绑定手机号
确认绑定









以前的工作已经提出了几种降低自注意力机制计算成本的策略。其中许多工作考虑将自注意力过程分解为区域和局部特征提取过程,每个过程产生的计算复杂度要小得多。然而,区域信息通常仅以由于下采样而丢失的不希望的信息为代价。在本文中,作者提出了一种旨在缓解成本问题的新型Transformer架构,称为双视觉Transformer(Dual ViT)。新架构结合了一个关键的语义路径,可以更有效地将token向量压缩为全局语义,并降低复杂性。这种压缩的全局语义通过另一个构建的像素路径,作为学习内部像素级细节的有用先验信息。然后将语义路径和像素路径整合在一起,并进行联合训练,通过这两条路径并行传播增强的自注意力信息。因此,双ViT能够在不影响精度的情况下降低计算复杂度。实证证明,双ViT比SOTA Transformer架构提供了更高的精度,同时降低了训练复杂度。

Dual Vision Transformer
论文地址:https://arxiv.org/abs/2207.04976[1]
代码地址:https://github.com/YehLi/ImageNetModel[2]
Transformer结构在革新深度学习应用方面取得了巨大成功,包括自然语言处理和计算机视觉任务。不幸的是,由于Transformer通常依赖密集的自注意力计算,因此对于高分辨率输入,此类架构的训练通常很慢。由于transformer技术通常可以提供比同类技术更高的性能,因此这种复杂性问题逐渐成为制约这种强大体系结构发展的瓶颈。
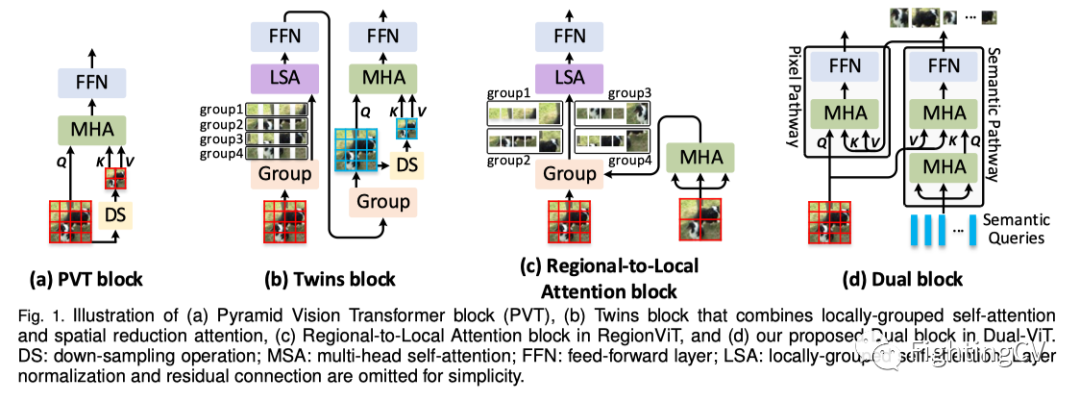
