构则完全不变。作者的策略是利用分组卷积来扩展计算模块的通道和基数,将相同的group parameter和channel multiplier用于计算每一层中的所有模块。然后,将每个模块计算出的特征图根据设置的分组数打乱成G组,最后将它们连接在一起。此时,每一组特征图中的通道数将与原始体系结构中的通道数相同。最后,作者添加了G组特征来merge cardinality。除了维护原始的ELAN设计架构外,E-ELAN还可以指导不同的分组模块来学习更多样化的特性。(难以置信,要是在CPU上运行,分分钟可能爆)
3.2 基于连接的模型的模型缩放
缩放这个就不说了,和YOLOv5、Scale YOLOv4、YOLOX类似。要不就depth and width,要不就module scale,可参考scale yolov4的P4、P5、P5结构。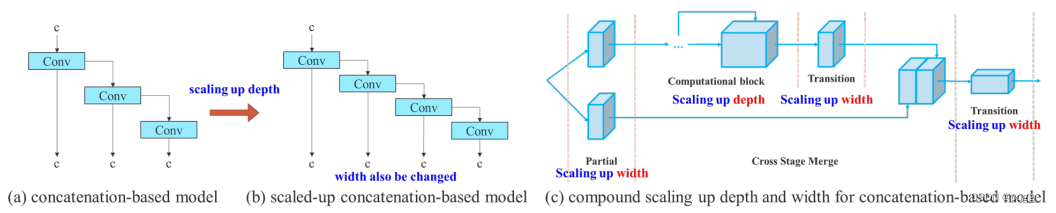
4.1 卷积重参化
尽管RepConv在VGG上取得了优异的性能,但将它直接应用于ResNet和DenseNet或其他网络架构时,它的精度会显著降低。作者使用梯度传播路径来分析不同的重参化模块应该和哪些网络搭配使用。通过分析RepConv与不同架构的组合以及产生的性能,作者发现RepConv中的identity破坏了ResNet中的残差结构和DenseNet中的跨层连接,这为不同的特征图提供了梯度的多样性(题外话,之前在YOLOv5 Lite上做过此类实验,结果也是如此,因此v5Lite-g的模型也是砍掉了identity,但分析不出原因,作者也没给出具体的分析方案,此处蹲坑)。
基于上述原因,作者使用没有identity连接的RepConv结构。图4显示了作者在PlainNet和ResNet中使用的“计划型重参化卷积”的一个示例。
4.2 辅助训练模块
深度监督是一种常用于训练深度网络的技术,其主要概念是在网络的中间层增加额外的辅助头,以及以辅助损失为指导的浅层网络权重。即使对于像ResNet和DenseNet这样收敛效果好的网络结构,深度监督仍然可以显著提高模型在许多任务上的性能(这个和Nanodet Plus相似,按笔者理解可以当成是深层局部网络的ensemble,最后将辅助头和检测头的权重做融合)。图5(a)和(b)分别显示了“没有”和“有”深度监督的目标检测器架构,在本文中,作者将负责最终的输出头称为引导头,将用于辅助训练的头称为辅助头。
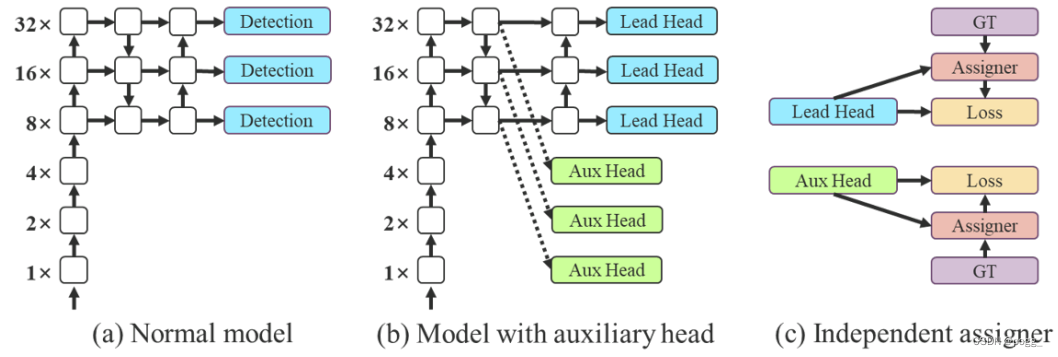
接下来讨论标签分配的问题。在过去,在深度网络的训练中,标签分配通常直接指的是ground truth,并根据给定的规则生成hard label(未经过softmax)。然而近年来,以目标检测为例,研究者经常利用网络预测的质量分布来结合ground truth,使用一些计算和优化方法来生成可靠的软标签(soft label)。例如,YOLO使用bounding box预测和ground truth的IoU作为软标签。
