绑定手机号
确认绑定









Chiplet又被翻译为芯粒或小芯片,为了不引起歧义本文直接使用Chiplet英文原文。到目前为止AMD、Intel、Nvidia等多家国际头部IC设计企业都推出过基于Chiplet的产品,而目前又传出苹果准备在下一代高端处理器中采用Chiplet技术。一时间Chiplet技术仿佛成为了流量明星,成为最近几年来集成电路行业最热的技术之一。而在国内,Chiplet技术也是受到了各方关注。但遗憾的是,除了海思以外还缺乏有公司或者机构真正采用Chiplet技术去做出商业级别的芯片。
那么各个头部公司青睐Chiplet的原因是什么呢?这实际是“摩尔定律”发展趋缓,依靠传统方法算力提升难度增加而探索出了一条技术途径。
“摩尔定律”到底死没死,是近10年来不断被提起的一个话题。不断有消息宣称“摩尔定律”已死,但又不断有专家出来辟谣说“摩尔定律”还活着,还在不断的延续。一时间仿佛“摩尔定律”化身为薛定谔的猫,处于“又生又死”的状态。但其实我们仔细分析一下“活”,就可以发现“摩尔定律”确实还活着,只不过越来越不能“健康”的活着。如果拿人来做比喻的话,那么在45nm工艺制程之前的摩尔定律可以说正值盛年,要想活下去注意身体、日常锻炼就好。而到了45nm节点时,过大的泄漏电流已经让微缩难以为继,不得已英特尔将采用被称为high-k的崭新材料来制造晶体管闸极电介质,而而晶体管闸极的电极也新的金属材料组合。这就好像40多、50岁的人经历了针对某个器官的重大手术一样,活是继续能活下去,但这活的质量已经大不如前。
而在工艺制程演进到28nm以下时,传统的平面晶体管结构完全不能支撑进一步微缩,2011年以后以FinFET为代表的新型器件结构全面崛起。至此以后工艺制程的微缩进入了“举步维艰”的时代,Intel公司由于其制程长期被卡在14nm附近导致处理器性能提升缓慢(当然,也不止这个原因)而被广大网友戏称为“牙膏厂”。即便是采用了FinFET技术也并没有能够为摩尔定律延寿多久,随着工艺制程进入了10nm以下,一些如GAAFET这样的新的器件结构又将被应用到产业中。
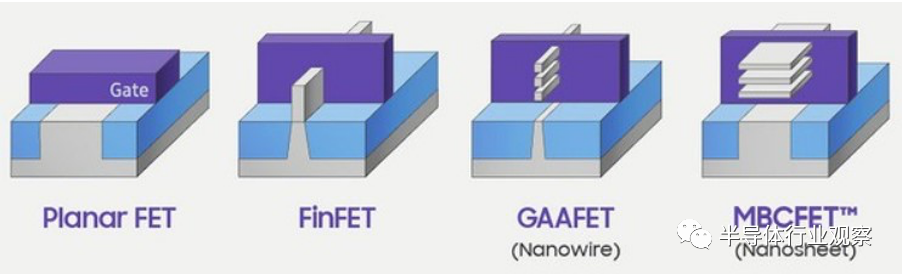
图1.近10年新型器件结构的演变
这些新型器件的结构导致工艺复杂,各家实现的技术路线也各不相同。同样是7nm制程的,台积电和三星的采取的技术路线区别很大。其实发展到这一步,“摩尔定律”可以类比于一个已步入暮年的普通人,靠“打针吃药”勉力维持着。虽然活着,但活得很艰难。活的很“贵”也活的很“脆弱”。
先来谈贵的问题。贵的原因是由于采用了大量新技术新工艺新结构,这让芯片制造的成本成倍增加。增加成本还不是最关键的,关键这样的成本增加似乎是无止尽的。为维持晶体管的密度可以持续增加,现在每革新一代制程就需要大量的技术和工艺创新。这就是使得经济成本完全没有办法摊薄。
事实上从图2就可以看出,在28nm以后,平摊到单个晶体管上的价格其实就没有下降,反而在不断的上升。这其实已经在经济上宣告了摩尔定律的终结——我们确实还是可以买到包含了越来越多晶体管的芯片,但是那种等2年左右时间就可以用同样的价格买到比原来多一倍晶体管芯片的“理想年代”已经一去不返了。
