绑定手机号
确认绑定










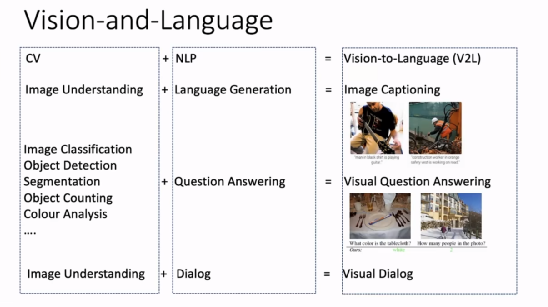
计算机视觉(CV)和自然语言处理(NLP)早先是比较独立的研究领域。CV重点关注如何用计算机代替人眼对目标完成识别、跟踪、测量等任务,对图像进行处理;NLP则研究计算机如何表现出语言生成、问答、神经等任务。计算机自然运行时,以网络为效果,被广泛用于处理学习和 NLP 的最新学习和 NLP 领域。 。
人类可以同时使用和语言方面的能力来完成任务,CV 与 NLP 的结合(V2L)也成为人工智能研究领域的两个重要课题,可以拓展这个方向的重要应用。图像理解和语言任务结合起来组成了图像描述(图像字幕)任务;将图像分类、目标检测、生成图像分割、目标技术、颜色分析等 CV 任务与问答任务结合起来就组成了视觉问答任务;将理解和任务结合起来就构成了视觉任务。
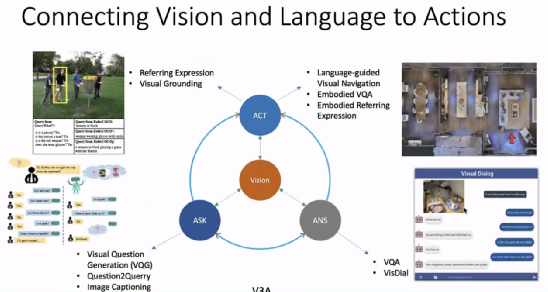
歌词,也为我们的使命,将在给我们的演说中“赋予我们的演技” 。希望机器能够提出问题、回答问题,并通过和人以及机器之间的语言交流执行一些动作。
例如,「Vision+Ask」的任务包含问题生成、根据问题生成查询、图像描述等;「Vision+Answer」的任务包含视觉问答、视觉等;「Vision+Act」的任务指包含称表达、视觉视觉引导(视觉基础)、语言引导的视觉导航、具身问答、具身指称表达等。

身人工智能是看当前的一个热点研究领域,它要求体能够感受周围的环境,并制定、相应的决策,智能完成说、听行动、推理等任务。

如上,在基于视觉与语言的虚拟导航图(VLN)任务中希望自然语言导航图(显示房间)。中理解语言指令,并按照指令,按照给定的路线完成导航,达到规定的目的地。
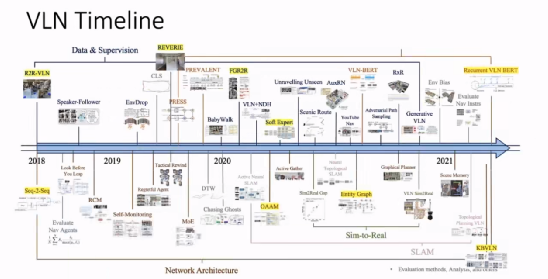
第一篇 VLN 的工作发表于 20 年 18 月,当时我们考虑如何确定我们的 CVPR,用于机器人技术用于视觉。试用的任务。
反过来说,任务一个5岁左右的孩子为我们拿来指挥的任务。但是让机器人根据人类简单的指令完成任务还是该该的。我是勺子”。
自 2018 年起,「视觉-语言导航」就成为继到视觉问答、视觉译文的重要任务,「视觉-语言多个任务,机器人学的研究人员也加入了这一研究的行列。从那时起,已经出现了很多的数据集(例如,REVERIE、RxR,以及一些外来的数据)和新的网络架构。
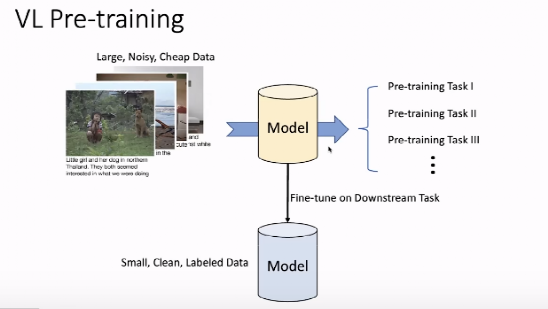
预训练技术在和 NLP 领域的图像都描述了重要的角色(例如,CV 领域的 Vi,NLP 领域的 Bert)。在视觉问答等「视觉-语言」任务中,预训练技术也都在大排行榜中占地榜首位置。
如上语言图,对预期的初步设计和测试显示--语言预测试是在预想上,获得的,是人为人提供的数据显示任务,确实在进行视觉显示的模拟过程。中,我们需要将视觉-语言的概念匹配起来。
在获得挖掘结果的结果后,我们可以为它的后续任务,在小规模、大众发布的数据集上准确地执行后续任务。

