绑定手机号
确认绑定









国家发改委等四部门联合发布《全国一体化大数据中心协同创新体系算力枢纽实施方案》,提出在京津冀、长三角、粤港澳大湾区、成渝以及贵州、内蒙古、甘肃、宁夏建设全国算力网络国家枢纽节点,启动实施“东数西算”工程,构建国家算力网络体系。
当前,算力已成为全球战略竞争新焦点,是国民经济发展的重要引擎,全球各国的算力水平与经济发展水平呈现显著的正相关。在2020年全球算力中,美国占36%,中国占31%,欧洲和日本分别占11%及6%。近年来,美国、欧洲、日本纷纷制定行动计划,不断运用算力助推经济增长。
“数据、算法、算力”是数字经济时代核心的三个要素,其中算力是数字经济的物理承载。这里,我们通过“预见·第四代算力革命”系列文章(共四篇),从微观到宏观,详细分析跟性能和算力相关的各个因素以及主流的算力平台,尽可能地直面当前算力提升面临的诸多挑战和困难,展望面向未来的算力发展趋势。这四篇文章为:
预见·第四代算力革命(二):三大主流计算平台CPU、GPU和DSA;
预见·第四代算力革命(三):面向未来十年的新一代计算架构;
预见·第四代算力革命(四):宏观算力建设。
本文为第二篇,欢迎关注公众号,阅读历史以及后续精彩文章。
参考文献:
https://www.jiqizhixin.com/articles/2017-10-31-15,矽说,RISC-V与DSA!计算机架构宗师Patterson与Hennessy 演讲实录
A New Golden Age for Computer Architecture,By John L. Hennessy, David A. Patterson, Communications of the ACM, February 2019, Vol. 62
Computer Architecture: A Quantitative Approach, Sixth Edition, John L. Hennessy, David A. Patterson, Morgan Kaufmann Publishers, 2019
IT行业变化太快,不变的唯有变化。
近年来,云计算、人工智能、自动驾驶、元宇宙等软件新技术层出不穷,并且已有的技术仍在快速迭代。软件技术日新月异,快速演进。然而,目前,支撑这一切的硬件,依然是以CPU计算为主的通用服务器。
指令集,是软硬件的媒介。CPU是最灵活的,原因在于运行于CPU指令都是最基本的加减乘除外加一些访存及控制类指令,就像积木块一样,我们可以随意组合出我们想要的各种形态的功能,形成非常复杂并且功能强大的程序(或者称为软件)。
CPU通过标准化的指令集,使得CPU平台的硬件实现和软件编程完全解耦,没有了对方的掣肘,软件和硬件均可以完全的放飞自我:
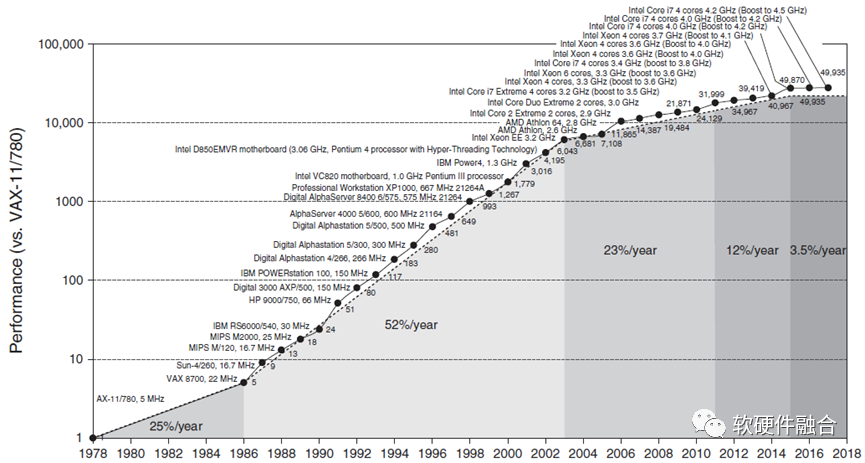
芯片设计工程师不需要关心具体场景,只关注于架构和性能,通过各种优化手段,快速提升CPU性能。从上图中,可以看到,在差不多40年的时间里,CPU的整体性能提升接近50000倍。一方面有赖于半导体工艺的进步,也有赖于处理器架构的翻天覆地变化。
