绑定手机号
确认绑定










大型视觉模型目前主导着计算机视觉的许多领域。最新的图像分类、目标检测或语义分割模型都将模型的大小推到现代硬件允许的极限。尽管它们的性能令人印象深刻,但由于计算成本高,这些模型很少在实践中使用。
相反,实践者通常使用更小的模型,如ResNet-50或MobileNet等,这些模型运行起来代价更低。根据Tensorflow Hub的5个BiT的下载次数,最小的ResNet-50的下载次数明显多于较大的模型。因此,许多最近在视觉方面的改进并没有转化为现实世界的应用程序。
为了解决这个问题,本文将专注于以下任务:给定一个特定的应用程序和一个在它上性能很好的大模型,目标是在不影响性能的情况下将模型压缩到一个更小、更高效的模型体系结构。针对这个任务有2种广泛使用的范例:模型剪枝和知识蒸馏。
模型剪枝通过剥离大模型的各个部分来减少大模型的大小。这个过程在实践中可能会有限制性:首先,它不允许更改模型族,比如从ResNet到MobileNet。其次,可能存在依赖于架构的挑战;例如,如果大模型使用GN,修剪通道可能导致需要动态地重新分配通道组。
相反,作者专注于没有这些缺点的知识蒸馏方法。知识蒸馏背后的理念是“提炼”一个教师模型,在本文例子中,一个庞大而繁琐的模型或模型集合,制成一个小而高效的学生模型。这是通过强迫学生模型的预测与教师模型的预测相匹配,从而自然地允许模型家族的变化作为压缩的一部分。
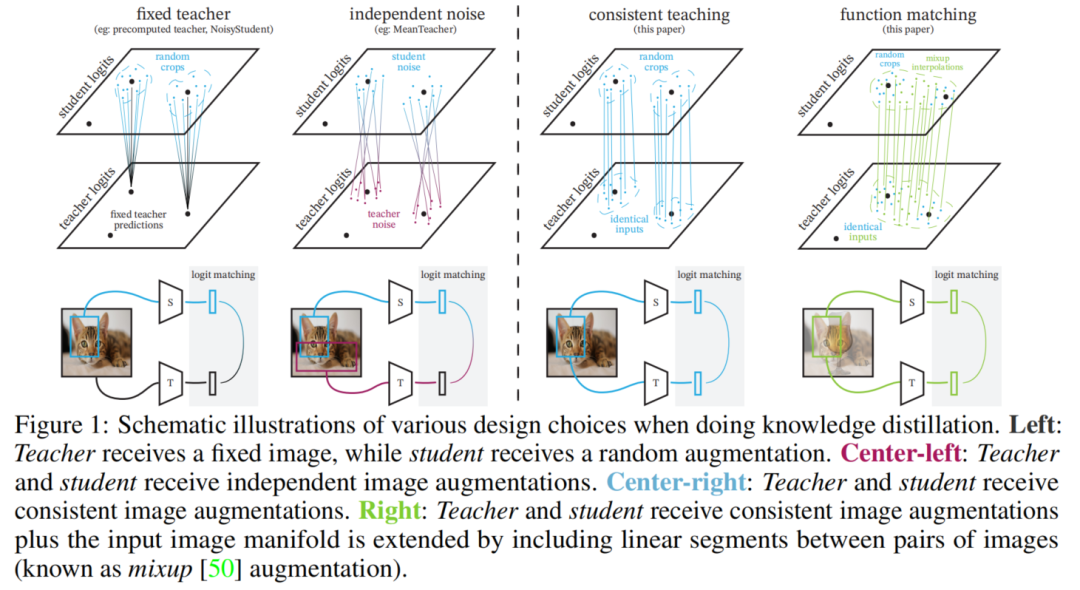 图1
图1密切遵循Hinton的原始蒸馏配置,发现如果操作正确,它惊人地有效;如图1所示作者将蒸馏解释为匹配教师和学生实现的函数的任务。通过这种解释发现对模型压缩的知识蒸馏的2个关键原则。
首先,教师和学生模型应该处理完全相同的输入图像,或者更具体地说,相同的裁剪和数据增强;
其次,希望函数在大量的支撑点上匹配,以便更好地推广。
使用Mixup的变体,可以在原始图像流形外生成支撑点。考虑到这一点,通过实验证明,一致的图像视图、合适的数据增强和非常长的训练计划是通过知识蒸馏使模型压缩在实践中工作良好的关键。
尽管发现明显很简单,但有很多种原因可能会阻止研究人员(和从业者)做出建议的设计选择。
首先,很容易预先计算教师对离线图像的激活量,以节省计算量,特别是对于非常大的教师模型;
其次,知识蒸馏也通常用于不同的上下文(除了模型压缩),其中作者推荐不同甚至相反的设计选择;
组后,知识蒸馏需要比较多的Epoch来达到最佳性能,比通常用于监督训练的Epoch要多得多。更糟糕的是,在常规时间的训练中看起来不理想的选择往往是最好的,反之亦然。
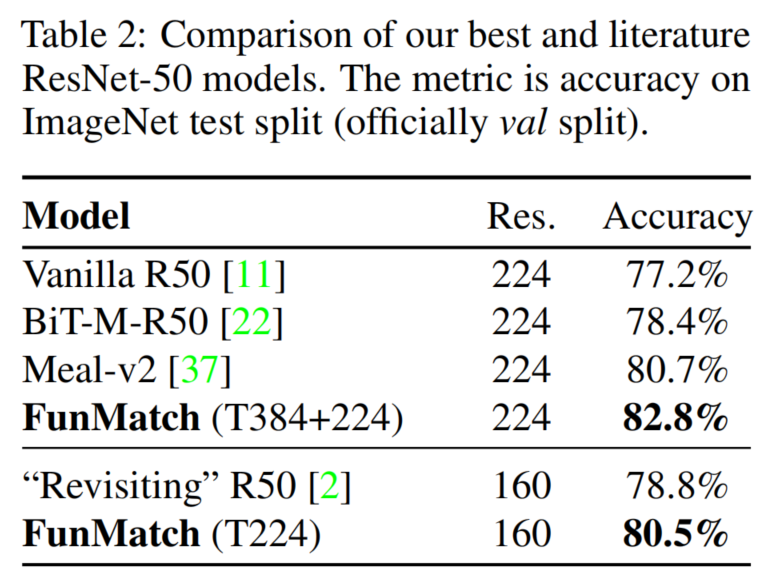