在本文中,作者将网络预测结果与ground truth一起考虑后再分配软标签的机制称为“标签分配器”。无论辅助头或引导头,都需要对目标进行深度监督。那么,‘’如何为辅助头和引导头合理分配软标签?”,这是作者需要考虑的问题。目前最常用的方法如图5(c)所示,即将辅助头和引导头分离,然后利用它们各自的预测结果和ground truth执行标签分配。
本文提出的方法是一种新的标签分配方法,通过引导头的预测来引导辅助头以及自身。换句话说,首先使用引导头的prediction作为指导,生成从粗到细的层次标签,分别用于辅助头和引导头的学习,具体可看图5(d)和(e)。
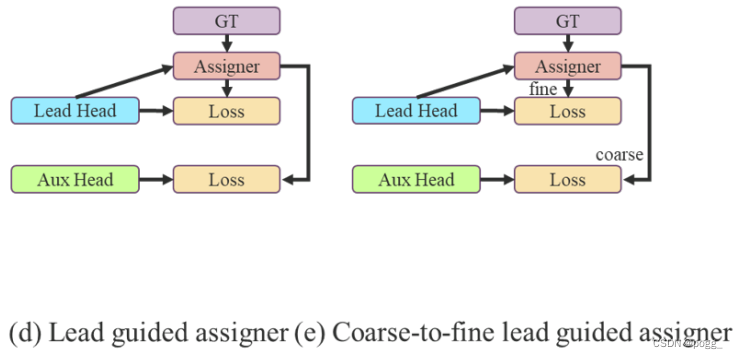
Lead head guided label assigner: 引导头引导“标签分配器”预测结果和ground truth进行计算,并通过优化(在utils/loss.py的SigmoidBin()函数中,传送门:https://github.com/WongKinYiu/yolov7/blob/main/utils/loss.py 生成软标签。这组软标签将作为辅助头和引导头的目标来训练模型。(之前写过一篇博客,【浅谈计算机视觉中的知识蒸馏】]https://zhuanlan.zhihu.com/p/497067556)详细讲过soft label的好处)这样做的目的是使引导头具有较强的学习能力,由此产生的软标签更能代表源数据与目标之间的分布差异和相关性。此外,作者还可以将这种学习看作是一种广义上的余量学习。通过让较浅的辅助头直接学习引导头已经学习到的信息,引导头能更加专注于尚未学习到的残余信息。
Coarse-to-fine lead head guided label assigner: Coarse-to-fine引导头使用到了自身的prediction和ground truth来生成软标签,引导标签进行分配。然而,在这个过程中,作者生成了两组不同的软标签,即粗标签和细标签,其中细标签与引导头在标签分配器上生成的软标签相同,粗标签是通过降低正样本分配的约束,允许更多的网格作为正目标(可以看下FastestDet的label assigner,不单单只把gt中心点所在的网格当成候选目标,还把附近的三个也算进行去,增加正样本候选框的数量)。原因是一个辅助头的学习能力并不需要强大的引导头,为了避免丢失信息,作者将专注于优化样本召回的辅助头。对于引导头的输出,可以从查准率中过滤出高精度值的结果作为最终输出。然而,值得注意的是,如果粗标签的附加权重接近细标签的附加权重,则可能会在最终预测时产生错误的先验结果。
4.3 其他可训练的bag-of-freebies
Batch normalization:目的是在推理阶段将批归一化的均值和方差整合到卷积层的偏差和权重中。
YOLOR中的隐式知识结合卷积特征映射和乘法方式:YOLOR中的隐式知识可以在推理阶段将计算值简化为向量。这个向量可以与前一层或后一层卷积层的偏差和权重相结合。