软件工程师,不需要关注硬件细节,聚焦于软件开发。软件没有了硬件的“约束”,逐渐发展成了一个超级生态。从各种数百万使用者的高级编程语言/编译器,到广泛使用在云计算数据中心、PC机、手机等终端的操作系统以及各种系统框架/开发库,再到各种专业的数据库、中间件,以及云计算基础的虚拟化、容器等。上述这些软件都是基础的支撑软件,是软件的“冰山一角”,而更多的则是各种应用级的软件。系统级和应用级的软件,共同组成了基于CPU的软件超级生态。
在手机端已经非常成熟的SOC实现,为什么在数据中心端没有大规模应用?为什么直到现,数据中心依然是以CPU为主的计算平台?这是因为,越是复杂的场景,对软件灵活性的要求越高,而只有CPU能够提供云场景所需的灵活性。
超大规模复杂计算场景对硬件灵活性的要求,主要体现在四个方面:
硬件的灵活性。硬件处理引擎要能够很好地支持软件的快速迭代。CPU因为其灵活的基础指令编程的特点,可以认为是最适合云计算的处理引擎。
硬件的通用性。厂家购买服务器,很难预测服务器会运行哪类任务。最好的办法是采用完全通用的服务器。CPU由于其通用性,成为云计算场景最优的选择。
硬件的利用率。云计算通过虚拟化把资源切分,实现资源共享,以此提高资源利用并降低成本。而目前,只有CPU能够实现非常友好的硬件级别的虚拟化支持。
硬件的一致性。云计算场景,软硬件相互脱离。同一个软件实体会在不同的硬件实体迁移,同一个硬件实体也需要运行不同的软件实体。而CPU,是一致性最好的硬件平台。

图 CPU性能提升的五个阶段
上图明确展示了CPU性能发展的五个阶段:
CISC阶段。上世纪80年代,x86架构为代表的CISC架构开启了CPU性能快速提升的时代,CPU性能每年提升约25%(图中22%数据有误),大约3年性能可以翻倍。
RISC阶段。CISC指令系统越来越复杂,而RISC证明了“越精简,越高效”。随着RISC架构的CPU开始流行,性能每年可以达到52%,性能翻倍只需要18个月。
多核阶段。单核CPU的性能提升越来越困难,通过集成更多CPU核并行的方式来进一步提升性能。这一时期,每年性能提升可以到23%,性能翻倍需要3.5年。
多核性能递减阶段。随着CPU核的数量越来越多,阿姆达尔定律证明了处理器数量的增加带来的收益会逐渐递减。这一时期,CPU性能提升每年只有12%,性能翻倍需要6年。
性能提升瓶颈阶段。不管是从架构/微架构设计、工艺、多核并行等各种手段都用尽的时候,CPU整体的性能提升达到了一个瓶颈。从2015年之后,CPU性能每年提升只有3%,要想性能翻倍,需要20年。
总之,受边际效应递减的影响,CPU的性能已经达到瓶颈;但是,各类上层应用对算力的需求是无止境的。当前,云计算面临的基本矛盾是:CPU的性能,越来越无法满足上层软件的需要。
GPU,Graphics Processing Units,图形处理单元。顾名思义,GPU是主要用于做图形图形处理的专用加速器。GPU内部处理是由很多并行的计算单元支持,如果只是用来做图形图像处理,有点“暴殄天物”,其应用范围太过狭窄。因此把GPU内部的计算单元进行通用化重新设计,GPU变成了GPGPU(本文接下来内容中,如没有特别说明,GPU都指的是GPGPU)。
到2012年,GPU已经发展成为高度并行的众核系统,GPU有强大的并行处理能力和可编程流水线,既可以处理图形数据,也可以处理非图形数据。特别是在面对SIMD类指令,数据处理的运算量远大于数据调度和传输的运算量时,GPU在性能上大大超越了传统的CPU应用程序。现在大家所称呼的GPU通常都指的是GPU。
