绑定手机号
确认绑定









过去的几年间,中国芯片产业迎来史无前例的投资热潮,资金和人才的大量涌入,一定程度上促进了半导体产业的迅速发展,尤其是在国家大力发展数字经济的背景下,人工智能、云计算、大数据、元宇宙等新兴前沿领域蓬勃发展,促生了大批本土GPU/CPU/AI等芯片设计创业公司,一时间可谓千帆竞发,百舸争流。但繁荣景象的背后也不免令人担忧,很多人思虑芯片行业是不是过热?或者审视我们需要再做些什么?又或者好奇接下来会发生什么?本文将为大家梳理回顾芯片行业的发展历程,特别是计算芯片的迭代和演进,以过去为镜,希望能给芯片产业特别是GPU芯片的未来发展带来一些借鉴和更深入的思考。
目录
01 蓄势待发阶段
02 小计算存储时代
03 中计算CPU时代
04 大计算GPU时代
05 小结和思考
蓄势待发阶段
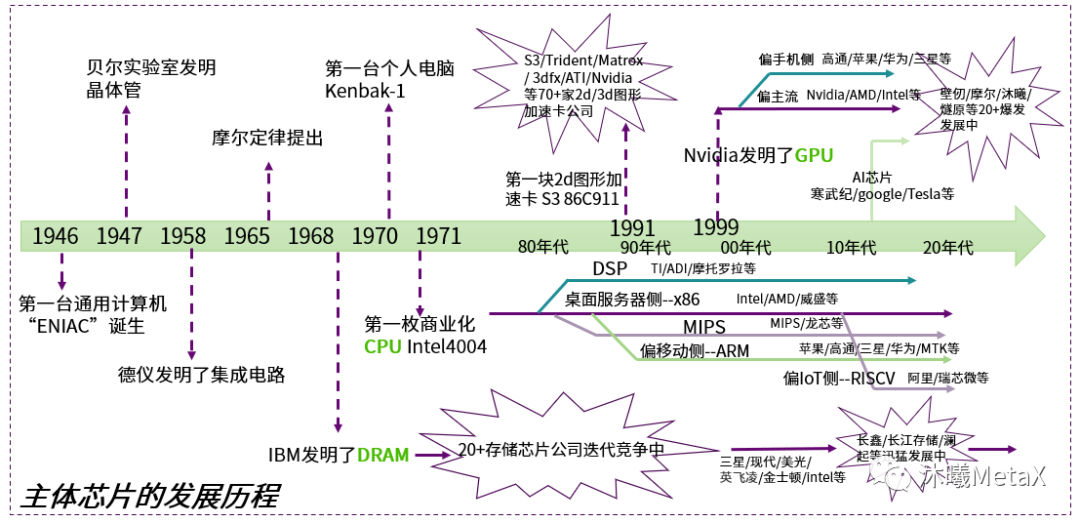
图1:主体芯片的发展历程
1833年,科学家迈克尔·法拉第发现了硫化银的电阻随着温度上升而降低的特异现象(电阻效应),揭开了半导体芯片发现、研究、迭代等一系列波澜壮阔的发展历程(图1)。
首先,科学家发现能够制造芯片的半导体材料(包括二氧化硅)有以下四个重要的特性:
电阻效应:如上文所提到,1833年由英国科学家迈克尔·法拉第发现。
光伏效应:1839年,法国科学家埃德蒙·贝克雷尔发现半导体和电解质接触形成的结,在光照下会产生一个电压,这就是后来人们熟知的光生伏特效应。
光电导效应:1873年,英国的威洛比·史密斯发现硒晶体材料在光照下电导增加的光电导效应。
整流效应:1874年,德国物理学家费迪南德·布劳恩观察到某些硫化物的电导与所加电场的方向有关。在它两端加一个正向电压,它是导通的;如果把电压极性反过来,它就不导电,这就是半导体的整流效应。
虽然半导体的这四个重要效应在1880年以前就先后被科学家发现,但由于缺少系统性的总结和对应的重点突破,在此后的几十年,虽然半导体材料研究和应用断断续续有一些实践,但总体进程非常缓慢。直到1947年,美国贝尔实验室全面总结了半导体材料的上述四个特性,此后四价元素锗和硅成为了科学家最为关注和大力研究的半导体材料,相关的晶体管发明开始层出不穷。一些重要节点包括:
■ 1947年,贝尔实验室的巴丁等三人发明了点触型NPN锗晶体管。
■ 1950年,威廉姆·肖克莱制成第一个双极结型PN结型晶体管。至今,PN结型晶体管仍是主流结构。
■ 1952年,实用的结场效应晶体管被制造出来。结场效应晶体管(JFET)是一种用电场效应来控制电流的晶体管。
■ 1960年,二氧化硅双极性晶体管诞生。
在芯片制造端,需要把一定数量的其它物质掺加到半导体材料中,改变半导体材料的电学性能,早期主要有离子注入工艺和扩散工艺这两种掺杂方法:
离子注入:1950年,美国人拉塞尔·奥尔等发明了离子注入工艺。它将杂质电离成离子并聚焦成离子束,在电场中加速后注入到半导体材料中去,实现对硅材料的掺杂,主要用于形成较浅的半导体结。
扩散:1956年,美国人富勒发明了扩散工艺。它将掺杂的原子气体注入到半导体材料中,用于形成较深的半导体结。
在芯片的上游需求侧,1946年第一台通用计算机ENIAC在美国宣告诞生。它采用17,468根电子管,7,200根晶体二极管和10,000个电容器等元器件等,占地170平方米。整个设计构建了现代通用计算器的原型,可用来解决通用问题。在性能方面,每秒能运行5000次加法或400次乘法进行线性方程组的求解,使得原来需要20多分钟时间才能计算出来的一条弹道,现在只要短短的30秒,一下子缓解了当时极为严重的计算速度远远落后于实际需求的问题。
此外,在和晶体管呈现相关的集成侧,1958年,基尔比首次把晶体管、电阻和电容等20余个元件集成在不超过4平方毫米面积的平板上,通过热焊方式把元件用极细的导线相互连接。集成电路首次被发明了出来,开创了世界微电子学的历史。

图2:芯片发展的生态要素已经完备
至此,如图2所示,芯片制造的底层技术“半导体材料”和“制造工艺”已经就绪;芯片的呈现“集成电路”有了原型;芯片的使用前景“计算机”等也有了明确的方向,芯片的发展注入了内生的动力。从此,半导体材料的优化,芯片的集成度,制造工艺的演进等开始快速迭代起来。基于对迭代的观察分析和总结,1965年,英特尔前总裁戈登·摩尔在《电子学》技术期刊上发表了摩尔定律,指出:半导体芯片上集成的晶体管和电阻数量将每年翻一番。尽管这一技术进步的周期从最初预测的12个月延长到后期的近18个月,但“摩尔定律”在过去的近60年基本上很好地反应了芯片的发展过程,或者说很好地给芯片的集成迭代指明了目标和方向。
小计算存储时代
计算机芯片的核心部件是CPU芯片、GPU芯片和存储芯片。从功能的角度来看,存储芯片可以分为计算存储和数据存储两大类。相比于CPU和GPU,存储是更基本的问题,也是早期系统的瓶颈,因此,芯片的高速迭代发展最早发生在内存芯片领域。
回到1946,ENIAC被发明时还没有专门的存储设备,它是通过累加器等搭建实现的。到了1956,冯·诺依曼发明了EDVAC。它首次把计算和存储分离开来,奠定了现代计算机架构的基础。具体到存储方面,它采用了1024个能存储44bit的磁心存储器。五六十年代的计算机主要都是用这种磁心存储器。
1966年,美国RCA公司研制出CMOS集成电路和第一块50门的门阵列芯片。1967年,贝尔实验室江大原等发明了非挥发存储器。这是一种浮栅MOSFET,它是可擦除可编程只读存储器(EPROM)、电可擦除可编程只读存储器(EEPROM)、闪存(Flash)的基础。1968年,IBM公司的罗伯特·登纳德发明单晶体管动态随机存取存储器(DRAM)。单晶体管DRAM是一个划时代的发明,后来它逐渐成为了计算机内存的标准。
此后数十年,美国涌现出了一大批内存芯片公司,你追我赶从几十bit芯片迭代到了1M芯片。期间,一个明星代表企业Intel首次登上舞台并开始大放异彩。早期内存芯片发展的代表事件有:
■ 1969年,Intel发布了业界第一颗固态存储芯片Intel 3101,64-bit SRAM,也是Intel的第一个产品。
■ 1969年,Intel发布了第一颗MOS存储芯片Intel 1101,256-bit SRAM。
■ 1970年,Intel发布了第一颗DRAM存储芯片Intel 1103,1024-bit DRAM;这是一颗划时代的芯片,发布不久就被HP 9800系列电脑采用,是到1972年为止销量最好的芯片。从此,磁心存储器开始慢慢退出历史舞台。
■ 1971年,Intel发布了第一块EPROM存储芯片Intel 1702,2048-bit EPROM。
■ 1971年,德州仪器深入研究Intel 1103后,重新设计3T1C(3个晶体管和一个电容)结构,推出了2048-bit DRAM。
■ 1973 年,德州仪器采用1T1C结构推出了4K-bit DRAM,成本更低,成为Intel的强劲对手。
■ 1973 年,莫斯泰克(Mostek)发布了4K-bit DRAM芯片MK4096,引入行列地址复用索引技术,大幅降低了制造难度和成本。
■ 1975年,Intel发布了第一块16K-bit DRAM芯片Intel 2116。
■ 1976年,莫斯泰克发布了16K-bit DRAM芯片 MK4116,凭借更好的成本优势,性能以及可靠性,击败Intel成为最主流的16K DRAM芯片。
在70年代,大型机和游戏机等一些电子设备已经有了很大的市场,期间内存芯片竞争激烈,但主要为美国企业所占据。1974年,仅英特尔一家就占据全球82.9%的DRAM市场份额,到70年代后期,莫斯泰克占据了全球DRAM市场85%的份额。
也就在70年代中期,在美国政府的扶持下,日本企业一方面以低价引进了美国最新的晶体管和集成电路技术,另外一方面日本政府批准了“VLSI(超大规模集成电路)计划”,联合日立、NEC、富士通、三菱、东芝五大公司一起针对DRAM存储器发起大攻坚,并在短短数年后就取得了很不错的成果,包括:
■ 1980年,在惠普对16K DRAM内存的竞标中,日本的NEC、日立和富士通完胜美国的英特尔、德州仪器和莫斯泰克,美国质量最好的DRAM的不合格率比日本最差的公司还高6倍。
■ 1982年,日本成为全球最大的DRAM生产国。
■ 1985年,NEC登上全球半导体厂商收入榜首,并在之后连续7年稳坐头把交椅。
期间,被日本厂商压着打的英特尔关闭了7座工厂,裁员7200人,这家11年前市占率达80%的公司从此关闭了存储器业务。为莫斯泰克做内存芯片设计的镁光科技(Micron)被迫裁员一半,1400名工人失业。
不过,日本半导体的辉煌仅仅持续了十来年。一方面,美国通过反倾销诉讼不停打压日本;另一方面,韩国三星李健熙在日本深刻感受到了芯片市场的诱惑力,并在1983年建立了第一个半导体工厂,并得到了美国的大力支援,从16K DRAM起步,短短3年时间就一口气掌握了 16K 到 256K DRAM 的关键技术;再一方面韩国也借鉴日本的“官产学”模式,由韩国电子通信研究所(KIST)牵头,联合三星、 LG、现代与韩国六所大学,一起对 4M DRAM 进行技术攻关,该项目持续了三年,研发费用高达1.1 亿美元,其中韩国政府承担了 57%。
到了90年代,日本半导体产业开始节节败退,韩国成了新一代存储器霸主。1992年,三星将NEC挤下DRAM世界第一的宝座;2000年前后,富士通和东芝先后宣布从DRAM市场退出。
到2000年时,全球内存厂商的数量仍超过 20 家,但经过1999年的大整合, 2001 年尘埃落定时排名前四的企业:三星、美光、海力士和英飞凌,握有近八成的市场份额。而后由于2001年DRAM价格狂跌,海力士和韩国SK合资成立SK Hynix;英飞凌因2008年世界金融危机,不得已将内存部门拆分出去,其后也不了了之。世界DRAM大厂只留下韩国三星、SK海力士、美国美光,三者占比在2018年超过95%,基本垄断了整个DRAM市场。另外,在技术方面,内存芯片从DRAM向SDRAM和DDR2/3/4/5/6不停的迭代更新,容量越来越大(从几十M到几十G),频率越来越高(从几百M到几G);且芯片的布局从平面布局到3维的堆叠(HBM),目前已经实现176层的堆叠,存储密度越来越高。
可喜的一点是,过去几年慢慢出现了一些中国厂商,长江存储、合肥长鑫和澜起科技等开始在内存芯片领域紧追世界前沿。长江存储实现了128层堆叠,在2020年第三季度突破了1%的全球份额,成功成为全球第七大NAND闪存企业。
中计算CPU时代
3.1
X86的起源与发展
1969年夏,当整个芯片业界都将目标集中在存储芯片的时候,日本一家计算器制造商 Busicom想开发一种计算器,设计原型为可执行多种普通的数学运算,不同的待执行程序保存在不同的ROM中(最少需要12 块内存和逻辑芯片,每个芯片内部都包含数量异常多的引线),可以插入打印机或电子显示器内。
Busicom找到Intel来开发,Intel一开始并不重视这个芯片项目,把这个项目分配给一位名叫 Marcian Hoff的年轻工程师。Hoff 认为 Busicom 的设计过于复杂笨重,性价比不高,因此他想出了一个新颖的替代方案:相比于有很多块逻辑芯片和ROM各自负责一些计算编程能力,更好的设计是有个计算单元负责所有并且提供更通用的编程计算能力。随后,Hoff和其它工程师一起把12个芯片缩减为4个:一个256 Byte ROM,一个 32-bit RAM,一个 10 位移位寄存器和一个4-bit微处理器。微处理器是英特尔精简设计的关键。经过2年的努力,第一个进入市场的微处理器 4004 在1971年诞生了,它总共集成了2,300个 CMOS晶体管,每秒可以执行60,000次操作,对1,280个4bits数据进行寻址访问和读取4KB的程序指令。
Intel 4004芯片的诞生拉开了CPU芯片迭代升级的序幕,在接下来的10年,CPU芯片快速地从4-bit迭代到了32-bit,一些标志性的芯片产品包括:
1974年,Intel 8-bit CPU 8080发布,它是第一块真正意义上的通用微处理器芯片。芯片一经发布就成为工业界的标准,被其它公司广泛效仿甚至被抄袭。8080采用6微米工艺,芯片大小为0.165x0.191英寸,每秒可以进行2.5M次8-bit加法运算。正是由于这款芯片,使得Intel能够从内存芯片的竞争失败中成功转型,并且在1981年就拥有20,000名员工和7.88亿美元的收入。
1974年,美国国家半导体公司推出了第一个 16-bit微处理器PACE,但由于该芯片的制造工艺是由空穴掺杂的 MOS 晶体管制成,正离子在硅中的移动速度约为电子速度的三分之一;PACE完成一次操作需要大约百万分之一秒,大约是第一个电子掺杂 16 位微处理器所需时间的四倍,所以PACE在激烈的竞争中并没有优势,很快就过时了。
1975年,AMD发布了去中心化的位片处理器2901,基本单元是4-bit的位片微处理器。多个位片处理器可以组合或级联起来,譬如3个4-bit位片微处理器串联起来操作12-bit的数据。它们通常被串在一起构成32位操作系统。整个设计比较节能且有扩展性,但由于整体方案较复杂以及16/32-bit市场不大,并没有获得广泛使用。
1976年,Zilog发布了Z-80,它借鉴8080处理器,有着相同的基本架构和指令集,但它相比前者有了巨大的改进,除了内部电路,还集成了自己的时钟、系统控制器、动态内存刷新器等。它在许多机器中都取代了8080,包括个人电脑、智能打字机、医疗设备、飞机导航控制和视频游戏。
1979年,摩托罗拉发布了基于电子晶体管的16-bit微处理器68000,比第一款16位处理器PACE快很多,被广泛使用,包括当时最先进的计算机Radio Shack TRS-80。
1981年,惠普发布了世界上第一块32-bit CPU,集成了450,000个晶体管,每秒可以处理1.8M次32bit的乘法。它在惠普自己的HP9000计算机中使用。
也是在1981年,Intel的8088(16-bit CPU,16-bit内部总线和8-bit外部总线,时钟频率4.77MHz,地址总线20位,可使用1MB内存;3微米工艺)芯片研发成功,并应用在IBM PC机中,从此开创了全新的微机时代。也正是从8088开始,PC机(个人电脑)的概念开始在全世界范围内发展起来。
1982年,Intel推出了80286芯片,采用1.5微米工艺,虽然它仍旧是16位结构,但在CPU的内部集成了13.4万个晶体管,时钟频率由最初的6MHz逐步提高到20MHz。其内部和外部数据总线皆为16位,地址总线24位,可寻址16MB内存。80286也是应用比较广泛的一块CPU。IBM 采用80286 推出了AT 机并引起了轰动,使得以后的 PC 机不得不一直兼容于PC XT/AT。
1985年,Intel推出了80386芯片,它是x86系列中的第一种32位微处理器,而且制造工艺也有了很大的进步。80386内部内含27.5万个晶体管,时钟频率从12.5MHz发展到33MHz。80386的内部和外部数据总线都是32位,地址总线也是32位,可寻址高达4GB内存,可以运行Windows操作系统。但80386芯片并没有引起IBM 的足够重视,反而是康柏率先采用了它并快速发展壮大。也是从这时候开始,PC厂商正式走“兼容”道路,也是AMD 等 CPU 生产厂家走“兼容”道路的开始。32位CPU从此大规模流行开来。
1989年,80486横空出世,它采用1微米工艺,第一次使晶体管集成数量超过100万,达到了 120 万个。此外它的主体架构是把80386和数学协处理器80387以及一个8KB的高速缓存集成在一起,所以它在一个时钟周期内能执行 2 条指令。
1992年,区别于其它市场上的80486芯片,Intel发布了奔腾CPU(不再顺着起名80586)并注册了商标,采用0.8微米工艺,集成了3.1M个晶体管,CPU运行频率60/66MHz,MMX技术被首次引入。
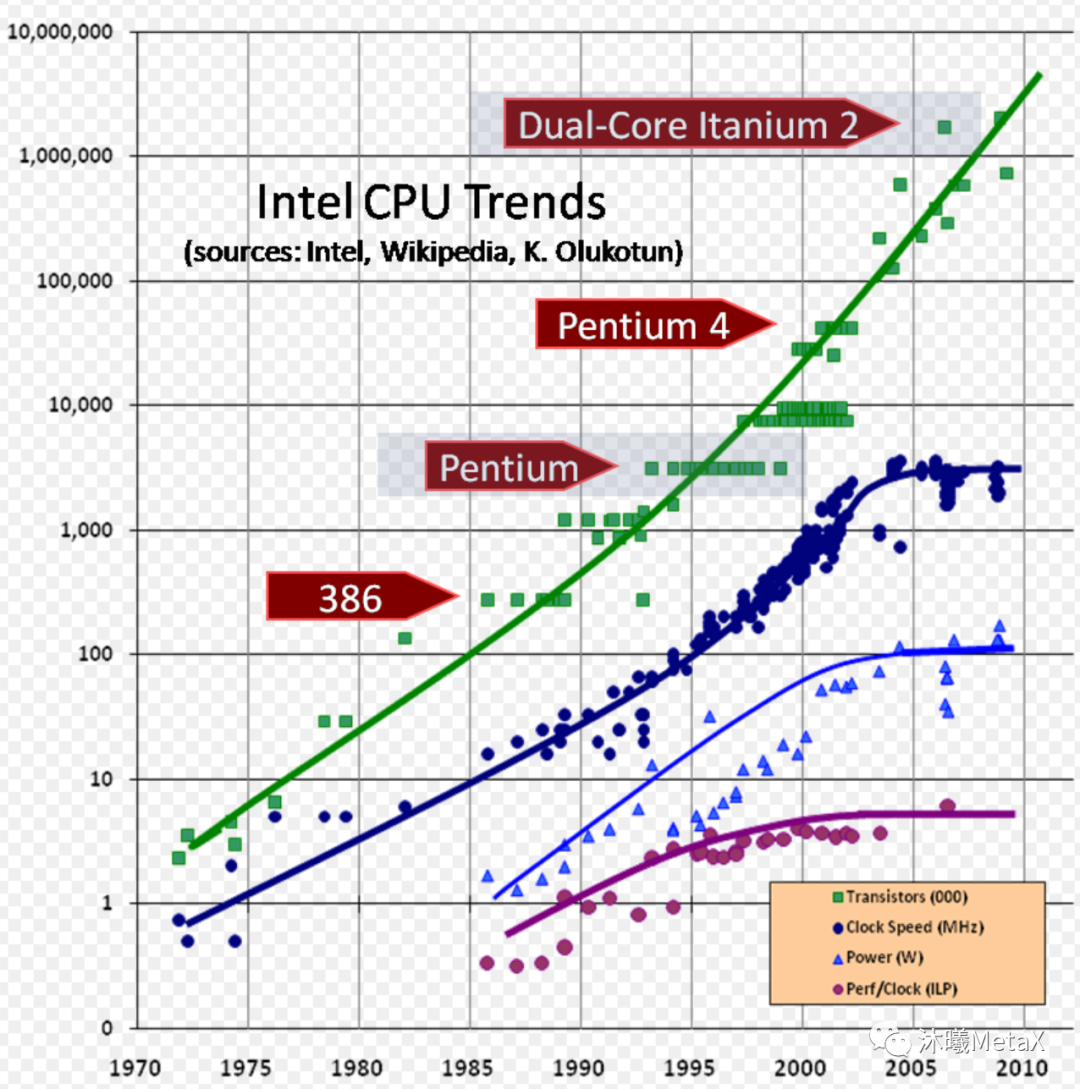
图3:Intel CPU在2010年前的迭代发展
https://en.wikipedia.org/wiki
CPU整体的大框架已然成型,在接下来的很长一段时间内,Intel CPU的演进方向比较明确,如图3所示:
■ 芯片集成度:晶体管数量每18个月翻一番。
■ CPU频率:从386的12.5MHz提升到奔腾的2.8GHz左右,此后缓慢增长。
■ Perf/Clock(ILP):表征架构综合性能的每时钟性能从386的0.5提升到了6左右,此后缓慢增长。
图4展示了上世纪90年代主要CPU厂商及对应产品的芯片频率,由于都是基于32-bit的总线和计算单元,很大的一个性能提升维度就是芯片的频率。

图4:90年代主要CPU厂商的产品和频率迭代趋势
https://en.wikipedia.org/wiki
其中AMD 1982年从Intel获得x86授权,和Cyrix等一起推出了80386、80486的兼容CPU,但由于架构总是落后于Intel一代,只取得了小部分市场。随后几年,一方面客观上不能再使用奔腾/80586等名字,另外一方面主观上也开始进行独立架构的研发,逐渐打开了属于自己的天地,一些关键节点包括:
1996年,AMD推出了首款独立设计且兼容x86的微处理器K5,证明了AMD也有能力提供与主流台式电脑全面兼容的微处理器。
1997年,AMD推出了包含MMX指令集的K6架构和芯片,采用0.35微米工艺,工作频率166~233MHz,一级缓存64KB,和Pentium达成平手。
1998年,迅速推出改进款K6-2,一方面提高频率到475MHz,另一方面一级缓存维持64KB,增加位于主板上的二级缓存,容量在512KB~2MB之间,让个人电脑价格首次降至1,000美元以下,以极高的性价比吹响了向Intel挑战的号角。