在本文的实证研究中,主要集中于压缩大型BiT-ResNet-152x2,它在ImageNet-21k数据集上预训练,并对感兴趣的相关数据集进行微调。在不影响精度的情况下,将其蒸馏为标准的ResNet-50架构(用GN代替BN)。还在ImageNet数据集上取得了非常强的结果:总共有9600个蒸馏周期,在ImageNet上得到了新的ResNet-50SOTA结果,达到了惊人的82.8%。这比原始的ResNet-50模型高出4.4%,比文献中最好的ResNet-50模型高出2.2%。
最后,作者还证明了本文的蒸馏方案在同时压缩和更改模型时也可以工作,例如BiT-ResNet架构到MobileNet架构。
2.1 Datasets, metrics and evaluation protocol
在5个流行的图像分类数据集上进行了实验:flowers102,pets,food101,sun397和ILSVRC-2012(“ImageNet”)。这些数据集跨越了不同的图像分类场景;特别是,它们的类的数量不同,从37到1000个类,训练图像的总数从1020到1281167个不等。
2.2 Teacher and student models
在本文中,选择使用来自BiT的预训练教师模型,该模型提供了大量在ILSVRC-2012和ImageNet-21k数据集上预训练的ResNet模型,具有最先进的准确性。BiT-ResNets与标准ResNets唯一显著的区别是使用了GN层和权重标准化。
特别地专注于BiT-M-R152x2架构:在ImageNet-21k上预训练的BiT-ResNet-152x2(152层,“x2”表示宽度倍数)。该模型在各种视觉基准上都显示出了优异的性能,而且它仍然可以使用它进行广泛的消融研究。尽管如此,它的部署成本还是很昂贵的(它需要比标准ResNet-50多10倍的计算量),因此该模型的有效压缩具有实际的重要性。对于学生模型的架构,使用了一个BiT-ResNet-50变体,为了简洁起见,它被称为ResNet-50。
2.3 Distillation loss
这里使用教师模型的和学生模型的之间的KL散度作为一个蒸馏损失来预测类概率向量。对于原始数据集的硬标签,不使用任何额外的损失:
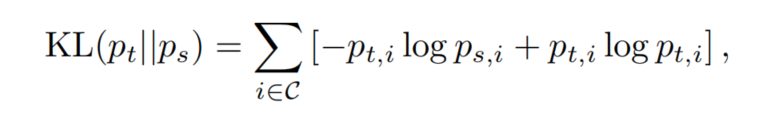
C是类别。这里还引入了一个温度参数T,用于在损失计算之前调整预测的softmax-probability分布的熵:

2.4 Training setup
为了优化,使用带有默认参数的Adam优化器训练模型。还使用了不带有Warm up的余弦学习率机制。
作者同时还为所有的实验使用了解耦的权重衰减机制。为了稳定训练,在梯度的全局l2范数上以1.0的阈值进行梯度裁剪。最后,除在ImageNet上训练的模型使用batch size为4096进行训练外,对其他所有实验都使用batch size为512。
