绑定手机号
确认绑定









像Intel Architecture Day这种大型活动,如今露面的普遍都是Raja
Koduri。Koduri以前的从业经验普遍与图形计算有关,比如他最早于1996年加入的S3
Graphics...Koduri被大众所知应该是2015年时,他成为AMD的Radeon技术部门首席架构师和高级副总裁。而在加入Intel以后,Koduri俨然成为了Intel的技术代言人。
比较有趣的是,这也伴随半导体行业发生转向的档口:人们愈发关注更偏专用的计算方向,甚至有人提出未来CPU这类通用计算处理器会走向边缘化,或者越来越作为单纯的控制器存在。GPU、NPU、IPU等各类XPU如今正大放异彩。所以这些年Intel的XPU策略也在做大肆的扩张,在CPU之外通过收购、研发快速铺开了不同的处理器产品线。

比如GPU就是Intel现在的一个发展重点,不仅是酷睿CPU产品线中近两年两度大幅加强了核显性能(Xe-LP),以及前不久Intel正式发布游戏GPU品牌“Arc”;还在于一年多以前,Raja Koduri就在Twitter发了一张Ponte Vecchio(面向数据中心的GPU)照片,引发无数猜想。
今年的Intel Architecture Day上,更多有关Intel GPU的产品信息揭开面纱。这次Intel主要谈到了面向游戏玩家的Xe-HPG架构Alchemist GPU;以及面向数据中心的Xe-HPC架构GPU芯片Ponte Vecchio。后者被Intel形容为技术难度“堪比登月”的芯片,这也是我们第一次见到MCM(Multi-chip Module)/chiplet形态的GPU芯片,后面的内容会做更详细的剖析。
虽然以前Intel曾多次尝试过进入GPU领域,但这次恐怕是动作幅度最大、计划最长远的一次。借着这次机会,我们也能看看作为GPU领域的新手,Intel是否有机会在两强争霸(以及数据中心英伟达一家独大)的局面下有所斩获;另外也能从中窥见当代GPU的思路大致会是什么样。
本文篇幅较长,大体分成三部分,可选择性阅读。不想看技术细节的,可略过中间部分,直接看最后的总结。
1.面向游戏玩家的Alchemist架构GPU;
2.面向数据中心的Ponte Vecchio GPU芯片;
3.总结,与oneAPI开发平台。
面向游戏的Alchemist,台积电N6工艺造
此前Intel在宣布Xe架构GPU的时候,提出以一个架构做弹性化扩展,来实现GPU产品覆盖各个领域,包括低功耗平台、游戏、工作站、数据中心等。其实在GPU领域里,同一种架构的规模化缩放也是常态。Xe此前在规划上有Xe-LP、Xe-HP、Xe-HPC之分,面向不同群体如下图所示:

这次Architecture Day上重点之一的Xe-HPG,是指high performance gaming。从Intel这次的介绍来看,不同的Xe架构差别也可能是比较大的。这次新发Xe-HPG架构Alchemist的GPU,就和此前集成在酷睿处理器内部的Xe-LP架构GPU有很大不同。或者说Xe-HPG GPU并不单纯只是Xe-LP GPU的规模扩大版。
首先是在GPU构成的基本单位上,Intel决定将不再采用之前“EU(执行单元)”的说法——原本我们过去谈Intel的核显,都用多少个EU来表明其规模——比如移动版11代酷睿,我们说其上最多有96EU的核显。Intel说之所以抛弃EU这个说法,是因为“EU数量变得太大,难以做参考;且迭代变化令其难以做比较”。

