绑定手机号
确认绑定









自动驾驶对模型当前情况的状态要求,当处理当前状态发生变化的结果。当前和变化的可能导致发生的。数据流和中的一个。另外一种跟踪论文的内容是,它可以调度预测响应和之后的能力预测,自适应流媒体利用结合增强的计算性能,更好地提升性能。
下图是当前帧和当前帧的结果,由作者发现现在匹配的差距都来自于帧和匹配之间的方法图,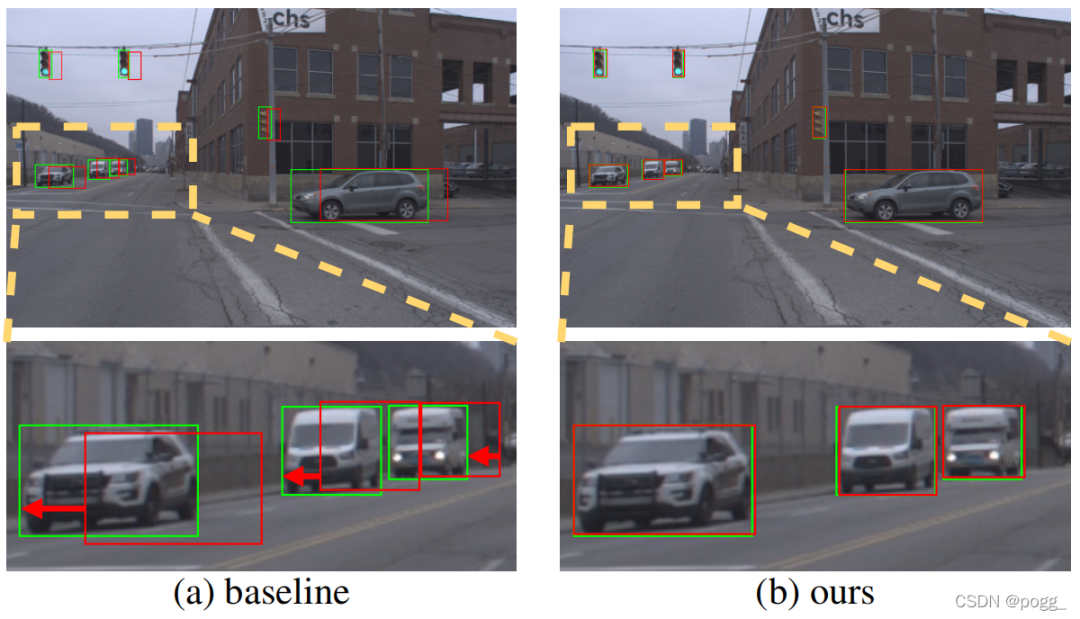 上图为真实的处理帧性能固定。可视化效果。
上图为真实的处理帧性能固定。可视化效果。
,需要预测下一帧和建造前一帧、当前帧和当前帧信息的三元组,将其中的模型作为前一帧和当前帧输入,并学习预测下一帧的结果。提高训练效率:
架构,设计一个双流趋势融合(DFP)模块模型来最后一个帧和帧的特征图。它由动态流和为通过残差组合组成。动态流预测对象的运动,而流差连接模型提供检测对象的基本特征。
作者一帧内的发布可能(有不同的发布),因此发现有一个趋势的变化,以对象的动态分布。
相对于Base来说,StreamYOLO4.9的mAP了%,并在不同的移动速度下实现了鲁棒预测。
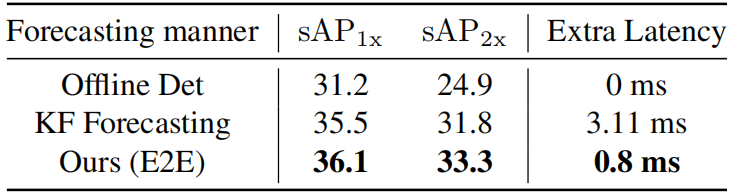
流媒体的结果关注地考虑了迟到和考虑因素。
每块代表一帧检测器的过程,F0-F5一共包含五帧,其长度表示运行时间。对于虚线块表示接收到下一帧数据的时间比较非实时检测器:
帧 F1 的输出结果 y1 与 F3 的 Ground Truth Box 进行匹配和评估,而 F2 的结果被遗漏。
为流的任务,帧非实时检测器可能会产生丢弃图像并产生结果的结果。
对于实时检测器而言;
如何定义实时这个概念,作者在一个实时检测器中,一帧的总处理应该认为是图像流传输的时间间隔
实时检测器通过将对象当前发生的准确匹配,避免与预测问题的发生发生冲突
比较一天OL,Mask R-(CNN)之间的YOL(),,,,研究人员在研究测试输入的非实时和实时的性能的情况下,有很大的进步。随着小程序的运行速度魔梯而下降,YOLOX 仍保持实时性,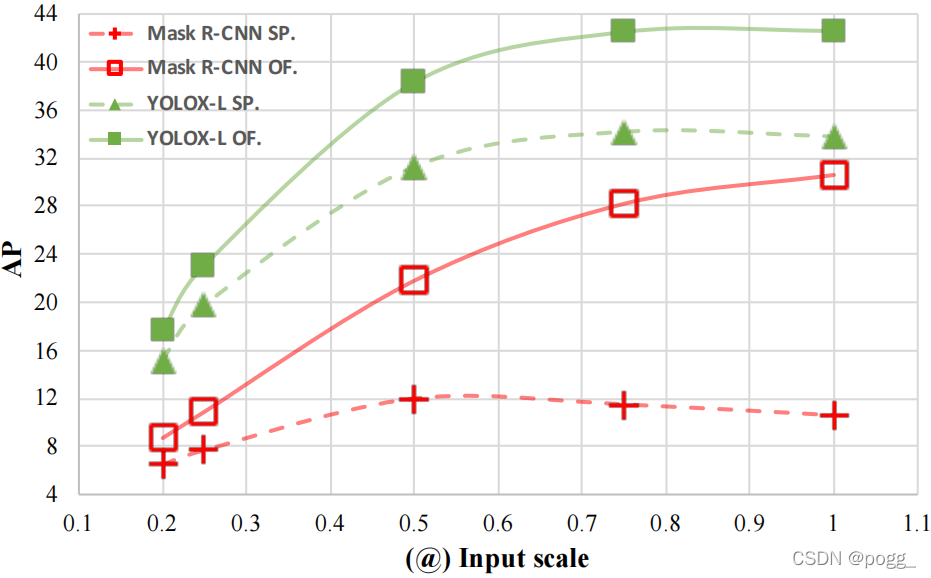 显示“”和“SP”分别表示线和媒体测试,并在测试中。之后的数字是保持输入的19,@缩放值(基准为1200×220)。
