绑定手机号
确认绑定









智猩猩公开课出品
策划:华严
理解三维场景是智能体的一项基础能力。但对于具身智能体而言,在复杂三维环境中进行推理仍颇具挑战,需要在开放空间中导航、理解复杂的空间关系,以及应对信息不完整(部分可观测)的问题。这些挑战要求模型具有任务分解和逐步推理的能力,而现有研究在该方面还比较匮乏。
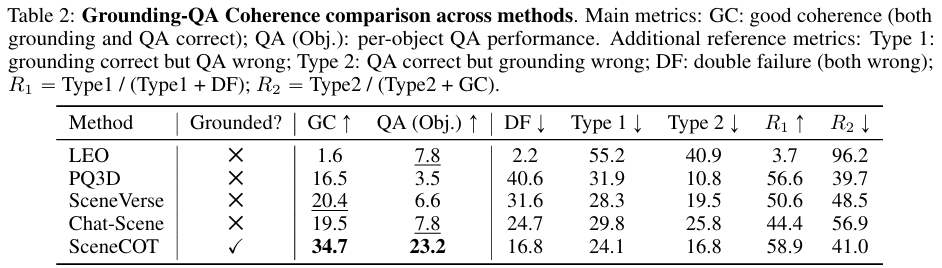
当前的3D视觉语言模型常常能生成看似合理的答案,却未能将这些答案grounding到场景中,导致grounding与QA的连贯性较差。模型可以流畅地回答,但回答所依据的视觉证据是什么、推理步骤如何展开,完全是黑箱。
为此,北京通用人工智能研究院联合北京大学、清华大学提出了一种用于三维场景中逐步grounding推理的创新框架SceneCOT。该框架通过模拟人类对复杂三维空间的思维链(CoT)过程,实现了极强的定位性能与逻辑一致性 。与SceneCOT相关论文成果收录于ICLR 2026。

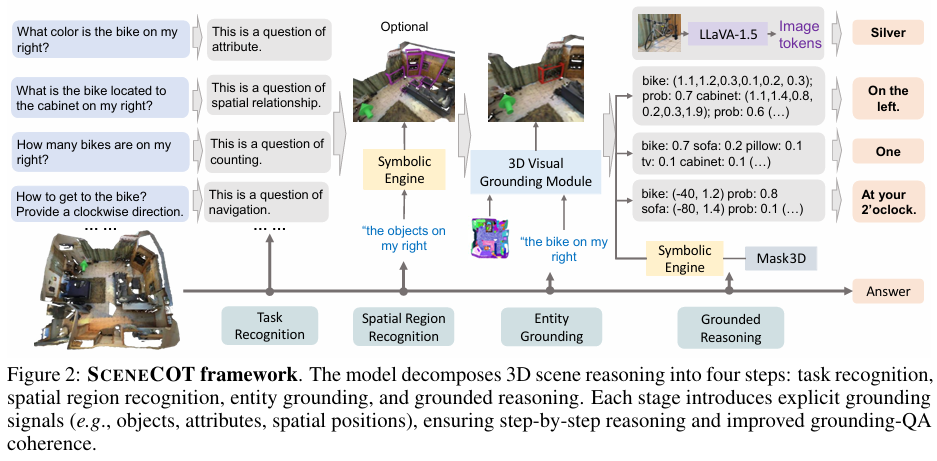
SceneCOT将复杂的三维推理任务拆解定义为3D-CoT,3D-CoT推理轨迹包含四个标准步骤:
1.任务识别与分析;
2.任务相关区域定位;
3.利用多模态专家模块进行grounding;
4.将中间结果整合为连贯答案,完成grounding推理。
这种分层阶段能够流确保每个答案都有清晰的grounding步骤作为支撑,确保了最终回答的准确性与可行性,实现了拟人的、可解释的、grounding推理。MSQA 数据集中一个情境化问答任务的示例推理轨迹的完整流程如图1所示。

图2说明了SceneCOT如何利用3D-CoT进行学习和推理。SceneCOT的核心构建于一个强大的MLLM之上,作为主要的推理引擎;还整合了专用 3D-VL 和 2D-VL 模型,符号引擎这两类模块化组件。
为了支撑SceneCOT的学习,该团队构建了首个用于三维推理的大规模接地式思维链数据集SceneCOT-185K,涵盖超过18.5万条高质量推理轨迹,用于支持三维场景中的逐步推理。
该数据集涵盖三维场景推理中的情境化推理和物体中心推理两类代表性任务。通过两步流程构建数据集:元数据收集和推理轨迹生成。
实验结果表明,SceneCOT不仅在情境化推理基准上达到了很强的性能,在Beacon3D基准上也表现突出:与其他以物体为中心基线方法相比,SceneCOT显著提升了grounding-QA之间的一致性。除了准确率的提升,SceneCOT所生成的可解释推理轨迹还使模型的决策过程变得透明可解释。
3月24日19点,「2026智猩猩公开课Live」第4期将开讲,由SceneCOT一作令狐雄坤主讲,主题为《构建具身三维场景理解的可解释性链式推理框架》。

令狐雄坤老师将以SceneCOT为核心,并从测评、模型架构、算法等多个角度展开,系统性地介绍在具身三维场景理解领域的系列工作。
首先,令狐雄坤老师将介绍大规模具身三维场景理解数据集MSR3D,为大模型训练提供高质量、规模化的多模态数据支撑。其次,将解析新基准Beacon3D,该工作首次引入“定位-推理一致性”指标,为开发可解释推理模型提供了明确指引 。接着,会重点介绍SceneCOT推理框架。最后,会分享最新研究3D-RFT,探讨如何利用强化学习进一步优化基于视频的三维场景理解能力。
第 4 期信息
主 题
《构建具身三维场景理解的可解释性链式推理框架》
提 纲
1、大规模具身三维场景理解数据集MSR3D
2、三维场景理解测试基准Beacon3D
3、可解释三维场景推理框架SceneCOT
4、基于强化学习的视频三维场景理解3D-RFT
主 讲 人 :令狐雄坤,硕士毕业于清华大学,毕业后任职于北京通用人工智能研究院,担任高级研究工程师。主要研究方向为多模态大模型、三维场景理解、通用具身智能体,在NeurIPS、ICML、ICLR等顶级会议上发表多篇一作/共一论文, 担任多个顶会审稿人。
直 播 时 间
3月24日19:00
成 果
论文1
标题:SceneCOT: Eliciting Grounded Chain-of-Thought Reasoning in 3D Scenes
主页:https://scenecot.github.io/
收录情况:ICLR 2026
论文2
标题:Multi-modal situated reasoning in 3d scenes
主页:https://msr3d.github.io/
收录情况:NeurIPS 2024
论文3
标题:Unveiling the mist over 3d vision-language understanding: Object-centric evaluation with chain-of-analysis
链接:https://arxiv.org/abs/2503.22420
收录情况:CVPR 2025
论文4
标题:3D-RFT: Reinforcement Fine-Tuning for Video-based 3D Scene Understanding
主页:https://3d-rft.github.io/
如何观看和学习
主讲人将于3月24日19点进行实时视频讲解和答疑互动,扫描或长按下方二维码,即可进入学习交流室,观看和学习本次公开课。
🎁邀请有礼:进入公开课学习交流室点击参加【邀请有礼活动】,可获得【精美礼品一份】。数量有限,先到先得!参与方式👇👇👇










