绑定手机号
确认绑定










随着自动驾驶汽车和自动赛车越来越受欢迎,对更快、更准确的检测器的需求也越来越大。但对机器来说图像分辨率和计算资源的限制使得检测更小的物体成为一个真正具有挑战性的任务,也是一个开放的研究领域。
本研究探索了如何对YOLOv5进行修改,以提高其在检测较小目标时的性能,并在自动赛车中进行了特殊应用。为了实现这一点,作者研究了替换模型的某些结构会如何影响性能和推理时间。在这一过程中在不同的尺度上提出一系列的模型YOLO-Z,并得到高达6.9%的改善,相比原YOLOv5推理时间检测更小的目标时的成本就增加3ms。
YOLOv5提供了4种不同的尺度:S、M、L和X。每种比例都对模型的深度和宽度应用不同的乘数,这意味着模型的整体结构保持不变,但每个模型的大小和复杂性是按比例缩放的。在实验中,在所有的尺度上分别对模型的结构进行修改,并将每个模型作为不同的模型来评估其效果。
为了设定Baseline,对YOLOv5的4个量表的未修改版本进行了训练和测试。然后分别测试这些网络的变化,以便观察它们对Baseline结果的影响。在进入下一阶段时,似乎对提高准确性或推理时间没有贡献的技术和结构被过滤掉。然后,尝试将选定的技术组合起来。重复这个过程,观察某些技术是否相互补充或减少,并逐渐增加更复杂的组合。
YOLOv5的原始实现提供了与COCO兼容性API的度量,这对于本研究的目的证明是有用的。计算特定尺度值的方式可以很好地指示模型的性能,但在极端情况下可能会稍微不准确。
由于这些度量在默认情况下只与COCO数据集兼容,在测试代码中重新实现了这个方法,以便在使用任何数据集时获得更有价值的数据。度量模块将计算大、中、小目标的值,以及整体性能。将目标划分为这三种类别取决于以下阈值:小(如果对象的面积小于32平方像素),大(如果该区域大于96平方像素),中等(如果该区域大于两个阈值)。换句话说,small<32x32<medium<96x96<large。