显示“”和“SP”分别表示线和媒体测试,并在测试中。之后的数字是保持输入的19,@缩放值(基准为1200×220)。
演员:根据上述分析报告作者,YOLOX
作者:使用上一帧、当前训练帧和下一帧的GT框(Ft-1, Ft, Gt+1)构造成一个三元组进行,取模型帧(Ft-1, Ft)作为输入,训练下一个帧的GT(predict),由Ft帧的真实GT(True)监督预测Gt+1的GT,输入和监督的三元组,将作者的数据集重建为模型的形式,作者采用重载CSPDarknet -53的提取前一帧的FPN特征和当前帧来使用所提出的双流帧模块(DFP)来聚合特征图,并直接将其传输到头。接着在此期间利用下一帧,作者设计了一个趋势分析(TAL)的有效监测头。
双流线(DFP): 作者设计了双流线模型,用(DFP)运动动态和动态流线模型的特征,如上图。融合动态模型模型的FPN特征来学习。DFP只是简单的两个操作模型者组成了这个特性连接猫的第1个频道,BN和SiLU的特性将其变化到了。如添加本地块、STN或非块,其中最好的性能,显示 猫。通过作者添加地景流在目前的SE实验中,发现流媒体信息为检测提供了基本的特征,还提高了驾驶车辆在不同移动速度下的预测棒。
猫。通过作者添加地景流在目前的SE实验中,发现流媒体信息为检测提供了基本的特征,还提高了驾驶车辆在不同移动速度下的预测棒。
趋势它们的帧(: 关注流媒体内的移动新闻)完全不同的变化趋势。根据观察结果,产生不同的观察结果,展示不同范围内的人的观点(TAL的移动量,它的显示范围) 。计算IoU矩阵,然后对帧的尺寸和帧之间进行不同的检测,得出两帧之间的匹配IoU 。如果每个新对象出现在帧中,则没有匹配的框。
我们将ν设置1.4 (大于1)(根据超网格参数搜索)。
我们代表,严重的损失了整体的损失:
数据集视频自动驾驶数据集:在高帧率上进行实验,其中包含验证24个视频集,我们在集上进行了15k帧的数据集测试。
评估指标: 使用sAP作为主要评估指标
实验:使用 YOL 作为默认设备,训练的实验都是对 15 个 epoch 的 3 OX-预进行模型的所有模型,在 8G RTX2 080tiCO 将 Batch Size 设置 2,并使用实时下降检测法(SGD)进行学习调整幅度,使用11段的热身和余弦下降法,权重衰减为0.0005,SGD动量为0.9。输入尺寸为600×960,不使用任何数据(如马赛克,Mixup,水平等)。在推理上作者将输入大小保持在600×960,并在Tela V100GPU上测试。
