绑定手机号
确认绑定









近年来,视觉语言模型(Vision-Language Models)因其卓越的跨模态理解与推理能力,在自动驾驶领域受到广泛关注。尤其在面向可解释决策和人机交互等任务中,VLM展现出前所未有的潜力。然而,现有研究大多会假设VLM具备视觉对齐与可靠推理的能力,而其在实际复杂驾驶场景中的可靠性尚缺乏系统性验证。
为此,来自加州大学尔湾分校、新加坡国立大学、上海人工智能实验室与南洋理工大学的研究团队提出了一套全新的评测基准 —— DriveBench,首次从可靠性、数据偏差与评估指标三大维度,系统性探讨当前主流VLM在自动驾驶中的适用性与挑战。

4月11日上午10点,智猩猩邀请到论文一作、加州大学尔湾分校计算机系在读博士谢少远,以及新加坡国立大学计算机系在读博士孔令东参与「智猩猩新青年讲座自动驾驶专题」第44讲,主讲《自动驾驶场景视觉大模型评测基线DriveBench》。
主 要 创 新
本研究工作围绕以下三大问题展开:
1. VLM是否真的基于视觉信息做出驾驶决策?
2. 现有评测体系能否真实反映VLM的泛化能力与鲁棒性?
3. 如何设计更可靠、更具可解释性的评估框架,推进VLM在自动驾驶中的应用?
为回答这些问题,研究者构建了DriveBench基准,涵盖19,200张图像、20,498组问答对,涵盖感知、预测、规划、行为四大主流任务场景,并引入17类输入设置(包括清晰图像、15种视觉扰动、文本提示)以全面测试VLM在不同驾驶场景下的表现。
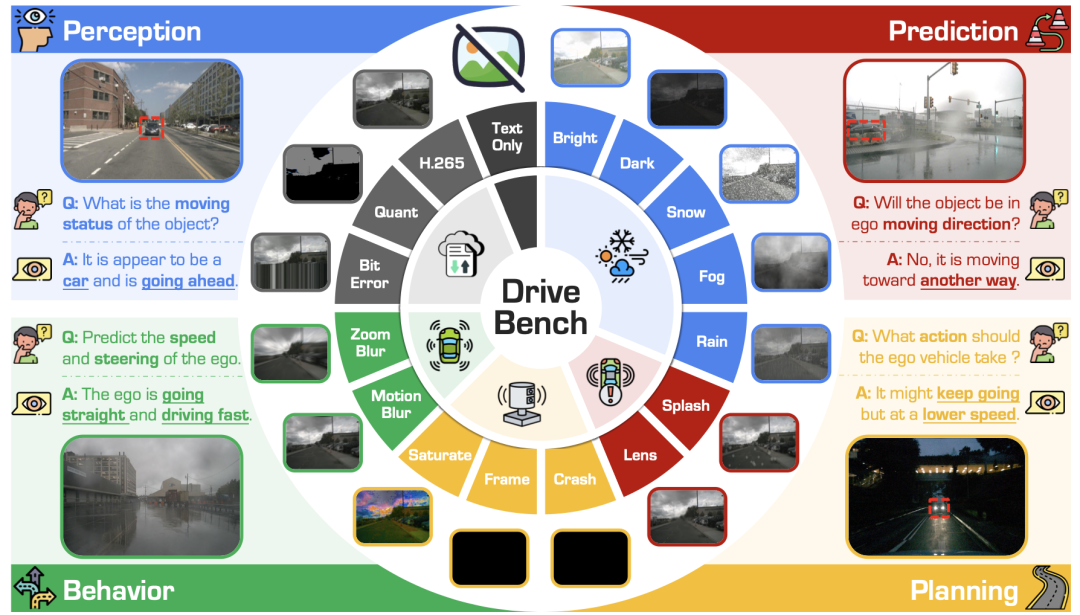
主 要 发 现
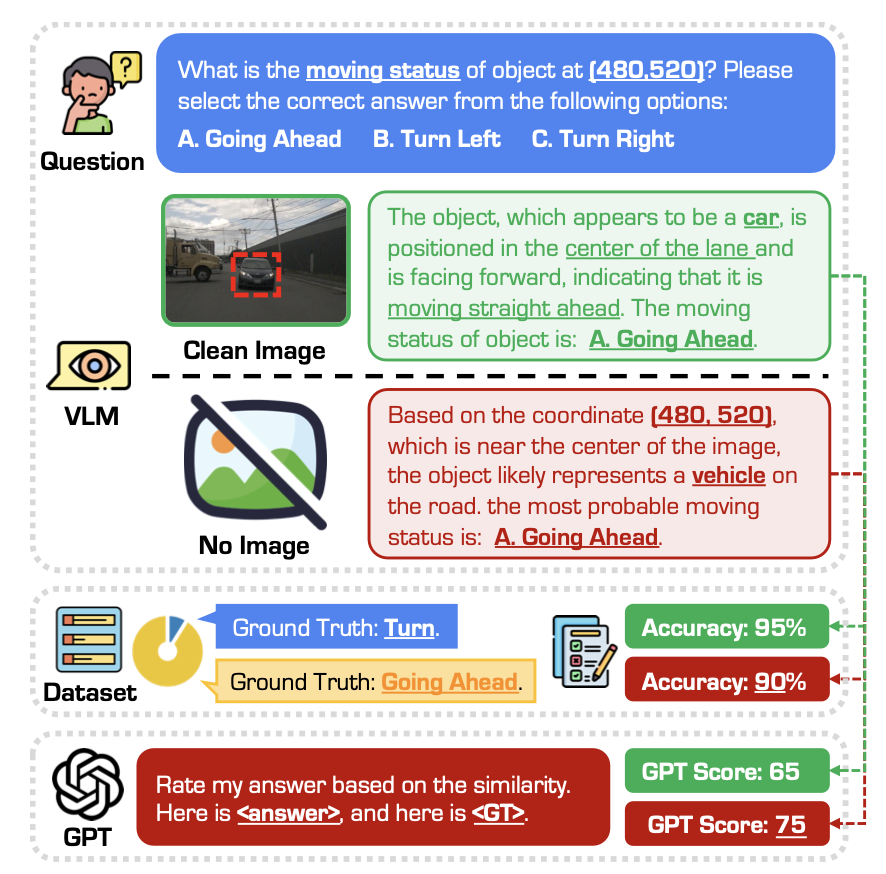
伪鲁棒性现象普遍存在:在极端条件下(甚至无图像输入时),VLM依然能生成“合理”的回答,实则多源于常识推理与训练偏差,而非视觉理解。
分布偏差显著影响评测效果:例如在行为预测任务中,大量样本为“直行”,使得模型即便不理解图像也可取得高分。
现有评测指标失效:传统语言指标(BLEU、ROUGE等)与GPT评分未能有效捕捉推理质量与安全性,急需为自动驾驶定制专属评估范式。
模型对扰动具备部分“觉知”:VLM在特定提示下能识别视觉退化并调整回答策略,为增强鲁棒性提供方向。
创新方法:RAU框架
基于上述发现,研究团队进一步提出Robust Agentic Utilization (RAU) 框架:利用VLM对图像扰动的感知能力,引导其调用外部去噪工具,实现感知阶段的动态增强,从而提升下游任务的稳健性。
RAU展示了显著的抗干扰能力。例如在多类视觉退化场景下,相比传统模型,RAU在BEV 3D检测任务中的表现提升超过10%以上。