为了训练模型并为实验提供信息,从自动驾驶赛车的角度采用了一个带注释的圆锥数据集。它最初的目的是根据圆锥体的颜色帮助自动赛车规划路径,因为知道总共有4类圆锥体(黄色、蓝色、橙色和大橙色),接近4000张图像(见图1,2)。
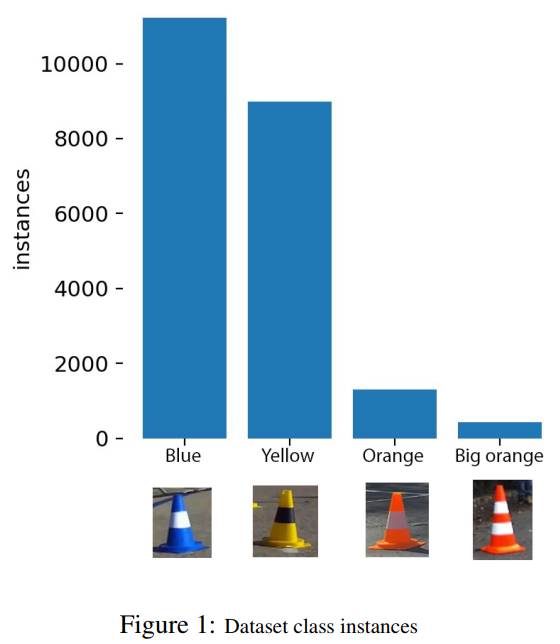

该数据集包括数字增强图像和具有挑战性天气条件的情况。像这样的数据集可以模拟自动驾驶汽车中更复杂的任务。锥体本身就是可以在路上找到的物体,在大小和位置上与其他物体有很多相似之处,比如交通标志。
尽管数据集将受益于更大的大小,但它的特点是目标密度非常高,有超过30000个标记目标。此外,在图1可以观察到蓝色和黄色类的很大偏差。这是有道理的,因为他们有助于双方的赛车,但它确实是一个不平衡影响整体结果。这些类上的性能将会考虑当评估模型,即通过平均分数显著的类别。
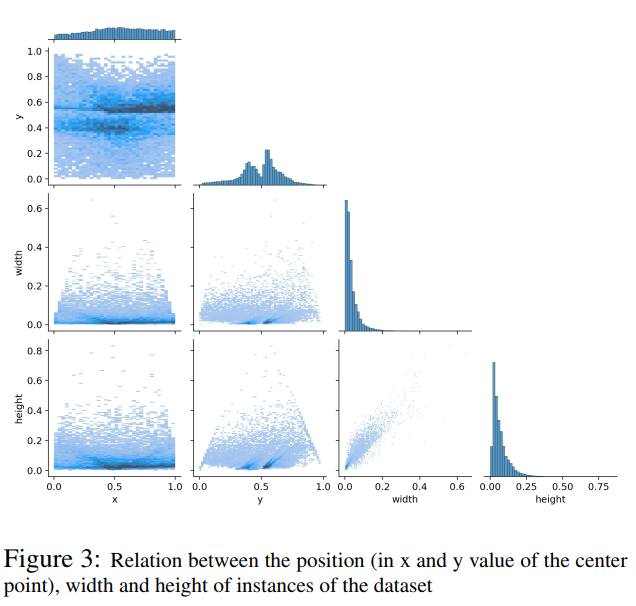
与自动驾驶场景中常见的其他物体(如其他车辆或行人)相比,圆锥体本来就很小。图3中的相关图(相关统计数据的图表)显示了数据集中目标(锥)的边界框的位置、宽度和高度。数据集具有高度集中的较小的目标框,由于透视投影而略微拉长。这种高比例的小目标使它有利于这类研究,因为它在很大程度上克服了在其他流行的数据集,包括MS COCO中缺乏这样的物体的问题。
该数据集以65:15:20的比例分为训练、验证和测试。
YOLOv5使用yaml文件来指导解析器如何构建模型。我们使用这种设置来编写我们自己的高级指令,说明如何构建模型的不同构建块以及使用哪些参数,从而修改其结构。为了实现新的结构,我们安排并为每个构建块或层提供参数,并在必要时指导解析器如何构建它。用我们的话说,我们利用YOLOv5提供的基础和实验网络块,同时在需要模拟所需结构的地方实现额外的块。
