绑定手机号
确认绑定









你见过乐器自己演奏么?看看这个:

图1. "活灵活现"的虚拟乐器还是在 NVIDIA 服务器房间里面"尽情"般表演
这正是 NVIDIA Research 在庆祝爵士乐及其发源地新奥尔良的视频中展示的技术。Follow 前沿 AI 的同学应该知道 CVPR 2022 线下会议当前正在美国新奥尔良城市火热举办中,可谓相当应景!
上述演示的 Demo 技术是被称为 "NVIDIA 3D MoMa",此技术可以让游戏开发者、建筑师、设计师等快速将目标物导入图形引擎,并对其进行处理:修改大小、改变材料或不同的照明效果。这项研究大大节省了内容创作者产出成果所需的时间和精力。
下面将深入聊聊 NVIDIA 3D MoMa 背后的 CVPR 2022 (Oral) 顶会论文及算法细节。

Extracting Triangular 3D Models, Materials, and Lighting From Images
主页:https://nvlabs.github.io/nvdiffrec/
论文(已支持下载):
https://nvlabs.github.io/nvdiffrec/assets/paper.pdf
代码(已开源):
https://github.com/NVlabs/nvdiffrec
一句话总结:本文提出了一种 2D 多视图图像到 3D 重建的新工作,即一种从多视图图像观察中联合优化拓扑、材料和照明的高效可逆渲染(inverse rendering)方法,其能够从多视图图像中提取具有空间变化材料和环境照明的未知拓扑的三角形网格(triangle meshes),并可以在任何传统和现代图形引擎中部署。

图2. 2D 多视图图像生成 3D 重建
多视图 3D 重建
神经隐式表示(Neural implicit representations):本文优化了显式网格表示的端到端图像损失,通过设计支持形状、材料和照明的内在分解,并利用有效的可微分光栅化。
显式表面表示(Explicit surface representations):本文将 DMTet(Deep Marching Tetrahedra) 扩展到 2D 监督,使用可微分渲染来联合优化拓扑、材料和照明。
BRDF 和照明估计
本文提出了一种可微分 split sum 照明模型。
本方法的输出直接与现有的渲染器和建模工具兼容。
本文优化了存储在 HDR probe 中的显式表面网格、BRDF 参数和光照,实现了更快的训练速度和更好的分解结果。
下表显示了本文方法与当前先进的 3D 重建方法的比较。

表 1. 方法分类。NV:神经体素,NS:神经表面
本文提出了一种 3D 重建方法,该方法由在未知环境照明条件下照明的物体的多视图图像以及已知的相机姿态和背景分割掩码监督。目标表示由三角形网格、空间变化的材料(存储在 2D 纹理中)和照明(高动态范围环境探测器)组成。本文精心设计优化任务以显式渲染三角形网格,同时稳健地处理任意拓扑。因此,与最近使用神经隐式表面或体素表示的工作不同,本文直接优化目标形状表示。
本文方法的框架如下图所示:

图3. 方法框架
1. 拓扑学习
具体来说,本文将 DMTet(Deep Marching Tetrahedra)修改为在 2D 监督的设置中工作,并共同优化形状、材料和照明。在每个优化步骤中,形状表示——在网格上定义的有符号距离场 (SDF,signed distance field) 的参数,具有相应的每个顶点偏移——使用 MT(marching tetrahedra)层转换为三角形表面网格。SDF 通过 MT 层转换成三角形网格的示意图如下所示:
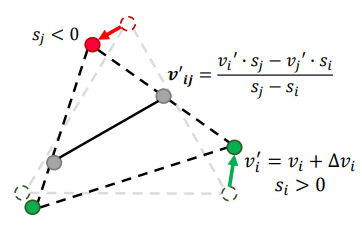
图4. MT(marching tetrahedra)提取转换
本文将生成的网格与相关竞争方法生成的网格进行了比较。虽然 NeRF(volumetric rep)和 NeuS(implicit surface rep)提供了高质量的视图插值(view interpolation),但在 MC 步骤中引入的质量损失在三角形计数较低时非常显著。

图5. 从一组 256 个带 masks 的渲染图像中提取三角形网格
2. 渲染模型
2.1 材料模型
接下来,本文在具有延迟渲染(deferred shading)的可微分光栅器(differentiable rasterizer)中渲染提取的表面网格,并与参考图像相比,计算渲染图像上图像空间的损失。并使用了基于物理的渲染(PBR,Physically Based Rendering)。

图6. 将 3D 模型表示为三角形网格和一组遵循标准 PBR 模型的空间变化材料
2.2 Texturing
表面网格的自动纹理参数化是计算机图形学中一个活跃的研究领域。本文优化拓扑,这需要不断更新参数化,可能会在训练过程中引入不连续性。
为了在拓扑优化期间稳健地处理纹理,本文利用体素(volumetric)纹理,并使用世界空间位置来索引纹理。这确保了映射随着顶点平移和拓扑变化而平滑变化。