1999年,AMD推出K7架构并起品牌名Athlon(速龙),融合了AMD以前CPU和DEC Alpha 21264的技术,采用250ns工艺,500MHz主频,属于业内首款第七代x86处理器。
从1999年开始,虽然桌面/笔记本/服务器端的总体领先者是Intel,但基本上是Intel和AMD你追我赶的两强争霸局面(市场份额见图5),威盛等厂商占有一定份额但都很小。
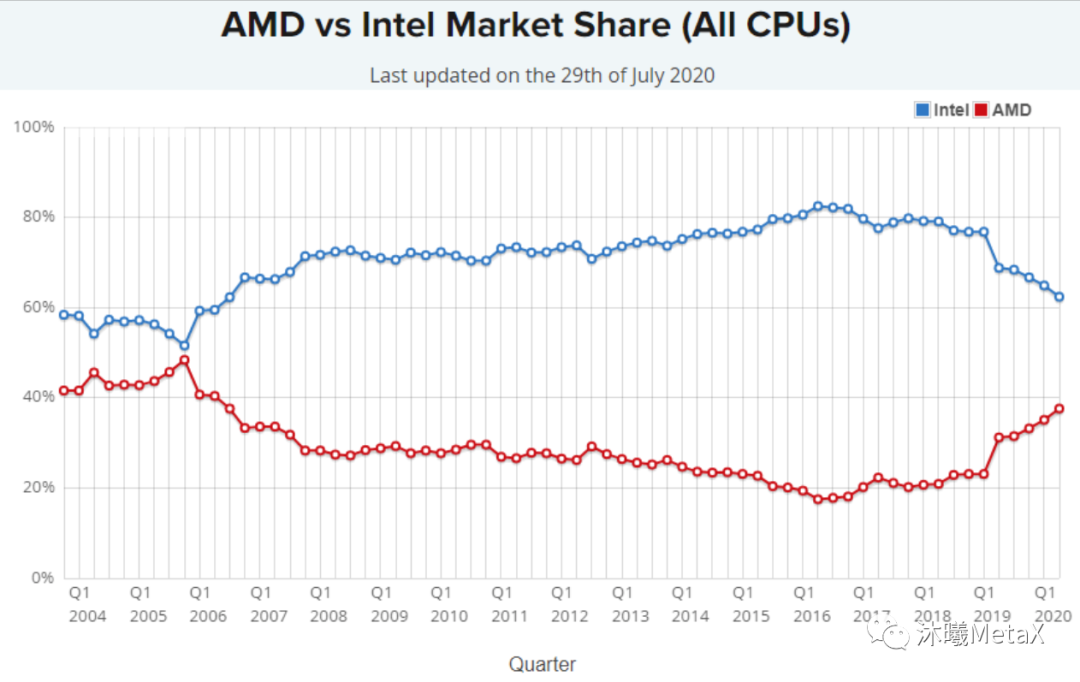
图5:Intel和AMD在CPU领域的市场份额
https://www.statista.com/statistics/735904/worldwide-x86-intel-amd-market-share/
图6具像地描述了Intel和AMD CPU芯片的主要迭代,2005年以前以比拼频率为主;之后进入了多核时代,从双核到四核、6核等等。Intel在2018年发布的服务器端芯片Xeon 9282(cascade lake架构)包含56核。另外,在芯片内部架构层面,一方面都适时地调整cache配置,增加及优化SIMD指令集等;另一方面出现技术分化,Intel在2008年开始加入了Turbo Boost技术来动态地boost频率,到2020年为止该技术已迭代3代;而AMD从2011年开始转向APU架构,CPU核和GPU核协同并共享L3 cache。此外,制造工艺也持续优化(7nm/5nm等),晶体管数量也继续摩尔迭代。
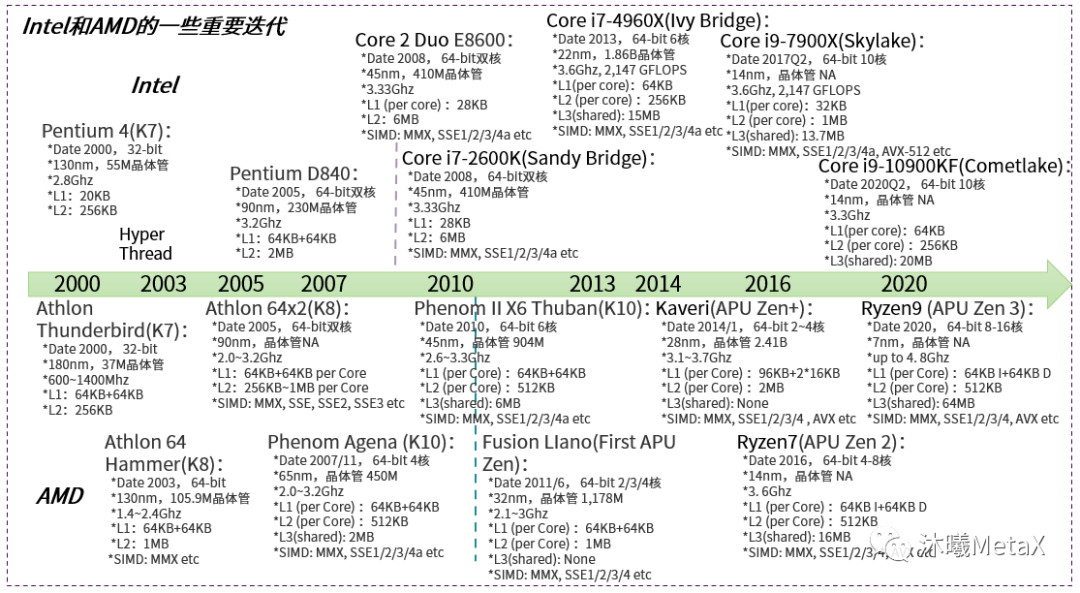
图6: Intel和AMD在2000~2020年CPU芯片的重要迭代
3.2移动端ARM
1978年,工程师克里斯·库里与赫尔曼·豪瑟相遇,两人志向相投,共同创办了CPU公司“Cambridge Processor Unit(剑桥处理器单元)”。在创建初期,公司主要从事当地市场的电子设备设计和制造业务。由于黑客策划入侵赌博机,当地有公司找到CPU企业,请他们专门设计一款适用于赌博机的微处理器控制器,以阻止黑客入侵。在1979年3月,“Acorn System 1”被发明了出来,核心是6502 CPU,频率为1MHz,内存超过1K。因为这款产品取得了成功,他们将公司改名为“Acorn Computer Ltd”。
1981年,英国广播公司BBC打算在整个英国播放一套提高电脑普及水平的节目,他们希望Acorn能生产一款与之配套的电脑。接下这个需求时,Acorn想复用原来的设计,但很快就发现自己产品的硬件设计并不能满足要求。当时,CPU的发展潮流正从8位变成16位,Acorn评估了美国国家半导体和摩托罗拉公司的16位芯片,发现芯片的执行速度有点慢,中断的响应时间太长且成本很高,不合预期。他们又找到如日中天的Intel,希望对方提供一些80286处理器的设计资料和样品,但遭到了拒绝。没有办法,他们决定自己造芯片。
经过多年的艰苦奋斗,基于RISC(精简指令集计算机)架构的微处理器在1985年终于被设计出来,Acorn给这款芯片命名为Acorn RISC Machine,这就是“ARM芯片”的由来。在1990年,Acorn公司也正式改称为ARM计算机公司。
由于ARM采用RISC架构,它支持的指令比较简单,所以功耗小、价格便宜,特别适合移动设备。但在成立后的那几年,并没有什么大的应用市场,ARM决定改变他们的产品策略:他们自己不再生产芯片,转而以授权的方式,将芯片设计方案转让给其他公司。随后与德州仪器的合作,给ARM公司带来了重要突破,也证实了授权模式的可行性。正是这种模式,开创了属于ARM的全新时代,在市场应用端的一些重大事件有:
■ 1993年,ARM将产品授权给Cirrus Logic和德州仪器。与德州仪器的合作,给ARM公司树立了声誉,也证实了授权模式的可行性。越来越多的公司参与到这种授权模式中,包括三星、夏普等。
■ 1993年,苹果公司推出了一款新型掌上电脑产品Newton。ARM公司开发的ARM6芯片被用于该产品之中。
■ 1997年,诺基亚6110手机发布,采用ARM专门为之开发的16位定制指令集(缩小内存空间),并获得了极大的成功。
■ 2001年,基于ARM架构的苹果Ipod发布并取得了巨大的成功。
■ 2007年,随着Iphone的热销,以及App Store的迅速崛起,让全球移动应用彻底绑定在ARM指令集上。
■ 2008年,谷歌推出了安卓系统,也是基于ARM指令集。
■ 2011年,微软公司宣布,下一版Windows将正式支持ARM处理器。这是计算机工业发展历史上的一件大事,标志着x86处理器的主导地位发生动摇。
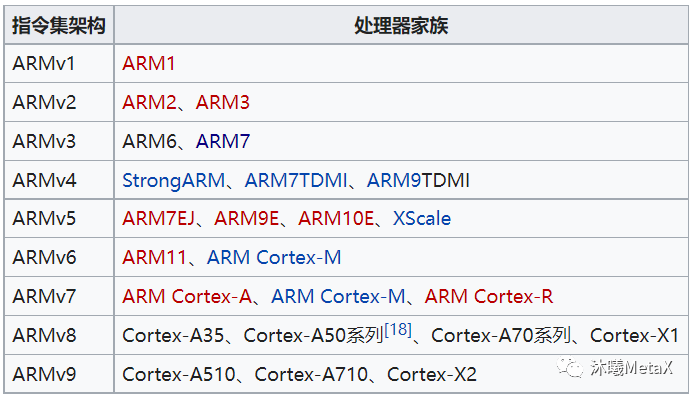
图7:ARM架构演进和芯片系列的对应关系
https://zh.wikipedia.org/wiki/ARM架构
在过去的30年,ARM内核从v1迭代到了v9(图7),系列特点包括:
ARMv3:1994年推出ARM7TDMI,使用范围最广的 32 位嵌入式处理器系列,0.9MIPS/MHz的三级流水线和冯·诺依曼结构。该系列处理器提供Thumb 16位压缩指令集和EmbededICE软件调试方式,适用于更大规模的SoC设计。
ARMv4:1997年推出ARM9,采用哈佛体系结构,指令和数据分属不同的总线,可以并行处理;采用五级流水线,主要应用于音频技术以及高档工业级产品,可以跑Linux以及Wince等高级嵌入式系统。
ARMv5:2001年推出ARM1020E,使用哈佛结构,6级流水线,主频最高可达325MHz,1.35MIPS/MHZ。定位为综合处理器,使用单一的处理器内核提供了微控制器、DSP、Java应用系统的解决方案,极大减少了芯片的面积和系统的复杂程度。
ARMv6:2002年推出ARM1136J,使用哈佛结构,8级流水线,主频最高可达500MHz,添加了跳转预测功能及多媒体处理扩展。ARM11的媒体处理能力和低功耗特点,特别适用于无线和消费类电子产品;其高数据吞吐量和高性能的结合非常适合网络处理应用;另外,ARM11在实时性能和浮点处理等方面可以满足汽车电子应用的需求。