站在“指令复杂度”的角度,CPU是标量指令计算,而GPU并行可以看做是SIMD或MIMD的计算。GPU的指令复杂度更高。
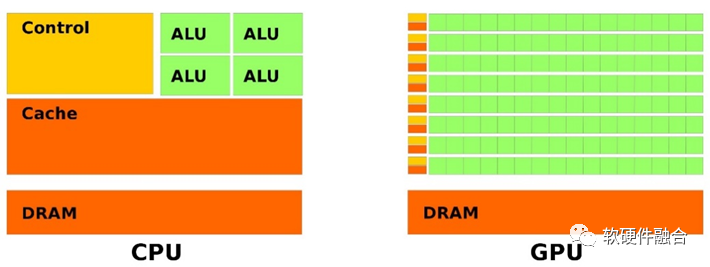
从计算资源占比的角度,如图所示,CPU把更多的资源用于控制和Cache,而把更少的资源用于计算,因此计算的性能相对较差。而GPU等非通用处理器则是把更多的资源投入到计算中,因此具有更好的性能。CPU注重的是是单核的高性能,而GPU注重的单核的高效能以及众核的高性能。

2006年NVIDIA推出了CUDA,这是一个通用的并行计算平台和编程模型,利用NVIDIA GPU中的并行计算引擎,以一种比CPU更高效的方式解决许多复杂的计算问题。CUDA提供了开发者使用C++作为高级编程语言的软件环境。也支持其他语言、应用程序编程接口或基于指令的方法,如FORTRAN、DirectCompute、OpenACC。
从“指令复杂度”的角度,我们可以非常清楚看到,GPU因为“指令”复杂度带来性能提升的好处的同时,其通用灵活性就变得更加困难。因此,CUDA成为NVIDIA GPU成功的关键,它极大地降低了用户基于GPU并行编程的门槛,在此基础上,还针对不同场景构建了功能强大的开发库,逐步建立了GPU+CUDA的强大生态。

网络处理器(Network Processor,简称NP)跟GPU在技术理念上有很多相似之处:都是通过特定优化的、高效能的小CPU核组成的众核系统,并行的完成计算任务。根据“指令”复杂度,从CPU到ASIC的划分,NP和GPU处于相同的位置。
NP具有如下的一些不足:
性能。虽然相比GPU,性能是在同一层级,但相比ASIC/DSA性能不够。
场景。顾名思义,NP主要用于网络场景的处理,没有像GPU那样作为通用并行计算,GPU可以用于非常多的高性能场景。
开发和生态。GPU由于NVIDIA CUDA的强大生态,框架、工具链、开发库都非常成熟。而NP由于生态的不成熟,以及各家NP之间也基本互不兼容,开发者需要了解非常底层的硬件细节,致使编程难度很大。
NP在网络领域有一定范围的采用,但网络领域更主要的处理引擎是网络ASIC,这些年还兴起了网络数据面可编程的网络DSA,都是相比NP架构具有更极致的性能。正因为NP相比ASIC/DSA的性能不足,以及相比GPU覆盖的场景有限,这样的 “高不成,低不就”,导致其一直没能成为(相比GPU而言)主流的通用计算平台。
通用CPU处理器演进遇到了瓶颈:
工艺角度。半导体工艺进步减缓,Dennard Scaling规律约束,芯片功耗急剧上升,晶体管成本不降反升。
架构角度。单核性能极限,多核架构性能提升也变得越来越慢。
作为计算机体系结构领域的泰山北斗,John Hennessy与David Patterson在获得2017年图灵奖时的获奖演说中指出:“未来十年,将是计算机体系结构的黄金年代”。针对计算机性能瓶颈,两人给出的解决方案是DSA(Domain Specific Architecture,特定领域架构)。意思是说,未来需要面向不同的场景,需要根据场景的特点,去定制芯片。
