绑定手机号
确认绑定









2015年,亚马逊AWS收购Annapurna,开始了芯片自研之路。差不多同一时间,谷歌自研的AI芯片TPU也开始在内部使用。从此,互联网云计算公司纷纷开始了自研芯片之路,这成为了这些年IC行业重要的趋势。
于是,大家开始认为,各家互联网公司有自己的差异化竞争力,需要针对性定制的芯片来支撑,认为芯片定制是未来趋势。甚至有一些知名的芯片公司,开始为客户提供定制化服务。
但需要大家厘清的一个事情是:
商业层次。定制芯片是可行的,许多大客户有这个诉求。这块的论述不是本文的重点。
技术层次。大芯片功能定制则是不可行的,技术层次的大芯片架构和设计实现需要足够通用。本篇文章,会就技术层面进行详细分析。

1.1 CPU取代ASIC,成为计算芯片的主流
CPU之前,几乎所有的芯片功能都是固定的,我们只能对芯片施加一些基本的控制。要想有不同的功能,就需要不同的芯片。而CPU解决了这一问题,CPU通过支持各类基础的加减乘除以及各类控制类指令等,然后再通过这些指令,组织成非常复杂并且功能强大的程序,或者称为软件。
CPU最大的价值在于提供并规范了标准化的指令集,使得软件和硬件从此解耦:
硬件工程师不需要关心场景,只关注于通过各种“无所不用其极”的方式,快速的提升CPU的性能。
软件工程师,则完全不用考虑硬件的细节,只关注于程序本身。然后有了高级编程语言/编译器、操作系统以及各种系统框架/库的支持,构建起一个庞大的软件生态超级帝国。
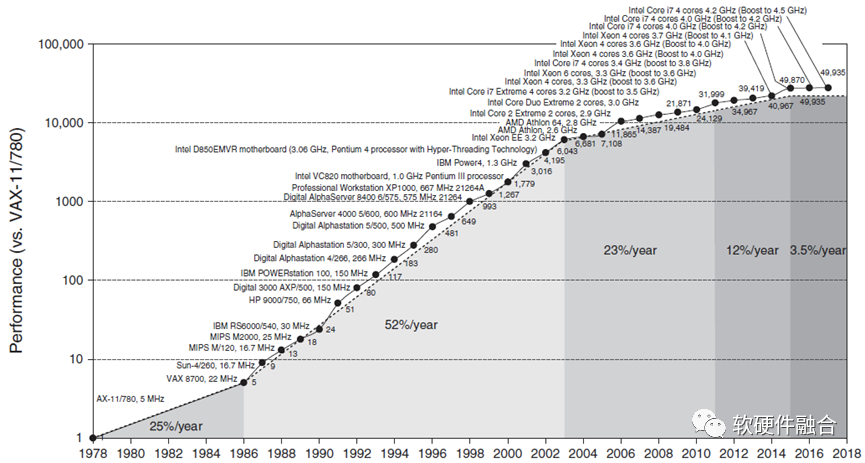
从图中,可以看到,在差不多40年的时间里,CPU的整体性能提升接近50000倍。一方面,这有赖于处理器架构的翻天覆地变化,也有赖于半导体工艺的进步。另一方面,更有赖于通过标准化的指令集,使得CPU平台的硬件实现和软件编程完全解耦,没有了对方的掣肘,软件和硬件均可以完全地放飞自我。
1.2 GPU到GPGPU
GPU,Graphics Processing Units,图形处理单元。顾名思义,GPU是主要用于做图形图形处理的专用加速器。GPU内部处理是由很多并行的计算单元支持,如果只是用来做图形图像处理,有点“暴殄天物”,其应用范围太过狭窄。
因此把GPU内部的计算单元进行通用化重新设计,GPU变成了GPGPU。到2012年,GPU已经发展成为高度并行的众核系统,GPGPU有强大的并行处理能力和可编程流水线,既可以处理图形数据,也可以处理非图形数据。特别是在面对SIMD类指令,数据处理的运算量远大于数据调度和传输的运算量时,GPGPU在性能上大大超越了传统的CPU应用程序。现在大家所称呼的GPU通常都指的是GPGPU。
NVIDIA因为在GPGPU上的技术能力和市场占有率,成为了目前市值最高的芯片公司。
只考虑系统架构,GPGPU的成功可以总结为两点:
通过通用性设计,拓宽了GPU的应用领域和场景,使得其可以更大规模的落地;
通过通用性设计,实现了软硬件的解耦,软件和硬件可以脱离对方的束缚,努力的提升“自我”。
1.3 从ASIC到DSA的回调