图7. 对体素表示进行采样以创建 2D 纹理会产生纹理接缝(左)。然而,进一步优化(右),可以快速自动去除接缝
这样生成的 2D 纹理与标准 3D 工具和游戏引擎兼容。
3. 基于图像的照明
本文采用基于图像的照明模型,其中场景环境照明由高分辨率 cube map 生成。
本文从实时渲染中汲取灵感,其中 split sum approximation 是一种流行的、有效的基于全频图像的照明方法。这里引入了 split sum 渲染模型的可微分版本,以通过可微分渲染从图像观察中学习环境照明。本文让 cube map (典型分辨率为 6 × 512 × 512)的纹素作为可训练参数。
为了获得纹素梯度,本文使用 PyTorch 的自动微分来表达光照计算。另外还创建了一个过滤后的低分辨率(6×16×16)cube map 来表示漫反射光照。
注:篇幅有限,关于算法的更多细节,建议阅读原文进行消化。
本文在实验中,针对各种应用评估了上述算法。为了强调此方法明确分解为三角形网格和材料,本文使用现成的工具展示了重新照明、编辑和模拟。
本文还比较了最近支持分解的神经方法:NeRD 和 NeRFactor,而且包括视图插值结果,最后,将 split-sum approximation 与基于图像的照明的球面高斯(SG,spherical Gaussians)进行比较。
1. 场景编辑和仿真
本文方法分解场景表示支持高级场景编辑,而以前使用基于密度的神经表示的工作仅支持基本的重新照明和简单形式的场景编辑。
在下图中,本文将使用 Blender Cycles 路径跟踪器渲染的重建模型的重新照明质量与 NeRFactor 的结果(通过评估神经网络渲染)进行了比较。

图8. 重新照明比较
下表中提供了定量总结,本文还测量了重建的反照率(albedo)纹理的质量。可以注意到,本文方法产生了更详细的结果,并且在所有指标上都优于 NeRFactor。
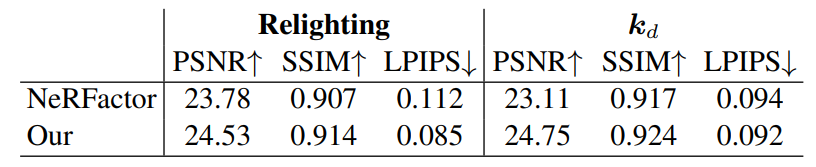
表 2. NeRFactor 合成数据集的重新照明质量。报告的图像指标是所有 4 个测试场景的 8 个验证视图和 8 个照明 probes 的算术平均值
本文方法的表示可以直接部署在可用于三角形网格的大量 3D 内容生成工具中,这极大地促进了场景编辑。图 9 中展示了高级场景编辑示例,其中将来自 NeRFactor 数据集的重建模型添加到 Cornell box 中,并在软体模拟中使用它们。请注意,本文的模型接收场景照明,投射准确的阴影,并稳健地充当虚拟对象的碰撞器。

图9. 为了突出显式表示的好处,本文将两个重建模型插入到 Cornell box 中。
2. 视图插值
2.1 合成数据集
表 3 显示了 NeRF 真实合成图像数据集的结果,在图 10 中显示了 MATERIALS 场景的视觉示例。本文方法始终与 NeRF 性能相近,在某些场景中质量更好。基于感知的图像指标(SSIM 和 LPIPS)的边距较小。
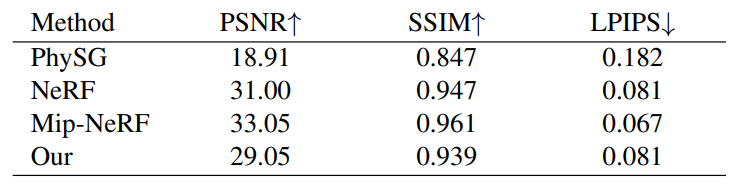
表 3. NeRF 真实合成数据集中八个场景的平均结果。

图10. 本文在 MATERIALS 场景中的结果,由来自 NeRF 合成数据集的 100 张图像重建。
2.2 真实世界数据集
NeRD 提供了一个小型真实世界照片扫描数据集,具有自动生成的(不准确的)覆盖蒙版和不同的相机位置。
视觉和定量结果如图 11 所示。由于数据集中的不一致,NeRF 和 NeRD 都很难找到带有透明“ floaters ”和孔洞的清晰几何边界。相比之下,本文方法得到了清晰的轮廓和图像质量的显著提升。