DSA针对特定应用场景定制处理引擎甚至芯片,支持部分软件可编程。DSA与ASIC在同等晶体管资源下性能接近,两者最大的不同在于是否可软件编程。ASIC由于其功能确定,软件只能通过一些简单的配置控制硬件运行,其功能比较单一。而DSA则支持一些可编程能力,使得其功能覆盖的领域范围相比ASIC要大很多。
DSA,一方面可以实现ASIC一样的极致的性能,另一方面,可以像通用CPU一样执行软件程序。当然了,DSA只会加速某些特定领域的应用程序。例如:用于深度学习的神经网络处理器以及用于SDN的网络可编程处理器。
我们看看网络发展的例子。回顾SDN的发展,背景是这样的:
网络芯片是一个紧耦合的ASIC芯片设计,随着支持的网络协议越来越多,其复杂度急剧上升,使用门槛也越来越高。
网络芯片提供的众多功能,每个用户能用到的只是一小部分,这反而拖累了ASIC的性能和资源效率。
完全硬件ASIC实现,上层的用户对网络没有太多的话语权,只能是在供应商已经定好的设计里修改一些配置参数。用户只能是“User”,难以成为“Developer”。
并且,用户要连接到数以千计甚至万计的设备中手动的去配置。
并且,这些设备可能来自不同的厂家,其配置接口完全可能大相径庭。
于是,SDN最开始推出了控制面和数据面分离的Openflow标准协议,通过集中决策,再分发到分布式的支持SDN功能的交换机中。更进一步的,还有了支持数据面编程的P4(Programming Protocol-Independent Packet Processors,可编程的协议无关的包处理器)语言以及网络包处理引擎PISA。这样,还可以通过P4软件程序把功能编程到硬件中去。PISA是一种网络领域专用DSA架构处理器,能够在达到ASIC级别性能的基础上仍然具有非常好的编程能力。
许多时候,为了提供最高效的解决方案,我们不得不根据场景做专门的定制。于是陷入了Case by Case永无休止的开发中无法自拔。并且,为了尽可能的扩大产品的覆盖范围,尽可能提高产品的应用范围,我们又不得不做功能超集,这样,之前因为定制积攒的性能和成本优势就变得不是那么明显。
云计算等复杂场景业务更新迭代很快,芯片的周期(3+5,研发+生命周期,长达8年)很长。大部分情况,ASIC都无法满足业务快速发展的需要。在既需要性能又需要灵活性的场景下,DSA和其他灵活处理器引擎混合架构成为比较合适的选择。
简而言之,定制的ASIC不适合灵活多变的云计算等复杂场景。
DSA架构的第一个经典案例是谷歌的TPU。TPU(Tensor Processing Unit,张量处理单元)是Google定制开发的ASIC芯片,用于加速机器学习工作负载。

图 谷歌TPU 1.0结构框图
如上图,TPU指令通过PCIe Gen3 x16总线从Host发送到TPU的指令缓冲区。内部模块通过256字节宽的总线连接在一起。矩阵乘法单元是TPU的核心,它包含256x256 MAC,可以对有符号或无符号整数执行8位乘加,16位乘积收集在矩阵单元下方的4 MB 32位累加器中。
TPU指令设计为CISC(复杂指令集计算机)类型,包括一个重复域。这些CISC类型指令的CPI(Cycles per Instruction,每条指令的平均时钟周期)通常为10到20。总共大约有十二条指令。

图 CPU、GPU和TPU的性能功耗比