ARMv7:2004年推出Cortex-M3,在经典处理器ARM11以后的产品改用Cortex命名,并分成A、R和M三类。
■ A类为应用型处理器,为可托管丰富OS平台和用户应用程序的设备提供全方位的解决方案;
■ R类为实时处理器,为要求可靠性、高可用性、容错功能、可维护性和实时响应的嵌入式系统提供高性能计算解决方案;
■M类处理器系列,是一系列可向上兼容的高能效、易于使用的处理器,这些处理器旨在帮助开发人员满足将来的嵌入式应用的需要 。
2005年推出了Cortex-A8,还是采用哈佛结构,引入了VFP和NEON等浮点和SIMD协处理器,包含双发射、超标量功能和13级主整数流水线;带有先进的动态分支预测,可实现2.0 DMIPS/MHz。Cortex-A8处理器给消费和低功耗移动产品带来重大变革,使得最终用户可以享受到更高水准的娱乐和创新。
ARMv8:2012年开始推出Cortex-A53和A57,首次使用64位指令集,保持与ARMv7架构的完全后向兼容性。Cortex-A57采用18级流水线,支持指令预取,3分发及优化cache配置等提高了单个时钟周期性能,比高性能Cortex-A15 CPU高出了20%至40%。它还改进了二级高速缓存的设计以及内存系统的其他组件,极大提高了能效。
ARMv9:2021年,应对在AI、安全及其它计算场景推出了ARMv9架构,有更强的向量处理单元(SVE2)、AI单元和DSP。
3.3小结和展望
CPU是控制芯片,也是早中期的主要计算芯片,即使到了2022年,CPU算力在端上或云上都还扮演着很重要的角色。图8罗列了到目前为主CPU领域的主要架构和公司。

图8:Wind整理的国内外CPU主要厂商
https://jishuin.proginn.com/p/763bfbd346b5
在CPU领域,大体可以看到3个趋势:
中国芯片设计进入蓬勃发展阶段:一方面,产业发展本身有往“深入”及“独特”发展的需要;另一方面,由于国际环境变化,CPU芯片领域得到了国家/企业等多个层面的战略重视。国内CPU芯片设计制造正在进入蓬勃发展的阶段,特别是在手机芯片上,华为的麒麟芯片等已获得成功的实践。
ARM和x86等应用边界开始模糊:先前x86侧重在桌面和服务器端,ARM侧重在移动端。现在ARM也已经在桌面端、服务器端发力。另一方面,桌面端和移动端在应用层面本身也有融合的趋势,手机/Pad/轻薄笔记本等逐步接替了很多桌面端的需求。如图9所预测的,在2030年的PC和服务器端,50%的机器都会采用既有ARM又有x86的异构体系;而单纯使用ARM架构芯片会达到23.1亿台,是单纯使用x86架构的7亿台的三倍多。
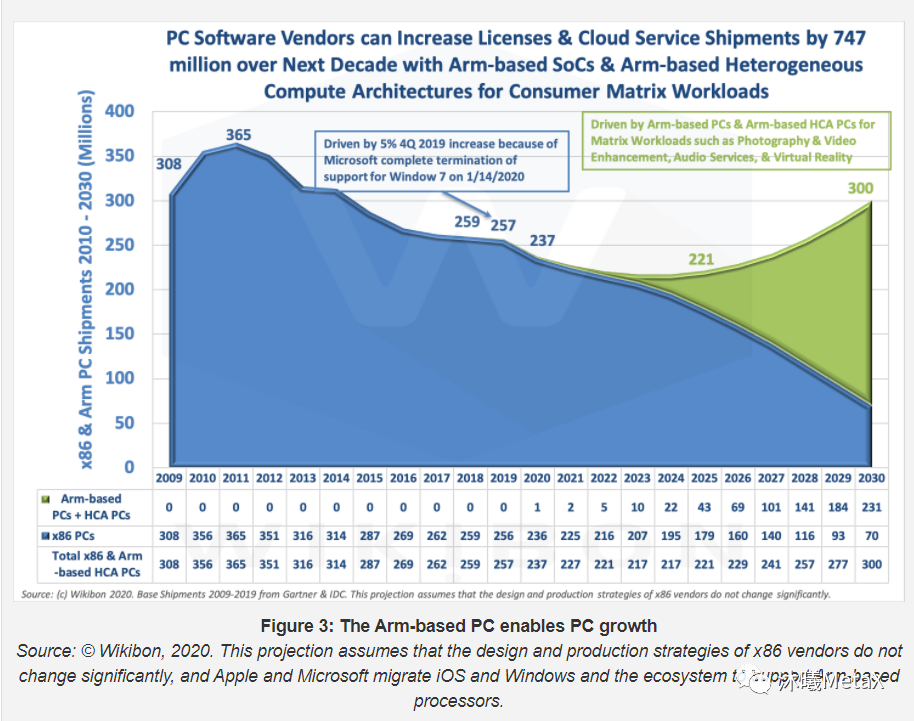
图9:Wikibon对X86和ARM架构在PC端市场的未来10年预测
边缘端逐步兴起,且会大规模采用RISC-V架构:一方面,IoT(物联网)随着智能家居、智慧城市、汽车自动驾驶、工业4.0等的发展一步步走向深入,更多元器件有计算和智能的需求;另一方面,RISC-V架构和ARM很相似,且是完全开源及可自行重构的架构,性能及生态也在快速发展中。RISC-V成为IoT时代使用最广泛的架构将会是未来的一大趋势。在图10 中Counterpoint对RISC-V进行了展望,到2025年,其在IoT领域能达到28%的市场份额。

图10: Counterpoint对RISC-V芯片的分析和前景预测
大计算GPU时代
承载当前最大算力的GPU芯片起步最晚,但发展最为迅猛,竞争更为激烈。图11从经典GPU功能的角度对整个行业发展过程进行了具象描述。
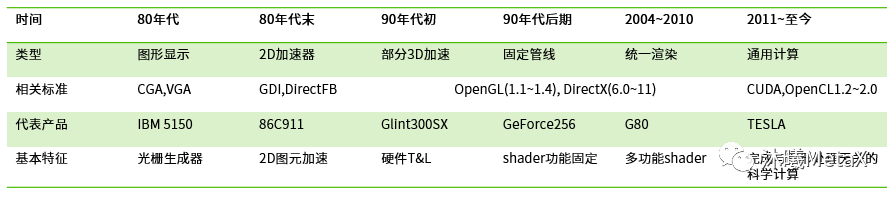
图11:半导体行业观察描述的GPU发展过程
(时间划分有待商榷)
http://www.semiinsights.com/s/electronic_components/23/43026.shtml
从计算功能的角度,图12可能展示了一个更好的划分。

图12:GPU(计算芯片)发展的阶段
4.12D/3D图形加速阶段
早期发明的电脑是文本方式的显示(譬如DOS),上世纪80年代开始采用图形输出的Apple II出现,但图形输出处理是用CPU来完成,然后再显示在屏幕上。最初的2D加速卡出现在游戏机雅达利2600上,它有专门负责图形处理和输出的Antic芯片和音频处理的CTIA芯片。在80年代的专业领域,英特尔用自己的82720图形卡芯片为基础生产iSBX 275视频图形卡,价格1000美元。它能够以256x256的分辨率(或以512x512的单色)显示八种颜色数据,带有32KB显示内存,足以绘制线、弧、圆、矩形和字符位图。该芯片还提供了缩放、屏幕分区和滚动的功能。
到了80年代末,个人电脑使用量越来越多,图形卡的需求越来越迫切,ATI,Trident,SiS,Realtek等纷纷成立着手研发首批PC端图形卡。1991年,成立于1989年的S3 Graphic公司发布了世界上第一款2D图形加速卡,命名为S3 86C911,911取名来源于保时捷911以彰显其速度,8C911主要规格为1MB的显存和支持16/256色色彩。此后2D图形加速卡进入了群雄争霸的时代,S3、Trident、Matrox三大厂商占据初始主导地位,随后的一些重要相关事件包括:
■ 1992年,SGI发布了OpenGL 1.0,这是一个针对2D和3D图形卡的API,初期瞄准基于UNIX的专业市场。由于SGI开发人员对其扩展有很好的支持,很快它被应用于3D游戏开发中。
■ 1994年,3Dlabs发布了第一块OpenGL兼容的3D加速芯片GLINT 300SX,带有高洛德着色、深度缓冲、全屏抗锯齿、Alpha混合等特性。这些特性被沿用至今,开启了计算机3D世界的大门。