所以这次Intel引入了一个新的GPU构成基本单位:Xe核心。Xe核心包括算术单元、cache、load/store逻辑单元。算术单元部分包含一般的矢量引擎,以及加速卷积和矩阵运算的AI引擎。有兴趣的同学可以去回顾一下Xe-LP的最小构成单元EU,及EU集群构成的subslice。感觉Xe核心在切分粒度上,还是比EU更大,并靠近subslice的。
对于Xe-HPG而言,Xe核心内部包含了16个矢量引擎和16个矩阵引擎,如上图所示。一个矢量引擎每周期处理256bit数据,16个一起似乎与英伟达安培架构的SM单位吞吐类似。
这里的Matrix Engines矩阵引擎,又被Intel称作XMX(Xe Matrix eXtensions),结构上也就是传说中的脉动阵列(systolic array)。后文会提到,XMX在游戏方面对XeSS这类超分辨率之类需求AI算力的特性是有价值的(XeSS类似于DLSS)。Xe核心的矩阵引擎每周期处理1024bit数据,转换成常见的inference操作也就是128 INT8。
英伟达GPU也有配套的tensor core,所以Intel的XMX也算是行业迈进的主旋律了。不过英伟达tensor core的配置并没有Intel这么激进,Intel这边是做到了每个Xe核都带XMX。似乎Intel对AI的未来比英伟达还看好,一旁的AMD不知作何感想。要知道这只是游戏GPU。

多个这样的Xe核心就构成了所谓的render slice(渲染切片)。Alchemist的一个render slice包含了4个Xe核心——当然除了Xe核心外,还配套了其他渲染固定功能单元,有4个光线追踪单元、4个纹理采样器(sampler),以及几何、光栅化单元,和像素后端(实现8 pixels/clock的吞吐)。在slice层面,Xe-HPG核心的实施粒度似乎比以前的Xe-LP更细了,包括Xe核心数量及固定功能单元的配置。
Intel特别强调了Alchemist为DirectX 12 Ultimate设计,所以支持VRS(可变着色率)Tier 2,mesh shading、sampler feedback,当然还有光线追踪(DirectX、Vulkan)。此处的光线追踪单元应该也是很多人比较关注的。Intel提到,这些光追单元“旨在加速光线遍历(ray traversal)、包围盒相交(bounding box intersection)和三角形相交计算”。这应该是比较常规的光追专用硬件设计思路,此前我们曾撰文探讨过。光追性能具体是什么样,还是要等将来的产品问世才能了解。

到整个GPU层面,也就是把这些slice组合起来,通过Memory Fabric将这些slice连接到共享L2 cache。在配置方案上,最多可以连8个slice。完整的GPU前端还会有个全局dispatch处理器,进行具体的任务分发。构成GPU的其他组成部分,比如显示、媒体引擎等大概都要等到具体产品问世的时候,才会有具体规格公布。

到产品层面,Alchemist GPU究竟是何配置,其实还是个未知数。不过其最大可扩展方案应该会比Xe-LP核显和之前买不到的DG1(Iris Xe Max),在性能方面高出许多;而且XMX、光追单元之类的功能跟进上,也表现出此前的DG1也就是练个手。
Intel也特别提到,与Xe-LP(DG1)相比,Xe-HPG在架构、逻辑设计、物理设计、工艺改进、软件迭代等各方面的努力,实现了运行频率与每瓦性能的提升,这两项都有1.5倍的提升。尤其频率提升表现为同电压下,频率的1.5倍提升。考虑加上更大的规模(比如用8个slice),则性能比DG1有数倍提升应该也不是问题。
谈到工艺改进,Alchemist GPU采用台积电的N6工艺制造——也就是此前N7工艺的一个改款。Alchemist也因此成为Intel的IDM 2.0计划施行的第一批产品。似乎IDM 2.0的推进还挺顺利。以Alchemist产品问世的时间点来看(2022Q1),N6工艺的GPU产品也会有一定的优势。此前Xe-LP核显和DG1用的是Intel 10nm工艺。
虽然Intel未曾透露最终产品的诸多配置细节,比如说选配多大显存,频率具体是多少,以及类似光追单元性能水平如何等。不过就架构层面的这些信息,以及N6工艺在GPU制造方面的略微领先,都令Intel的游戏GPU的准备工作看起来十分到位。