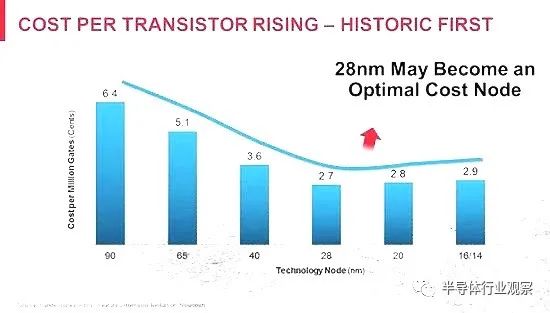
图2.不同制程下每百万门的造价
接下来说“脆弱”的问题,也就是晶体管的缺陷不断增加的问题。这其实是晶体管微缩到一定程度以后,必然出现的问题。现在的晶体管加工早已经是让光刻技术“不堪重负”。无论是多重曝光还是浸润式光刻,都是用一种“明知不可为而为之”的方式在追求极致的微缩。而这就让工艺的一致性和准确性控制非常难做,出现工艺误差甚至加工缺陷的情况就越来越严重。最终反应到芯片上面就是成品率低或者说器件故障率高。故障率高的结果就是一次加工,抛开测试后无法工作的坏片,剩下能工作的芯片就很少。本来加工一次就贵,加工完了以后还要扔掉不少,于是加工出来的合格产品的价格就会居高不下
传统上解决的方法无非两种:一是加大投资进一步去改进工艺加强品控,但这不但投资巨大而去改进总是有物理极限的;二是利用容错设计的方法让芯片即使在有错的情况下也可以正常工作,但这也需要付出额外硅片面积来实现容错电路的,当缺陷多到一定程度以后加过多的容错电路从经济上看又不划算 。所以“脆弱”的问题最终还是反应到了“贵”上面,成为进一步推高先进制程芯片造价的推手。
以上两个问题应该如何解决?确实都不太好解决,但可以尝试先来解决第二个问题。解决第二个问题的方法就是“切”,把大芯片切成小芯片。
图3给了一个示意图,当我们的裸芯(Die)的面积越小,那么在缺陷概率一定的情况下整体的良率越高。如果裸芯的面积是40*40的良率才35.7%。如果面积减少到20*20,良率就上升到了75%。如果进一步减小,良率还会提升。这里面有一些统计学上的数学关系。这里就不详细解释了,大家从理性直觉简单来分析一下就能明白:在缺陷“密度”确定的情况下,裸芯的面积越小,“撞”上缺陷的概率就越大。
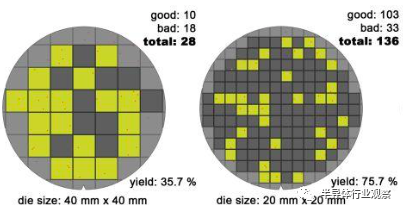
图3.裸芯面积越小整体良率越高
所以把大芯片切成小芯片(Chiplet)就变成了提升良率的一种必然选择。而一旦切成Chiplet以后又有了一个新的好处:快速复用。虽然以前SoC设计方法学中IP已经被设计成可以复用的,但形成SoC原型设计以后该走的软硬件协同验证、后端与物理设计、流片制造、封装测试的流程一个也少不了。可以说是“复用了但又没有完全复用”。而如果是Chiplet的话,就是一个已经走完了完整设计、制造、测试流程的成品小裸片,只是需要直接做一次封装加工就可以用起来。其复用的程度远超过现在的IP。
图4就给出了AMD复用Chiplets的一个典型案例。把多个Chiplet在封装级重新拼装成起来构成完整的系统级芯片,可以在保证良率的前提下继续让单颗芯片内部的晶体管数量增加,又可以复用之前已经成熟的Chiplet。
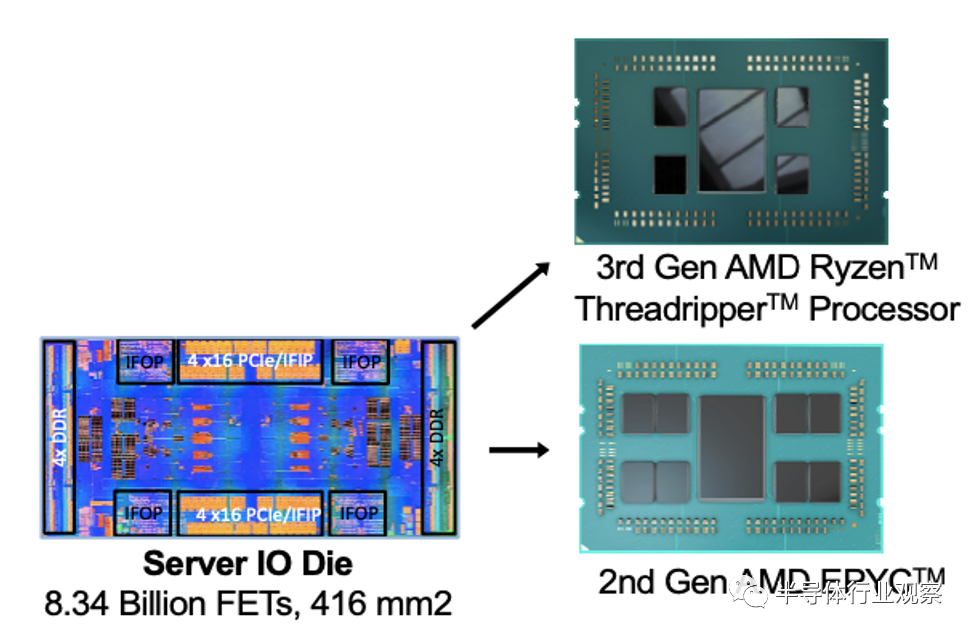
图4.AMD在第三代锐龙(Ryzen)处理器上复用了第二代宵龙(EPYC)处理器的IO Chiplet