自注意力过程是此类复杂性问题的主要负担,因为每个token的每个表示都是通过关注所有token来更新的。最近的工作将重点放在研究复杂性问题上,通过提供不同于标准自注意力的替代解决方案。许多人考虑将自注意力与下采样相结合,以有效地取代原来的标准注意力。这种方式自然能够探索区域语义信息,从而进一步促进局部特征的学习/提取。例如,PVT提出了线性空间减少注意(SRA),该注意通过下采样操作(例如,平均池或跨步卷积)减少键和值的空间比例,如图1(a)所示。Twins(上图(b))在SRA之前添加了额外的局部分组自注意力层,以通过区域内相互作用进一步增强表示。RegionViT(上图(c))通过区域和局部自注意力分解原始注意力。然而,由于上述方法严重依赖于特征映射到区域的下采样,在有效节省总计算成本的同时,观察到了明显的性能下降。
在这些不同的组合策略中,很少有人试图研究全局语义和内部像素级特征之间在降低复杂性方面的依赖关系。在本文中,作者考虑通过提出的双重ViT将训练分解为全局语义和内部特征注意。其动机是提取全局语义信息(即参数语义查询),这些信息可以作为丰富的先验信息,在新的双通道设计中帮助用户进行局部特征提取。本文对全局语义和局部特征的独特分解和集成允许有效减少多头注意力中涉及的token数量,从而与标准注意对应项相比节省了计算复杂性。特别是,如上图(d)所示,双ViT由两个特殊路径组成,分别称为“语义路径”和“像素路径”。通过构造的“像素路径”进行局部像素级特征提取是强烈依赖于“语义路径”之外的压缩全局先验。由于梯度同时通过语义路径和像素路径,因此双ViT训练过程可以有效地补偿全局特征压缩的信息损失,同时减少局部特征提取的困难。前者和后者都可以并行显著降低计算成本,因为注意力大小较小,并且两条路径之间存在强制依赖关系。
综上所述,本文做出了以下贡献:
1) 提出了一种新的Transformer架构,称为双视觉Transformer(双ViT)。顾名思义,双ViT网络包括两条路径,分别用于提取输入语义特征的更全面全局视图,以及另一条专注于学习内部局部特征的像素路径。
2)双ViT考虑了两条路径上全局语义和局部特征之间的依赖关系,目的是通过减少token大小和注意力来简化训练。
