绑定手机号
确认绑定









大家好,又见面了。
好久没写趣味项目的文章了,今天推荐几个比较不错的开源项目。
基于 Nerf 的人脸建模算法。
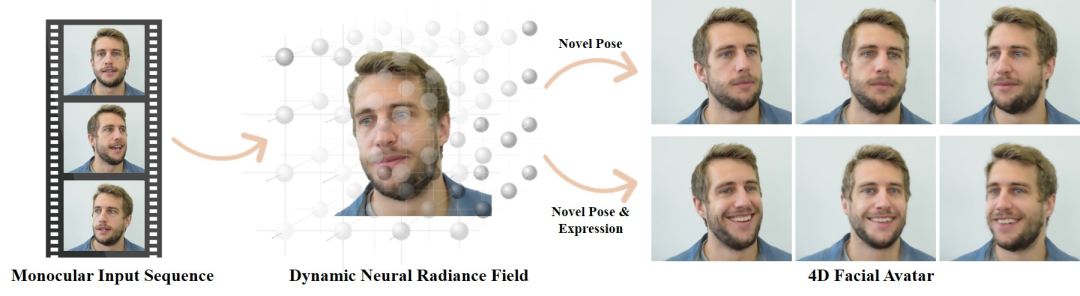
输入一个单目图片序列,算法建模生成人脸模型。
直接看下生成效果吧:

不用专业的拍摄设备,也不需要带深度信息的摄像头,普通的手机拍一小段视频,就能生成 4D Face Avatar。
这比之前介绍过得一阶运动模型的效果要逼真很多,毕竟这个是对人脸进行了建模,细节更好。
有了人脸模型,就可以通过其他视频,驱动这个人脸模型,做表情,做动作。

总结一下优点:只需要 monocular input,不需要 multi-view, 数据较好获取,且可⽣成新的pose 和表情。
当然缺点也有:⼀个 subject 对应⼀个模型,⽆法泛化。
训练一个 Nerf 模型,需要不少的时间。
项目地址:
https://github.com/gafniguy/4D-Facial-Avatars
这段时间,最火的方向,莫过于基于文本用AI生成图像。
这类算法我也推荐过很多,像 DALL·E 2 和 Imagen,在之前的文章里,我都有介绍过。
功能都是类似的,根据一段文字描述,生成对应的图片,比如:

其实除了用文本生成 AI 图像,还可以驱动 3D 模型。


根据一段文字描述,控制 3D 人体模型做动作。
别看这些 3D 模型其貌不扬,但结合现在火热的一些 3D 人体建模算法,有趣的玩法很多。
想象一下:
你有个手机,拍摄了某个人的一段视频,然后就可以对这个人体进行 3D 建模,进而通过语音控制,可以让他/她做出各种动作。
当然,现在受限于建模资源、速度等问题,想要实现这些,还需要一些时间。
项目地址:
https://github.com/athn-nik/teach
最后,再推荐一个非常实用的大合集。
我们知道,继 OpenAI 在 2021 提出的文本转图像模型 DALLE 之后,越来越多的大公司卷入这个方向,比如谷歌在今年相继推出了 Imagen 和 Parti,以及 DALL·E 2 和 stable-diffusion 等。
这些算法,有的是基于 GAN 的,有的是基于扩散模型(Diffusion Model)的。
OpenAI 的论文 Diffusion Models Beat GANs on Image Synthesis 也证明了扩散模型能够超越 GAN。
所以,关于扩散模型的研究,今年涌现了很多算法。
然后,便有了这个汇总项目,将各种扩散模型算法分门别类进行了总结:

想学习看论文的小伙伴,可以从这里下手:
https://github.com/YangLing0818/Diffusion-Models-Papers-Survey-Taxonomy
三个实用项目分享给大家,祝各位玩得愉快~