Intel另外也给出了Arc家族GPU未来路线图,代号为Battlemage、Celestial、Druid的新架构都在开发中,表明在造游戏GPU这件事情上,Intel这次还是很认真。
除了GPU本身,有关软件及开发生态的问题也是尤为值得一提的,毕竟Intel也算是这个领域的新手:对游戏开发者而言,成熟和简易的生态是确保显卡最终真正有销路的基础。英伟达在这方面的耕耘已经很久了,也不是一朝一夕就能超越的。
Intel在会上提到的,主要包括对于DirectX 12 Ultimate新特性的全面支持,包括光线追踪、VRS、mesh shading、sampler feedback,据说Intel过去这些年一直在和微软合作对新功能做打磨。
另外Intel也在与Epic合作,“现在我们的独立GPU能够运行虚幻引擎5”。“产品发布时,我们还将更新我们的用户控件,帮助玩家利用AI辅助虚拟摄像头、游戏高光时刻捕捉、直播拍摄等技术。这些技术将使用我们的高性能与高质量的硬件编码器。”
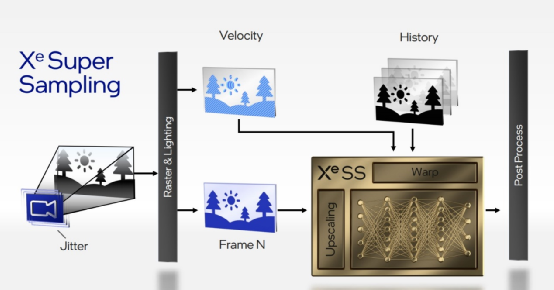
在特性支持上尤为值得一提的是XeSS(Xe Super Sampling),这是个类似于DLSS超分辨率技术,即将低分辨率的画面通过深度学习,来合成高分辨率渲染质量的画面。有关英伟达DLSS技术,此前我们多次撰文提到过。说XeSS和DLSS更接近(而不是AMD的FSR),是因为Intel大致解释提到XeSS原理是藉由画面中的临近像素,以及过去帧进行运动补偿,来重建子像素细节。该过程需要通过神经网络进行,和英伟达的二代DLSS是比较类似的。
这种操作显然就是由Xe核心中的XMX做硬件加速的。Intel在会上也演示了1080p到4K画面,与原生4K分辨率渲染的比较,效果看起来还不错。似乎在光线追踪之外,超分辨率技术也已经成为GPU厂商的技术必争之地了。
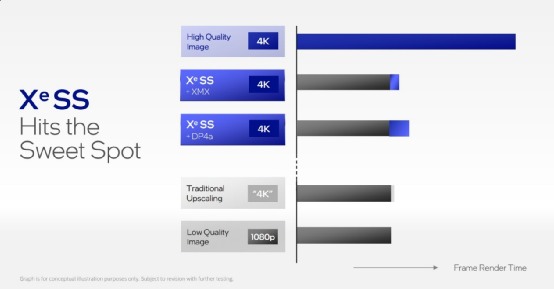
比较有趣的是,Intel计划把XeSS推到Xe GPU以外(这一点就比较像AMD了),“包括竞争对手的产品”。“我们通过用DP4a指令来实现这一点,该指令已经用于各种硬件产品。”“这会将XeSS带给数以百万计的游戏玩家。”据说有不少“早期游戏开发者”已经开始采用XeSS。“初始XMX版本的SDK将于本月面向软件厂商推出,DP4a版本则将于今年晚些时间推出。”
Ponte Vecchio,第一个MCM GPU
此前我们撰文谈到过,GPU越做越大,已经接近光刻机可处理的rectile limit,那么GPU未来的发展方向极有可能是走向chiplet式的MCM(multi-chip module)形态方案的。只不过GPU要应用MCM,仍然有不小的技术难度。AMD和英伟达此前都在这方面做过努力。
现在看来最早推MCM型GPU的,似乎是Intel,也就是Intel这次花了相当大篇幅解释的、采用Xe-HPC架构、面向数据中心、主要针对AI和HPC工作负载的Ponte Vecchio。Intel说这颗芯片的实现,在难度上堪比登月计划。
现在面向数据中心的GPU、FPGA、AI芯片产品,在发布会上都喜欢用PPT来吊打Intel至强处理器。在算力上用更偏专用的芯片来吊打通用处理器,听起来是不够公平的。不过从行业走向来看,Intel也应该早就发现,CPU在数据中心的重要性已经大不如前了。即便这次的Sapphire Rapids新增了AMX以及各种专门的加速单元,数据中心作为Intel的主场,推更专用的芯片也是势在必行的。

