绑定手机号
确认绑定









设计一款自动驾驶芯片挑战Mobileye和英伟达是不是有点不自量力?未必,目前自动驾驶系统芯片即SoC设计大都是搭积木的方式,各种第三方IP就是积木,只要搭配得当,还是有可能挑战Mobileye和英伟达的,关键不在于技术,而在于有持续不断的巨量资金注入,这是一场马拉松比赛,坚持到最后就是胜利。
Mobileye的优势是软硬一体,开发周期最短,开发成本最低,技术成熟稳定,缺点是产品同质化明显,无法凸显整车厂的特色。MIPS指令集导致其系统封闭,升级能力差,无法适应快速演进的传感器技术,特别是激光雷达的大量出现。英伟达的优势是AI算力极其强大,留有足够的算力冗余,能适应各种算法,也能满足未来3-6年的算法演变。GPU的浮点算力也很强大,算力冗余足够,视觉感知能力强。英伟达提供完整的软件栈,系统也有点封闭,但算力很强大,整车厂还是能做出特色。缺点是GPU占裸晶面积大,硬件成本居高不下。
实际自动驾驶雷声大雨点小,在2017和2018年,众多科技类企业或整车厂都信誓旦旦要在2020年或2021年推出L4级车,没有方向盘和刹车踏板,最终都不了了之。2021年则是很多厂家推出号称L3/L4的量产车,但年销量都很难上千,究其原因主要是性价比太低,所谓L3/L4就是加强版的自适应巡航或堵车时的自动跟车,但代价却很高。目前L3/L4的技术条件远未成熟,未达到量产上路的地步,比如感知领域,突然出现的静止目标,非标障碍物,婴儿和小孩低矮目标探测与识别,光强度的迅速变化等挑战,以及决策领域的允许加塞或不允许等。此外,基础条件也不具备,如高精度地图和定位,红绿灯的V2X等。
未来10年内,L2+还是市场主流,至少占到90%的市场。高AI算力在L2+领域没有用武之地,所谓AI算力,只是卷积加速器,只是视觉分类的一个功能。遇上突然出现的静止目标、非标障碍物、婴儿和小孩低矮目标,即使再高的AI算力,还是要出事故,但硬件厂家的推波助澜,让消费者误以为高算力就是高等级自动驾驶。
要提高安全性不是提高AI算力就能做到的,激光雷达或立体双目能提供原生3D感知的传感器应用才能提高安全性,同时也要基于传统可解释可预测算法才能提高安全性。深度学习是个黑盒子,无法预测结果,无法解释,无法提高安全性。立体双目技术门槛太高,只有奔驰丰田大厂才玩得转,这是内部培养了十几年人才的成果。大部分企业都只能选择激光雷达。
激光雷达对SoC运算资源的需求CPU就可以完成,避免使用高成本的GPU。
图片来源:互联
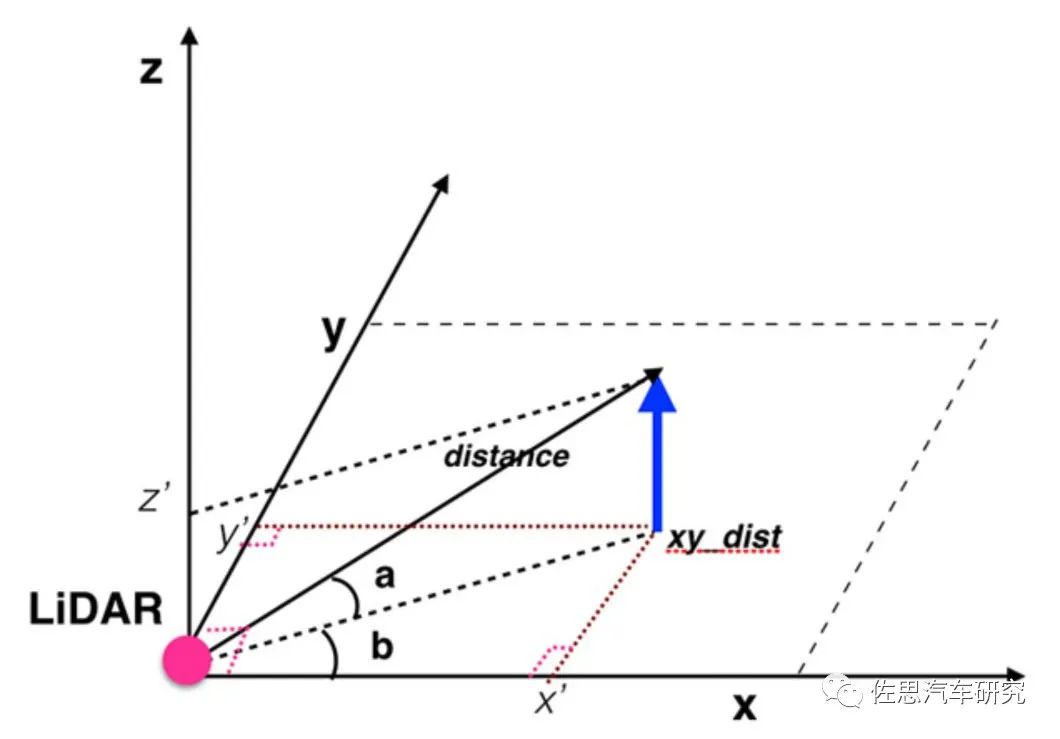