ASIC是定制芯片AS-IC,对应的,可以把其他偏通用的IC称之为GP-IC。一般来说, ASIC引擎“指令”复杂度最高,也即性能最极致。但实际上,受限于很多其他原因,ASIC的表现并不如大家想象的那么优秀:
ASIC是定制的,没有冗余,理论上是最极致的性能。但因为ASIC是场景跟硬件设计完全耦合,硬件开发的难度很高,难以实现超大规模的ASIC设计。
理论上来说ASIC的资源效率是最高的,但由于ASIC覆盖的场景较小,芯片设计为了覆盖尽可能多的场景,不得不实现功能超集。实际的功能利用率和资源效率(相比DSA)反而不高。
ASIC功能完全确定,难以覆盖复杂计算场景的差异化要求。差异化包含两个方面:横向的不同用户的差异化需求,纵向的单个用户的长期快速迭代。
即使同一场景,不同厂家的ASIC引擎设计依然五花八门,毫无生态可言。
DSA针对特定应用场景定制处理引擎甚至芯片,支持部分软件可编程。DSA与ASIC在同等晶体管资源下性能接近,两者最大的不同在于是否可软件编程。ASIC由于其功能确定,软件只能通过一些简单的配置控制硬件运行,其功能比较单一。而DSA则支持一些可编程能力,使得其功能覆盖的领域范围相比ASIC要大很多。
DSA,一方面可以实现ASIC一样的极致的性能,另一方面,可以像通用CPU一样执行软件程序。当然了,DSA只会加速某些特定领域的应用程序。例如:用于深度学习的神经网络处理器以及用于SDN的网络可编程处理器。
1.4 千万种手持设备,最终都融合进了智能手机

如上图所示,周围的这些形态和功能各异的各种电子设备,每一样都具有特定的功能,满足用户形形色色的需求,但最终,都几乎消失在历史长河中。剩下的,就只有唯一的一个私人移动终端——智能手机。
第一代iPhone面市时,诺基亚工程师对其进行了全面的研究,最终认定,它不会对诺基亚产生威胁,原因是造价太高,并且只兼容2G网络,而且未能通过基本的抗摔测试。诺基亚引领了很多手机功能的“创新”,比如手机摄像、全功能键盘、塞班操作系统,当然也包括和弦铃声、换壳等。此时的诺基亚,市场占有率最高,如日中天。但是,诺基亚没能挡住历史的滚滚潮流,无法改变被市场无情抛弃的命运。
智能机和功能机最大的区别是:功能机是提供产品功能给用户;而智能机提供的产品是一个没有具体功能的通用平台,通过安装开发者开发的各种APP,给客户提供不一样的功能。这个改变,使得单个平台就可以适配用户数以万计的各种个性化需求。
2.1 终端小规模芯片设计的思考逻辑
终端场景的小芯片,通常是以SOC方式存在的。一方面终端设备的数量庞大;另一方面,许多芯片不需要7nm、5nm这样的先进工艺,其研发成本也相对较低。研发成本在单芯片的成本占比非常低,更多的则是芯片本身量产时的成本。这类芯片,一定是优先考虑芯片的面积等影响量产成本的因素。
除此以外,许多终端场景芯片是电池供电,这就对芯片的功耗的重视程度放在了第一位。功耗要求严格的话,势必需要对一些不必要的功能进行裁剪。不管是内部模块,还是整个SOC架构,一定是尽可能精简。
总结一下,终端场景,设备数量庞大,成本主要受量产成本的影响,并且功耗敏感。这样,终端SOC,就表现为定制的特征。
2.2 数据中心为什么是以CPU为主?