Raja Koduri也在讲话中特别谈到了这一点。所以Xe-HPC或者说Ponte Vecchio的使命便是极大程度的填充这其中的空白(这次报道中不曾提及的Intel新发布的IPU基础设施处理器,其实也有这样的使命)。君不见英伟达如今在数据中心已经赚到盆满钵满了吗?
上面这张图的蓝色曲线表示Intel处理器,绿色表示“业内最好的”(英伟达?),在HPC、AI、内存带宽方面都存在着历史上的差距(也就是之前每逢处理器芯片,必被吊打的局面)。而Xe是Intel决心领先行业的GPU架构。那么我们就来看看Intel的Xe-HPC架构,与Ponte Vecchio芯片。

和前文谈到的Xe-HPG一样,Xe-HPC也以Xe核心为GPU的基本构成单元。不过在Xe核心构成上有差别。前文谈到,Xe-HPG Alchemist每个核心是16个矢量引擎和16个矩阵引擎,在Xe-HPC上则是8个矢量引擎和8个矩阵引擎(XMX)。但从单引擎可处理的数据来看,其量级是不同的。Xe-HPC核心中的单个矢量引擎每周期可处理512bit数据——是Xe-HPG的2倍;而每个矩阵引擎,“8深度脉动阵列”,每周期处理4096bit数据(8组512bit宽矢量运算),则是Xe-HPG的4倍。显然Xe-HPC核心极大加强了XMX。似乎比隔壁英伟达的配方在AI算力上明显更为足料。
Xe核心构成大体与Xe-HPG是一样的,即主要是ALU、cache、load/store逻辑单元。这里Intel给出了一些更具体的数字,包括load/store操作是每周期fetch 512bit数据——应该比隔壁Xe-HPG要宽;与此同时L1-D cache尺寸为512KB,Intel表示这是行业内最大的。“L1 cache也可通过软件配置作为暂存区,即Shared Local Memory(SLM)”。
矢量引擎对于数据格式每周期的操作支持,包括了256 FP32、256 FP64、512 FP16;XMX则为2048 TF32、4096 FP16、4096 BF16、8192 INT8。Intel特别强调说,Xe核心能够共同发射(co-issue)指令,“超越这些单一的每个时钟周期运算次数”。Intel函数库和内核利用这项特性可实现Xe核心更高的性能。

多个Xe核心组成slice。一个Xe-HPC的slice是由(最多)16个Xe内核构成的,比前文谈到的Xe-HPG规模大出了很多;总共也就是8MB L1 cache。Slice中强调了Xe-HPG图形计算的一些固定渲染功能单元;每个核心依然搭配1个光追单元,所以一共是16个光追单元——前面也已经提过光追单元用于光线遍历、包围盒相交与三角形相交运算。这对专业视觉应用会有价值。
此处的Hardware Context能够让GPU并行执行多应用,“不需要开销比较大的基于软件的上下文切换”。“这也极大增加了云上GPU的利用率。”Intel并没有说这种硬件上下文切换的具体实现。