LiDAR通过激光反射可以测出与物体之间的距离distance,因为激光的垂直角度是固定的,记做a,这里我们可以直接求出z轴坐标为sin(a)*distance。由cos(a)*distance我们可以得到distance在xy平面的投影,记做xy_dist。LiDAR在记录反射点距离的同时也会记录下当前LiDAR转动的水平角度b,根据简单的集合转换,可以得到该点的x轴坐标和y轴坐标分别为cos(b)*xy_dist和sin(b)*xy_dist。
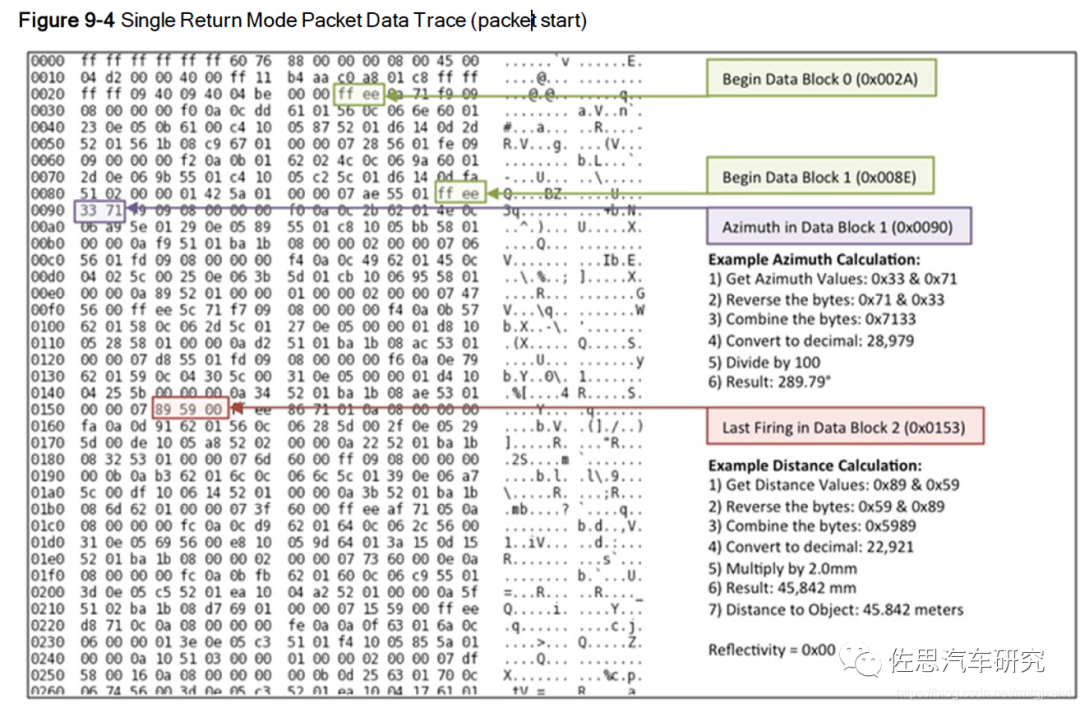
Velodyne VLP-16的数据包
图片来源:互联网
激光雷达的数据处理主要是两部分,第一部分是坐标变换,包括极坐标到直角坐标XYZ之间的变换,激光雷达坐标系与车辆坐标系的变换,这其中主要是三角函数变换。第二部分是点云配准。去噪音等预处理可以看做点云配准的一部分工作。
早期乘法运算和浮点运算资源奇缺,因此J. Volder于1959年提出了一种快速算法,称之为CORDIC(COordinateRotation DIgital Computer) 坐标旋转数字计算算法,这个算法只利用移位和加减运算,就能计算常用三角函数值,如Sin,Cos,Sinh,Cosh等函数。J. Walther于1974年在这种算法的基础上进一步改进,使其可以计算出多种超越函数,进一步扩展了Cordic 算法的应用。因为Cordic 算法只用了移位和加法,很容易用CPU来实现。Cordic算法首先用于导航系统,使得矢量的旋转和定向运算不需要做查三角函数表、乘法、开方及反三角函数等复杂运算。
CORDIC用不断的旋转求出对应的正弦余弦值,是一种近似求解法。旋转的角度很讲求,每次旋转的角度必须使得正切值近似等于 1/(2^N)。旋转的目的是让Y轴趋近于0。把每次旋转的角度累加,即得到旋转的角度和即为正切值。比如Y轴旋转45度,则值减小1/2,再旋转26.56505°,再减少1/4,再旋转角度14.03624º,再减少1/8,依次减少1/16,1/32......,最后Y轴的值无限小,趋近于0 。要避免浮点运算也很简单,我们用256表示1度(即8比特)。这样的话就可以精确到1/256=0.00390625度了,这对于大多数的情况都是足够精确的了。256表示1度,那么45度就是 45*256 = 115200。其他的度数以此类推。只取整数运算,避免了浮点运算。
第二部分运算量比较大的,也是程序员们比较关注的,一般三角函数计算坐标变换都是激光雷达厂家提供SDK的。
说到点云配准,就绕不开PCL库。PCL库源自ROS,即机器人操作系统,机器人系统经常用到激光雷达3D影像,为了减少重复开发,打通各个平台,ROS推出了PCL库。PCL(Point Cloud Library)是在吸收了前人点云相关研究基础上建立起来的大型跨平台开源C++编程库,它实现了大量点云相关的通用算法和高效数据结构,涉及到点云获取、滤波、分割、配准、检索、特征提取、识别、追踪、曲面重建、可视化等。