在图4中可以看出AMD在第三代锐龙(Ryzen)处理器上复用了第二代霄龙(EPYC)处理器的IO Chiplet,这种复用不但意味着可以将“老旧制程”生产的Chiplet继续应用到下一代产品中以节约成本,更意味着可以极大的节约设计、验证和生产的周期并渐小失败的风险。这一方面要节约大量的人力成本,同时也可以加快上市时间。
如果只是看单位硅片面积上的晶体管数量,Chiplet技术仿佛没有什么帮助,也谈不上“延续”摩尔定律。但如果一颗完整的芯片看成是封装后“成品”,我们可以认为摩尔定律还在继续延续,因为总的晶体管数量确实增加了。尤其是重要的是,这是在不大量的增加成本的前提下完成的,虽然这似乎是一条“退而求其次”的路线。
综上所述:1、摩尔定律如果继续依靠传统的“微缩”路线从经济上来说其实已经难以为继,单个芯片上集成更多的晶体管虽然从技术上来说依然可行但成本已经大到无法接受;2、先进制程的良率问题是让流片成本居高不下的主要因素之一,将大裸片“切”成Chiplet是有效提升单个晶圆良率的必由之路,也是让摩尔定律可以持续的主要方法之一。3、Chiplet技术不但可以提升良率,还可以通过复用成熟的Chiplet进一步降低设计成本和风险,让单颗芯片内部晶体管数量持续增加的同时成本依然可以接受。
发展Chiplet技术面临的问题
可以看到,Chiplet技术是制程演进到了纳米级别,摩尔定律从经济上已难以为继时所发展出来的一条技术路线。也可以说是不得已而为之,改变了传统的技术演进方式。在某种程度上说,有一点“产业链局部重构”的意味。但这种改变必然也要面临新的问题。
首要的问题就是多个Chiplet之间的通信问题。这又分为了几个层次,包括了封装技术、电路设计、协议标准等多个方面。
首先是封装技术,Chiplet技术要把原本单个大硅片“切”成多个再从封装级组装起来。单个硅片上的布线密度和信号传输质量是要远远高于Chiplet之间的。这就要求必须要发展出高密度、大带宽布线的“先进封装技术”,尽可能的提升在多个Chiplet之间布线的数量并提升信号传输质量。好消息是经过多年的发展,Intel和台积电(TSMC)都已经有了相关的技术储备,通过所谓的中介层(Interposer)将多个Chiplet互连起来。TSMC公布的技术是CoW,而Intel公布的是EMIB。今天这些技术仍然在不断演进中,并有更新的技术不断推出。
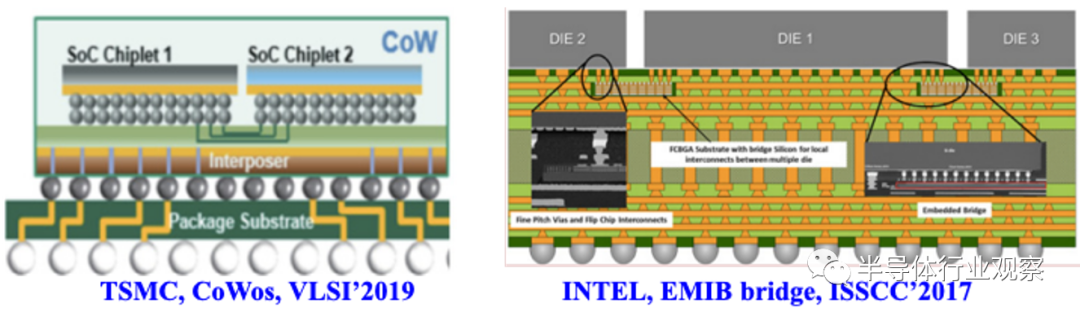
图5.台积电和Intel公开发表的先进封装技术
其次是用于Chiplet之间的高速通信接口电路设计,也就是Chiplet间通信的“物理层”设计。Chiplet之间的通信当然可以依靠传统的高速Serdes电路来解决,甚至可以完整的复用PCIe之类目前已经成熟的协议。但这些协议是用于解决芯片间甚至板卡间通信的,在Chiplet之间通信用会造成面积和功耗的浪费。目前专门研究Chiplet间高速通信接口的论文也不少,也有很多类似的IP核被各大公司研制出来。