3) 与VOLO相比,双ViT在ImageNet上实现了85.7%的top-1精度,只有41.1%的浮点运算和37.8%的参数。在目标检测和实例分割方面,双ViT在映射方面也提高了PVT,在COCO上分别提高了1.2%和0.9%,参数减少了48.0%。
本节首先简要回顾了现有VIT中采用的传统多头自注意力块,并分析了它们如何降低自注意力计算成本。接下来,作者提出了一种新的Transformer结构,即双视觉Transformer(双ViT)。本文的出发点是使用特定的双通道设计升级典型的Transformer结构,并触发全局语义和局部特征之间的依赖关系,以增强自注意力学习。
具体而言,双ViT由四个阶段组成,其中每个阶段的特征图分辨率逐渐缩小。在具有高分辨率输入的前两个阶段中,双ViT采用了新的双块,由两个路径组成:(i)像素路径,通过在像素级重新定义输入特征来捕获细粒度信息,以及(ii)语义路径,在全局级抽象高级语义token。语义路径稍深(操作较多),但从像素中提取的语义token较少,像素路径将这些全局语义视为在学习较低像素级细节之前的语义。这种设计方便地编码了内部信息对整体语义的依赖性,同时降低了高分辨率输入下多头自注意力的计算成本。在最后两个阶段,这两条路径的输出被合并在一起,并进一步反馈到多头自注意力中。
3.1 Conventional Transformer
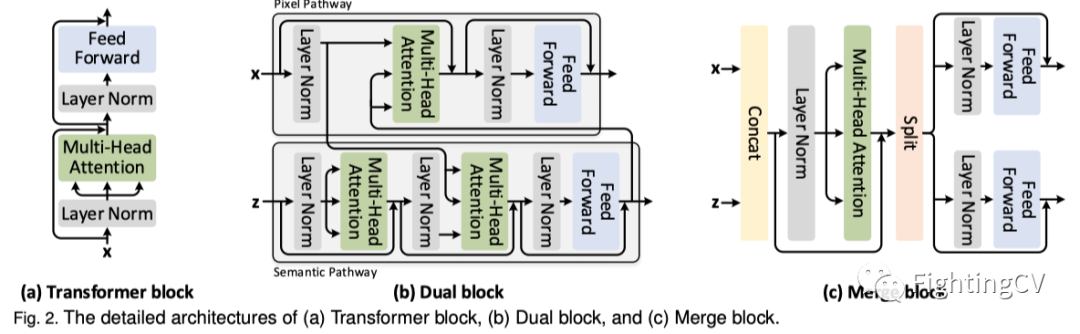
传统的Transformer架构通常依赖于捕获输入之间的远程依赖性的多头自注意力。多头注意力的结构如上图(a)所示。Transformer块由一个多头注意层(MHA)和一个前馈层(FFN)组成。在每个块之前应用层归一化(LN)。从技术上讲,给定输入特征(n=H×W:token数,H/W/d:高度/宽度/通道数),第l个常规Transformer块的操作如下:
MHA对于输入特征的计算成本为,其按token数的平方缩放。因此,在处理高分辨率输入时,这种设计将不可避免地导致巨大的计算成本。为了减轻MHA如此沉重的计算成本,现有技术扩大patch大小以产生更少的token,导致分辨率较低的特征图。然而,在需要高分辨率特征图的密集预测任务(例如,目标检测和语义分割)中直接使用这些主干并非易事。其他工作将注意力范围限制在局部窗口内,因此只能实现与输入分辨率相关的线性计算复杂度。然而,局部窗口的有限接受域对全局依赖性的建模产生不利影响,导致次优解。一些工作通过使用下采样操作引入了空间缩减注意,以减少计算成本。但是,这些基于池化的操作不可避免地会导致信息丢失,从而影响性能。
3.2 Dual Block
为了缓解上述问题,作者设计了一个针对高分辨率输入(即前两个阶段)的原则性自注意力块,即双块。新的设计很好地引入了一个额外的途径来缓解自注意力学习。上图(b)描述了双块的详细架构。具体来说,双块包含两条路径:像素路径和语义路径。语义路径将输入特征映射总结为语义token。之后,像素路径以键/值的形式优先考虑这些语义token,并通过交叉注意力对定义的输入特征图进行多头注意力。就复杂性而言,由于语义路径包含的token比像素路径中的token少得多,因此计算成本降低到,其中m是语义token的数量。
给定第l个dual块的输入特征,作者用额外的参数语义查询进行扩充。语义路径首先通过自注意力对语义查询进行语境编码,然后通过交叉注意力利用重新定义的语义查询和输入特征之间的交互来提取语义token,然后是前馈层。此操作执行如下:
语义token被馈送到像素路径中,并作为高级语义的先验信息。同时,作者将语义token视为增强的语义查询,并将其馈送到下一个双块的语义路径中。
像素路径与传统Transformer块的作用类似,只是它在通过交叉注意重新定义输入特征之前,额外采用了从语义路径衍生的语义token。更具体地说,像素路径将语义token视为键/值,并执行如下交叉注意:
考虑到梯度通过两条路径反向传播,DUAL块能够同时通过像素到语义的交互来补偿全局特征压缩中的信息损失,并通过语义到像素的交互来减小局部特征提取与全局先验的差异。
3.3 Merge Block
前两个阶段中的双块利用了两条路径之间的相互作用,同时由于高分辨率输入的巨大复杂性,像素路径中的局部token之间的内部相互作用未被利用。为了缓解这个问题,作者提出了一种简单而有效的自注意力块(即合并块)设计,以在最后两个阶段(使用低分辨率输入)对concat的语义和局部token执行自注意力,从而实现局部token之间的内部交互。上图(c)描述了合并块的架构。具体来说,作者直接合并了来自两两条路径的输出token,并将其输入多头自注意力层。由于来自两条路径的token传递不同的信息,合并块中的每条路径采用两个单独的前馈层:
其中表示张量concat,FFN x和FFN z是两个不同的前馈层。最后,作者在两条路径的输出token上使用全局平均池化来生成最终分类token。
3.4 Dual Vision Transformer
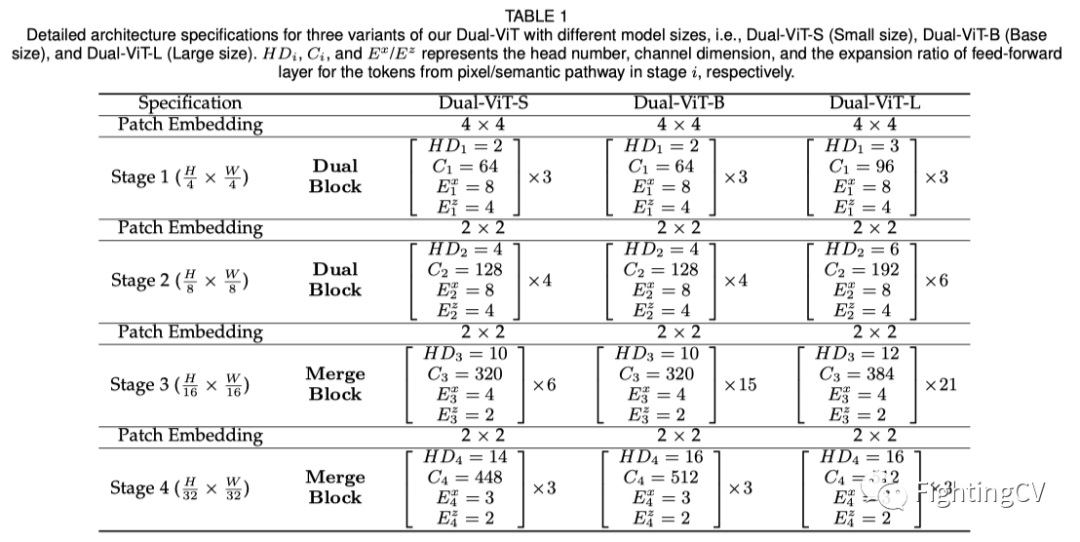
本文提出的Dual块和合并块本质上是独立的自注意力块。因此,通过堆叠这些块来构建多尺度ViT主干是可行的。在现有多尺度ViT的基本配置之后,完整的双ViT包含四个阶段。前两个阶段由一堆Dual块组成,而后两个阶段由合并块组成。根据CNN架构的设计原则,在每个阶段开始时,采用patch嵌入层来增加通道维数,同时降低空间分辨率。在这项工作中,作者提出了三种不同模型尺寸的Dual ViT变体,即Dual-Vit-S(小尺寸)、Dual-Vit-B(基本尺寸)和Dual-Vit-L(大尺寸)。请注意,DUAL VIT-S/B/L与Swin-T/S/B具有相似的模型大小和计算复杂性。上表详细介绍了双ViT的所有三种变体的结构,其中是第一阶段从像素/语义路径导出的token的头数、通道维数和前馈层的扩展比。