支持多种操作系统平台,可在Windows、Linux、Android、MacOSX、部分嵌入式实时系统上运行。如果说OpenCV是2D信息获取与处理的结晶,那么PCL就在3D信息获取与处理上具有同等地位,PCL是BSD授权方式,可以免费进行商业和学术应用。其背后主要是慕尼黑大学(TUM - Technische Universität München)和斯坦福大学(Stanford University)。工业领域除了所有激光雷达厂家都支持PCL库外,丰田和本田也是PCL库的赞助者。
PCL库建立于2013年,那个时代,CPU是最主要的运算资源,因此PCL库针对CPU做了优化,PCL中的底层数据结构大量使用了SSE(可以看作是SIMID)优化。其大部分数学运算的实现是基于Eigen(一个开源的C++线性代数库)。此外,PCL还提供了对OpenMP和英特尔线程构建模块(TBB)库的支持,以实现多核并行化。快速最近邻搜索算法的主干是由FLANN提供(一个执行快速近似最近邻搜索的库)。PCL中的所有模块和算法均通过使用Boost共享指针的传递数据,因此避免重新复制系统中已经存在的数据。
点云配准最常用的两种方法一个是迭代最近点算法ICP (Iterative Closest Point),KD树可看做是ICP的高维版,一个是正态分布变换NDT (Normal Distribution Transform)。这两种算法自然都在PCL库里。英特尔则在2020年推出类似PCL库的Open3D开源库,不用说,自然也有对CPU的优化。
现在让我们再回到自动驾驶芯片,要应对不断增加分辨率的激光雷达,就要增强CPU算力,CPU的裸晶面积一般远小于GPU,这就意味着CPU性价比更高。考虑到芯片的设计周期与应用量产周期有2-3年,因此性能要尽可能地强大,同时为了保持足够的开放性,ARM架构是必须使用的。
图片来源:互联网
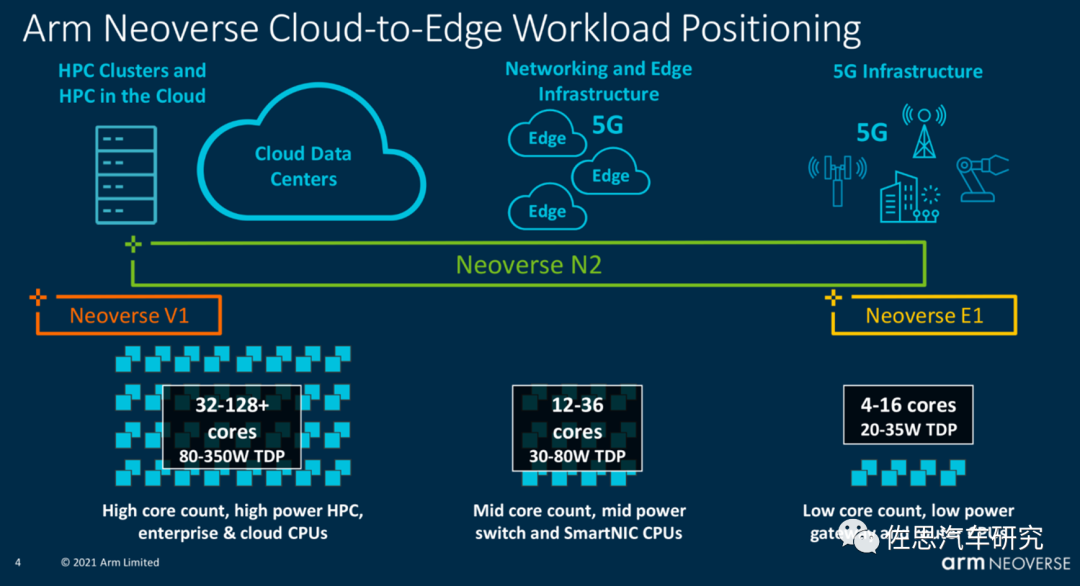
ARM在2019年3月针对服务器HPC市场推出Neoverse平台,按照计划最初是Ares,即希腊神话里的战神,2020年是Zeus,即希腊神话中的宙斯,2022年是Poseidon。V1是ARM目前算力最强的CPU架构。
图片来源:互联网
考虑到台积电的产能紧张,价格高昂,即便是特斯拉这样的知名客户,也被台积电拒之门外,因为特斯拉的量太低了,台积电的资源都给大客户了,小客户的排期遥遥无期。从性价比和供应链的角度,三星是唯一选择,三星产能充足,价格也远低于台积电,缺点是5纳米工艺不够成熟,因此只能选择7纳米的V1。
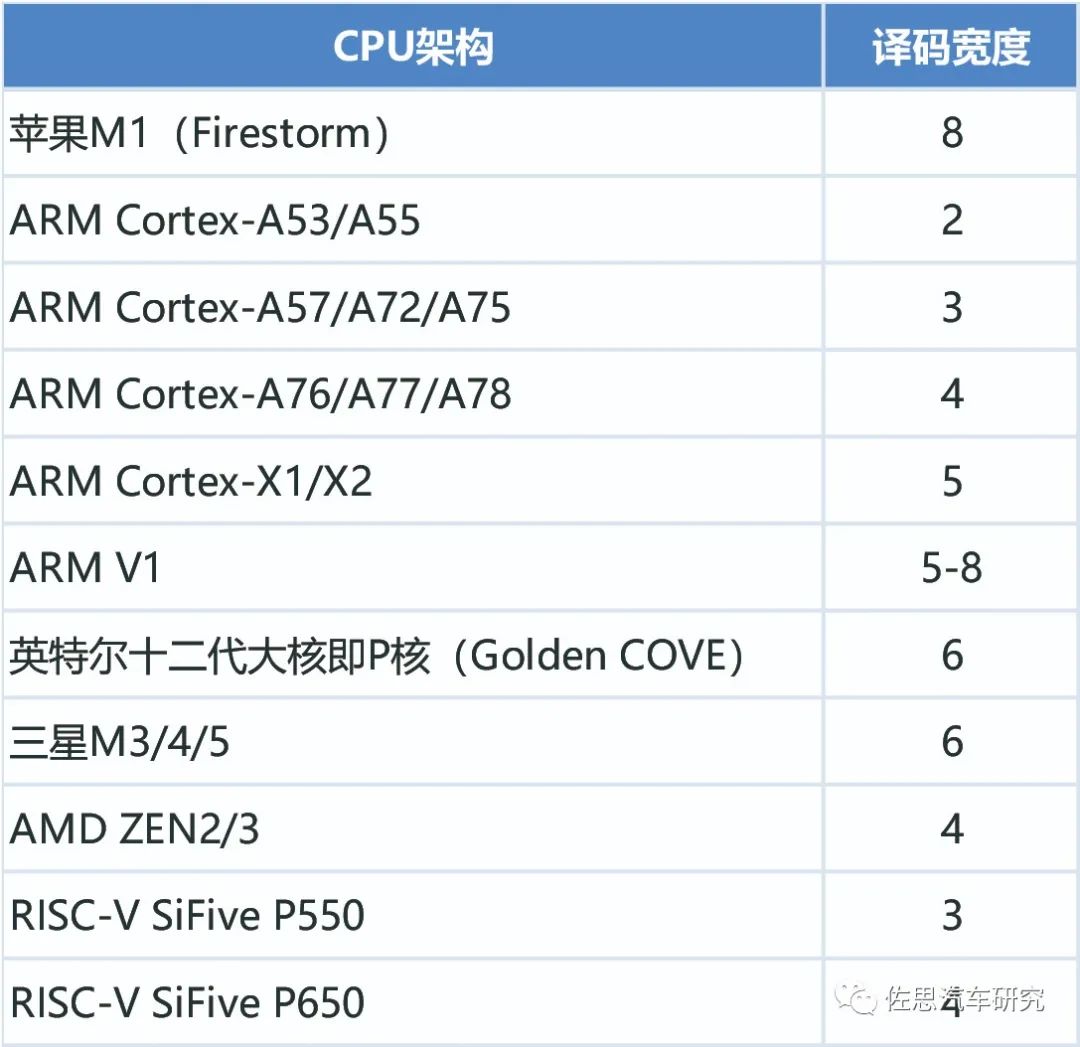
为什么说V1是最强的?