通信协议是保证不同Chiplet之间能够顺利的完成数据交互的必要保证,也是决定Chiplet能否“复用”的前提条件。目前Intel公司推出了AIB协议、TSMC和Arm合作搞了LIPINCON协议,当然还有不少别的协议,在此不再赘述。虽然各家都在嚷嚷协议的重要性,但在目前的环境下Chiplet首先是“头部半导体”公司才会采用的技术,而这些公司“切”自己设计的大芯片然后再“封”起来自己说了算就行,并没有太多去和别的Chiplet互联互通的紧迫性。目前对于协议看得最重的应该是DARPA,因为DARPA所关心的市场属于量不大但特定需求多的市场。如果各家都按一定的标准来把自己的Chiplet通信接口和协议标准化了,那DARPA就可以“采众家之长”,从产品定义到最终产品实现之间的环节会少很多。这将大大提升美军信息技术的迭代能力,这也是DARPA推动电子复兴计划中“CHIPS”项目的初衷。其次跟着吆喝的是一些IP公司,如果实现了通信协议的统一,这些IP公司就有可能实现从“卖IP”到“卖Chiplet”的转型,开发出新的商业模式。
综合看以上几个方面,先进封装技术是Chiplet实施的基础和前提,事实上正是由于先进封装技术的突破才让Chiplet技术从构想走入现实。面向Chiplet的通信接口电路设计也很重要,相信这些已经实施了Chiplet的头部公司一定也有自己的设计。但如果“实在没有”,用现有技术凑合的话其实能勉强一用。至于通信协议,目前应该还属于“谁都说服不了谁”的阶段。其实这个也很正常,通信协议真正能够推开,最后就是“产品为王”。最后基于那个产品的协议占了主流,哪个协议也就成为了“事实标准”。Wishbone、CoreConnect、Avalone这些片上总线协议如今听过的人不多了的原因,无非是Arm作为最大的SoC方案供应商占据了大部分市场以后自然把其支持的AMBA协议簇给带火了。现阶段强行的去谈什么统一标准既没有意义也不现实,最终必然是“剩者为王”。更何况现阶段Chiplet还是“自家切了自家用”的阶段,只要这些头部公司内部统一了就行。从《全球工程前沿2021》报告中公布的合作网络也可以看出,目前各个机构之间的合作几乎没有。
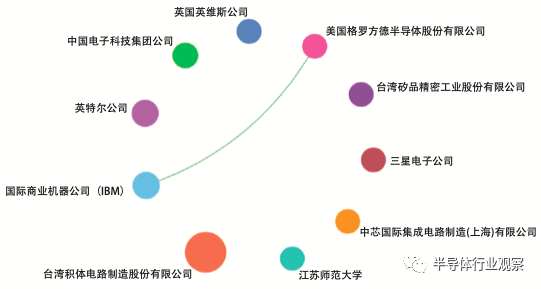
图6.各个公司在Chiplet技术上的合作网络
发展Chiplet要解决的第二大问题就是“设计方法学”的问题,说稍微直白一点就是:先进封装解决了如何“拼”的问题,但更重要的是要解决如何“切“的问题。半导体行业观察公众号前几日发表的“英伟达新论文,透露出GPU设计的无奈和未来”中详细的阐述了英伟达公司在决策下一代GPU要采用Chiplet技术时应该如何把一整个完整的大设计划分成多个Chiplet的思考和验证过程,这其实就是“设计方法学”的初步体现。而要让基于Chiplet的设计方法真正从“可用”变到“好用”,需要定义完整的设计流程以及研制配套的设计辅助工具。这一块展开说了又是一大段论述,为了节约篇幅在此不做详细阐述。
国内外发展Chiplet的“同”和“异”
Chiplet作为先进的集成电路技术,目前在国内也是有大量的公司和研究机构关注。有关Chiplet什么联盟、论坛之类的也有不少。但基于目前的国际形势和国内产业的实际发展水平,国内要面临的困难和国际头部IC设计公司并不相同。