图11. 从照片重建(来自 NeRD 的数据集),将本文方法结果与 NeRD 和 NeRF 的结果进行比较。
3. 比较球面高斯和 Split Sum
在图 12 中,本文将可微分 split sum 环境照明近似值与常用的球面高斯 (SG) 模型进行了比较。Split sum 在所有频率上更好地捕获照明,同时具有较低的运行时成本。这里观察到与具有 128 lobes 的 SG 相比,优化时间减少了 5 倍。在推理时,评估分割和近似值非常快,只需要两次纹理查找。
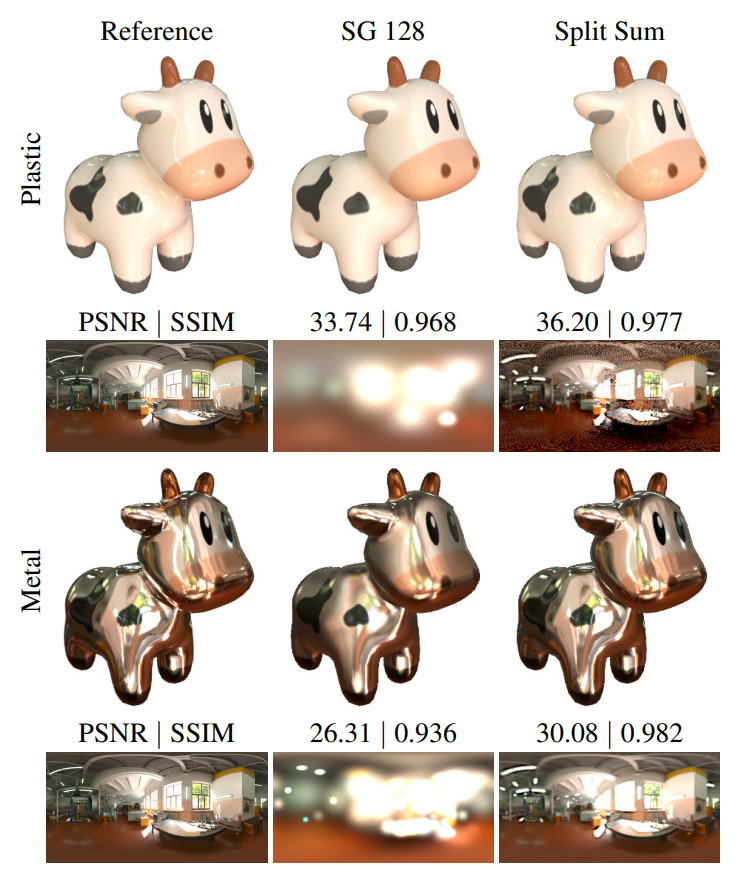
图12. 使用 128 lobes 与 Split Sum 用球形高斯近似的环境照明
总之,本文展示了与视图合成和材料分解的最新技术相当的结果,同时直接优化了显式表示:具有材料和环境照明的三角形网格。通过设计,本文方法的表示直接与现代 3D 引擎和建模工具兼容,从而支持大量应用并简化了工作流程。本文方法可以用作外观感知转换器,从(神经)体素或 SDF 表示到具有材料的三角形 3D 模型,补充了许多最近的技术。
上述介绍的就是 NVIDIA 3D MoMa 技术背后的算法。生成的 3D 模型无需转换即可部署在任何支持三角形渲染的设备上,包括手机和 Web 浏览器,并以交互速率进行渲染。据了解,NVIDIA 3D MoMa 在单个 NVIDIA Tensor Core GPU 上一小时内就可以生成三角形网格模型。
虚拟爵士乐队的乐器:从 2D 到 3D
为了展示 NVIDIA 3D MoMa 的应用场景和性能,NVIDIA 研究团队从不同角度收集了五种爵士乐队乐器(小号、长号、萨克斯管、架子鼓和单簧管)的多视图图像,每种乐器分别被拍摄约 100 多张图像。

图13. 从不同角度拍摄乐器图像
NVIDIA 3D MoMa 将这些 2D 图像重建为每个乐器的 3D 表示。然后 NVIDIA 团队将这些乐器从其原始场景中取出,并将它们导入 NVIDIA Omniverse 3D 模拟平台进行编辑。
在 NVIDIA Omniverse 中编辑 3D 模型
在任何传统的图形引擎中,创作者都可以轻松改变由 NVIDIA 3D MoMa 生成形状的材料。比如这里用 NVIDIA Omniverse 将小号、萨克斯管等乐器的材料替换成黄金、白银、木材等。

图14. 在图形引擎中编辑 3D 模型

图15. 编辑乐器材料
然后,创作者可以将新编辑的对象放入任何虚拟场景中。这里 NVIDIA 团队将这些乐器放入 Cornell box 中。由下图可知,虚拟乐器对光的反应就像在真实的物理世界中一样,闪亮的铜管乐器反射出明亮的光,哑光鼓皮吸收光。

图16. 动态照明和物理世界
这些通过逆向渲染生成的新对象可以用作复杂动画场景的构建块,比如这里以文章开头的虚拟爵士乐队的形式展示。
更多技术细节可以阅读原论文和代码进行学习,更多应用展示可以点击下方视频进行观看。
NVIDIA 这项技术可以帮助创作者快速将 2D 图像变成 3D 物体,而且兼容传统和现代 3D 引擎和建模工具。这将极大地简化建筑师、设计师、游戏开发者和艺术家等创作者的工作流程,提高整体工作效率。
算法代码已开源!