影响CPU算力最关键的参数是Decode Wide译码宽度,译码宽度可简单等同于每周期指令数量即IPC,即每个周期完成多少个指令。
图片来源:互联网
译码宽度的增加是非常困难的,不是想多少就多少的,简单来说每增加一位宽度,系统复杂度会提高15%左右,裸晶面积也就是成本会增加15-20%左右。如果简单地增加译码宽度,那么成本也会增加,厂家就缺乏更新的动力,所以ARM的做法是配合台积电和三星的先进工艺,利用晶体管密度的提升来减少裸晶面积降低成本,因此ARM的每一次译码宽度升级都需要先进制造工艺的配合,否则成本增加比较多。同时ARM也从商业角度考虑,每年小升级一次,年年都有提升空间。8位宽度是目前的极限,苹果一次到位使用8位宽度,缺点是必须使用台积电最先进的制造工艺。
此外,RISC和CISC还有区别,CISC增加宽度更难,但CISC的1位宽度基本可顶RISC的1.2-1.5位。英特尔是有实力压制苹果的,就是制造工艺不如台积电。CISC指令的长度不固定,RISC则是固定的。因为长度固定,可以分割为8个并行指令进入8个解码器,但CISC就不能,它不知道指令的长度。因此CISC的分支预测器比RISC要复杂很多,当然目前RISC也有长度可变的指令。遇到有些长指令,CISC可以一次完成,RISC因为长度固定,就像公交车站,一定要在某站停留一下,肯定不如CISC快。也就是说,RISC一定要跟指令集,操作系统做优化,RISC是以软件为核心,针对某些特定软件做的硬件,而CISC相反,他以硬件为核心,针对所有类型的软件开发的。
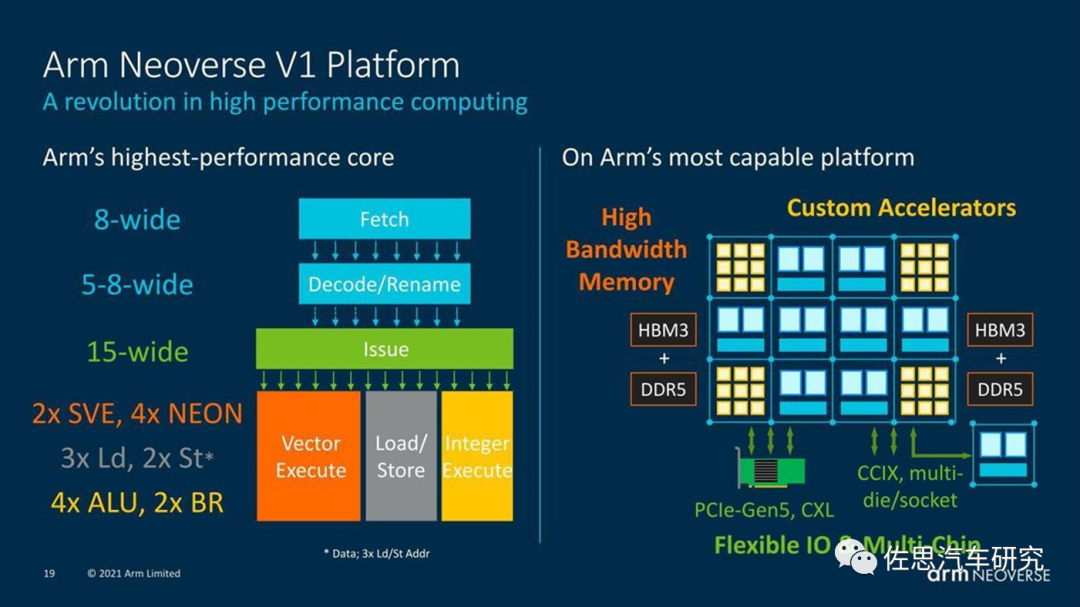
V1的宽度是可变的,最高8位
图片来源:互联网
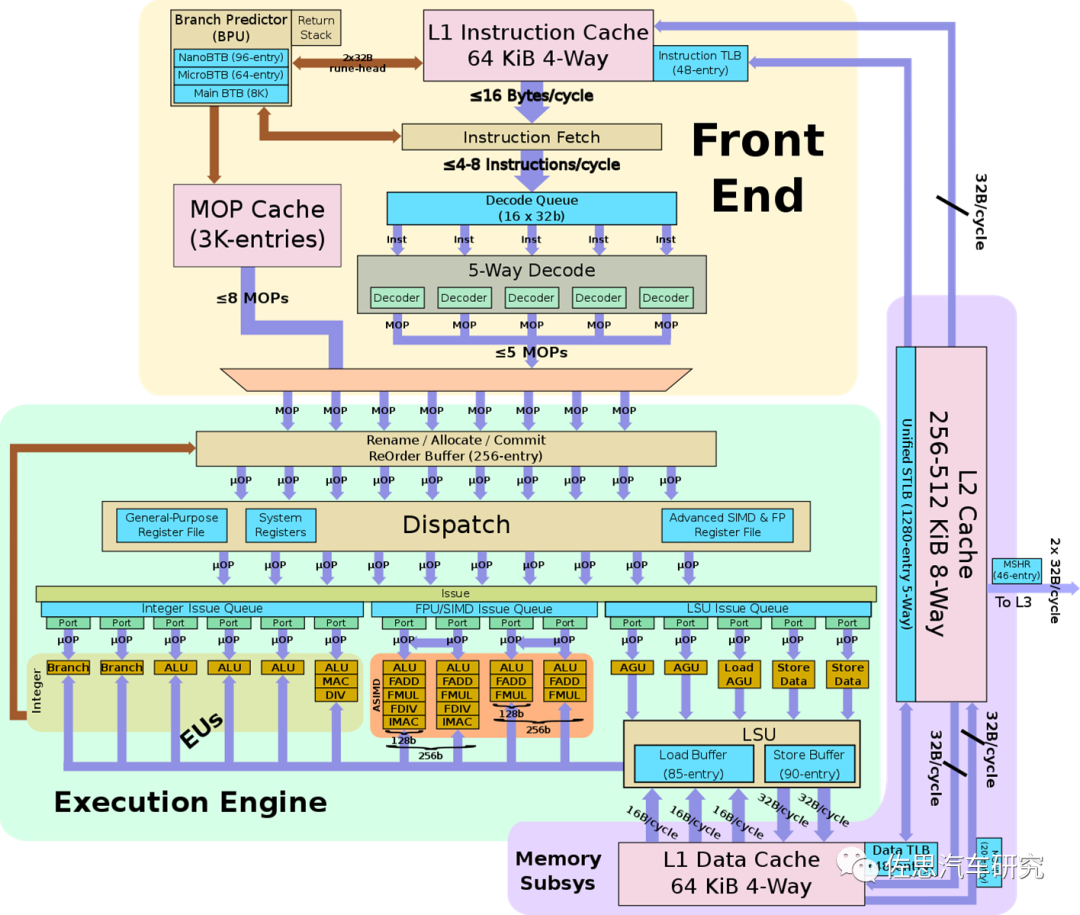
ARM Neoverse V1的微架构
图片来源:互联网
除了译码宽度,后端的分布和发射(Dispatch与Issue)宽度和ALU也要跟得上,否则前端很忙,后端很闲,也是没用,通常提升方法是增加发射宽度。分布方面,ARM Cortex-A77是10位,V1是10位,苹果M1的大核Firestorm据说是13位,三星猫鼬M4/M5是12位。不过V1的发射单元比较多,有15位。后端的运算单元ALU也比较多,有8个,4个整数,4个浮点或SIMD。
图片来源:互联网
V1是针对HPC开发的,推荐32核以上配置,但车载肯定不能这样做,功耗太高,12核V1足够,算力基本上能与16核的ARM Cortex-A78AE相当,甚至还要更高。浮点运算也不弱。
图片来源:互联网
Neoverse V1的机器学习性能和浮点运算性能也很强。

图片来源:互联网
机器学习性能,V1是N1的4倍,浮点运算性能是N1的2倍,典型的N1是华为的鲲鹏系列服务器CPU,也就是华为称之为泰山V110内核。