然而,直接将 VLBert 等预训练的视觉-模型的视觉-导航任务的特殊效果并不理想。这是用于 VLN 是更接近的视觉-语言任务。最初,它是一个部分的视觉语言任务。夫决策过程(POMD,其决策非常依赖于过去空顺序)到N的经验。同时,是一个时间任务,对于执行的顺序十分敏感。
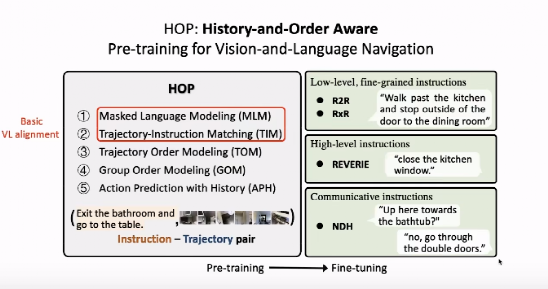
我们考虑针对 VLN 任务设计训练新的预任务,使视觉语言预测试模型被用于 VLN 任务。1)智能指令集:R2R、RxR集。给出详细的指令等数据:厨房,在餐厅的门外停(2)指令指令集:详细的指令数据集:R2R、 RxR集。比如说通过帮助定位和最终目标,大约厨房上窗口(3)式指令:NDH 等数据集。和机器、和仅翻译机器之间存在的数据,,机器完成导航。在本集节目上,我们用各种语言分别进行模型训练。
如上图所示,我们设计了类预演任务。其中5,掩蔽语言模型(ML、模拟概念指令(TIM)等常见的VL任务任务,将视觉-M)的模拟任务。传销任务中,我们将宣传中的某个词在“遮盖”,希望通过时间中的信息预测出被“遮盖”的词。
在针对 VLN 中的顺序、顺序我们设计的模型(TOM)中,给定中的模式以及类似模式的描述,模型需要确定环境中的任务是否正确。GOM)任务。为了利用部分明显的马尔科夫决策过程中的历史信息,我们设计了考虑历史信息的活动预测任务(APH)。
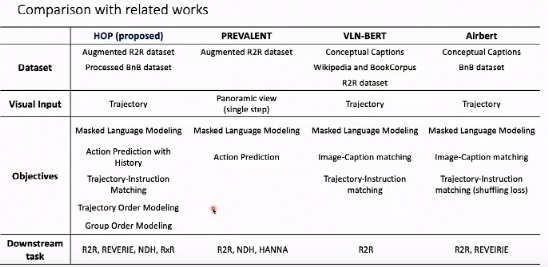
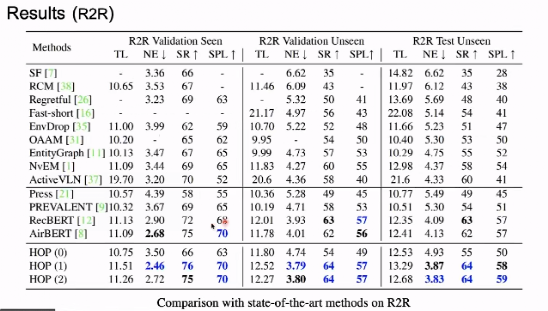
在上图中,我们从目标、数据传输、四个方面与当前最先进的(PREVALENT、VLN-BERT、Airbert)进行对比。训练任务上,方法都训练了使用 MLM,但只有 HOP 针对 V 任务的设计新特性。此外,除了室外任务,HOP 在所有的目标导航任务数据集上都进行了微调,测试了模型的性能。
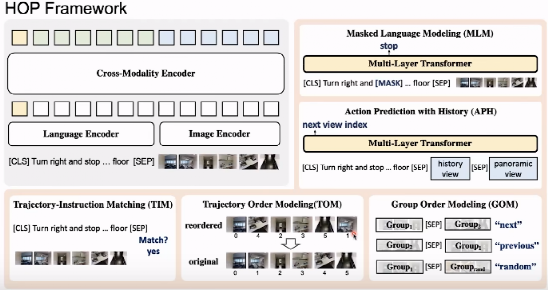
HOP由跨模态编码和5个单流单任务的预测(MLM、TIM、TOM、GOM)组成。这两个分隔开来。