跟终端场景相比,数据中心的需求却又是另一个逻辑。这里有一个非常经典的问题:终端非常流行SOC,但为什么数据中心服务器却依然是CPU打天下?
越是复杂的场景,对系统灵活性的要求越高,而只有CPU能够提供云场景所需的灵活性。CPU作为云计算场景的主力计算平台有其合理性,主要体现在四个方面:
硬件的灵活性。软件应用迭代很快,支持软件运行的硬件处理引擎要能够很好地支持这些迭代。ASIC这样绝对定制的处理引擎不太适合云计算场景,而CPU因为其灵活的基础指令编程的特点,可以认为是最适合云计算的处理引擎。
硬件的通用性。云计算厂家购买硬件服务器,然后把服务器打包成云服务器卖给不同的用户,很难预测这些硬件服务器会运行哪类工作任务。最好的办法是采用完全通用的服务器,用在哪里都可以。这样,CPU由于其绝对的通用性,成为云计算场景最优的选择。
硬件的利用率。云计算的基础技术是虚拟化,通过虚拟化把资源切分,实现资源共享,以此提高资源利用并降低成本。而目前,只有CPU能够实现非常友好的硬件级别的虚拟化支持。
硬件的一致性。在终端场景,软件依赖硬件,成为软硬一体。在云计算数据中心,软件和硬件是需要相互脱离的。在云计算场景,各种复杂系统交织在一起,形形色色各种任务混合运行,这些任务随时可能被创建、复制、迁移和销毁。同一个软件实体会在不同的硬件实体迁移,同样的同一个硬件实体也需要运行不同的软件实体。这对硬件平台的一致性提出了很高的要求。
在性能满足要求的情况下,CPU就成了数据中心计算平台的最佳选择。
2.3 DSA的发展困境,说明:算力芯片需要性能提升,但不能损失通用灵活性
很不幸的是,CPU已经达到了性能瓶颈。系统越来越复杂,需要选择越来越灵活的处理器;而性能挑战越来越大,需要我们选择定制加速的处理器。这是一对矛盾,拉扯着我们的各类算力芯片设计。
谷歌TPU是第一个DSA架构的AI加速芯片,从TPU开始,各类DSA架构的AI芯片如雨后春笋般出现。但如今,差不多5年时间过去,AI芯片大规模落地的案例依然不多。最明星的谷歌TPU,目前也遇到了一些困境。
据“云头条”公众号报道:“谷歌发言人表示,重视TPU源自2018年至2021年在组织上和战略上的混乱和迷茫,结果导致投入不足,对GPU支持并未给予应有的重视度,以及缺乏与大型GPU供应商英伟达的合作,不过这几方面都在迅速改善。公司发言人表示,谷歌自己的内部研究也主要致力于TPU,这导致GPU使用方面缺乏良好的反馈回路。”
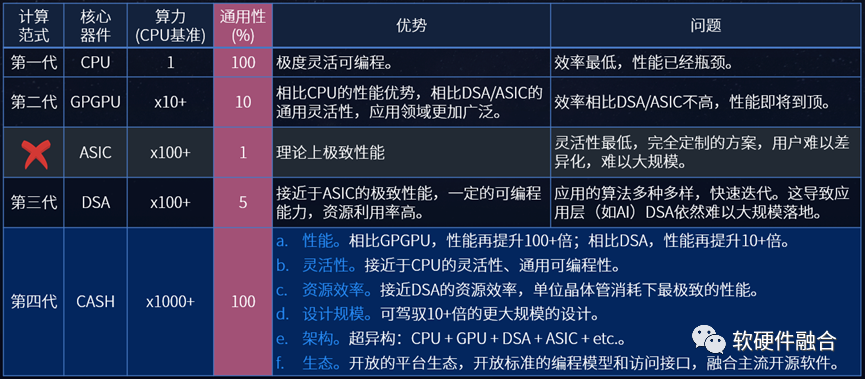