ARM最近引入2代SVE,NEON指令集是ARM64架构的单指令多数据流(SIMD)的标准实现。SVE(可扩展矢量指令Scalable Vector Extension)是针对高性能计算(HPC)和机器学习等领域开发的一套全新的矢量指令集,它是下一代SIMD指令集实现,而不是NEON指令集的简单扩展。SVE指令集中有很多概念与NEON指令集类似,例如矢量、通道、数据元素等。SVE指令集也提出了一个全新的概念:可变矢量长度编程模型(VectorLength Agnostic,VLA)。
传统的SIMD指令集采用固定大小的向量寄存器,例如NEON指令集采用固定的128位长度的矢量寄存器。而支持VLA编程模型的SVE指令集则支持可变长度的矢量寄存器。这样允许芯片设计者根据负载和成本来选择一个合适的矢量长度。SVE指令集的矢量寄存器的长度最小支持128位,最大可以支持2048位,以128位为增量。SVE设计确保同一个应用程序可以在支持不同矢量长度的SVE指令机器上运行,而不需要重新编译代码,这是VLA编程模型的精髓。
SVE指令集是在A64指令集的基础上新增的一组指令集,而SVE2是在ARMv9架构上发布的,它是SVE指令集的一个超集和扩充。SVE指令集包含了几百条指令,它们可以分成如下几大类:加载存储指令以及预取指令,向量移动指令,整数运算指令,位操作指令,浮点数运算指令,预测操作指令,数据元素操作指令。
简单地说,针对8位精度,如果SVE用理想状态下的2048位指令,那么相当于同时256个核并行计算,如果是16位精度就是128核。如果处理器有12核,那么做深度学习时可近似为256*12=3072个核心运行,与GPU相差无几。当然如此宽的数据操作编译器自动矢量化无能为力,为难开发者手动汇编也不好做。并且需要足够的缓存和寄存器数量来配合,成本会暴增。不过256或512位还是问题不大,英特尔的AVX512指令就是如此。一般推理用的就是8位整数精度,512位就是近似64核。简单算一下,假设是512位宽,12核心,那么就是64*12=768个核心,运行频率2GHz,理想状态下就是768*2=1526GOPs的算力。
选择CPU后就是选择GPU。GPU实际上就是针对并行数据的浮点运算器,也就是针对计算机视觉的,激光雷达的大量使用有助于降低对视觉的依赖,而计算机视觉是最耗费浮点算力的,激光雷达的大量使用是未来可以确定的事实,加上GPU最耗费成本,且很难做得过英伟达,因此不需要太高。
选择ARM的MALI G710,16核配置650MHz下可以获得1174GFLOPS的算力。
G710可能是ARM最成功的GPU架构。
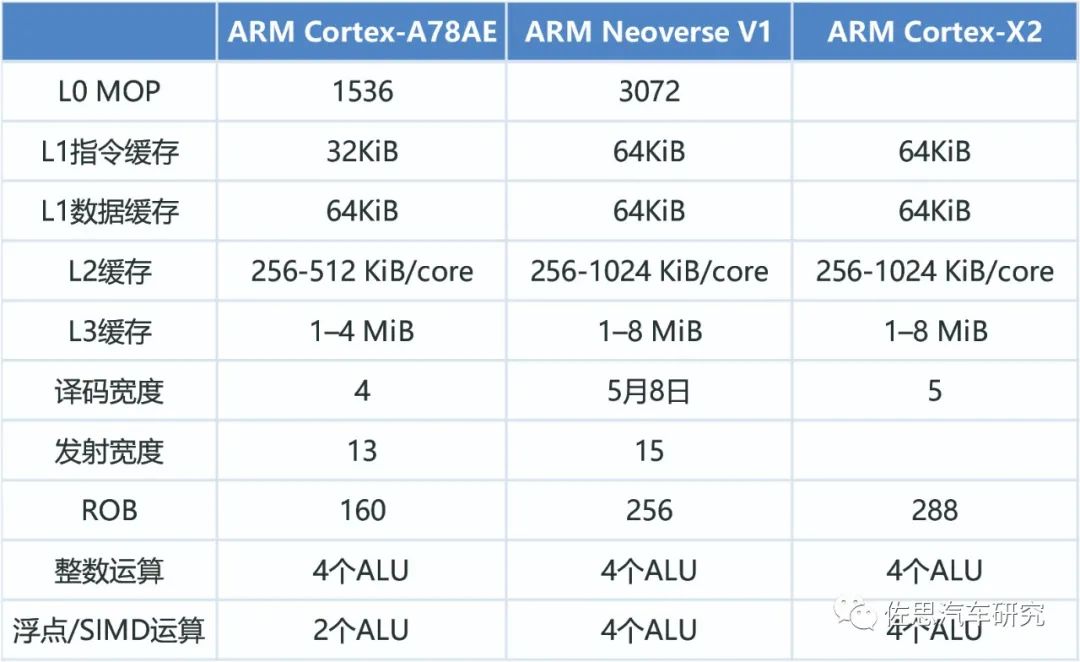
与英伟达桌面级GPU比,ARM的架构差异比较大。ARM采用大核设计,一般写为MALI G710 MPX或MCX,X代表核心数,MALI的核心就是渲染核即Shader Core,可以近似于英伟达的SM流多处理器。渲染核里有执行引擎,可以算是CPU领域的ALU。
MALI G710渲染核
图片来源:互联网
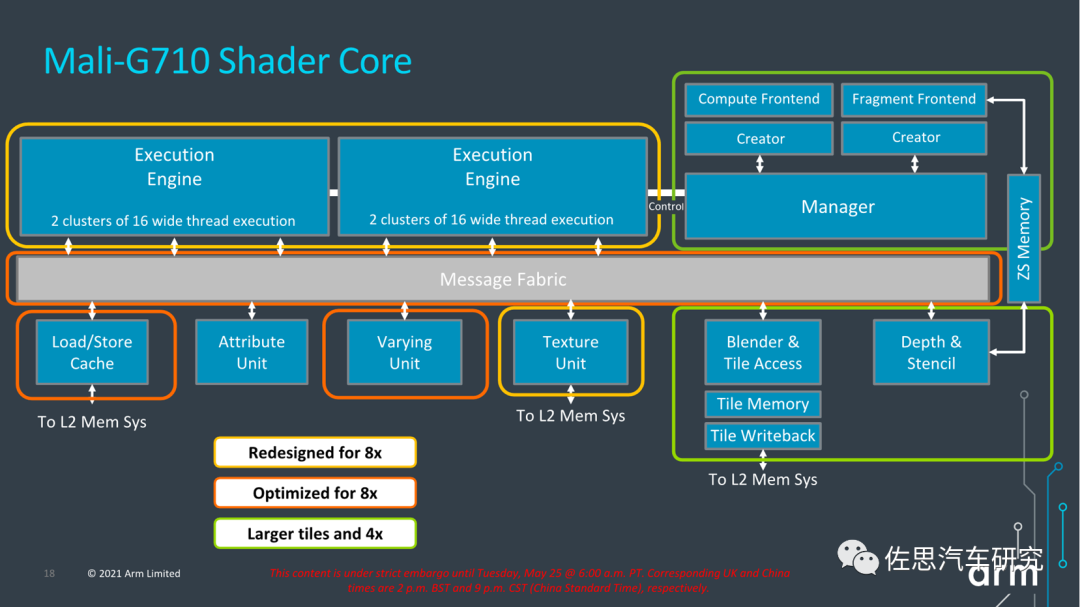