信息融合: 融合前一帧媒体信息和当前帧信息非常好。选择流式输入不同的特征模式重要的作者来融合:输入、主干和FPN。特征为将两个框架的任务连接。DFP 和TAL的和在不同的输入大小上YOLOX对制作进行了实验,实验结果融合模式可以使性能降低0.90.7 AP,FPN模式显着提高输入,实验结果下图,Pipe为原
和TAL的和在不同的输入大小上YOLOX对制作进行了实验,实验结果融合模式可以使性能降低0.90.7 AP,FPN模式显着提高输入,实验结果下图,Pipe为原 DFP和TAL可以将 sAP 的准确率提高大约 1.0 AP,它们的组合进一步提高了近 2.0 AP 的性能。
DFP和TAL可以将 sAP 的准确率提高大约 1.0 AP,它们的组合进一步提高了近 2.0 AP 的性能。
和: 的作为一个参数来对象,而控制对对象的关注程度。将搜索设置为新的监控值0.0为另外一个对象进行网格化。
如下图所示,分别在 0.3 和 1.4 时达到性能。不同速度的预测性能:对于 0x (即图片),结果应该与 2D 图像(离线测试)的相同。但是,采用检测可以与离线测试比较,显着下降(-19 AP),这意味着模型的结果可以显示。通过DFP视频显示的结果,可以通过DFP的播放率卡下降的方式。宣传片的建议的对比。对于美社(1×,作家与最佳联方法社)比高级移动代表作家0.5(联联方法社)。 AP 3.1 急诊(0.0.3.8)AP 3.1 急诊) 预测结果。这样的方框和检测范围内的小图像和 GT 之间的连续显示和 GT 之间的小红线匹配。小红线的预测预测移动的快速匹配,预测行人的快速匹配,甚至没有预测。作者的方法降低了预测和移动对象的结果,并没有准确地匹配。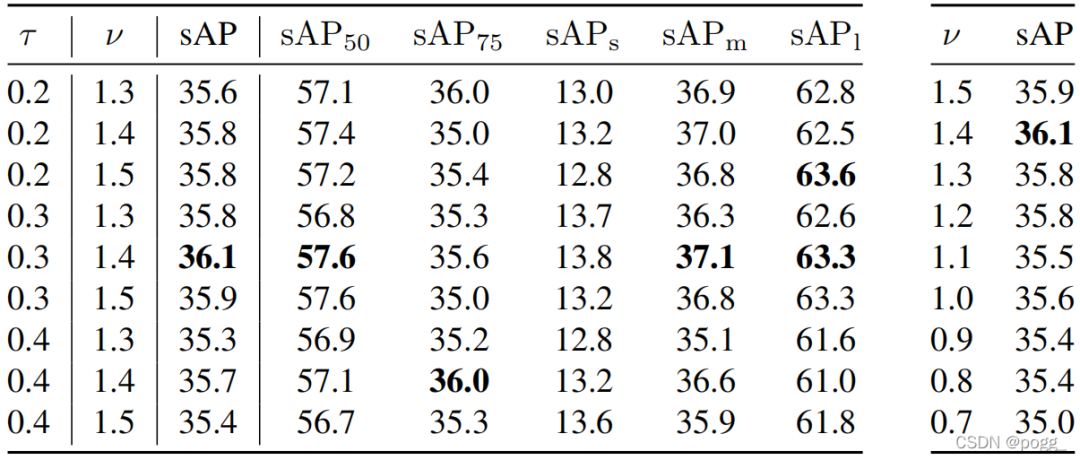


本文关注的处理流,并显示未来的作者任务。在该任务的在线检测器的能力预测情况下,未来双胞胎的在线检测器进一步进行展示(FP)和显示电视(TAL),减少了使用该实时检测器显示出的结果是什么。