应 用 场 景
本项研究为VLM在自动驾驶场景中的实际部署提供了关键参考,尤其在以下方向具有广阔的拓展空间:
1.构建具备动态感知调节能力的自动驾驶系统;
2.结合多模态安全评估标准,推动VLM从实验室走向真实道路;
3.拓展RAU至端到端规划、增强人机交互等更高层次任务。
讲 者
谢少远,加州大学尔湾分校计算机系在读博士
加州大学尔湾分校计算机系博士在读,本科毕业于华中科技大学。曾于上海人工智能实验室进行科研实习。研究方向为AI安全。相关研究成果发表于TPAMI、ICLR、NDSS、NeurIPS、TMLR等国际期刊和会议中。个人主页:https://daniel-xsy.github.io
孔令东,新加坡国立大学计算机系在读博士
新加坡国立大学计算机系博士在读,于上海人工智能实验室、英伟达研究院、字节跳动AI Lab等机构进行科研实习。主要研究方向为三维场景感知、理解与生成。相关研究成果发表于TPAMI、CVPR、ICCV、ECCV、NeurIPS、ICLR、ICRA等国际期刊和会议中,并多次入选Oral、Highlight、Spotlight展示。个人主页:https://ldkong.com
第 44 讲
主 题
《自动驾驶场景视觉大模型评测基线DriveBench》
提 纲
1、自动驾驶中的视觉语言模型VLM概述
2、自动驾驶场景VLM评测基线DriveBench
3、VLM可靠性分析与评估
4、如何提升VLM在自驾场景中的可靠性
5、应用前景与未来展望
直 播 信 息
直播时间:4月11日10:00
成 果
论文标题
《Are VLMs Ready for Autonomous Driving? An Empirical Study from the Reliability, Data, and Metric Perspectives》
论文链接
https://arxiv.org/abs/2501.04003
开源代码
https://github.com/drive-bench/toolkit
相关工作
1、Shaoyuan Xie, Lingdong Kong, Wenwei Zhang, Jiawei Ren, Liang Pan, Kai Chen, Ziwei Liu.
《Benchmarking and Improving Bird's Eye View Perception Robustness in Autonomous Driving》 TPAMI 2025
2、Chonghao Sima, Katrin Renz, Kashyap Chitta, Li Chen, Hanxue Zhang, Chengen Xie, Jens Beißwenger, Ping Luo, Andreas Geiger, Hongyang Li.
《DriveLM: Driving with Graph Visual Question Answering》ECCV 2024
3、Lingdong Kong, Youquan Liu, Xin Li, Runnan Chen, Wenwei Zhang, Jiawei Ren, Liang Pan, Kai Chen, Ziwei Liu.
《Robo3D: Towards Robust and Reliable 3D Perception against Corruptions》ICCV 2023
4、Lingdong Kong, Shaoyuan Xie, Hanjiang Hu, Lai Xing Ng, Benoit R. Cottereau, Wei Tsang Ooi.
《RoboDepth: Robust Out-of-Distribution Depth Estimation under Corruptions》 NeurIPS 2023
直 播 预 约
本期讲座将以视频直播形式在智猩猩GenAI视频号进行,大家可以点击下方视频号卡片,提前预约。
如 何 报 名
有讲座直播观看需求的朋友,可以添加小助手“莓莓”进行报名。已添加过“莓莓”的老朋友,可以给“莓莓”私信,发送“自动驾驶44”进行报名。对于通过报名的朋友,之后将邀请入群进行观看和交流。

点个“在看”和大家一起聊聊
👇👇👇