模型的Backbone是用于获取输入图像并从中提取特征映射的组件。这是任何目标检测器的关键步骤,因为它是负责从输入图像提取上下文信息以及将该信息提取为模式的主要结构。
作者尝试用2个Backbone替换YOLOv5中现有的Backbone。
ResNet是一种流行的结构,它引入残差连接来减少在深层神经网络中收益递减的影响。
DenseNet使用类似的连接,在网络中尽可能多地保存信息。实现这些结构需要将它们分解为基本块,并确保各层适通信。这包括确保正确的特征图尺寸,这有时需要为模型的宽度和深度略微修改缩放因子。
在这两种情况下,为了保持相当的复杂性,重要的是要避免大大偏离原始的层数。因此,使用了ResNet50,并按比例缩小了DenseNet,以保持其核心功能。此外,YOLOv5利用了Backbone和Neck之间的空间金字塔池化(SPP)层。然而,在本工作中,没有触及这一层。
将位于Head和Backbone之间的结构称为“Neck” (见图4),其目标是在将Backbone提取的信息反馈到Head之前尽可能多地聚合这些信息。该结构通过防止小目标信息丢失,在传递小目标信息方面发挥了重要作用。它通过再次提高特征图的分辨率来做到这一点,这样来自Backbone的不同层的特征就可以被聚合,以提升整体的检测性能。
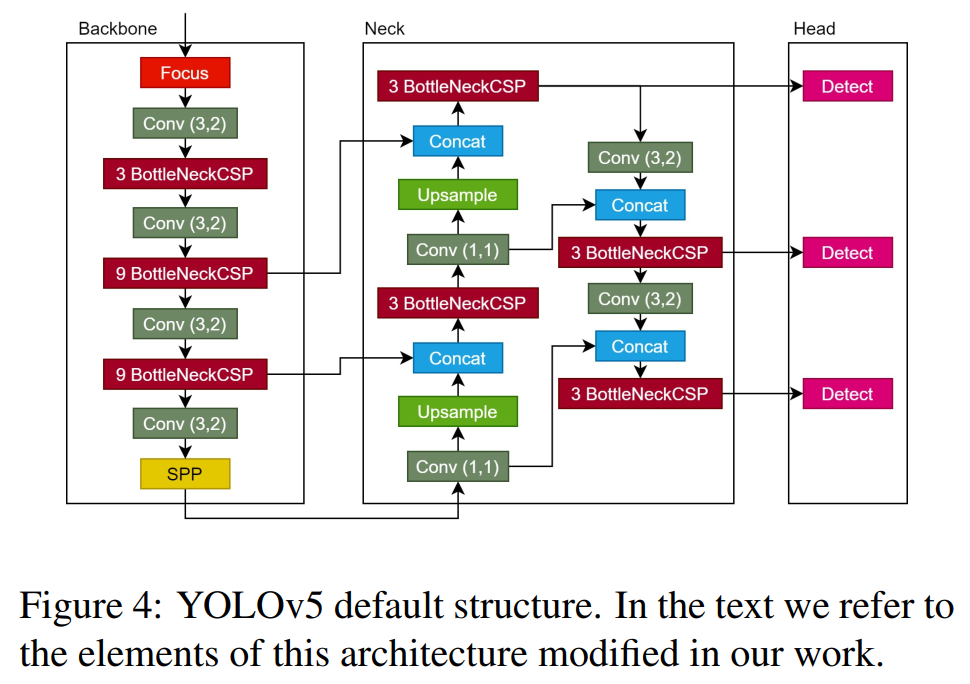
在本工作中,将当前的PAN-Net替换为bi-FPN。虽然都保留了类似的特征,但复杂性不同,因此实现所需的层数和连接数也不同。
模型的Head负责获取特征映射,并通过从Neck获取几个聚合的特征映射来预测边界框和类。除了接收到的参数之外,这个结构可以保持原样,因为它是模型的一个基本部分,在小目标检测中没有前面提到的元素那么大的影响。
然而,还有其他一些元素会对小目标检测性能产生影响。除了输入图像的大小之外,还可以修改模型的深度和宽度,以改变处理的主要方向。Neck和Head的层连接方式也可以手动改变,以便专注于检测特定的特征图。