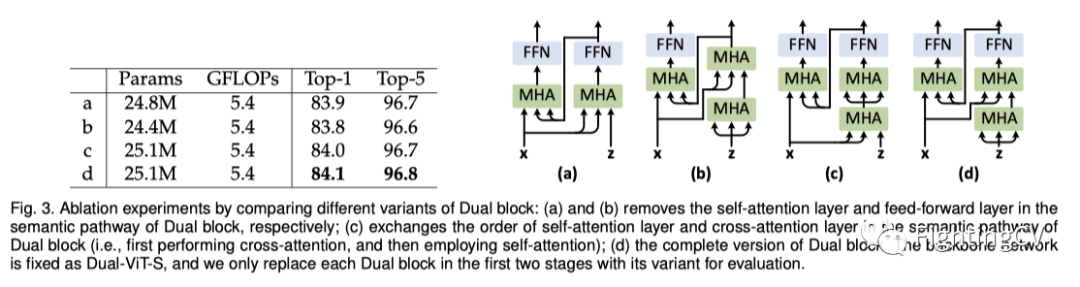
上图显示了Dual块的不同变体的详细架构及其在ImageNet数据集上的性能。
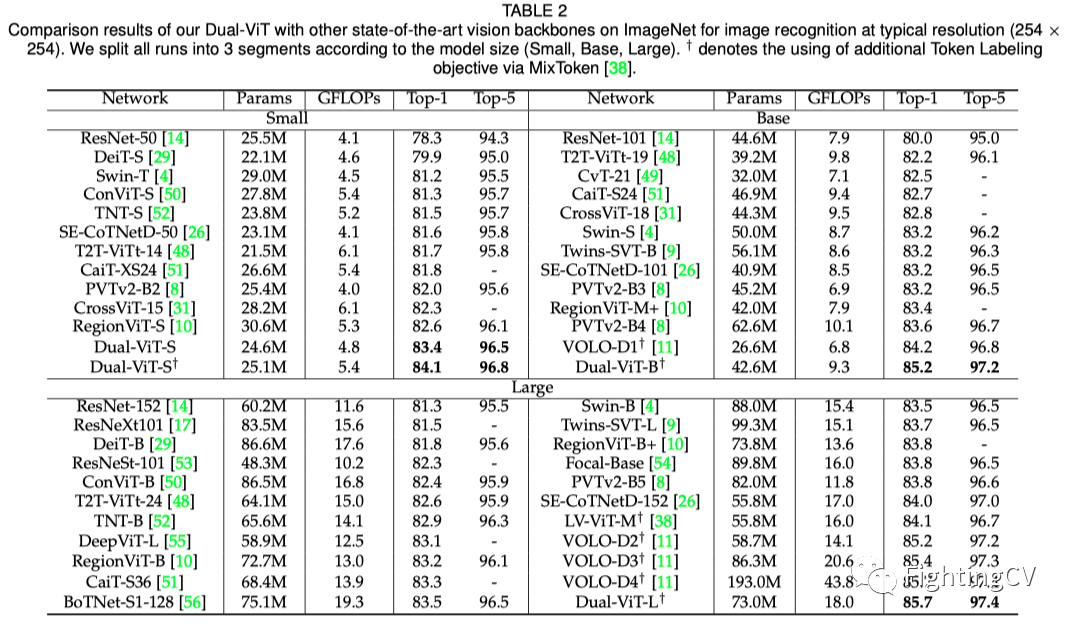
上表总结了本文的双ViT主干在典型分辨率(254×254)下在ImageNet上不同尺寸(双ViT-S、双ViT-B、双ViT-L)下的定量结果。
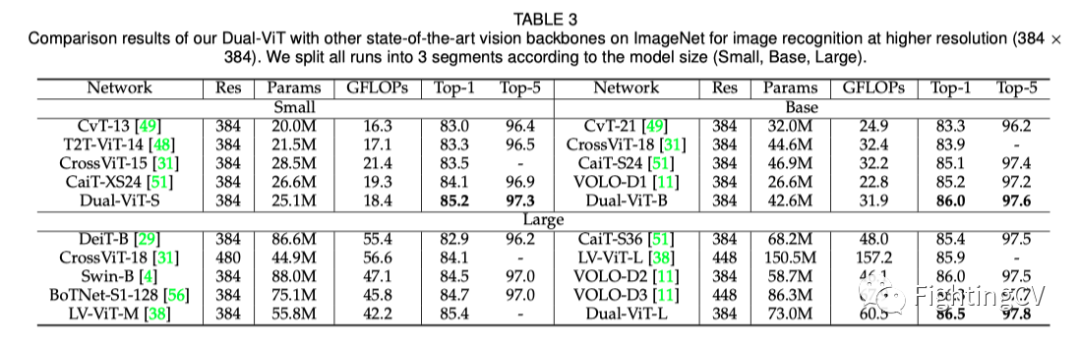
上表总结了本文的双ViT主干在更高分辨率(384×384)下在ImageNet上不同尺寸(双ViT-S、双ViT-B、双ViT-L)下的定量结果。

为了进一步验证双ViT作为通用视觉主干的有效性,作者将其与最先进的主干进行了比较,将其转移到目标检测和实例分割的密集预测下游任务中。COCO的性能如上表所示。
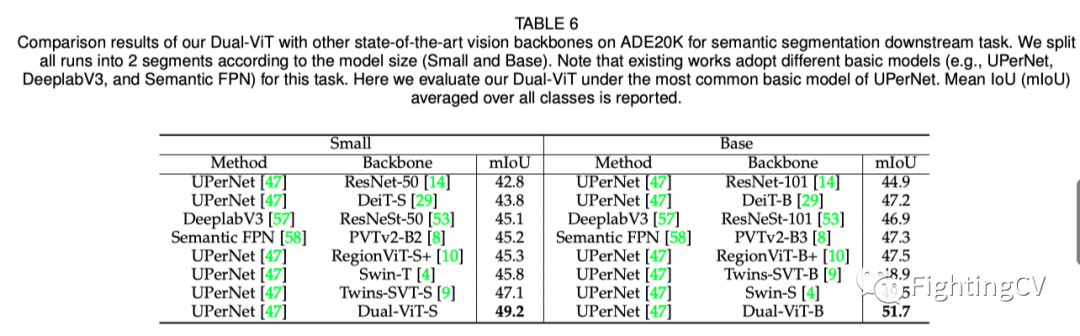
上表列出了语义分割下游任务在ADE20K上的性能比较。类似地,在相同的超级网基本架构下,双ViT-S/双ViT-B的性能分别比最佳竞争对手SVT/SWN-S高出2.1%/2.2%。
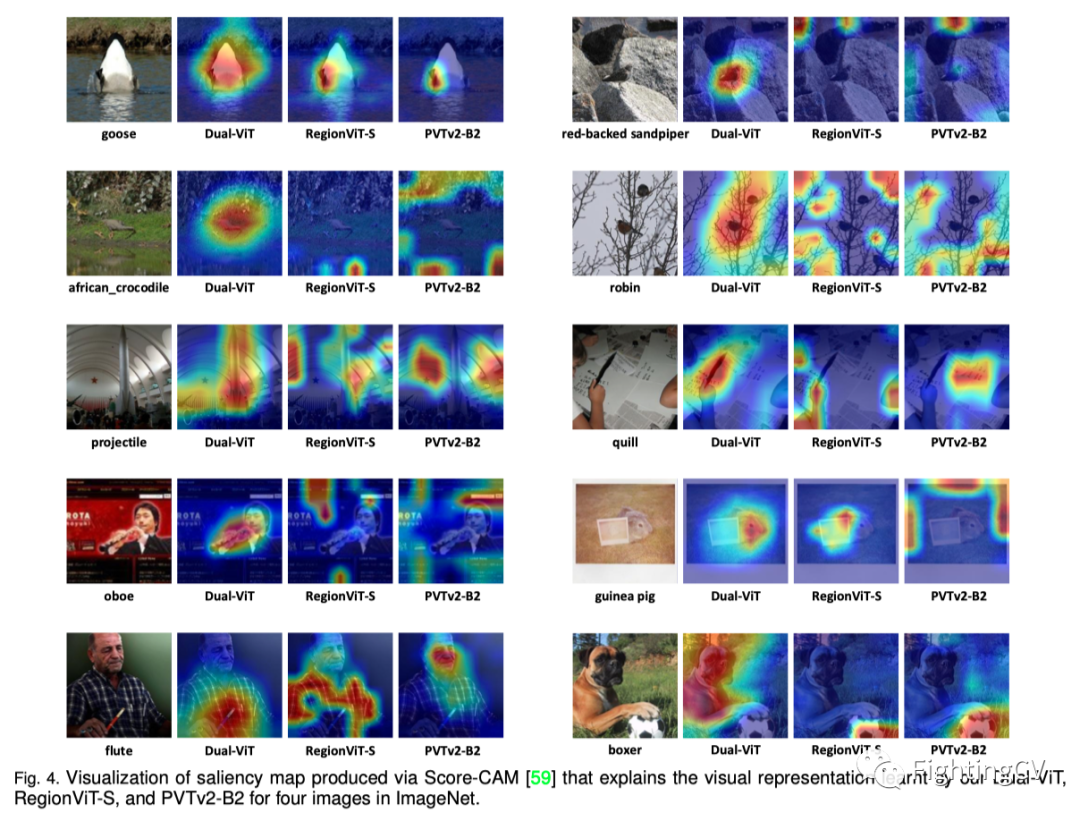
通过score-CAM生成的显著图可视化,解释了本文的双ViT学习的视觉表示。
在这项工作中,作者提出了双视觉Transformer(DualViT),这是一种新的多尺度ViT主干,它在两个交互路径中新颖地模拟了自注意力学习:用于学习内部像素级细节的像素路径和从输入中提取整体全局语义信息的语义路径。从语义路径中学习的语义标记进一步作为高级语义,以促进像素路径中的局部特征提取。通过这种方式,增强的自注意力信息沿着两条路径并行传播,以寻求更准确的延迟权衡。各种视觉任务的大量实证结果表明,DualViT相对于最先进的VIT具有优越性。