以目前的国际形势下,国内集成电路产业最大的挑战来自于“封锁”,而最大的机会来自于“自主”。由于“封锁”的问题,让我们难以像以前那样非常方便的获取到先进制程来代工。这也很“巧合”的与Chiplet技术出现的原因类似:微缩的道路走不下去了,在单位硅片面积上增加晶体管数量有困难,只有转而追求在单个封装内部晶体管数还等持续提升。这也是目前发展Chiplet技术对于国内芯片产业最大的意义,当我们走传统方式延续摩尔定律的路子被“卡”断的时候,依然有一条“退而求其次”技术路线可以走。
虽然目的类似,但国内发展Chiplet的其它条件却和国际头部IC设计公司发展Chiplet并不相同。
从上面的分析我们可以看出,先进制程下采用Chiplet是由于良率问题而导致单个裸芯面积不能太大,而不得不去把大的设计“切”小。而我们要面临的问题是由于制程不够先进,单位面积上容纳的晶体管数量有限,继续去做大会面临电源噪声、功耗、良率等一系列问题。这两者之间有一定的相似性,都是要限制单个裸片上的晶体管数量,但背后的限制条件并不相同,这一点尚未有人进行深入的研究和比较。
先进封装技术是发展Chiplet的前提,前面已有论述。但先进封装技术和“传统封装技术”的差别其实和大,其工艺流程可以相互借鉴的不多。目前先进封装技术实际上是掌握在台积电、Intel这些传统被认为是“晶圆制造商”(Foundry厂)手中的,因为中介层的加工其实和“晶圆制造”而非“传统封装”更为接近。由于我不太掌握目前国内先进封装的技术能力到底到了哪一步,对此也不展开阐述,欢迎有知道的朋友评论区补充。我只是想强调的一点是:如果我们在先进封装技术能力上有差距,我们需要考虑在布线密度和信号带宽低于国际先进水平的限制下发展Chiplet技术,对此我们要有所准备。
第三个问题是目前国内缺乏大型系统级芯片定义与规划人才,也缺乏有能力规划Chiplet的头部设计公司。这其实是芯片产业整体欠账所导致的。目前国内设计能力最强的公司是海思,而海思也曾经在2014年就已经用Chiplet的方式完成过产品设计。根据公开的文献报道,海思的鲲鹏处理器也通过Chiplet的方式实现处理器的“系列化”。但除此之外,还未见有更多的商业成功案例。从“英伟达新论文,透露出GPU设计的无奈和未来”一文中可以看出将大的设计划分为多个Chiplet不但是一个技术问题,更是一个面向未来的产品规划问题。有“复杂大芯片”设计能力和经验的公司在国内屈指可数,有决心去规划这样的战略方向并敢于付诸实践的就更少。
最后一点,就是国内缺乏必要的Chiplet积累,包括技术积累和产品积累。与Intel、AMD等头部IC设计公司自身已经有非常成熟的复杂芯片产品不同,国内很多公司依赖于Arm、Synopsys等公司的全家桶产品支持和“保姆式”服务。还有很大一部分产品走的是“跟研”甚至是“仿制”的路线,对于复杂系统芯片的理解和掌控能力非常的弱。很多产品还在对标国外“中端”产品,尚未达到需要去“切分”的程度。更不用说具备一些“立等可用”的Chiplet成品。