■ 1995年,S3发布了Trio64,把原先分离的24-bit数模转换、64-bit图形处理器、可编程双时钟生成器等模块集成在一块芯片上,支持1024x768x64K颜色,较好地支持多媒体加速,取得了巨大的成功。
■ 1995年,NVIDIA推出其首款产品 NV1,配备了基于正交纹理映射的 2D/3D 图形核心,开始加入战场。
■ 1996年,微软推出DIRECTX 1.0/2.0/3.0,它不仅仅提供了类似OpenGL的3D 图形API(Direct 3D+Direct Draw),而且还包括Direct Input, Direct Play等一整套的多媒体接口方案。
同年,Nvidia推出业界首个支持微软Direct3D的驱动程序。
■ 1996年,ATI发布了Mach64 GT,基于TSMC 500nm工艺,支持最新的DirectX 5.0, 包含1个 pixel shaders,采样Xclaim技术是第一个支持Mac计算机的显卡,并且与S3的Trio一起提供了全动态视频播放加速功能。
同年,Nvidia推出全球首款128位3D处理器RIVA 128,前四个月销量就达到100万台。
■ 1999年,Nvidia首先提出了GPU概念,把GPU定义为:具有集成变换、照明、三角设置/裁剪和渲染引擎的单芯片处理器,每秒可处理至少1000万个多边形。
随着Windows操作系统(Win98,2000,XP,Vista等)越来越为广大用户所使用,对应的Direct3D API功能需求成为了GPU芯片厂商迭代的主要源动力和事实标准。Nvidia凭借出色的研发实力和优秀的市场策略,越来越成为GPU领域的王者,昔日的领导厂商S3,3DFX逐渐被收购慢慢淡出了主流市场。ATI凭借在2000年发布了划时代的Radeon显卡,具备了和Nvidia一较高下的资格,从此,整个PC独立显卡领域,基本呈现ATI和Nvidia两大阵营对战的局面。
图13罗列了这一阶段Nvidia和AMD的一些标志性GPU芯片,芯片的发布基本沿着DirectX的版本升级,期间也支撑了一款又一款的经典游戏如魔兽世界、半条命2、极品飞车10等。
体现芯片计算能力的核心指标有两个:浮点计算能力(FLOP)和数据读写带宽(BW)。从2000年开始,如图14所示,GPU芯片在这一阶段开始超越CPU芯片成为最强的计算芯片,并且差距在持续拉大并基本保持在1个数量级左右。

图13:Nvidia和AMD DirectX时代的交互迭代
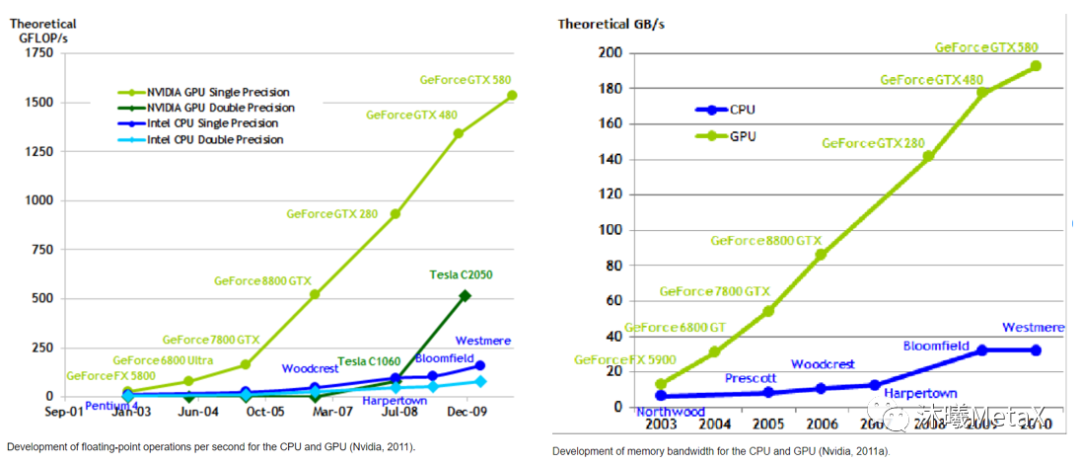
图14:20世纪初GPU和CPU的计算能力对比和带宽对比
https://www.researchgate.net/journal/Mathematical-Problems-in-Engineering-1563-5147
虽然独立显卡端(笔记本电脑&工作站等,Intel在集成显卡端有很大的份额)的主导厂商是Nvidia和AMD,但由于它们的产品普遍功耗较大,从60W到300W左右,不适合在手机场景直接使用。一些厂商另辟蹊径发力移动端,随着智能手机和手机游戏的蓬勃发展,移动端的GPU也得到了迅猛发展。移动端GPU主要公司和产品如图15所示。

图15:2020年移动端的主要GPU厂商和代表产品
https://toutiaosg.com/6806315161167593987
4.2GPGPU阶段
硬件是固化的,因而是有限的;而软件是可变的,因而是无穷的。
从2000年D3D(Direct 3D)8.0开始,为了让复杂物体譬如毛发火焰等被渲染地更加逼真和高效,可编程功能(Vertex Shader 1.0,Pixel Shader 1.0)开始被引入,Nvidia的NV20 GPU在2001年率先支持了可编程功能。在随后的几年,如图16所示,D3D每年都有一个小版本的迭代,对GPU内部的可编程性有了明确且越来越高的要求。

图16: DirectX的发展对GPU内部的可编程需求越来越高
另外一方面,GPU的主要任务是处理成千上万个三角形的顶点/内部像素的着色。为了处理这类简单类似但数据量巨大的任务,GPU构建了很多的浮点乘法和加法计算单元,是一种典型的可并行计算架构。而任何复杂的功能本质上都可以拆解为乘法和加法运算,GPU特别擅长的矩阵乘(GEMM)就是科学计算的基本运算单元。从Nvidia发布NV20后,就有前沿的研究人员开始思考用GPU来进行科学计算。2005年,科学计算中常用的一个程序LU decomposition(矩阵的上三角矩阵和下三角矩阵分解),在GPU中进行了实现,并第一次比在CPU中运行地更快。
Nvidia敏锐地感知到了一种可能性,并极具前瞻性地对GPU硬件和软件架构进行了深入研究。2006年,Nvidia正式推出CUDA,一种用于通用GPU计算的革命性架构,借助CUDA,科学家和研究人员能够利用GPU的并行计算能力来应对最为复杂的计算挑战。从此,GPU的演化不仅仅是满足图形(D3D等)方面的需求,更是往并行化、通用化的方向去努力(CUDA,OpenCL,OpenACC,OpenMP,OpenHMPP等)。

图17: Nvidia/AMD计算GPU的产品迭代及规格
在芯片层面,2007年,Nvidia推出了Tesla产品线。Tesla专注在高性能计算领域,其中的芯片代表了Nvidia相同架构下最强的计算能力。从C870开始到P100,差不多10年的时间, 芯片制造工艺从90nm迭代到16nm,晶体管从681M迭代到15.3B,基本上符合摩尔定律。此外,32-bit浮点的计算性能也从C870的345.6GFLOPS提升到了P00的10.6TFLOPS。
同时期AMD的GPU发展重心主要还是在图形领域(除了桌面端,在家庭游戏机端中取得了较大成功,PS2/3/4/5,Xbox 360/One等都使用了AMD芯片),在计算产品领域,在2016年发布Instinct品牌和首款产品MI6,以及对标CUDA计算框架的ROCm。

图18: “GPU和GDDR”方式和“GPU和HBM”方式的外形区别