本文的方案的另一个重要组成部分是Mixup数据增强策略。特别在“函数匹配”策略中中引入了一个Mixup变量,其中使用从[0,1]均匀抽样的较强的Mixup系数,这可以看作是最初提出的β分布抽样的一个极端情况。
作者还使用了““inception-style”的裁剪,然后将图像的大小调整为固定的正方形大小。此外,为了能够广泛的分析在计算上的可行(训练了数十万个模型),除了ImageNet实验,使用标准输入224×224分辨率,其他数据集均使用相对较低的输入分辨率,并将输入图像的大小调整为128×128大小。
3.1 “consistent and patient teacher”假说
在本节中,对介绍中提出的假设进行实验验证,如图1所示,当作为函数匹配时,蒸馏效果最好,即当学生和教师模型输入图像是一致视图时,通过mixup合成“filled”,当学生模型接受长时间的训练时(即“教师”很有耐心)。
为了确保假说的稳健性,作者对4个中小型数据集进行了非常彻底的分析,即Flowers102,Pets,Food101,Sun397进行了训练。

为了消除任何混杂因素,作者对每个精馏设定使用学习速率{0.0003,0.001,0.003,0.01}与权重衰减{,,,,以及蒸馏温度{1,2,5,10}的所有组合。
3.1.1.Importance of “consistent” teaching
首先,证明了一致性标准,即学生和教师看到相同的视图,是执行蒸馏的唯一方法,它可以在所有数据集上一致地达到学生模型的最佳表现。在本研究中,定义了多个蒸馏配置,它们对应于图1中所示的所有4个选项的实例化:
1 Fixed teacher
作者探索了几个选项,其中教师模型的预测是恒定的,为一个给定的图像。
最简单(也是最差的)的方法是fix/rs,即学生和老师的图像大小都被调整到224x224pixel。
fix/cc遵循一种更常见的方法,即教师使用固定的central crop,而学生使用random crop。
fix/ic_ens是一种重数据增强方法,教师模型的预测是1024种inception crops的平均值,我们验证了以提高教师的表现。该学生模型使用random crop。
2 Independent noise
用2种方式实例化了这种常见的策略:
ind/rc分别为教师和学生计算2种独立的random crop;
ind/ic则使用heavy inception crop。
3 Consistent teaching
在这种方法中,只对图像进行随机裁剪一次,要么是mild random cropping(same/rc),要么是heavy inception crop(same/ic),并使用相同的crop向学生和教师模型提供输入。