如上图,其中的TPU’是使用了GDDR5存储的改进型。可以看到,相比CPU性能提升196倍,相比GPU性能提升68倍。谷歌随后又开发了TPU 2.0、3.0版本。TPU 1.0的性能峰值达到了92Tops,而TPU2.0性能峰值达到180Tflops,TPU3.0更是达到了420Tflops。并且,从TPU 2.0开始,TPU不再是作为一个加速卡应用于通用服务器,而是定制的TPU集群,这样会更大限度地发挥TPU的加速价值。
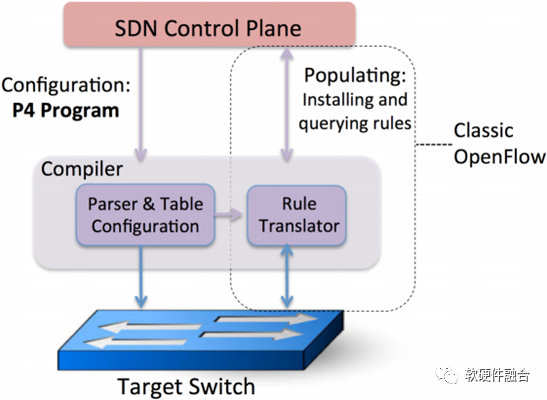
P4是一种面向网络数据面编程的高级语言。上图展示了P4和已有的协议接口之间的关系。P4用来配置交换机,告诉它们应该如何处理数据包。已有的协议接口(例如OpenFlow)负责将转发表送入固定功能的交换机。
P4模型将数据包如何在不同的转发设备上(例如以太网交换机、负载均衡器、路由器)被不同的技术(例如固定功能的ASIC交换芯片、NPU、可重配置的交换机、软件交换机、FPGA等)进行处理的问题通用化。这就使得能够用一门通用的语言来描绘通用的P4模型来处理数据包。
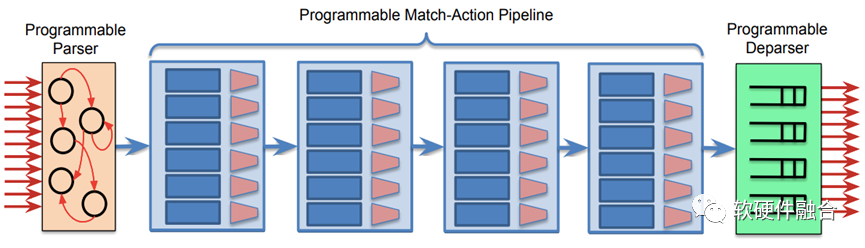
上图是PISA架构(Protocol Independent Switch Architecture,协议无关的交换架构),是一种支持P4数据面可编程包处理的流水线引擎,通过可编程的解析器、多阶段的可编程的匹配动作以及可编程的逆解析器组成的流水线,来实现数据面的编程。这样可以通过编写P4程序,下载到处理器流水线,可以非常方便地支持新协议的处理。
Intel (原来的Barefoot,2019年被Intel收购)基于PISA架构的Tofino芯片,是网络领域最典型的DSA,其实现的可编程流水线既能够达到ASIC级别的性能,又能够通过P4对整个包处理数据面进行编程。
在Intel看来,虽然已经存在NP和FPGA,可以修改网络协议和编辑数据包,并为那些知道如何编写微代码或RTL的人员提供适度的可编程性,但是它们跟ASIC的性能不在一个数量级。因此,NPU和FPGA只能在性能不敏感的地方找到用武之地。Intel为网络行业提供两全其美的解决方案:可编程性数据平面协议,并且达到行业最高的速度。Tofino不仅可以做到比传统ASIC还要更快,而且具有的可编程能力,使得网络编程变得更加容易并且通用。
DSA提供了比传统ASIC更多的灵活性,但依然难以担当数据中心主力计算平台的重任。主要原因是:
DSA是面向某个特定的领域定制优化的设计,这就约束了DSA芯片的应用规模和商业价值。大家都知道,一颗先进工艺的大芯片的一次性研发成本都非常的高,这就需要芯片的大规模落地来摊薄单个芯片的成本。而面向特定领域的设计,和大规模落地相互是矛盾的。
DSA的灵活性具有一定局限。不同用户的场景需求有很大的差别,即使是同一个用户,其场景的应用逻辑和算法仍在快速的迭代。而DSA芯片设计需要3年,芯片生命周期大约5年。8年的周期里,DSA很难支撑众多客户的需求以及客户需求的长期迭代。
DSA难以成为“宏场景”的整体解决方案。以云计算场景为例,是很多场景组合到一起的宏场景。站在系统的角度,数据中心为了运维管理的需要,需要尽可能少的服务器类型。DSA解决特定问题A,如果有A、B、C等多个问题同时需要解决,该如何办呢?