早期ARM是SIMD设计,近期变为GPU常用的SIMT。G710的执行引擎比G77翻倍,有两个执行引擎,每个执行引擎包含两个簇,执行16位宽的线程,等于是64个ALU,G710支持7-16核设计,也就是最高1024个ALU。
MALIG710执行引擎
图片来源:互联网
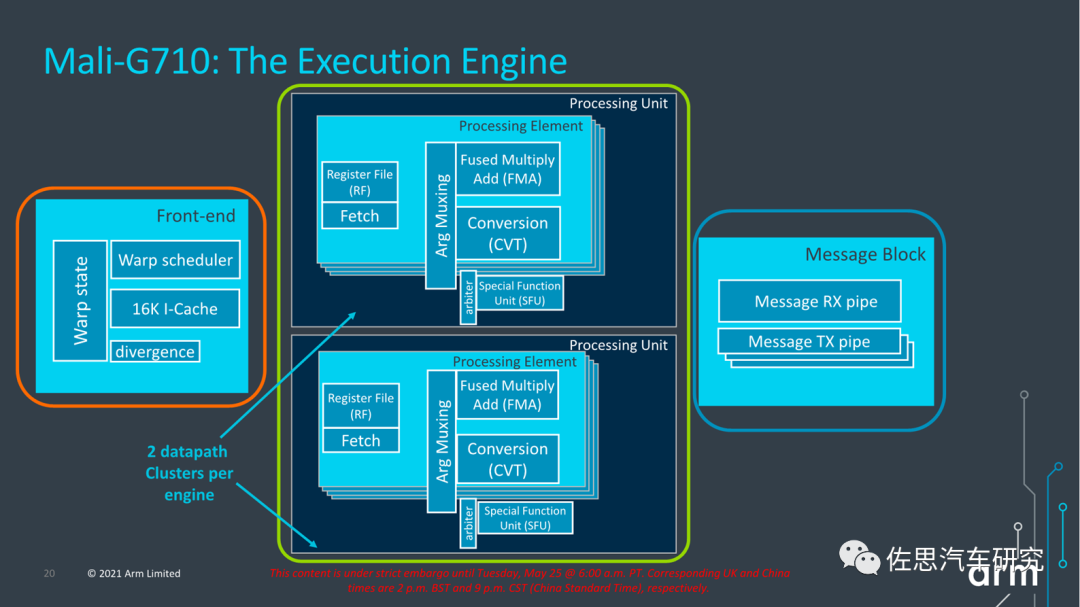
G710的执行核,前端没有透露具体信息,应该和G77一样,是64个warp或1024个线程。每个处理单元都有三个ALU:FMA(混合的乘积累加计算)和CVT(Convert)单元是16-wide,而SFU(特殊功能单元)是4-wide。每个FMA每周期可以做16次运算,运算数据精度为FP32,换成FP16就是32次,8位整数INT8就是64次,像英伟达的桌面级GPU,FP16和FP32是分开计算的,也就是说可以同时计算,但移动级的MALI不需要这样设计。Convert单元处理基本整数操作和自然类型转换操作,并充当分支端口。
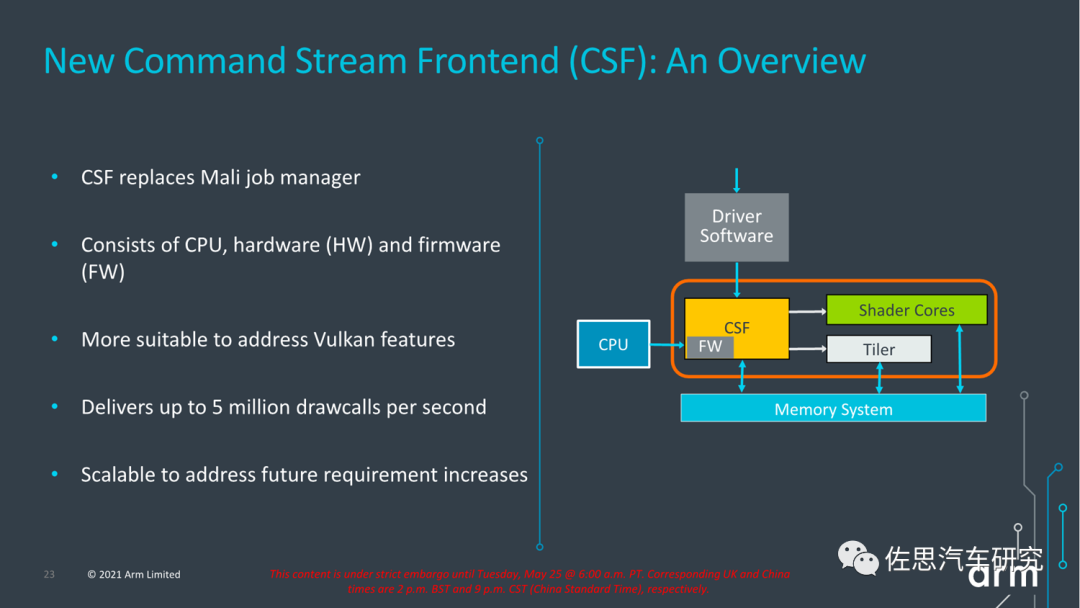
ARMMALI GPU CSF
图片来源:互联网
G710最大的变化,添加了CSF。G710首次把Mali的jobmanager换成了所谓的Command Stream Frontend。这个CSF负责处理调度和draw call,CSF这个模块由CPU、HW和固件构成。Arm表示,HW本身是全新设计的;而固件层的引入,能够针对一些比较复杂的图形负载提供更具弹性的性能,而且能够减少驱动开销、提升效率;对诸如Vulkan等API提供更简捷的支持等。固件处理来自host的请求和通知,负责硬件资源调度,减少诸如protected mode进出的开销,还能通过指令模拟来提供硬件原本不具备的特性。
ARM MALI系列GPU最被人诟病的就是draw call开销太大,实际性能与理论性能差别很大,特别是玩3D游戏时,此时CPU和GPU都很费资源,CPU优先处理内部需求,对于GPU的draw call处理不够及时,导致帧率下降。
接下来是AI加速器,计算机视觉依赖AI加速器,但激光雷达不需要太多AI加速。传统AI加速器靠堆砌MAC数量,数量越多,理论算力越强,非常简单粗暴,缺点是成本高,效率低。特别是效率低下,虽然理论算力数字非常漂亮,做到几百TOPS很容易,但实际使用中,内存墙的瓶颈,算力会大打折扣,还有算法模型的适配性,有时候只有理论算力的10%,而车载芯片受限于成本,又不可能使用高带宽HBM内存。
典型的AI加速器其核心是基于流水线的指令并行,即当前处理单元的结果不写回缓存,而直接作为下一级处理单元的输入,取代了当前处理单元结果回写和下一处理单元数据读取的存储器访问。这就是所谓脉动阵列,基本上AI加速器都是如此。这实际上两维的超宽SIMD,一个横向,一个纵向,2个维度最大化复用数据,从上传下PE(计算单元)间复用权重和partial sum,从左到左传PE间复用输入特征图。从相邻PE拿数据,前后门传一下就行,不需要去共享大型SRAM取数据,省掉大量寻址逻辑,数据能耗更低。控制逻辑艰难,布线简单,裸晶面积小,功耗低,频率可以做到2-3GHz,同时架构易扩展,常见的有4096和8192两种。有些如华为和英伟达,做成了3维,实际和2维度相差不大,最后那一维是前两维的延伸,本质上还是两维。