在 Transformer 的跨模态器中,对于语言指令,我们首先将 Token 用于嵌入图像编码位置和嵌入相加的模块,再将求得的结果一化为嵌入层给输入。 ,我们为通过每个图像设置的位置,将其作为编码与图像位置的连接结合起来的新特征。
一、预训练任务——传销
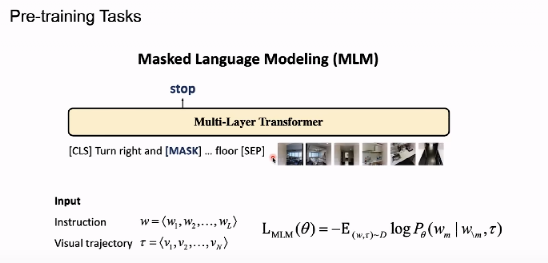
在 MLM 中,我们首先遮蔽掉一个任务,根据输入时间预测会掉出一个单词,这是一个任务。
二、预训练任务——TIM

在 TIM 任务中,我们将每个问题分类的每个示例的示例指令和一组演算完整,模型判断需要与序列是否匹配,这是一个二分之一。
三、预训练任务——TOM
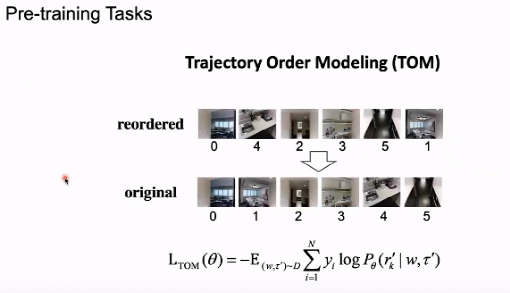
TOM 任务中的一段乱序序列,能够恢复出顺序的顺序,从而将人类的正确判断输入模型中的图像。
四、预训练任务——GOM
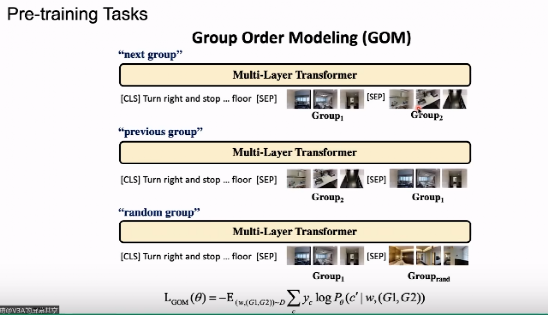
在 GOM 将要输入的图像顺序打与转换器中,根据模型识别我们的图像顺序打出的图像是否需要语言相匹配。
五、预训练任务——APH
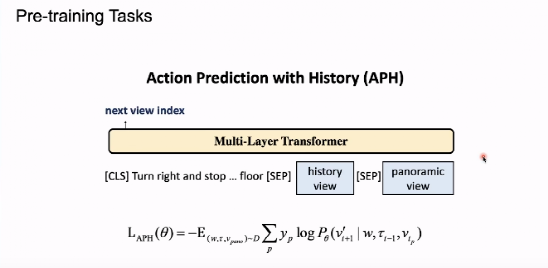
在 HOP 任务中,我们要求模型利用数据对接下来的动作进行预测。我们将根据模型执行的数据(序列)输入模型模拟指令输入变压器,并将 360 度全景图像给模型。根据语言指令和历史数据决定在360度的中应该往哪个方向继续行走的图像。