4 Function matching
这种方法扩展了consistent teaching,通过mixup扩展图像的输入,并再次为学生和教师模型提供一致的输入。为了简洁起见,将这种方法称为“FunMatch”。
3.1.2 Importance of “patient” teaching
人们可以将蒸馏解释为监督学习的一种变体,其中标签是由一个强大的教师模型提供的。当教师模型的预测计算为单一图像视图时,这一点尤其正确。这种方法继承了标准监督学习的所有问题,例如,严重的数据增强可能会扭曲实际的图像标签,而轻微的增强可能又会导致过拟合。
然而,如果将蒸馏解释为函数匹配,并且最重要的是,确保为学生和老师模型提供一致的输入,情况就会发生变化。在这种情况下,可以进行比较强的图像增强:即使图像视图过于扭曲,仍然会在匹配该输入上的相关函数方面取得进展。因此,可以通过增强来增加机会,通过做比较强的图像增强来避免过拟合,如果正确,可以优化很长一段时间,直到学生模型的函数接近教师模型的函数。
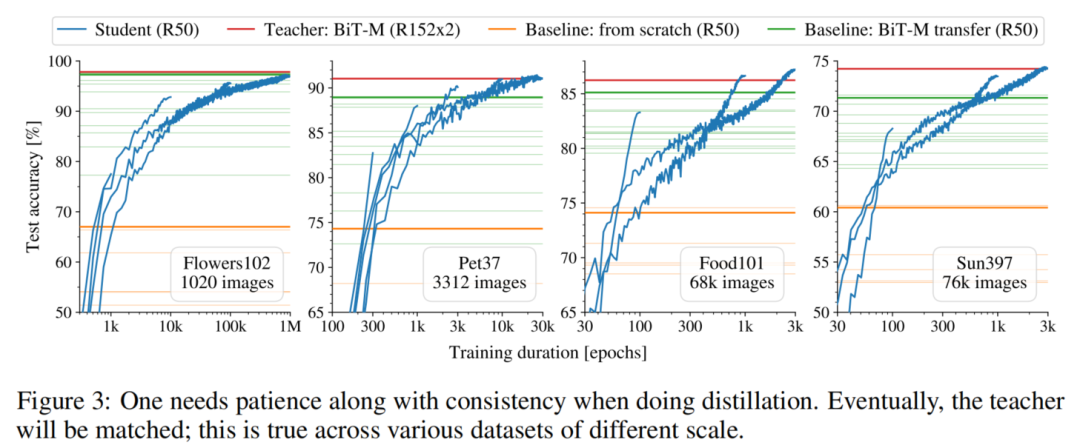
在图3中证实了作者的假设,对于每个数据集,显示了在训练最佳函数匹配学生模型时不同数量的训练Epoch的测试精度的变化。教师模型为一条红线,经过比在标准监督训练中使用的更多的Epoch后,最终总是能够达到。至关重要的是,即使优化了一百万个Epoch,也没有过拟合的迹象。
作者还训练和调整了另外2个Baseline以供参考:使用数据集原始硬标签从零开始训练ResNet-50,以及传输在ImageNet-21k上预训练的ResNet-50。对于这2个Baseline,侧重于调整学习率和权重衰减。使用原始标签从零开始训练的模型大大优于学生模型。
值得注意的是,相对较短的100个Epoch的训练结果比迁移Baseline差得多。总的来说,ResNet-50的学生模型持续地匹配ResNet-152x2教师模型。
3.2 Scaling up to ImageNet
基于对前几节的见解,作者还研究了所建议的蒸馏方案如何扩展到广泛使用和更具挑战性的ImageNet数据集。
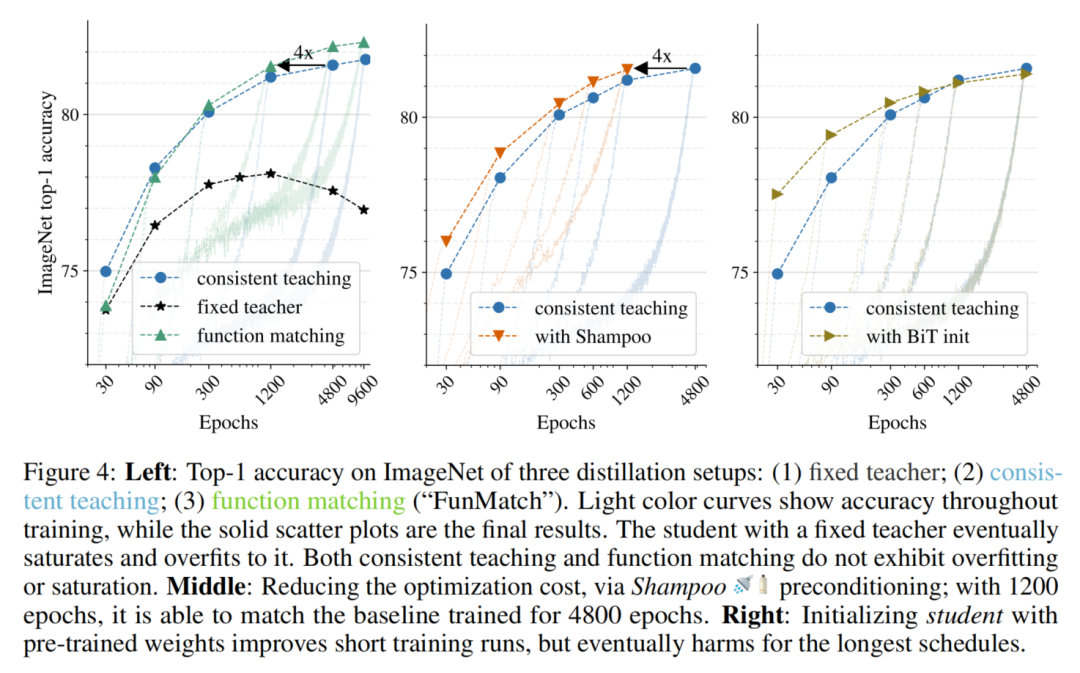
按照与之前相同的协议,在图4(左)中,报告了3种蒸馏设置的学生训练过程中的准确性曲线:
fixed teacher
consistent teaching
function matching