在这项研究中,作者探索了涉及高分辨率特征映射的重定向连接的效果,以便将它们直接反馈到Neck和Head。这可以通过扩大Neck以适应额外的特征图来实现,也可以通过替换最低分辨率的特征图以适应新的特征图来实现,图5显示了这两个选项以及默认(原始)布局。
使用更高分辨率的特征图通常可以提高对较小目标的性能,但需要耗费推理时间和潜在的对较大目标的检测,这与增加输入图像大小的效果类似。用这两种方式在Neck整合这种行为,以最大限度地减少其缺点,同时最大限度地利用其优点。
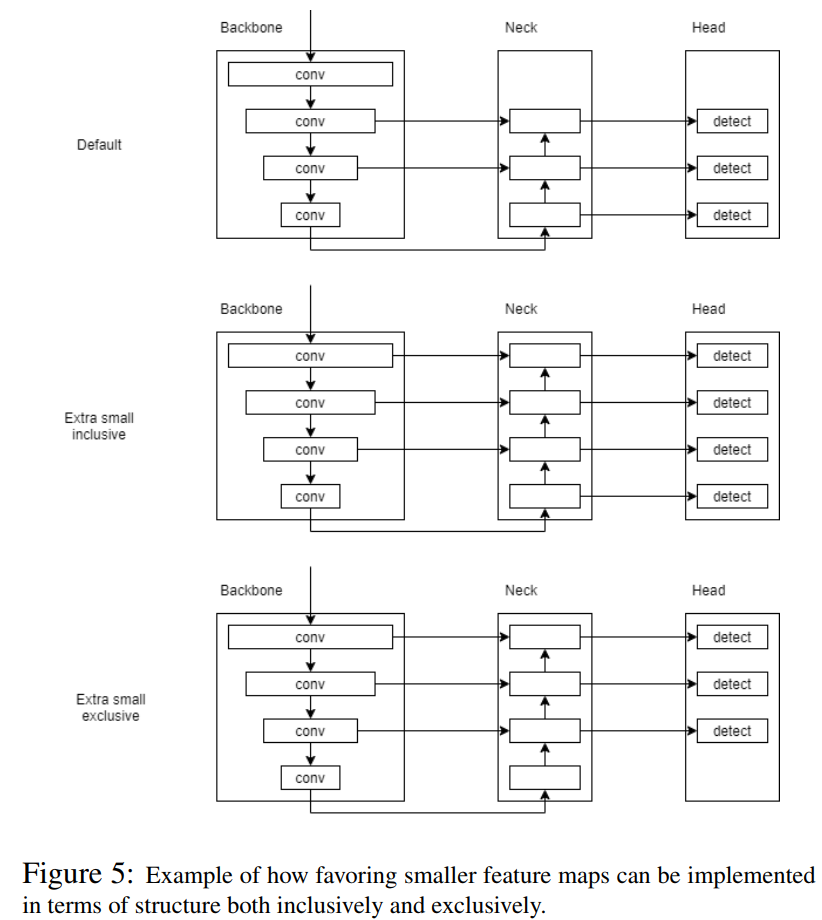
注意,一些参数将不得不调整到新的结构,因为网络的学习能力可能会受到影响。主要是在Head应用Anchor的大小,需要根据所使用的特征图的分辨率进行调整。

在对YOLOv5进行调整以更好地检测更小的目标的方法的实验中,本文能够识别体系结构修改,这种修改在性能上比原始的检测器有明显改善,而且成本相对较低,因为新的模型保持了实时推理速度。
所应用的技术,即自动赛车技术,可以从这样的改进中获益良多。正如在图8中看到的,这样的变化确实对检测有可量化的影响。在这项工作中,不仅显著提高了Baseline模型的性能,而且还确定了一些特定的技术,这些技术可以应用于任何其他应用程序,包括检测小或远的物体。
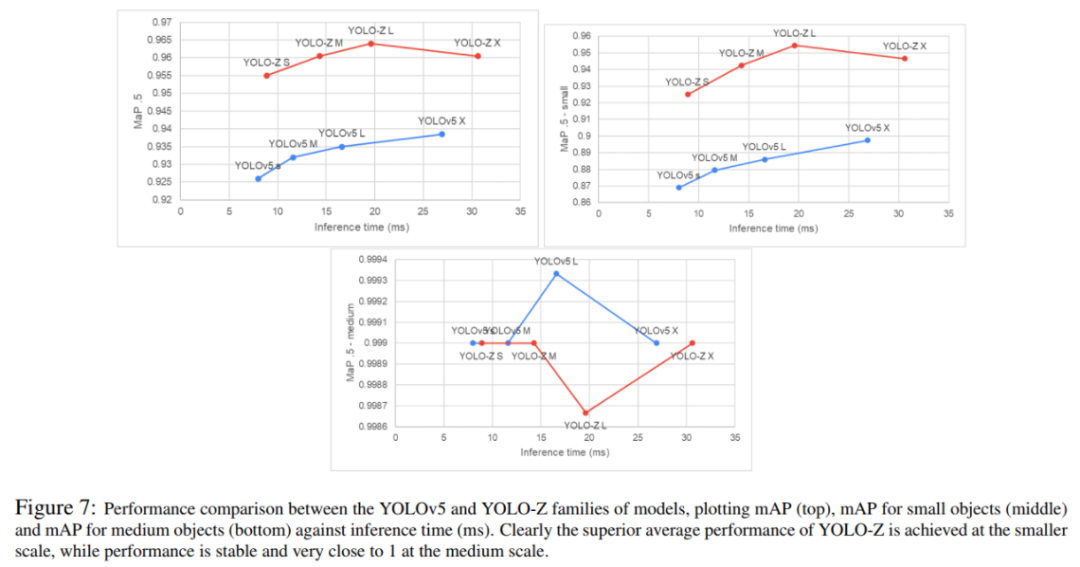
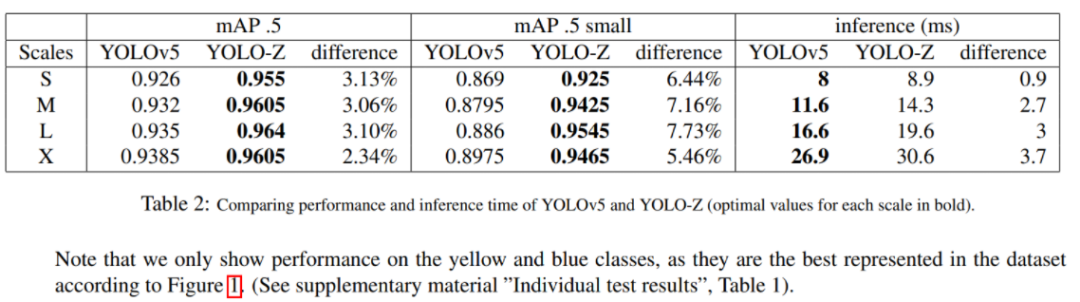
YOLO-Z家族的最终结果是,模型表现的YOLOv5类,同时保留一个推理时间等实时应用程序兼容的自动化赛车(见表2和图7)。特别是较小的目标是本研究的重点(图7中,中间),而对于中等大小的目标(下图),性能是稳定的。
[1].YOLO-Z: Improving small object detection in YOLOv5 for autonomous vehicles