多个slice理论上应该构成了完整的GPU,不过Intel在此处称其为stack。似乎在整个GPU芯片上是一片die,或者一片chiplet的概念。
每个stack具体是4个slice:也就是说一个stack内(最多)会包含64个Xe内核、64个光追单元、4个Hardware Context。和Xe-HPG一样,stack这一级也就有了L2 cache(容量未知)。另外作为面向数据中心的GPU,外围要扩展出4个HBM2e控制器,还有“8个Xe Link”——是Intel专用于GPU之间连接的方案。媒体引擎部分,Intel依然没有细说其规格。Xe Memory Fabric连接了Copy Engines、媒体引擎、Xe Link模块、HBM、PCIe组成部分。

MCM的魔法就在Intel的多stack方案中体现出来了。用Intel的EMIB封装技术把两个stack(也就是两个chiplet/die)连起来——EMIB封装技术此前我们也多有介绍了,这是一种不同于台积电CoWoS用interposer硅中介来做die与die之间2.5D封装的方案,而是用嵌入在封装基板中的silicon bridge,以更低的成本实现die之间的互联,在效率上又会显著的高于直接从封装基板走线的方案。
Intel表示,“我们将每个stack上的Xe Memory Fabric直接连起来,这样也就在stack之间实现了统一一致性存储,这对软件而言很重要。”业界的第一个MCM GPU也就出炉了。上面这张图展示了2-stack方案。未知这种弹性扩展方案的延迟表现如何,不过这样的堆料方法的确能够达成显著更高的性能水平。
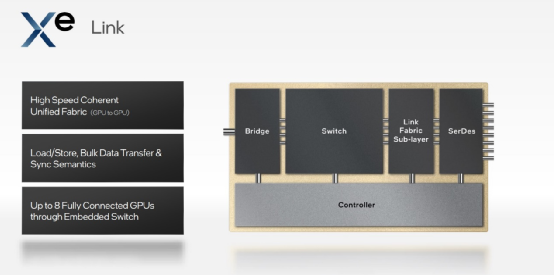

在多stack构成GPU以后,对数据中心而言,就涉及到GPU之间的连接了。Intel对此的方案是Xe Link,“支持load/store,大量数据迁移和同步语义;包含一个8-port switch,不需要额外的组件,就能在一个节点内实现至多8个GPU完全互联”。Intel表示,OAM-Universal BaseBoard加速模块设计规范下,对AI一类大型负载普遍可以用8个GPU的方案。不知道互联效率如何,Intel也没有在会上公布带宽等方面的具体数据。
接下来就该到产品层面了,即这回Architecture Day展示的重头戏Ponte Vecchio芯片。当Ponte Vecchio首席架构师将这枚芯片展示出来的时候,我们还是对其芯片尺寸表示相当震惊:其上超过1000亿晶体管,部分用到了台积电N5工艺,还记得之前的游戏GPU用的是台积电N6吗?不过事实上,基于2.5D/3D封装的不同chiplet用上了不同的制造工艺,据说这一颗芯片总共涉及到5种不同的制造工艺。

这颗芯片的开发,不只是前文提到的Xe核心及其构成方法,还涉及到各种新架构和新设计,乃至新工具的开发,“我之前从未在一款产品中做过这么多的新东西”,“Ponte Vecchio是我在30年的芯片开发生涯中开发的最复杂的芯片。”这是Intel Ponte Vecchio首席架构师Masooma Bhaiwala说的。最终目标是令其跑起来“就和monolithic芯片一样”,毕竟这是MCM/chiplet式的设计。