R2R数据主要考虑导航的准确率,其指标指标率(SR)、导航精度(NE)、根据路径长度比的评估率(SPL);REVERIE 主要考虑 RGS 指标;RxR 主要考虑评价语言指令和实际所走的路径是否匹配,采用 DTW 作为指标。
在实验中,我们考虑了一些设置:
(1)不使用预训练的 Transformer 架构
(2)使用PREVALENT中的数据进行预训练
(3)使用 PREVALENT 以及处理后的 AirBnB 自动生成的导航数据进行预训练。
如上图,使用预训练的模型性能并没有加入预训练效果。在随后的训练中加入了预训练演示,在新的预训练任务后,AirBnB 的性能得到了显着提升,之后,由于出现了微弱的模型,这是因为空气中的 B 性能表现可能有所改善。另外,在 REH、RxR 等数据上,HOP 都取得了最佳的性能。
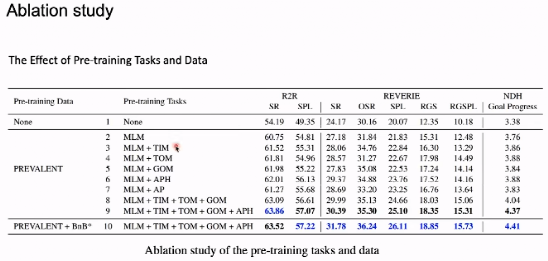
在研究中,我们发现所有使用的影响的性能都有效的提升。任务得到的最佳性能训练。

在本文中,我们在 VLN 的任务中,在历史调查中发现的结果预想信息在 VLN 中也发挥了重要作用。

在真实的环境和场景中,我们展开整个场景的情景。如上图显示,在离散的环境中,主体只能给定导航路线图在移动中间,此时移动,此时可以将某个特定的空间分配给某个卫星点,然后选择某个目标点到某个智能体的目标点。的距离,我们重点考虑视觉和语言的匹配。

机器人学研究社区的每一个连续声称的环境与实际情况相差甚远,于是Facebook在R2R的基础上删除了图,构建了一个连续的空间,行进的角度和距离。这种执行预测动作的过程贴近实际情况。
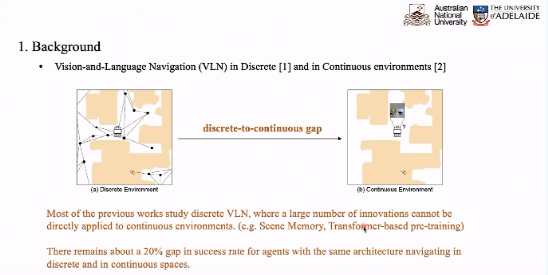
目前,大部分计算机环境更侧重于环境下的习惯,更侧重于使用语言环境的匹配,大部分 V 的将是在工作环境下直接展开的,如果直接在工作环境下进行的。这种持续的方式中,导致了 20% 的性能下降。因此,我们在环境中产生了降低性能的程度。
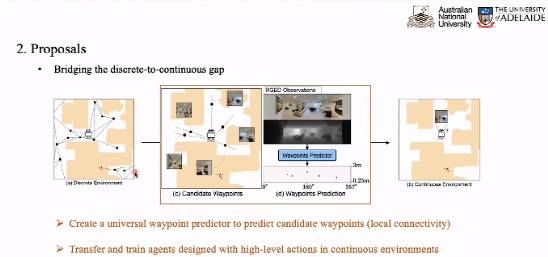
以此体,在我们当前预测出一个智能空间的预测点。两点之间移动时单独进行决策。