所以,在中国发展Chiplet需要注意目前国内实际的产业状态。一方面Chiplet作为一种新的技术路线,确实给出了在单个裸片晶体管数量受限的情况下保持封装后芯片产品整体晶体管数量持续提升的方法;另一方面Chiplet绝不是解决目前国内芯片产业的“万能神药”,其局限和挑战同样很大,还会由于国内的特殊情况而导致新的挑战。
国内发展Chiplet可以采取的路线
通过前面的分析,大致谈了Chiplet技术产生的原因以及发展过程中面临的挑战,也简要分析了一下国内发展Chiplet要面临的一些与国际IC设计头部公司不同的困难。最后,简要结合作者的研究经验谈一些不太成熟的看法,供大家参考。
首先是要重点突破“先进封装技术”。从前文的分析可以看出,先进封装技术是实施Chiplet技术的前提。在不能大幅度提升布线密度和信号带宽的前提下发展Chiplet技术,就好像在不具备基础道路的国家发展物流产业,必然要受到极大的限制和阻碍。值得高兴的是,从各种公开报道和各种渠道的消息来看,目前国内在先进封装技术上取得了一定的成果。
其次是以要立足于国内芯片产业的现实,不以拔苗助长。目前国内芯片产业发展势头良好,但由于长期欠账导致人才、技术都相对匮乏,短期内不具备形成“聚合效应”的能力。也缺乏龙头性企业带动下迅速形成“生态”的可能性。所以目前现实的情况只能是各个企业根据自身情况选择合适的发展Chiplet技术的路线,而不能强行的依靠所谓的“联盟”、“标准化组织”搞圈地运动甚至强行推广某个标准或技术。要允许有一段“百家争鸣”的阶段。但后期应该以“赛马制”尽快挑选出能用的“良马”,发挥我国“集中力量办大事”的优势牵引推动产业链整合。
第三要认真研究目前国际头部IC设计公司的Chiplet技术路线差异,结合国内各厂商实际情况形成符合自身产业晋级的技术路线。目前各头部IC设计公司的Chiplet技术路线其实都有差异,例如AMD公司的CPU Chiplet+IOD模式,Intel 的“主Chiplet+外围Chiplets”模式等等,既建立在自身技术条件的基础上也考虑目标市场以及产品发展的具体需求。而目前国内面临的状况是在旧制程上“堆算力”的问题,因此“切”的问题要弱于“拼”。个人认为直接将现有成熟裸芯当成Chiplet,搭配必要的外围Chiplet来构建封装级的异构系统可能是目前最为实际、最能利用国内现有基础路线。
最后也是最重要的是应学习DARPA模式,以国家项目牵引打通上下游产业链的配套,实现具有我国特色的Chiplet产业模式从无到有的转换。虽然Chiplet在产业界已有雏形,但不能否认的是DARPA着力推动的CHIPS项目对于Chiplet的“催熟”作用。而我国在目前的国际战略态势下,更是需要以重大项目牵引,发挥Chiplet设计模式对于设计制造流程的优化,凸显其在小批量、多场景、系列化芯片产品上的优势。通过特定产品走通完整的技术路线,进而初步形成完整的产业链条。
以上就是本人一些不成熟的看法,欢迎大家批评指正。由于年底事情较多,导致本文完成的较为匆忙,对于某些技术文献的引用和对技术名词的解释存在一定不规范的地方,还请各位读者见谅。本文在完成过程中受到了中科芯集成电路有限公司的大力支持和帮助,在此表示诚挚的感谢。