EMA Model:EMA 是一种在mean teacher中使用的技术,作者使用 EMA 模型作为最终的推理模型。
5.1 实验环境
作者为边缘GPU、普通GPU和云GPU设计了三种模型,分别被称为YOLOv7-Tiny、YOLOv7和YOLOv7-W6。同时,还使用基本模型针对不同的服务需求进行缩放,并得到不同大小的模型。对于YOLOv7,可进行颈部缩放(module scale),并使用所提出的复合缩放方法对整个模型的深度和宽度进行缩放(depth and width scale),此方式获得了YOLOv7-X。对于YOLOv7-W6,使用提出的缩放方法得到了YOLOv7-E6和YOLOv7-D6。此外,在YOLOv7-E6使用了提出的E-ELAN,从而完成了YOLOv7-E6E。由于YOLOv7-tincy是一个面向边缘GPU架构的模型,因此它将使用ReLU作为激活函数。作为对于其他模型,使用SiLU作为激活函数。
5.2 baseline
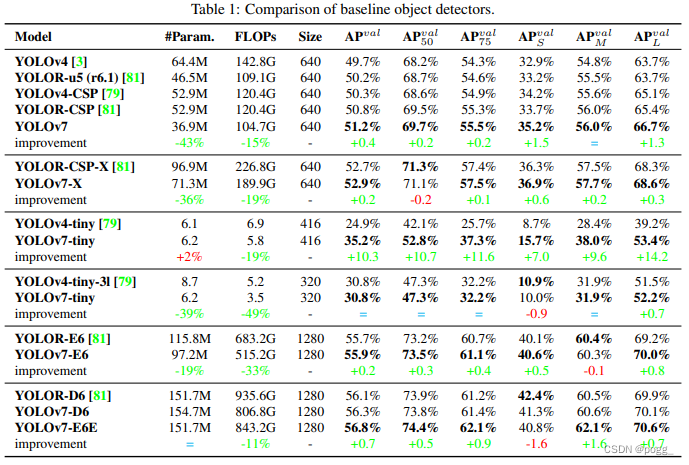
选择当前先进的检测器YOLOR作为基线。在相同设置下,表1显示了本文提出的YOLOv7模型和其他模型的对比。从结果中可以看出:
与YOLOv4相比,YOLOv7的参数减少了75%,计算量减少了36%,AP提高了1.5%。
与最先进的YOLOR-CSP相比,YOLOv7的参数少了43% ,计算量少了15%,AP高了0.4%。
在小模型的性能中,与YOLOv4-tiny相比,YOLOv7-Tiny减少了39%的参数量和49%的计算量,但保持相同的AP。
在云GPU模型上,YOLOv7模型仍然具有更高的AP,同时减少了19%的参数量和33%的计算量。
5.3 与sota算法的比较
本文将所提出的方法与通用GPU上或边缘GPU上最先进的的目标检测器进行了比较,结果如下表所示。
从表2可以看出所提出的方法具有最好的速度-精度均衡性:
比较YOLOv7-Tiny-SiLU和YOLOv5-N(v6.1),YOLOv7-Tiny-SiLU在速度上快127帧,准确率提高10.7%。
YOLOv7在帧率为161帧时有51.4%的AP,而相同AP的PP-YOLOE-L只有78帧,且参数l少41%。
YOLOv7-X在114FPS时,比YOLOv5-L(v6.1)99FPS的推理速度更快,同时可以提高3.9%的AP。
YOLOv7-X与YOLOv5-X(v6.1)相比,YOLOv7-X的推理速度要快31fps。此外,在参数量和计算量方面,YOLOv7-X比YOLOv5-X(v6.1)减少了22%的参数和8%的计算量,但AP提高了2.2%。
使用输入分辨率1280,YOLOv7与YOLOR进行比较,YOLOv7-W6的推理速度比YOLOR-P6快8FPS,检测率也提高了1%的AP。
至于YOLOv7-E6和YOLOv5-X6(v6.1)比较时,前者的AP增益比后者高0.9%,但参数减少45%,计算量减少63%,推理速度提高了47%。
YOLOv7-D6的推理速度与YOLOR-E6接近,但AP提高了0.8%。