谷歌TPU的困境可以简单总结为:底层芯片平台和上层应用算法的通用灵活性不匹配问题。上图对各类处理引擎的性能和灵活性进行了定性的分析,我们来进一步分析,DSA架构AI芯片的问题可以总结如下:
AI场景目前从性质上来说,属于应用层次:算法众多,模型众多,而且算法迭代很快。因此,需要运行AI的硬件平台具有非常高的适应性和灵活性。
实践证明,目前,DSA架构所能提供的灵活可编程能力无法满足上层应用和算法所需,因此DSA架构的AI芯片落地出现困境。
实践证明,GPGPU是目前AI算力的主流平台,因为GPGPU的灵活可编程能力和AI算法的需求是相对匹配的。
AI芯片要想大规模落地,需要应用和平台两方的相向而行:
随着AI的发展成熟,场景和算法逐步成熟,AI场景逐步从应用层次沉淀成基础设施层次。也即对灵活可编程能力的要求降低。
DSA架构AI芯片的持续创新,在保证性能极致的情况下,尽可能的持续提升芯片的灵活可编程能力。
3.1 系统复杂度上升,使得硬件平台必须通用
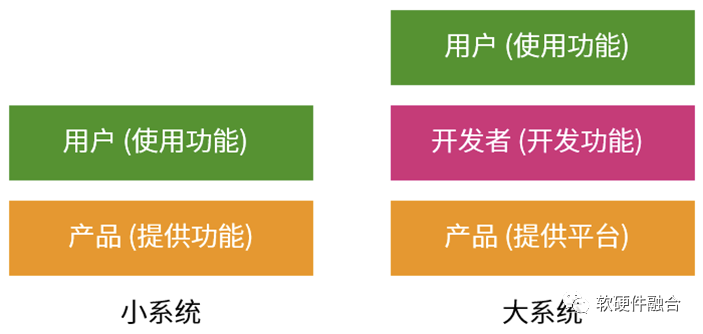
小系统,我们明确地知道使用场景和用户需求是什么,并且系统的构建成本低,场景也有足够大的规模。那么可以设计一个功能确定的专用系统来满足用户场景需求。
但大系统,面对的多个场景混合到一起的宏场景,每个场景用户需求五花八门,多个场景叠加,就构成了千千万万的差别化的用户需求。如果再考虑到复杂系统中软件的持续快速迭代,和硬件的复杂度和“漫长”生命周期。硬件构建确定的功能,来直接满足最终用户的需求,几乎是不可能的事情。一定要通过一个中间层,在相对通用的产品平台,开发用户“千人千面”的功能需求。
系统越来越复杂以后,不要尝试着帮助用户决策,因为:用户的业务也在快速的演进发展中,用户自己可能都不知道自己明天的需求是什么。把功能固化到硬件中,就变得不那么现实。需要构建底层平台,然后通过中间层的框架、编程环境等,来开发特定的功能,以此来服务更上层的使用者。
3.2 芯片的研发成本,需要更多的量来摊薄
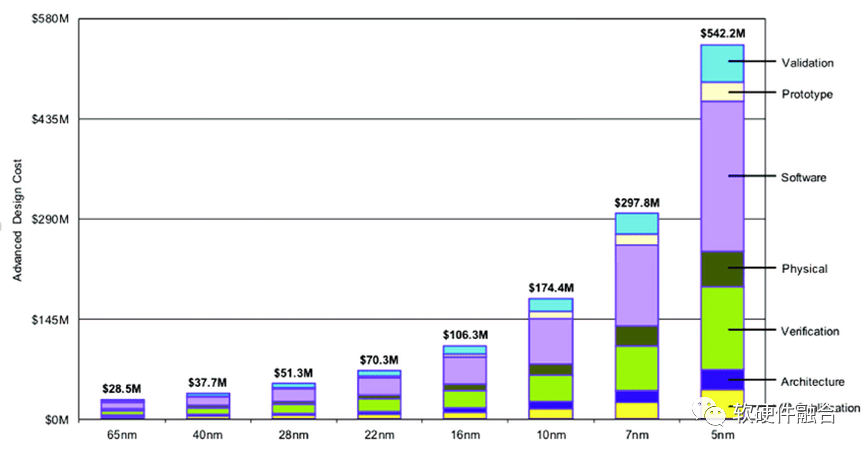
半导体工艺发展到现在,5nm芯片的研发成本大概是5个多亿美金。芯片需要足够的销量,才能摊薄研发成本。
这个挑战很大,这意味着在智能终端需要1亿颗芯片,数据中心需要1百万颗芯片的量才能有效摊薄研发成本。
3.3 不同用户业务差异和用户业务迭代
