绑定手机号
确认绑定









不知道各位小伙伴,还记不记得,我 2020 年发过的一篇文章。
让图片,动起来,用特朗普和蒙娜丽莎的图片,合唱了一首《Unravel》,效果是这样的。
今天,给大家介绍一个,比这个效果更好,功能更多的算法。
通过一个视频,就可以驱动静止的图片,按照视频的动作,运动起来。
成龙大哥,驱动各个图片的效果:

除了驱动头像,还可以驱动身体。

该死,这糟糕的心动感,我必须跑一跑这个算法。
今天,继续手把手教学。
算法原理、环境搭建、效果实现,一条龙服务,直接开始!
论文的名字是:
「Thin-Plate Spline Motion Model for Image Animation」
清华大佬们的作品,翻译成中文大概意思是,基于薄板样条插值的图像运动模型。
我大致浏览了下论文,针对一些现有的无监督学习方法,进行了改进。
像 2020 年我介绍的算法:
「First Order Motion Model for Image Animation」
缺少背景修复,也就是inpainting,这样生成的运动效果就不够逼真。
今天要介绍的算法,对此做了改进,成为了新的 SOTA。
这类算法还是挺有意思的,可以用在视频会议、直播、视频特效、娱乐短视频等多种场景。
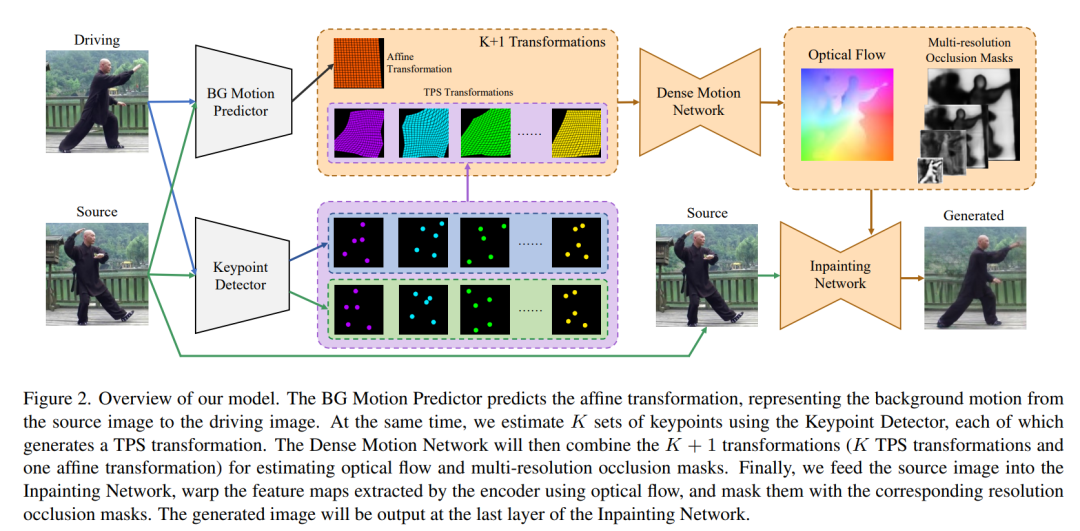
算法主要分为四个部分:
Keypoint Detector:关键点预测,输出人体的关键点。
BG Motion Predictor:图像背景也是运动的,背景变化预测。
Dense Motion Network:可以理解为运动估计网络,结合关键点信息、背景运动信息,以及局部仿射变换信息,生成下一步的动作。
Inpainting Network:对运动后空缺的部位进行补全,填充背景。
Dense Motion Network 和 Inpainting Network 的网络都是 hourglass 结构,就是先下采样,再上采样,形似沙漏状,密歇根大学的研究团队在ECCV2016发表的比较经典的网络结构。
这个算法,是一个新的端到端算法,提出了 TPS motion estimation 方法来驱动图像。
篇幅有限,更详细的内容,可以直接看论文:
https://arxiv.org/pdf/2203.14367.pdf
算法已经开源:
项目地址:
https://github.com/yoyo-nb/Thin-Plate-Spline-Motion-Model
首先需要搭建开发环境,这里还是建议使用 Anaconda,安装一些必要的第三方库,可以参考这两篇开发环境搭建的内容:
Pytorch深度学习实战教程(一):语义分割基础与环境搭建
两篇开发环境搭建教程,如果想手把手的视频教程,可以参考这个:
https://www.bilibili.com/video/BV14R4y1g7qs
环境搭建的问题,文章和视频教程都出过了,可以参考,这里就不再累述。
项目的 requirements.txt 详细列出了依赖。
cffi==1.14.6
cycler==0.10.0
decorator==5.1.0
face-alignment==1.3.5
imageio==2.9.0
imageio-ffmpeg==0.4.5
kiwisolver==1.3.2
matplotlib==3.4.3
networkx==2.6.3
numpy==1.20.3
pandas==1.3.3
Pillow==8.3.2
pycparser==2.20
pyparsing==2.4.7
python-dateutil==2.8.2
pytz==2021.1
PyWavelets==1.1.1
PyYAML==5.4.1
scikit-image==0.18.3
scikit-learn==1.0
scipy==1.7.1
six==1.16.0
torch==1.10.0+cu113
torchvision==0.11.0+cu113
tqdm==4.62.3
使用 conda 或者 pip 安装即可。
环境弄好,下载权重文件,作者提供了清华云盘,下载速度还不错。
https://cloud.tsinghua.edu.cn/d/30ab8765da364fefa101/
创建一个 checkpoints 文件夹,然后将权重文件放进去。
然后就可以下面的指令运行算法:
CUDA_VISIBLE_DEVICES=0 python demo.py --config config/vox-256.yaml --checkpoint checkpoints/vox.pth.tar --source_image ./source.jpg --driving_video ./driving.mp4
CUDA_VISIBLE_DEVICES 指定 gpu,config 指定配置文件,checkpoint 指定权重文件,source_image 指定原始图像,driving_video 为驱动图像的视频文件。
如果不想部署本地的环境,也可以使用 Colab:
https://colab.research.google.com/drive/1DREfdpnaBhqISg0fuQlAAIwyGVn1loH_?usp=sharing
这个算法是没有声音的,如果想添加声音,生成一个视频,可以参考我之前的代码改造下这个算法。
我之前用的是 ffmpeg 写的处理代码。