YOLOv7-E6E的推理速度与YOLOR-D6接近,但AP提高了0.3%。
5.4 消融实验
(一)比例缩放的方式
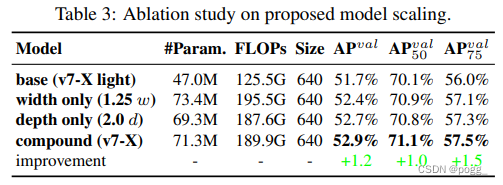
表3显示了在使用不同的模型扩展策略进行放大时获得的结果。其中,本文提出的复合尺度方法将计算块的深度加大1.5倍,将过渡块的宽度扩大1.25倍。与只扩大宽度的方法进行比较,本文提出的方法可以在更少的参数和计算量下提高0.5%的AP。如果与只扩大深度的方法进行比较,只需要增加2.9%的参数量,增加1.2%的计算量,就可以提高0.2%的AP 。从表3的结果中可以看出,本文提出的复合缩放策略可以更有效地利用参数量和计算量。
(二)模型重参化
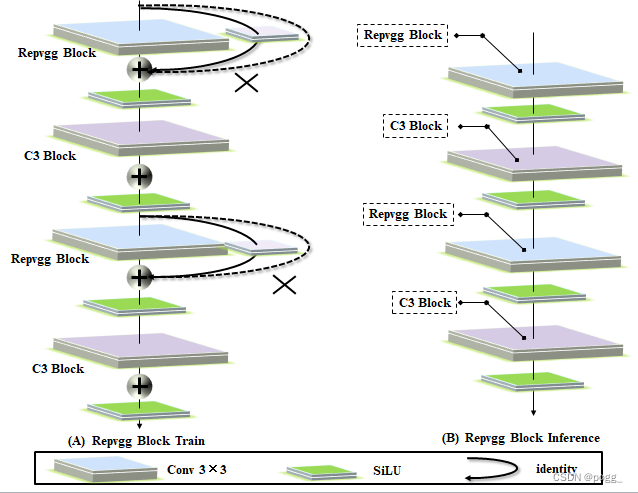
为了验证本文所提出的模型重参数化的通用性,作者将其分别应用于基于concatenation的模型和基于residual的模型上进行验证。基于concatenation的模型和基于residual的模型分别为3个Block的ELAN和CSPDarknet。在基于concatenation的模型实验中,用RepConv替换了3个堆叠的ELAN中的3×3 卷积,详细配置如图6所示。
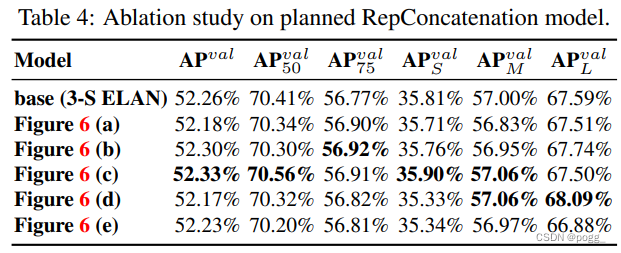
从表4所示的结果可以看到,所有更高的AP值都出现在参数化的模型中。在处理基于残差模型的实验中,由于原始dark block没有3×3的卷积块,作者另外设计了一种反向dark block,其体系结构如图7所示。
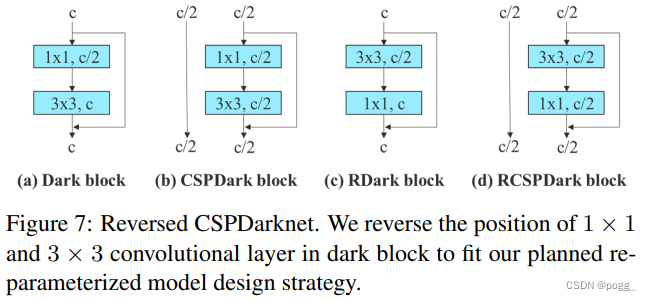
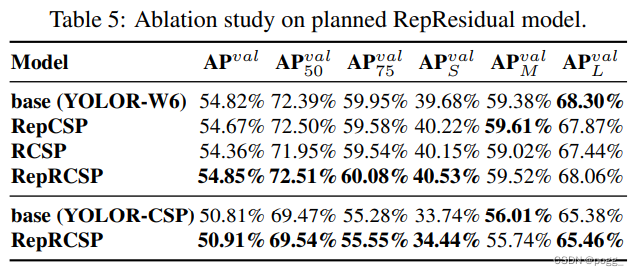
因为dark block和反向dark block的CSPDarknet具有完全相同的参数量和concat操作,所以比较起来相当公平。表5所示的实验结果完全证实了所提出的重参化策略对于residual的模型依旧有效。RepCSPResNet的设计也符合本文的设计模式。
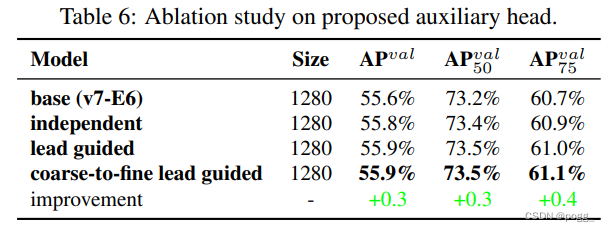
(三)辅助损失头
在辅助头实验的辅助损失中,作者比较了引导头和辅助头的独立标签分配策略,同时也比较了所提出的引导型标签分配方法,在表6中显示了所有的比较结果。
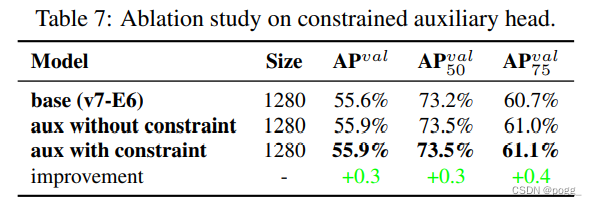
在表7中,作者进一步分析了从粗到细的引导型标签分配策略对辅助头解码器的影响。也就是比较了引入/不引入上界约束的结果。从表中的数字来看,通过距离目标中心的大小来约束目标的上界可以获得更好的性能。
本文提出了一种新的实时检测器。在研究过程中,本文发现了重参化模块的替换问题和动态标签的分配问题。为了解决这一问题,提出了一种可训练的bag-of-freebies策略来提高目标检测的精度。基于此,本文开发的YOLOv7系列目标检测模型获得了最先进的结果。