在SDN出现之前,主流的网络设备基本是ASIC的,设备提供什么功能,用户才能用什么功能。但是随着云计算等更复杂的网络场景出现,对网络协议和功能的个性化需求越来越多。当用户的需求反馈给芯片厂家(如博通、思科等),它们再在新一代的芯片研发中心去支持(并且,是否支持新的协议或功能还需要内部决策,有可能一些认为不太重要的协议或功能就无法得到支持,并且小客户提的需求就不会太多考虑),芯片开发完成后第一时间交付给用户,然后等到用户更新自己的软件服务,至少需要2年时间。这么长的周期,对互联网云计算的客户来说,是完全不可接受的。
不同用户的业务存在差异;即使同一个用户,其业务也会经常性地更新迭代;甚至,一些大客户内部,不同部门之间的同一个场景的业务也存在差异。当我们面对客户千千万的需求的时候,不能只做一个相对功能固定的产品,这样无法满足用户差异化的场景需求;也无法做千千万的产品来一一满足,因为芯片的NRE门槛使得这样的做法就完全不可能;合适的做法则是做一个通用的平台来尽可能地满足所有需求。
二八定律,是计算机领域的一个常见的规律。如:CISC指令集太过冗繁,只有20%的指令经常用到,这就是RISC指令集的基础;云计算,是一个由众多服务组成服务分层体系,随着不断的抽象封装,云运营商接管了80%的众多服务分层,而用户只需要关注20%的应用或函数。
当面对错综复杂的用户差异性需求时,相近场景问题的本质必然是相同的。也即不同用户的差异化需求,特征上是符合“二八定律”的。其中80%共性部分可以通过固化的硬件实现,20%个性化的部分可以通过软件编程实现。当然,这里的软硬件解耦非常考验芯片团队对场景和业务的整体把控能力,以及软硬件解耦和再协同的能力。
说到通用,大家一般会想到芯片公司提供的产品和解决方案;说到定制,大家一般会想到客户自研或者找第三方合作伙伴深度合作。但其实,通用和自研是不矛盾的,通用是技术路径,自研是商业选择,完全可以自研的同时做通用的产品,亚马逊AWS就是典型的例子。
DPU/IPU的相关技术创新,是从亚马逊AWS开始的。全球最早的DPU类产品,即亚马逊AWS的第一代Nitro,是在AWS re:Invent 2017上发布的。初代Nitro本质是一款CPU芯片,几乎100%的计算都在CPU完成。之后,后续的几代Nitro,开始逐步集成一些相对弹性一些的加速器。
为什么说Nitro最开始的产品是CPU呢,原因在于:
类似NVIDIA DPU,通过硬件加速实现了单颗芯片满足整个DPU/IPU的工作,而在AWS的NITRO系统里,通常需要5张NITRO不同类型的卡来协作满足需求。