这种架构的缺点就是除非数据完全符合脉动阵列的规模,否则延迟明显,如TPU的256x256脉动阵列,当遇到FC层输入输出节点少、1x1的卷积核等情况,还是要空转256个周期才能有第一个计算结果,效率急速降低,解决办法很简单,软硬一体,确保让阵列都能满负荷运转。不过嘛,这就彻底封闭了,等于把灵魂都给芯片厂家了。
卷积的运算也有两种,一种是脉动阵列最合适的矩阵乘加累积,另一种是滑动窗口,转换成矩阵乘的好处之一就是方便支持各种奇奇怪怪的卷积,在转换阶段就做了dialation扩张、stride步长、deform变形、pad、非对称卷积核等处理,但会多几个数据转换和额外的内存读写。直接滑窗可能不需要变形和额外内存读写,但优化起来卷积方式相对受限,如果在卷积阶段调整步长或dialation等逻辑,会引起流水线中断,降低效率。不过似乎可以用VLIW指令做对应约束。
除此之外,AI加速器还是标准的冯诺依曼架构,数据和程序指令共用一个总线,虽然可以分开存储,像今天大多数CPU的L1缓存都是指令和数据分开存储,但寻址总线还是共用的,仍然是标准的冯诺依曼架构,这在AI加速器上非常不合适,AI加速器有着天量的数据存取,消耗大量时间,产生大量功耗,即便是脉动阵列数据大量复用,但是指令和数据还是共用总线,数据还是要频繁地读出和写入,这就是存储墙问题。解决办法有多种,一种是增加SRAM容量,SRAM速度最快,还在Die内部,物理距离最近,但成本会暴增,除了训练用,推理阶段绝对不会有人用。HBM退而求其次的办法,是一种解决办法,HBM带宽高,容量远大于SRAM,且与计算单元物理距离很近,在每次计算的两个值中,一个是权值Weight,一个是输入Activation。如果有足够大的片上缓存,结合适当的位宽压缩方法,将所有Weight都缓存在片上,每次仅输入Activation,就可以在优化数据复用之前就将带宽减半。不过HBM必须用3D封装或者说Chiplet,基本上就只有台积电一家能做,且价格高昂,车载芯片用不起。未来如果持续缩小权重模型,使用HBM量降低,或许会出现车载的HBM。
最合适的解决办法是哈佛架构,哈佛架构可以一定程度上减少存储墙的问题,它的指令和数据是不同的总线,读取指令同时也可以读取数据,没有等待的间隙。DSP是典型的哈佛架构。缺点是通常要配合VLIW,编译器写起来很麻烦,再有就是DSP无法做到多核,算力难以大幅度提升。
