绑定手机号
确认绑定









由于上述领域相关的图片信息都具有十分复杂的背景,对待识别目标干扰性强,且通常存在目标重叠、相似度高、部分遮挡等问题,进行目标定位具有相当大的难度。

传统算法

传统的目标定位算法通常使用滑动窗的方法,主要可分为以下三个步骤:
候选框:利用不同尺寸的滑动窗,在图片中标记一块区域作为候选区;
特征提取:针对输入图片的候选区域,提取视觉特征(例如人脸检测常用的Harr特征、行人检测和普通目标检测常用的HOG特征等);
分类器识别:利用分类器进行目标和背景的判定,比如常用的SVM模型等。
上述传统算法在一些特定的应用方面已经取得了不错的成绩,但仍有不少缺点。首先,其需要手动提取图像特征,提取方法需要不断尝试比较才能得到好的特征;其次,提取的特征与模型性能的优劣直接相关,导致模型针对性强,不能灵活应用于其他情景;此外,有些算法中还涉及到复杂的边缘检测过程,包括阈值分割、分水岭算法等。繁杂的处理过程导致模型检测效率较低,无法满足在工业生产中的广泛应用。
深度学习
在2012年的ImageNet竞赛中,AlexNet神经网络一举成名,也使CNN成为了计算机视觉研究的中心,同时再一次掀起了深度学习的研究热潮。
2.1 R-CNN [1]
R-CNN是先进的视觉对象检测系统,它将自下而上的候选区域提取与卷积神经网络的丰富功能结合在一起。R-CNN在不使用上下文记录或要素类型集成的情况下实现了检测精度的大幅提升。
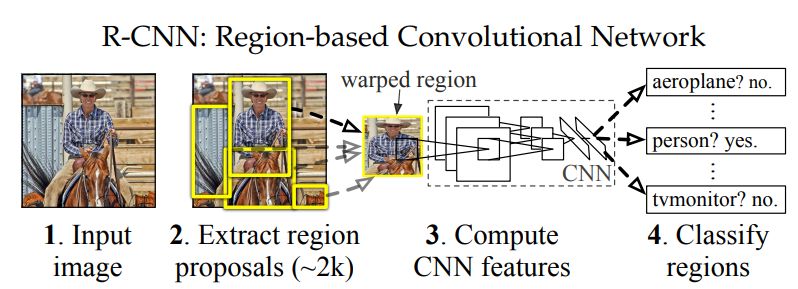
R-CNN算法的具体实现方法如下:
输入图片,基于区域候选方法(如selective search方法)生成约2000个候选区域;
对每个候选区域进行Resize,固定大小后送入CNN模型中并得到特征向量;
将特征向量送入一个多类别的分类器中,判断候选区域中所含物体属于每个类别的概率大小;
在R-CNN最后训练一个边界框回归模型,以提升目标定位的准确性。
本方法使用CNN网络自动提取特征,避免了手动提取特征的复杂操作,提升了工作效率。但由于每个候选区域都需要送入CNN模型计算特征向量,会耗费一定的时间。
2.2 Faster R-CNN[2]
Faster R-CNN是目标检测领域最经典的算法之一。它主要由用于生成候选区域框的深度全卷积网络和Fast R-CNN 检测模型两部分构成。
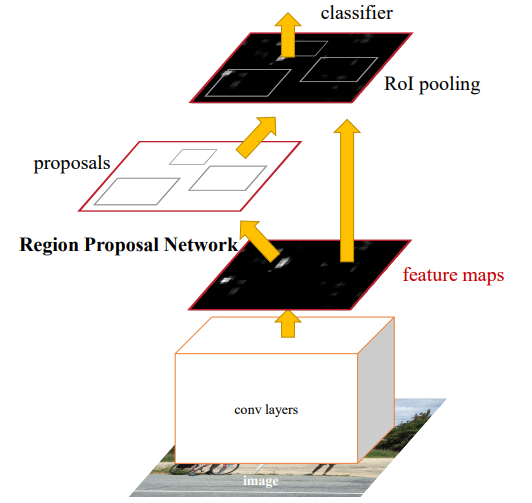
Faster R-CNN的网络结构如上图所示,由图中可以看出其由四部分组成:
Conv layers:对输入的整张图片,提取其特征图;
Region Proposal Networks:用于推荐候选区域(通过softmax判断anchors属于前景还是后景,并借助box regression修正anchors,输出多个候选区域);
ROI Pooling:将不同大小的输入转换为固定长度的输出,送入后续的全连接层判定目标类别;
Classification:输出候选区域所属的类别及其精确的位置。
RPN层是Faster R-CNN网络最大的亮点,使用RPN代替启发式候选区域的方法,极大的加快了训练的速度和精度。
2.3 Yolo v3 [3,4]
前面介绍的两种算法均为Two-stage,而Yolo属于One-stage,它不需要提取候选区域,可以直接产生物体的类别概率和位置坐标值,这里将针对目前更受欢迎的Yolo v3展开介绍。

Yolo v3的具体实现可以分为三步,分别为:
多尺度预测:借助残差网络结构形成了更深的网络层次,可以在三种不同的尺度上进行检测;
基础网络:使用Darknet的变体Darknet-53,在Imagenet上训练了53层网络,并在检测任务时再次堆叠53层,形成了106层完全卷积的底层架构;
分类器:使用多个logistic分类器,以进行多标签对象的分类。
作为Yolo算法多次优化后的产物,Yolo v3是当前目标检测最优的算法之一,其具有结构清晰,实时性好,可以通过改变模型结构的大小平衡速度与精度等优点。此外,Yolo v3还提升了小尺寸物体的检测效果,解决了前两个版本存在的问题。
2.4 SSD [5]
SSD算法(全称Single Shot MultiBox Detector)同Yolo一样属于One-stage,且整体稳定性比Yolo好很多,其网络结构如下图所示。

SSD的基本实现流程较Yolo复杂,可概括如下:
输入图片,使用卷积神经网络CNN提取特征,并生成特征图;
抽取其中6层的特征图,并在特征图的每个点上生成default box;
将所得的default box全部集合起来,并输入极大值抑制NMS中,筛选并输出最后的default box。
同样作为One-stage方法,SSD采用CNN直接检测的方法替代Yolo在全连接层之后做检测的方法提升了训练速度。此外,SSD提取不同尺寸的特征图,分别用来检测大小不同的物体;还使用不同尺度和长宽比的Anchors提升了定位准确度,实现了在高速运行的同时保持高精度的重大突破。
总结
本文参考前沿文献,总结了部分目前应用较为广泛的部分目标定位算法框架及具体思路。总的来说,目标定位检测可分为Two-stage(产生候选区+确定位置)和One-stage(直接产生物体的位置坐标值)两大类,均可以实现快速准确且鲁棒性好的目标定位,且可以灵活的应用于建筑业、航天工程以及工业生产等众多行业。
参考文献:
[1] Girshick R, Donahue J, Darrell T, et al. Region-based convolutional networks for accurate object detection and segmentation[J]. IEEE transactions on pattern analysis and machine intelligence, 2015.
[2] Ren S, He K, Girshick R, et al. Faster r-cnn: Towards real-time object detection with region proposal networks[C]//Advances in neural information processing systems. 2015.
[3] Redmon J, Farhadi A. Yolov3: An incremental improvement[J]. arXiv preprint arXiv:1804.02767, 2018.
[4] https://towardsdatascience.com/yolo-v3-object-detection-53fb7d3bfe6b.
[5] Liu W, Anguelov D, Erhan D, et al. Ssd: Single shot multibox detector[C]//European conference on computer vision. Springer, Cham, 2016.












