绑定手机号
确认绑定









大家好,又见面了。
最近有一位,背景太假的 up 主火了。
不知道是天生体质,还是他得罪了团队里的哪位大哥,导致他无论是直播,还是拍视频,总和身后的背景格格不入,被网友质疑使用了假背景。
于是放了大招,发澄清视频回应,结果惨遭全网鬼畜。

视频被剪辑换了各种背景,什么熔岩、飞机、鳄鱼池,都来了。
也算是另类出圈,又是一位被鬼畜玩火的 up。
说到背景太假,让我想到一个新出的算法,不仅背景假,人也是假的!

一个 10s 的视频,算法进行 3D 建模,生成一个场景模型、人物模型。
这样,这个人物模型,就可以在这个场景里,做任意的动作,给他来个后空翻,再跳一段舞,都可以。

3D 模型都有了,假人+假背景的视频,也是轻松搞定。
这个算法有个很形象的名字 NeuMan,论文已被 ECCV 22 收录,并且已开源。
我们再看看 NeuMan 几组酷炫的效果。
左上角是输入的训练视频,左下角是生成的背景模型,右侧则是合成后的小哥在建模的场景下,跳跃的效果,背景的人物,都是建模出来的。

不仅是跳跃这种常规操作,广播体操也完全没问题。

甚至是,NeuMan还可以将上面例子中的两个人合成到一起,放到一个场景中。

再加上一个人,立马变成魔性的广场舞视频。

自从伯克利和谷歌联合打造的 NeRF(Neural Radiance Fields神经辐射场)横空出世,各种重建三维场景的研究层出不穷。
NeuMan 原理就是基于 NeRF 实现的,训练了一个人物 NeRF 模型和一个场景 NeRF 模型。
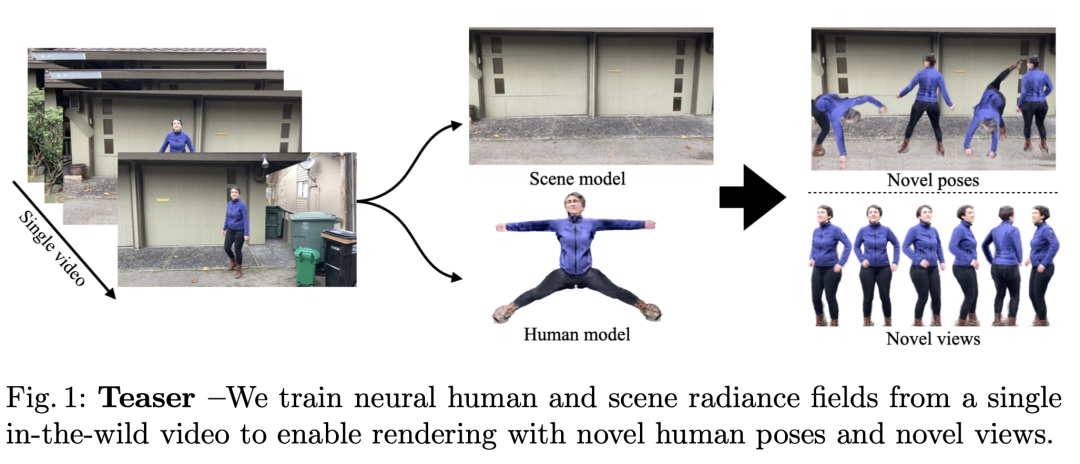
然后使用人物+场景,就能合成新视频。
因为已经建模,所以加几个人,换什么场景,也就随心所欲了。
训练思路是,对于一段视频,使用 Mask RCNN 进行分割,分割前景人物和背景。
然后分别对前景人物和背景进行 3D 重建。因为输入是视频,被前景遮挡的部分,在下一帧也会漏出来,所以前景和背景都是完整的。
对于人体的 NeRF 模型训练,引入了一种端到端的 SMPL 优化和纠错神经网络。
使用端到端的 SMPL 优化的人体模型,能够更好地表现人体的典型体积。
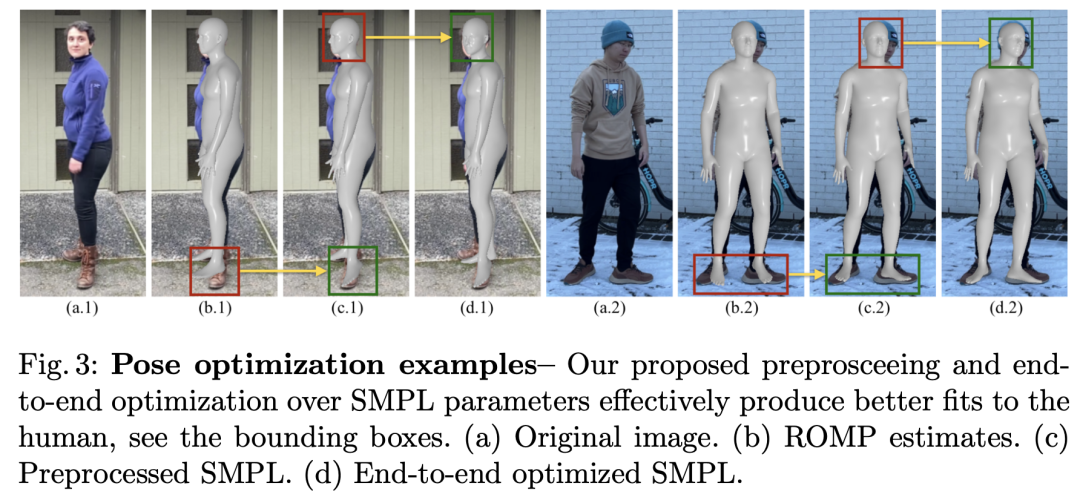
而纠错神经网络,顾名思义,补充细节,纠正一些 SMPL 阶段留下的问题。
人体模型和场景模型都搞定了,再使用 colmap 进行点云对齐,将人物模型按照一定比例,放到场景模型中。

可以操纵人体 3D 模型做一些动作,很多动作都是有现成模版。
甚至可以像玩游戏一样,通过按键操控。
至此,叠加的点云,就形成了新的渲染效果。
最后再说下这个项目地址:
https://github.com/apple/ml-neuman
环境搭建都是类似,安装依赖,看了下使用 conda 就行,可以参考我之前发过的基础环境搭建教程:
https://www.bilibili.com/video/BV14R4y1g7qs
好了,今天就聊这么多。
我们下期见!








