绑定手机号
确认绑定









在使用虚拟机部署的私有云、公有云场景中,虚拟机热迁移有着广泛的应用。虚拟机热迁移指的是将虚拟机的整个运行时状态保存下来,然后快速地恢复到另一个硬件平台上,恢复以后,虚拟机仍旧平滑运行,用户几乎不会察觉到任何差异。
为什么要进行热迁移
利用热迁移,管理员可以在对用户透明的前提下,灵活地配置数据中心的资源,例如:
· 简化系统运维管理:系统运维操作如停机维护、系统重启、软硬件升级等操作,可通过将其上运行的虚拟机迁移至别处、执行运维操作、将虚拟机迁移回来的三个步骤来实现。
· 实现系统的负载均衡:随着系统资源的不断分配和用户使用情况的变化,难免造成集群内主机资源(如CPU、内存、存储等)不均衡,通过热迁移可以灵活地调配资源,达到负载均衡的效果。
· 增强系统的主动容错能力:对即将发生物理故障的主机,可使用热迁移技术将运行的业务迁移走,避免故障造成业务中断,大幅提高了可靠性。
· 优化系统的电源管理:通过热迁移来集中资源使用,并将空闲主机下电来优化系统的能耗。
GPU服务器的热迁移
热迁移本质是对业务运行所需资源的替换,要在不停止业务的情况下更换资源,必然涉及到任务状态的保存和恢复。当前主流的虚拟化平台如KVM、Xen、HyperV、Vsphere等都对CPU、内存、磁盘的状态保存和资源替换有较好的支持,因为无论是CPU寄存器、虚拟内存数据、虚拟磁盘状态等都有着丰富的保存、恢复接口。
但对异构算力资源而言,其内部硬件资源的管理与厂商强相关。如Nvidia GPU在运行CUDA程序时,其寄存器状态、显存内容等对用户并不可见,也没有对外提供状态打包保存、状态恢复等接口,目前GPU直通、VF直通等虚拟化方案也还无法支持热迁移。具体到AI应用的场景,例如运行长时间的AI训练任务,如果中途需要进行负载均衡或停机维护的热迁移操作,会造成训练中断。
GPU池化对虚拟机热迁移场景的价值
在不支持硬件设备暂停、恢复的情况下,热迁移的一种方案是不替换算力资源,即程序在迁移前后仍然使用原有的GPU卡。此时,实现GPU池化是关键。为了方便理解这一点,我们以KVM热迁移针对虚拟磁盘的处理作为类比:
为了保证迁移前后存储的状态与迁移前一致,必须要保证从虚拟机的视角来看,虚拟磁盘的数据是一致的,且已下发或完成的I/O状态一致。要实现这点,通常有两种方式:
1、 使用共享存储,使得两台主机均能看到同一个虚拟磁盘后端,如共享卷或共享文件系统里的文件。通常我们称之为镜像存储池。
2、 直接拷贝所有磁盘数据。
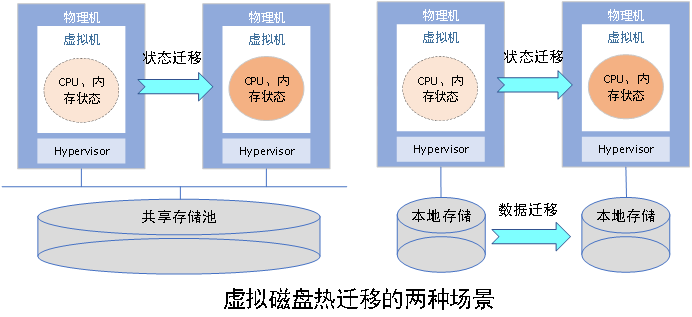
显然,第一种方式仍然使用原有的磁盘或文件,不需要任何的数据搬移,因此迁移速度显著加快,且不占用额外空间,这是因为池化存储给了集群内所有主机相同的访问方式,这也是各大云厂商普遍使用的方式。而第二种方式由于切换了使用的磁盘,因此涉及所有磁盘的大量数据的拷贝,被称为整机迁移。
相较于传统的GPU虚拟化技术,池化GPU资源,可以帮助我们更快、更高效地使虚拟机在算力池中迁移,而且对用户无感。这类迁移的显著特征是,虚拟机迁移到目的主机后,仍然使用原有的GPU资源池,并不涉及GPU状态保存和恢复。而相较于存储资源池技术的成熟,GPU作为绑定于一台主机上的硬件资源,要被不同的主机所共享需要的技术挑战更大,而OrionX对GPU资源的隔空取物和资源池化管理能力,为Client热迁移提供了完美的支持:
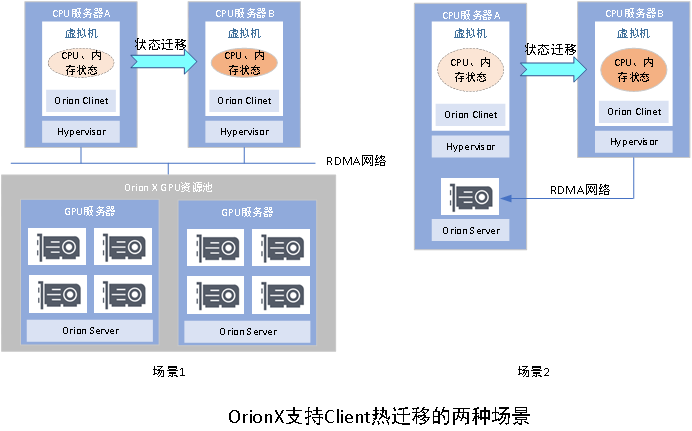