以AI为例,AI-DSA各家都在按照自己的理解定制芯片,可以说在AI领域,还没有标准的软硬件交互交接口,并且框架以及算法和应用都还没有完全稳定。总之,在AI领域,目前还没有形成足够强大的生态。这样,就进一步限制了AI-DSA的落地规模,也就削弱了AI-DSA作为一个主力算力平台的作用。
ASIC是定制芯片AS-IC,对应的我们可以把其他偏通用的IC称之为GP-IC。
在文章里,我们已经对CPU、GPU和DSA三大平台的优劣势进行了详细的分析。而ASIC是作为反面参考案例的。那么,为什么ASIC没有成为一种主流的计算平台呢?ASIC存在的问题,在前面“为什么不是ASIC?”章节已经进行了说明,这里再做一次总结性的强调。
最开始我们说过,ASIC引擎“指令”复杂度最高也即性能会更极致。大家通常的理解,也是如此。但实际上,受限于很多其他原因,ASIC的表现并不如大家想象的那么优秀:
ASIC是定制的,没有冗余,理论上是最极致的性能。但因为ASIC是场景跟硬件设计完全耦合,硬件开发的难度很高,难以实现超大规模的ASIC设计。
理论上来说ASIC的资源效率是最高的,但由于ASIC覆盖的场景较小,芯片设计为了覆盖尽可能多的场景,不得不实现功能超集。实际的功能利用率和资源效率(相比DSA)反而不高。
ASIC功能完全确定,难以覆盖复杂计算场景的差异化要求。差异化包含两个方面:横向的不同用户的差异化需求,纵向的单个用户的长期快速迭代。
即使同一场景,不同Vendor的ASIC引擎设计依然五花八门,毫无生态可言。
而能够成为主流处理引擎的CPU,GPU和DSA其实都有一个共性的特征,那就是“通用”:
CPU,中央处理器,其实还有个更加通俗的名字,通用处理器;
GPU也是因为做到了GP-GPU才开始大放异彩;
DSA可以看做是定制的AS-IC向通用性的回调,DSA是一种GP-IC(对比AS-IC)。
平台 | 性能 | 资源效率 | 灵活性 | 软件生态 |
CPU | ★☆☆☆☆ 边际效应递减:增加晶体管资源,性能提升有限。性能瓶颈,摩尔定律失效。 | ★☆☆☆☆ 相比其他硬件加速处理器,CPU效率最低。 | ★★★★★ CPU指令最简单,是一些最基础的组件。像搭积木一样,编程灵活。 | ★★★★★ CPU广泛应用,软件生态庞大而成熟。 |
GPU | ★★★☆☆ 性能比CPU大幅提升,比DSA/ASIC有较大差距。未来性能即将瓶颈。 | ★★★☆☆ 高效率的小核,以及部分加速引擎。与CPU相比,资源效率显著提升。 | ★★★☆☆ 本质是众核并行,编程具有一定灵活性。同步并行约束,编程相对简单。 | ★★★★☆ GP-GPU CUDA编程生态比较成熟。 |
ASIC | ★★★★☆ 定制无冗余,理论上极致的性能。受限于设计复杂度,难以超大规模设计。 | ★★★★☆ 理论上最高的资源效率,但不可避免存在功能超集。 | ★☆☆☆☆ 功能逻辑完全确定。CSR和可配置表项,通过驱动程序控制硬件运行。 | ☆☆☆☆☆ 同一领域,不同厂家ASIC实现存在差别,需要特定驱动程序。无生态可言。 |
DSA | ★★★★★ ASIC一样极致的性能。由于一定程度的软硬件解耦,能够实现较大规模设计。总体性能高于ASIC。 | ★★★★★ 少量可编程的通用性是需要代价的,但功能利用率高于ASIC。 | ★★☆☆☆ 少量指令,需要强大的编译器,把算法映射到特定DSA架构。相比ASIC,具有一定的可编程性。 | ★☆☆☆☆ 算法和框架经常更新,难以把主流框架完全并且长期地映射到特定DSA架构。 |