作为参考,基础教师模型达到83.0%的top-1。fixed teacher再次经过长时间的训练计划,并在600个Epoch后开始过度拟合。相比之下,consistent teaching方法会随着训练时间的增加而不断提高教学表现。由此可以得出结论,consistent是在ImageNet上进行蒸馏工作的关键,类似于前面讨论的中小型数据集上的结论。
与简单consistent teaching相比,function matching在短时间内的表现稍差,这可能是由于拟合不足造成的。但当增加训练计划的Epoch时,function matching的改进变得很明显:例如,只有1200个Epoch,它能够匹配4800个Epoch的consistent teaching性能,从而节省了75%的计算资源。最后,对于实验的最长的function matching运行,普通的ResNet-50学生架构在ImageNet上达到了82.31%的Top-1精度。
3.3 Distilling across different input resolutions
到目前为止,假设学生和教师都接收到相同的标准输入分辨率224px。但是,可以将不同分辨率的图像传递给学生和老师,同时仍然保持一致:只需在原始高分辨率上进行裁剪图像,然后为学生和教师模型调整不同的大小:他们的视图将是一致,尽管分辨率不同。这种洞察力可以用于向更好、分辨率更高的教师模型学习,也可以用于训练一个更小、更快的学生。
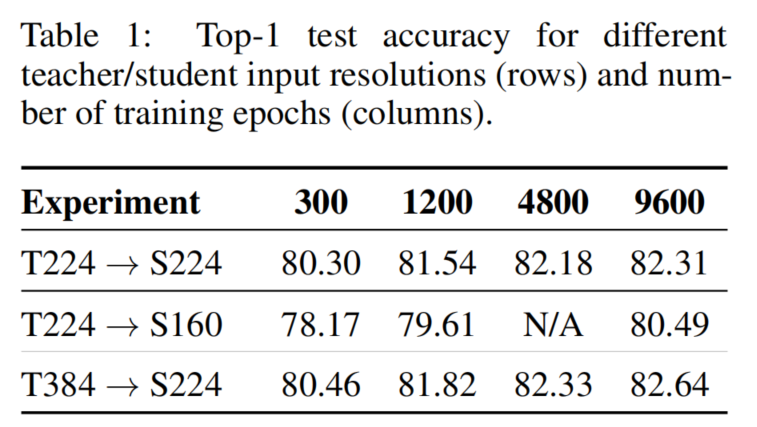 表1
表1作者主要研究了2个方向:首先,训练一个输入分辨率为160个像素的ResNet-50学生模型,同时保持教师模型的输入分辨率不变(224个像素)。这让模型速度提高了一倍,仍然达到了惊人的80.49%的 top-1 准确度(见表1),而在此分辨率下使用一系列修改后得到的最佳模型准确率为78.8%。
其次,在Big transfer之后,作者提取了一个在384px的分辨率下微调的教师模型(并达到83.7%的top-1准确率),这次让学生的分辨率保持不变,即使用224px的输入分辨率。如表1所示,与使用224像素分辨率教师相比,提供了一致的全面改进。
3.4 Optimization: A second order preconditioner improves training efficiency
作者观察到,由于长时间的训练计划,优化效率成为“函数匹配”视角的精馏方案的一个计算瓶颈。直观地说,作者认为优化困难源于这样一个事实,即用多变量输出比固定的图像级标签来拟合一般函数要困难得多。因此,作者进行了初步探索,是否更强大的优化器可以更好地完成任务。
为此,我们使用二阶预处理器将底层优化器从Adam更改为Shampoo。在图4(中)中观察到Shampoo达到了相同的测试精度,相比Adam使用的4800个Epoch,Shampoo仅用了1200个Epoch就达到了,并且步骤时间开销最小。而且,总的来说,在所有实验设置中都观察到对Adam的持续改进。