· 场景1(CPU、GPU分离部署):OrionX的GPU资源池化能力使CPU集群和GPU集群解耦。CPU集群里的任何虚拟机在使用GPU集群的远程池化资源来执行AI任务时,均可以在集群内任意迁移,以完成运维、资源调配、节电等工作。
· 场景2(CPU、GPU融合部署):虚拟机A使用本机的GPU卡X进行训练任务,此时可动态地迁移至主机Y,迁移恢复后,A可通过RDMA远程继续使用X进行训练,保证业务不中断。由于OrionX的RDMA远程性能相较于本地性能损耗较低,因此对用户几乎无感。
Server热迁移
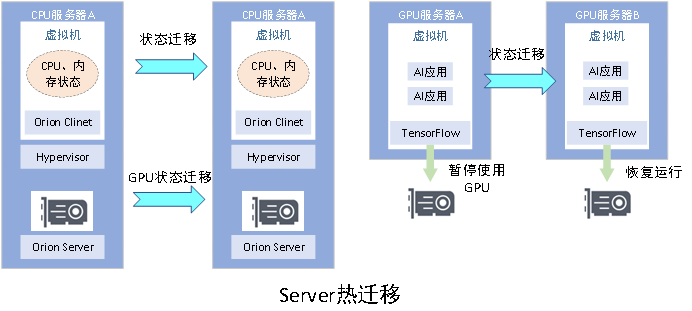
与上文讲的整机迁移类似,当迁移前后,AI任务所使用的GPU卡发生变化,则被称为Server热迁移。Server热迁移涉及动态换卡操作,就依赖GPU状态的保存和恢复。如下图的场景1所示。
当前,根据Nvidia GPU的公开资料,无法确保在发生迁移时GPU处于一种确定性的状态或是进行状态打包封装和恢复的操作,因此不支持该类型的GPU状态迁移。
在缺少相应接口的情况下,OrionX尝试从框架层来操作。当确保虚拟机内运行的是固定的AI框架(如TensorFlow、Pytorch等)时,可以让框架下发终止使用GPU的命令,并在迁移后重新恢复执行。具体流程如下:
1. 接收迁移信号,暂停应用;
2. 做checkpoint, 把GPU上的数据搬运到CPU端,如果数据量过大则需要落盘。
3. 框架内部需要做一些状态重置,让runtime context变CPU only,清空所有不必要的GPU信息包括handle、mem_ptr等;
4. 等待迁移信号结束;
5. 将checkpoint的数据恢复到GPU端,恢复全部GPU状态(包括一些handle的重新初始化, gmem分配;
6. 完成后可以再次触发框架状态恢复完成信号。
总结
虚拟机热迁移在云场景的运维中扮演着重要的作用,而对GPU资源的热迁移也一直是难点。
OrionX通过GPU隔空取物和资源池化,实现了Client热迁移,使GPU虚拟机可以在集群内任意迁移,同时保持任务不被中断。同时,通过在框架层的深入,OrionX实现了Server的热迁移,使用户对池化GPU资源的使用更加灵活。
后续,趋动科技还将与OrionX所支持的其他国产芯片厂商合作,联合推出硬件辅助的应用透明热迁移方案,使AI应用集群的资源配置更加灵活、从而给予业务更高效的支持。
关于趋动科技
趋动科技于2019年成立于北京中关村高新技术园区,拥有专业的研发、运营和服务团队,被评为 WISE2020「新基建创业榜」最具成长性创业公司TOP20、「REAL 100创新家」、「2021创业邦100未来独角兽」等。趋动科技专注于为企业用户构建数据中心级 AI 算力资源池和AI开发平台,趋动科技的 OrionX 猎户座 AI 算力资源池化软件能够帮助用户提高资源利用率和降低TCO,提高算法工程师的工作效率。趋动科技的双子座 GEMINI AI 训练平台,为客户提供强大的AI算力管理服务以及高效的算法开发和训练支持,能够化繁为简,帮助企业建好AI平台、管好 GPU、用好 AI 服务。
趋动科技创始人兼CEO王鲲博士表示,凭借标准化、可复制的产品架构,趋动科技得到了包括互联网、金融、电信运营商、科研机构和高校等大量行业头部客户的认可。资本市场对于趋动科技的发展充满信心——趋动科技成立两年多已经完成近亿美元的融资,顶级的投资机构持续支持趋动科技的发展,包括国开装备基金、沙特阿美旗下多元化风投基金Prosperity7 Ventures、元禾重元、招银国际、顺为、高瓴、嘉御、戈壁、讯飞和涌铧在内的国内外顶级VC正在见证趋动科技锐意进取的脚步。