本文这款芯片更多考虑性价比、高效率以及对激光雷达的支持,因此不需要太高的AI算力,选择CEVA的NeuPro M。用于车载AI加速的DSP IP供应商不少,如新思科技的DesignWare ARC处理器系列,Cadence的Tensilica Vision Q7,VeriSilicon(芯原微电子)的Vivante Vision IP,Imagination的NNA。DSPIP最大的还是CEVA,并且第一大汽车逻辑芯片厂家瑞萨在其下一代自动驾驶SoC中就有采用CEVA的DSP IP,极有可能就是NeuProM。

图片来源:互联网
2022年1月初CES大展期间,CEVA推出第三代AI加速器IP,即NeuPro-M,最高算力达1200TOPS,且每瓦就可达到24TOPS算力,效率大约是高通AI100的2倍,英伟达Orin的2.5倍,特斯拉FSD的4-5倍。
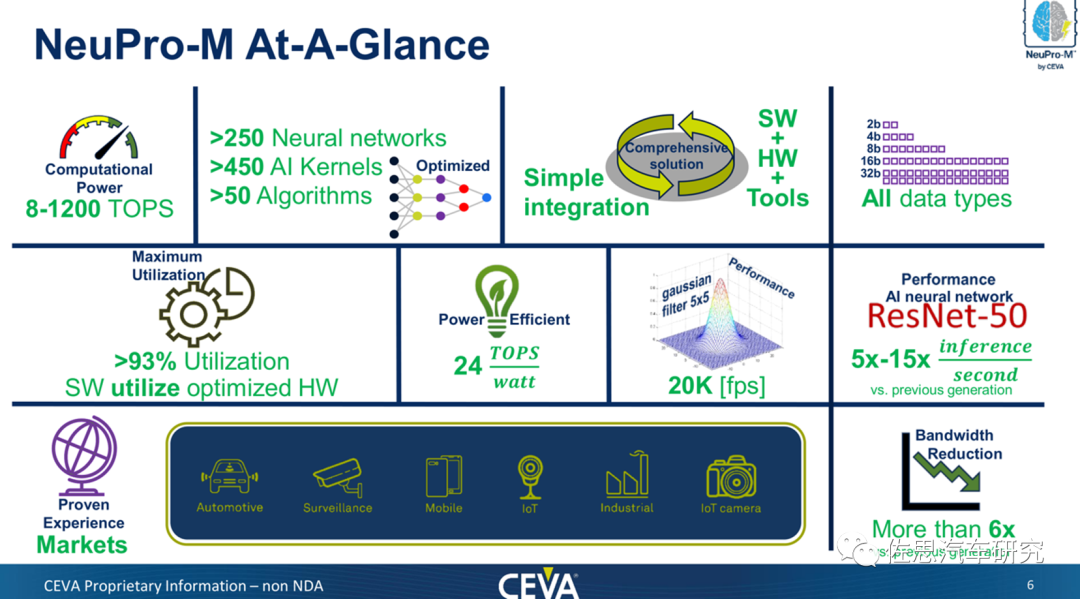
图片来源:互联网
针对汽车市场,CEVA提供NeuPro-M内核及其CEVA深度神经网络 (CDNN)深度学习编译器和软件工具包,不仅符合汽车ISO26262 ASIL-B功能安全标准,并满足严格的质量保证标准IATF16949和 ASPICE要求。
NeuPro-M内部框架图
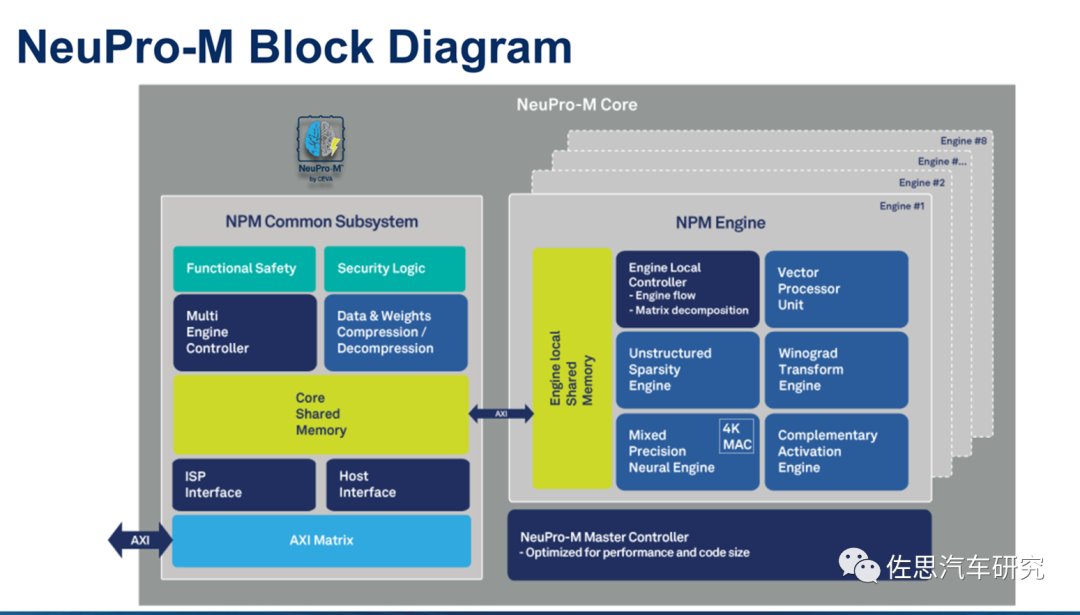
图片来源:互联网
第二代产品NeuPro-S的框架图
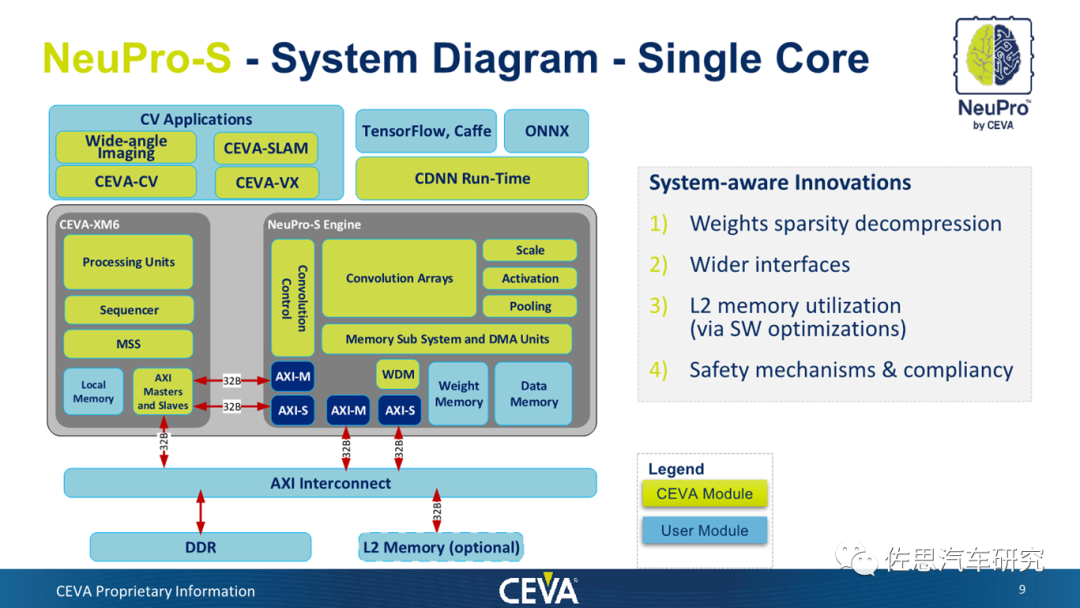
图片来源:互联网
上图为第二代产品NeuPro-S的框架图,其实际是CEVA-XM6 DSP与NeuPro-S引擎的复合体,虽然NeuPro-M内部框架图未再提及XM6,但看AXI主从分布,XM6应该只是换了个名字叫NPM Common子系统。NeuPro-S引擎有点类似于一个脉动阵列的AI加速器,以NeuPro-S 4000拥有4096个整数8比特精度MAC单元,上图为其单核框架图。NeuPro-M也是4096个MAC,不过精度从2位整数到16位浮点都有。NeuPro-M 架构中创新功能,同时使用 Winograd变换正交机制、Sparsity引擎和低分辨率 4x4位激活,可将网络(如Resnet50和YoloV3)的循环次数减少三倍以上。
XM6的内部框架
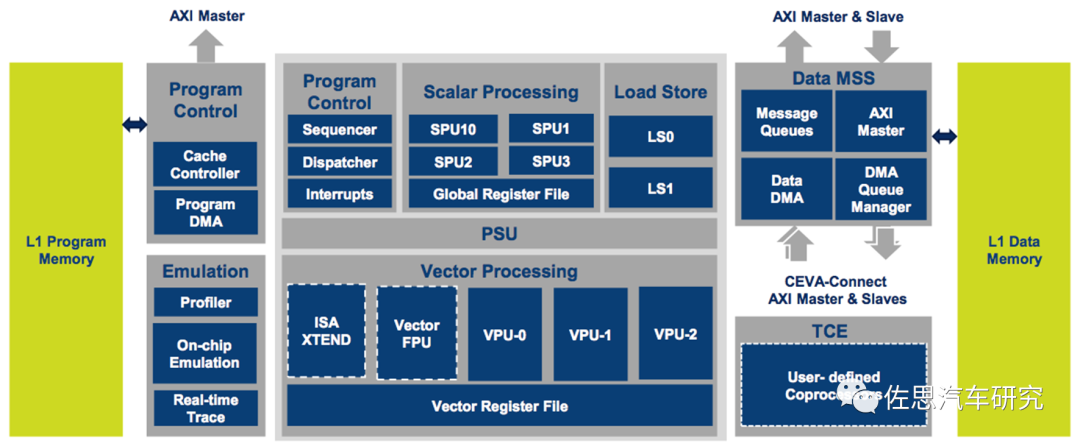
图片来源:互联网
NeuPro–M系列处理器初始包含以下预配置内核:• NPM11 –单个NeuPro-M引擎,在 1.25GHz下算力高达20 TOPS,• NPM18 – 8 个NeuPro-M 引擎,在1.25GHz下算力高达160 TOPS,这里的TOPS对应都应该是8比特整数位精度。估计制造工艺是7纳米,5纳米运行频率可以再提高,本设计中用单核NPM11就足够,功耗低于1瓦,也更容易过车规,成本也比较低。
子系统不多,特别是AI加速器只是单核,因此片上网络NoC也可以不用,总线就足够,ARM的CMN700就够用。
设计一款性能足以挑战英伟达Orin和Mobileye EyeQ6H的芯片不是什么难事,最大的问题是资金从哪来,供应链如何确保。至于配套的软件部分,只要舍得花钱招人,不是什么难事。