从AWS的一些产品功能的描述中可以分析出,Nitro依然是一个充满了通用可编程能力的芯片。
即使自研芯片,AWS依然尽可能地保持Nitro系统的通用可编程能力,审慎的加入各类加速引擎。可以看出,其对通用灵活性的追求,明显地高过了对性能的追求。
定制还是通用,在技术层面是一个技术选择问题。但在更宏观的层次来看,却又是一个必须选择的道路。
算力,是数字经济时代的核心生产力,算力对推动科技进步、促进行业数字化转型以及支撑经济社会发展发挥着重要的作用。《2020全球计算力指数评估报告》指出,算力指数平均提高1个点,数字经济和GDP将分布增长0.33%和0.18%。2021年12月,Intel高级副总裁兼加速计算系统和图形部门负责人Raja Koduri表示:要想实现《雪崩》和《头号玩家》中天马行空的体验,需将现在的算力至少再提升1000倍;并认为,元宇宙可能是继Web和移动互联网之后的下一个主要的互联网形态(也即Web3.0)。
要想算力千倍万倍提升,不仅仅需要应用算法、系统架构、工艺封装等全方位的巨大创新,还需要站在更宏观更系统的角度,把各个层次、各个方向的创新进行充分地整合。
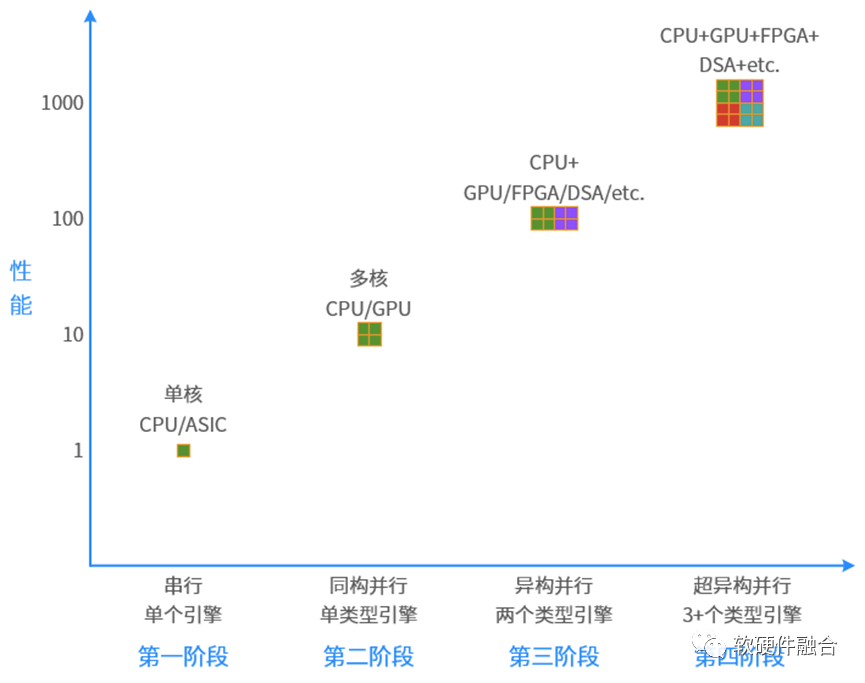
首先,体现在微观层次,算力芯片需要高性能。计算已经从同构计算走向异构计算,但异构计算解决单领域问题,把更多领域的异构计算整合在一起,形成超异构计算。计算,需要再从异构计算走向超异构计算。
其次,宏观算力,需要算力芯片大规模部署。芯片想要大规模部署,就要能够灵活地适应更多的场景落地,满足各个用户差异化的需求,满足上层应用经常性的、持续数年的业务逻辑迭代。也就是说,芯片的特性方面,需要支持更多的通用灵活可编程能力。
再次,宏观算力需要充分利用。虽然,可以通过网络把各自的计算设备连成一体,但其算力仍然是各自的孤岛,这些算力无法共享和自动化分配,这就需要把各自算力的孤岛打通,主题体现在:
计算需要跨不同的计算引擎,软件需要可以在CPU、GPU、DSA等架构处理引擎上运行;
计算需要跨不同芯片厂家的平台,这对平台的一致性提出要求,需要形成开放的架构和生态;
计算需要跨云、网、边、端设备,实现云网边端的融合;
计算需要跨不同的CSP的不同数据中心,以及不同厂家、不同品牌、不同类型的终端设备。
万物互联,不仅仅是各个云边端设备之间的通信互联,更是把大大小小的设备算力连成了一体,如臂使指。这就需要开放的计算生态。
总之,通用的、开放的算力技术生态,是整个数字经济社会持续繁荣发展的必由之路。