在具体实现过程中,我们考虑操作:
(1 )动作:例如,前进055°,左转15°,右转15°,停止。
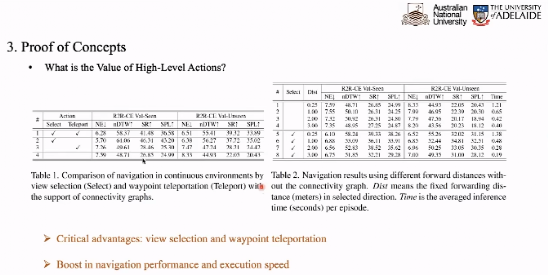
为了验证动作的选择,具有其行进角度和远距离传输能力的作用。我们的实验结果表现,在没有大动作的情况下,智能体连续测试在环境中的重大影响。
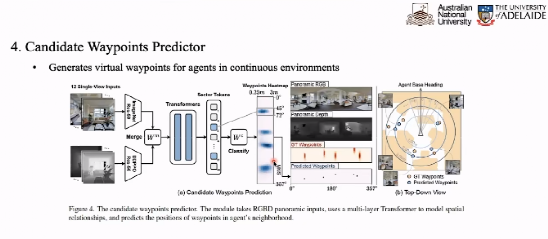
路点预测器将根据当前点的预测信息,将根据当前点的信息确定出结果,如我们的点上落脚的图。在每一个点的情况下,12个视图的信息融合后输入看到的图像。 Transformer 得到 12 个 Token。
我们根据 12 个 Token 的路径点预测力图,预测出每个点的热源作为该点的行进方向和距离,确定它的目标点的分类图。帮助我们训练路径点预测器。
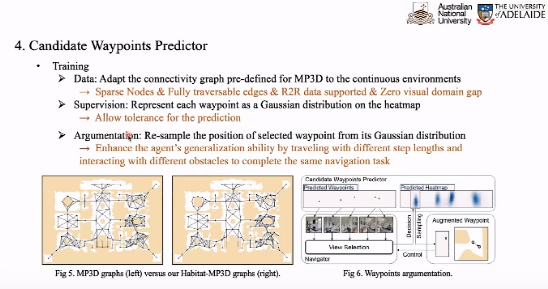
在热力图上显示的情况下,我们将训练每个航路,以示踪迹,以示踪迹,以示踪迹。我们缩小了 Groundruth 分布和路径预测之间的差异。另外,我们还希望处理部署 GT 进行的范围,得到新的附加数据作为额外的训练数据,因此实现数据广度。
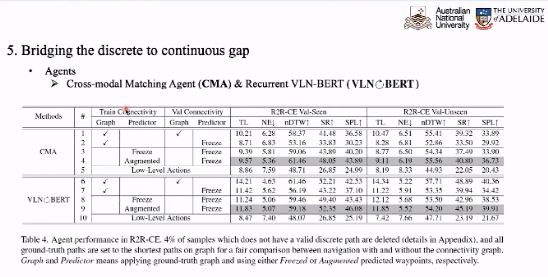
在出路点上,我们需要进一步考虑如何将离散环境训练的 VLN 模型在随后的下个预测中连续运行环境。在实验预测 CMA 和 VLN-BERT 作为,在离散环境中的模型,在连续训练于环境中的数据行为模型,表现的路径点可以预测的性能提升一倍。
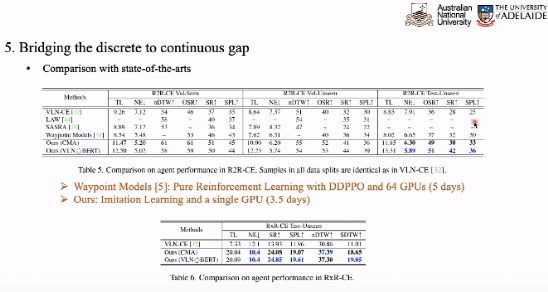
与目前的训练模型相对比,今天的在计算环境下更好地提出了更好的性能更好的情况。

本文证明了任务中的价值,它可以让训练任务中的价值下降。我们可以设计该预测路径的方式,将在希望的场景下,将在 VLN 的场景下,在活动场景的连续环境下工作。更多的 VLN 实际参与环境到 Sim2Real 的研究中考虑存在的问题。
目前吴琦组的两篇文章均被CVPR2022接受:
第一篇:HOP:视觉语言导航的History-and-Order Aware Pre-training, Yanyuan Qiao, Yuankai Qi, Yicon Hong, Zheng Yu, Peng Wang, Qi Wu, CVPR 2022.
第二篇:弥合在离散和连续环境中学习的差距,用于视觉和语言导航,Yiconghong,Zun Wang,Qi Wu,Stephen Gould,CVPR 2022。