Intel把这枚芯片的构成切分为不同的“tile”,有compute tile、rambo tile、XeLink tile、HBM tile、Base tile等。Intel还特别提到,除了以EMIB的封装方式连接HBM内存(以及前面提到Xe-HPG本身也在stack之间做EMIB的die-to-die连接),Ponte Vecchio也用上了Foveros 3D封装方案,Foveros封装此前我们也撰文仔细探讨过。加上不同tile用上了5种制造工艺,有的是台积电造,有的是Intel自己造,这套方案的复杂度也就可想而知了。
从这张图似乎很难推断究竟是哪个tile叠在哪个tile上面,Intel只是说creates the 3D stacking of active silicon for power and interconnect density。Intel在此也特别分享了有关这颗芯片实现上的一些技术挑战,比如由于tile的多样和复杂性,Foveros的位置、floorplan需要在更早期的阶段就定稿。Ponte Vecchio芯片的Foveros连接数也比以往Intel的设计高出2个数量级。另外,测试验证也因此很复杂,所以需要实时开发出更多的工具、方法等等。

这颗芯片上的Compute tile,也就是计算部分属于芯片核心,每个tile包含8个Xe核心,总共4MB L1 cache(似乎和前面谈到Xe-HPC可配置每16个Xe核心构成1个slice、8个slice构成一个stack的方法不大一样,是某种弹性化方案?)。Compute tile是用台积电N5工艺制造的。
做Foveros 3D封装时,这部分tile的bump间距是36μm。从Intel以前公布的数据来看,36μm的间距应该是第二代Foveros,相比初代的连接密度翻倍。所以说Compute tile事实上同时浓缩了台积电最先进的制造工艺,和Intel最先进的封装工艺,也算是IDM 2.0战略的大成之作了吧。

Base tile部分是负责连接的,基于Intel 7工艺制造(也就是之前的10nm Enhanced SuperFin),其中包括各种I/O和高带宽组成部分,包括L2 cache,也涉及到PCIe Gen 5、HBM2e、(tile-tile的)MDFI高速互联、EMIB桥等。Intel表示这个base tile是Ponte Vecchio芯片上存在最大设计挑战的一部分。
另外还有Xe Link tile,也就是负责多GPU互联的部分,是基于台积电N7工艺制造,最高90G的SerDes支持。其他部分tile,Intel并未多做介绍。

Ponte Vecchio整体上,A0芯片(RTL开发完成后的首个硅流片?)所能达成的性能水平包括>45 TFLOPS的单精度算力(参考英伟达安培架构A100 GPU的FP32标称算力19.5 TFLOPS),>5 TBps的Memory Fabic带宽,以及>2 TBps的连接带宽(应该是指内部tile间的高速连接)。这组数字表明各部分tile在实现上都是比较“健康”的。
Raja有稍稍提到Ponte Vecchio GPU实际性能表现,“基于Ponte Vecchio和Sapphire Rapids的ResNet-50推理性能推图,超过每秒43000张图,超过市面上能见到的标准。而在训练方面,我们还处于早期阶段,初步测试显示Xe HPC的计算、内存和互联带宽已经具备训练最大型数据集和模型的能力。我们现在看到Ponte Vecchio性能是每秒超过3400张图片。”
这个表达还是比较模糊,尤其是在没有其他测试环境、没有价格也没有功耗数据的情况下。不过这么足的堆料做到性能上的领先也是应该的。

Ponte Vecchio最终形态自然是PCIe板卡,外加Xe Link互联bridge,Xe Link把多个GPU连起来。Raja表示OEM合作伙伴会提供多种加速计算系统——比如像上图这样的,系统方案中配套的CPU当然也就是Sapphire Rapids了。
oneAPI,Intel的XPU野心扩张计划
最后我们从硬件层面简单总结一下Intel的Xe GPU新品。其实就最终产品层面,仍有很多信息是未公开的,毕竟Architecture Day活动是以谈架构技术为主的。无论是Xe HPG Alchemist架构的高性能游戏GPU,还是面向数据中心HPC、AI的Xe HPC新品Ponte Vecchio芯片,都能表明Intel在GPU方向上投入了巨大的人力和物力。
Intel这次定的起点很高,Alchemist游戏GPU明年一季度就问世,GPU领域主流的光线追踪、XeSS(超分辨率),以及DirectX 12 Ultimate诸多特性就已经准备就绪,而且在堆料上看起来一点也不比英伟达节约。
而面向数据中心的Ponte Vecchio堆料和工艺技术的采用,甚至到了有些令人咂舌的程度。不谈Xe核心在矩阵引擎、cache堆料上的充沛,感觉一颗芯片用5种制造工艺,以及2.5D+3D封装齐上,还是业界第一颗MCM GPU——这些配置面前,1000亿晶体管这种数字都是不够看的。怪不得Intel称其实现难度堪比登月计划。
就这样的投入来看,Intel对GPU型产品寄予的期望,应该是完全不落于其传统项目CPU之后的。毕竟如文首所述,如今的行业现状和格局已经完全不像从前了。随摩尔定律的放缓,CPU在各类设备上的重要性都在下降,这是个XPU崛起的时代。只不过以英伟达如今在游戏与数据中心领域的地位,要从其口中分得一杯羹,也并不是件易事。