https://en.wikipedia.org/wiki
这一时期,对AMD来说值得一提的是HBM在显卡中的引入。计算芯片的两个核心要素是计算力和数据读写带宽,在M40、K20X等所有显卡中,虽然显存都很大,譬如12GB,但都额外使用独立封装的内存芯片;GPU芯片通过GDDR3/4/5等控制器对内存芯片中的数据进行快速读取(图18左)。AMD工作人员发现采用DDR/GDDR迭代的方式,单位功耗的数据读取性能在某一个频率点会发生明显地下降;因此AMD从2008年开始着手研究HBM,并在2013年和SK海力士一起推出了首款HBM芯片。它采用3D堆叠的办法把内存芯片直接和GPU芯片封装在一起(图18右),一层堆叠是一个256-bit的channel,4个8层的堆叠就可以达到4096-bit的双向读写接口,比先前GDDR5的384-bit有了一个数量级的提升。AMD的Radeon R9 FURY X(2015/6, 28nm, 8,900M晶体管)是首款采用HBM的GPU,随后,Nvidia的Tesla产品线也开始大规模使用HBM技术,其中P100是首款采用HBM2的GPU。
4.3AI阶段
在20世纪七八十年代,卷积网络、感知机、反向传播等就已被发明出来,但相关研究及进展都波澜不惊。直到2009年,人类社会才快速进入到了AI阶段,其中的大事件包括:
■ 2009年,斯坦福教授李飞飞发起了ImageNet项目,收集并开源了包括27大类、3822小类共14M张图片及对应的类别标识,并进行一年一次的视觉挑战大赛(ILSVRSC)。
■ 2011年,计算机科学家Alex Krizhevsky等首次采用了GPU来进行深度学习网络的训练,并研发了AlexNet网络,连续在2011年和2012年取得视觉挑战大赛的冠军,且效果远超第二名的经典算法(SIFT等)。一方面得益于网络的精巧设计,但更重要的是首次采用了2块GTX 580显卡,证明GPU能够使大规模数据的网络训练得以低成本实现。
■ GoogleNet(vgg),Inception,GAN,ResNet等AI网络和算法被发明并持续迭代。
■ 2016年,google用AI算法AlphaGo全网络视频直播下围棋,战胜了围棋世界冠军李世石,彻底引爆了全世界。

图19: 蓬勃发展的GPU和AI芯片
一开始,GPU只是不经意地被使用在AI算法实践中。随着AI算法的影响越来越大,芯片界也开始了针对性的研究,一些里程碑事件包括:
2014年,寒武纪发布了人工智能处理器的开山之作DIanNao(电脑),分析了AI的重要算子并构建了首款NPU;在随后几年又陆续发布了DaDianNao,PuDianNao等,在学术界和工业界产生了极大的影响。
2014年,Nvidia基于CUDA编程框架,发布了专门面向AI加速的cudnn v1计算加速库,使得AI算法在GPU上可以更简便、更高效地运行起来。此后cudnn持续更新迭代了8个大版本。
2016年,Google发布了TPU芯片,专门用于深度学习的推理,此后陆续迭代发布了4款TPU芯片。
2017年,Nvidia发布了V100芯片,里面有专门为AI设计的TensorCore,它能以半精度的方式计算 4×4 矩阵乘法的特定内核,并在一个时钟周期内将计算结果累加到单精度(或半精度)4×4 矩阵中,相比常规的32-bit浮点计算快8倍。TensorCore在随后的芯片中迭代了3个大版本。
图19罗列了2016年以来问世的重要计算芯片,从中不仅可以看到Nvidia,AMD和Intel等传统芯片厂商,新兴厂商如Google、华为、Graphcore、寒武纪、阿里等也纷纷入局并发布重量级产品,侧面反应出AI计算芯片的重要性,以及其中蕴藏的各种可能性。
移动端的手机芯片厂商(图15),如ARM、高通和Imagination等,也都添加了AI的协处理器或者加速指令,在移动端开始提供越来越强的AI算力。
最后,和CPU、内存芯片类似,国内GPU&AI芯片在应用场景需求和国际大环境变化等多重因素促进下,约从2018年开始,十几家厂商先后涌现,展开了一个蓬勃发展的AI计算时代。
4.4计算芯片迭代趋势
从过去五十年主体芯片的发展历程不难总结出,芯片迭代的核心驱动在于:一要满足(将来)应用场景的需要;二要性能更强大或性价比更合理。这两点也适用于计算芯片未来的发展。
计算芯片的应用场景在持续演化中,在大的层面越来越清晰,大体可分为以下几种:
AI:目前AI已渗透到人类活动的方方面面(衣食住行玩)。AI算法在大方向上包括视觉、语音、3D、自然语音理解、控制等方面。从计算维度上,它主要包括:(1)数据的感知和采集:来源于各种sensor包括摄像头和IoT传感器等,计算少但数量极大;(2)AI算法的训练:以较强计算能力的服务器、台式机为主,计算量极大但数量中等;(3)AI部署:以各种边缘或移动设备为主,数量很大;也包括一些服务器等,数量较大。
图形图像(包括游戏):这将是人类永恒的需求,在服务器端和移动端始终拥有巨大需求,芯片也会相应迭代。
高性能计算:探索未知,预测未来,高性能计算在众多前沿科学领域有着极为重要的应用,在服务器端也会有持续的需求。
那么计算芯片如何进一步取得更强大的性能或性价比?以下迭代的角度可供参考:
芯片制造
芯片制程是极为关键的一环,晶体管集成度的提升能够降低成本和功耗,未来会朝着1nm的极限目标持续努力。但另一方面,如图20所示,随着芯片制程的发展,单位晶体管的成本已不再降低,功耗也极有可能面临相同的境况。届时芯片制造将不再追求单芯片的集成度,而是芯片间的组合拓展,譬如1台机器包括8块芯片,512台机器组成一个集群。此外芯片的封装测试也在持续提高自动化、智能化水平,在一定程度上能够实现成本的下降。
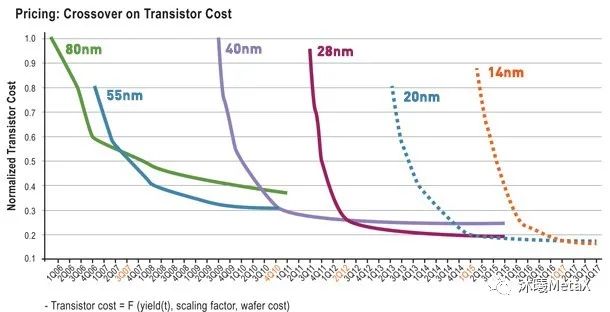
图20:80nm后各工艺节点单个晶体管的费用随时间的变化趋势
“Beyond Moore’s law,” The Economist, May 26, 2015.
存储带宽
分为芯片内存储带宽和芯片间存储带宽两部分,都将保持扩张趋势。芯片内存储将大规模使用更先进的HBM,如4096bit,6144bit,8192bit等,带宽则迭代到1.8TB/s到3.3TB/s等。芯片间的存储带宽也将越来越大,从并发连接数量及连接带宽两个维度进行扩张。
计算能力和芯片架构
两者有着较大的关联。芯片架构从大的维度包含CPU、GPU、DSA(Domain Specific Architecture, TPU, NPU等)、FPGA和ASIC。它们都由晶体管组成,只是作用和功能多样性不同。ASIC灵活性最差,只能满足初始制造时的功能;FGPA可重构,多样性最强,但重构之后使用时和ASIC情况类似;GPU处在中间;CPU功能多样性最强;DSA处在ASIC和GPU中间。所以从实现确定功能的效率角度, ASIC最高,GPU次之,CPU最低。图21展示了不同形态芯片架构在不同任务上的能效比。
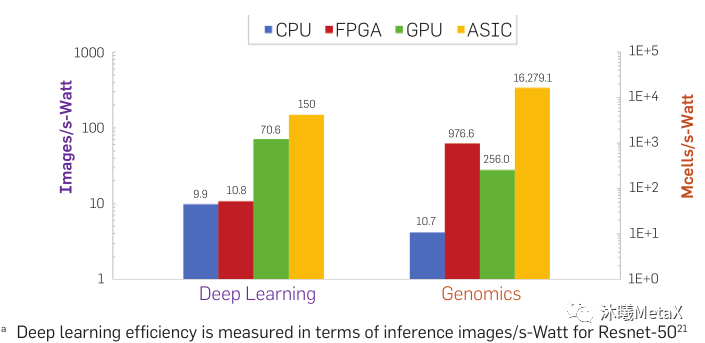
图21:不同芯片形态在深度学习和基因组测序类应用上的能量效率对比
“Domain-specific hardware accelerators,” Communications of the ACM, Jun. 2020
所以,高性价比的芯片架构是与需要解决的问题强相关的。如果问题特别确定,譬如完成99.9%准确率的人脸识别,ASIC是较好的选择。但在较复杂且需要不停迭代的任务中,进化中的GPU架构将会在较长时间内取得最佳综合效果。图22展现了Nvidia架构芯片A100和其它各种NPU架构的性能比较,从中可以看出,一方面A100性能明显高于各种NPU架构(ResNet50比TPUv4略差);另一方面A100在各个AI算法方向都有很好的表现,比NPU具有更强的普适性。
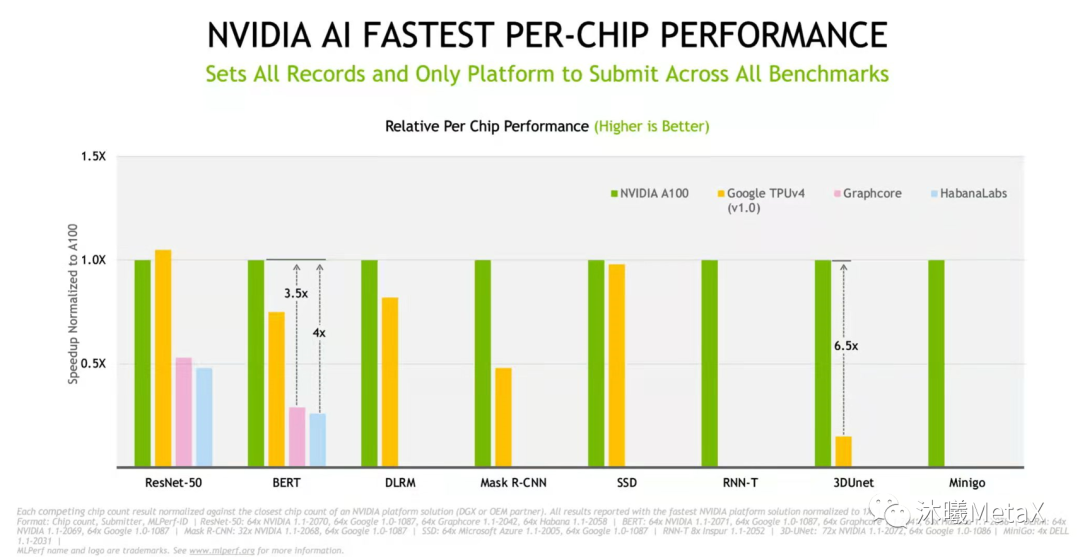
图22:mlperf 多种AI主流任务的性能比较
https://www.nvidia.com/en-us/data-center/mlperf/
计算能力的迭代除了频率和架构,基础计算单元也非常重要。在GPU时代,单精度浮点计算能力迭代到20TB/s已是一个瓶颈,AI时代更重要的是需要和场景相结合,定义合适的计算单元,譬如BF16、TF32、int16、int8等计算精度。此方面的研究将不停深入并具有多样性。
软件生态
一个芯片要充分发挥其能效,离不开上层软件栈和生态的构建。如今Nvidia芯片一枝独秀,软件生态的构建已相当完善,不仅有好用易用的编译器和驱动程序,还有CUDA、cudnn、RAPIDS、tensorRT、TritonServer等加速库和计算软件框架,以及汽车自动驾驶、omniverse等更上层的整体解决方案。类似的底层框架或上层应用会结合应用场景继续迭代并且扩展开来。而底层的芯片需要做一些功能性的适配,譬如虚拟化等。
小结和思考
纵观芯片数十年的发展和迭代历程,我们可以看出,在技术相对同质的情况下,制造能力和成本优势对芯片企业的发展起到重要作用。但在更长的时间线上,创新及持续优化迭代才是企业真正胜出的关键。这里的创新不仅仅是单一技术本身(譬如内存行列地址复用)的创新,更是结合大的应用背景下包括功能设计、制造成本、软件生态等系统级的联合创新和优化。
从GPU芯片的发展历程来看,从GPU诞生伊始竞争就极为激烈,2D&3D高峰时期有70多家芯片设计公司入局,Nvidia在3D时代胜出后又引领了GPGPU时代和当前的AI时代。现如今,华为、平头哥、寒武纪、壁仞、摩尔线程以及沐曦等众多国内GPU(或AI计算)芯片设计公司不断涌现,成为GPU发展历史上第一次大规模参与高端芯片设计的中国力量。这源于国际竞争大背景下国家层面给予的大力支持,同时也是中国经济社会以及产业发展的必然趋势。中国经济体量巨大,上层应用创新层出不穷,急需要底层的巨大算力支撑,也自然而然需要更高性价比以及更多独特性的系统解决方案(包括芯片)。当前正处于AI的高速成长期,各种AI场景的落地正处于初级阶段,其中蕴藏的可能性和多样性为中国本土企业带来了巨大的发展机遇。
有国家和资本层面的支撑,有持续积累的技术和专业人才,坚持以市场和应用场景为导向,锐意创新,持续迭代,相信经过10年左右的大浪淘沙,中国也能够诞生在世界层面有影响力(top10)的大计算芯片设计公司,让我们拭目以待。
参考文献
1.https://en.wikipedia.org/wiki
2.https://wiki.mbalib.com/wiki
3.https://baike.baidu.com
4.https://www.techpowerup.com/gpu-specs/
5.https://www.eet-china.com/mp/a71064.html
6.https://www.thoughtco.com/history-of-computer-memory
7.https://smithsonianchips.si.edu/augarten/index.htm
8.https://tech.sina.com.cn/csj/2019-06-12/doc-ihvhiews8336095.shtml
9.https://jishuin.proginn.com/p/763bfbd346b5
10.https://zhuanlan.zhihu.com/p/370771150
11.https://www.semiinsights.com/s/electronic_components/23/43026.shtml
12.https://www.eet-china.com/mp/a44855.html
13.https://www.nvidia.cn/about-nvidia/corporate-timeline
14.https://www.bilibili.com/read/cv9822991
15.https://zhuanlan.zhihu.com/p/30797822
16.https://toutiaosg.com/6806315161167593987
17.https://www.tomshardware.com/picturestory/713-amd-cpu-history-2.html
18.https://siliconangle.com/2020/06/26/exiting-x86-apple-microsoft-embracing-arm-based-pc/
19. “Beyond Moore’s law,” The Economist, May 26, 2015.
20.W. Dally etc, “Domain-specific hardware accelerators,” Communications of the ACM, Jun. 2020
21.https://www.nvidia.com/en-us/data-center/mlperf/
22.https://zhuanlan.zhihu.com/p/361920046
23.https://www.counterpointresearch.com/zh-hans/riscv-semiconductor-ip-market-2025/