最后的最后,我们从Intel的oneAPI开发生态布局上可以看出一些端倪。Intel的XPU策略强调同一套开发生态,也就是Intel的oneAPI——这个软件平台的主旨是用一套API实现不同硬件性能埠的对接。Intel作为多种不同处理器类型的制造商,而且在CPU市场仍占据统领地位,推行这套生态还是有一定的优势;虽然当前GPGPU也还是英伟达的主场。
Intel在这次会上说软件开发者以往“必须用OpenCL、CUDA等不同的专业语言重写需要加速的代码。”所以oneAPI提供“开放、基于标准、跨架构、跨矢量的统一软件栈。”不过oneAPI事实上仍然是比较年轻的平台,首个版本发行至今时间也不久。

oneAPI指定了通用的HAL(硬件抽象层)、数据并行编程语言,以及解决数学、深度学习、数据分析和视频处理领域的各种性能库。更具体的本文就不再多谈了。
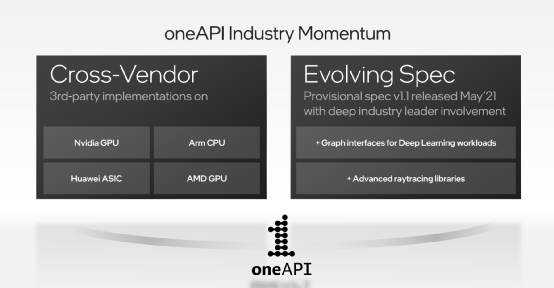
比较值得一提的是“已经有面向英伟达GPU、AMD GPU和Arm CPU的DPC++和oneAPI函数库实施方案。”Intel的说法是,“独立软件开发商、操作系统开发商、终端用户和学术界已经在广泛采用它。”
Intel公布说目前多个领域的软件开发商已经推出了超过300个基于oneAPI统一编程模型的应用;现有开发者超过20万;而且“我们有超过80个关键HPC应用、AI框架和中间件,采用了oneAPI,从现有仅基于CPU、或者是基于CUDA的GPU实施方案上快速移植。”
除了AI以外,oneAPI也有Rendering Toolkit、IoT Toolkit、HPC Toolkit、BASE Toolkit之类的各种构成。比如Rendering Toolkit中可做光线追踪的组成部分(Embree光线追踪库),Intel介绍说oneAPI Rendering Toolkit能应用于第三方处理器,比如说苹果M1。更多oneAPI的特性,几段话也很难介绍完。
不过感觉这些已经能够表现出Intel在生态构建上,入侵竞争对手市场的野心。此前Intel曾表达过oneAPI的“目标”是实现开放、跨平台、跨架构的开发与执行。其推进动作和速度还真是相当快。
美国阿贡国家实验室及Aurora项目已经在全面启用包括Sapphire Rapids、Ponte Vecchio、傲腾在内的Intel硬件产品,以及oneAPI。一个Aurora blade设备包含2个Sapphire Rapids CPU和6个Ponte Vecchio,主要用于HPC和AI。Intel这家公司如今的运转速度感觉比过去快了非常多。