3.5 Optimization: A good initialization improves short runs but eventually falls behind
受迁移学习的启发,良好的初始化能够显著缩短训练成本并实现更好的解决方案,作者尝试用预训练的BiT-M-ResNet50权重初始化学生模型,结果如图4(右)所示。
当蒸馏持续时间较短(30个epoch)时,BiT-M初始化提高了2%以上。然而,当训练计划足够长时,差距就会缩小。从1200个epoch开始,从头开始训练1200个epoch与BiT-M初始化的学生模型相匹配,并在4800个epoch略超过它。
3.6 Distilling across different model families
除了为学生和老师使用不同的输入分辨率之外,还可以使用不同的架构,这使模型能够有效地从更强大和更复杂的教师模型那里转移知识,同时保持简单的架构,如MobileNet。
作者通过2个实验证明了这一点。首先,使用2个模型作为教师模型,并表明这进一步提高了性能。其次,训练了一个MobileNet v3学生模型,并获得了迄今为止最好的MobileNet v3模型。
作为学生模型,使用MobileNet v3(Large),对于大多数实验,选择使用GroupNorm(默认为8组)而不是BatchNorm的变体。没有使用原始论文中使用的任何训练技巧,只是进行函数匹配。

学生模型在 300个epoch后达到74.60%,在1200个epoch后达到76.31%,从而产生了最好的MobileNet v3模型。
创建一个模型,该模型由默认教师模型在224像素分辨率和384像素分辨率的平均logits组成。这是一种不同但密切相关的教师模型,而且更强大但也更慢。在尝试的每个时间段内,这个教师模型的学生都比默认的教师模型的学生好,并且在9600次蒸馏之后,达到了82.82%的新的最先进的top-1 ImageNet准确率。
3.7 Comparison to the results from literature
3.8 Distilling on the "out-of-domain" data
通过将知识蒸馏看作是“函数匹配”,可以得出一个合理的假设,即蒸馏可以在任意的图像输入上进行。到目前为止,在论文中,只使用关于感兴趣任务的“域内”数据。在本节中,将研究这个选择的重要性。
对pets和sun397数据集进行实验。使用本文的蒸馏方案使用来自food101和ImageNet数据集的域外图像来蒸馏pets和sun397模型,并且对于参考结果,还使用来自pets和sun397数据集的“域内”图像进行蒸馏。
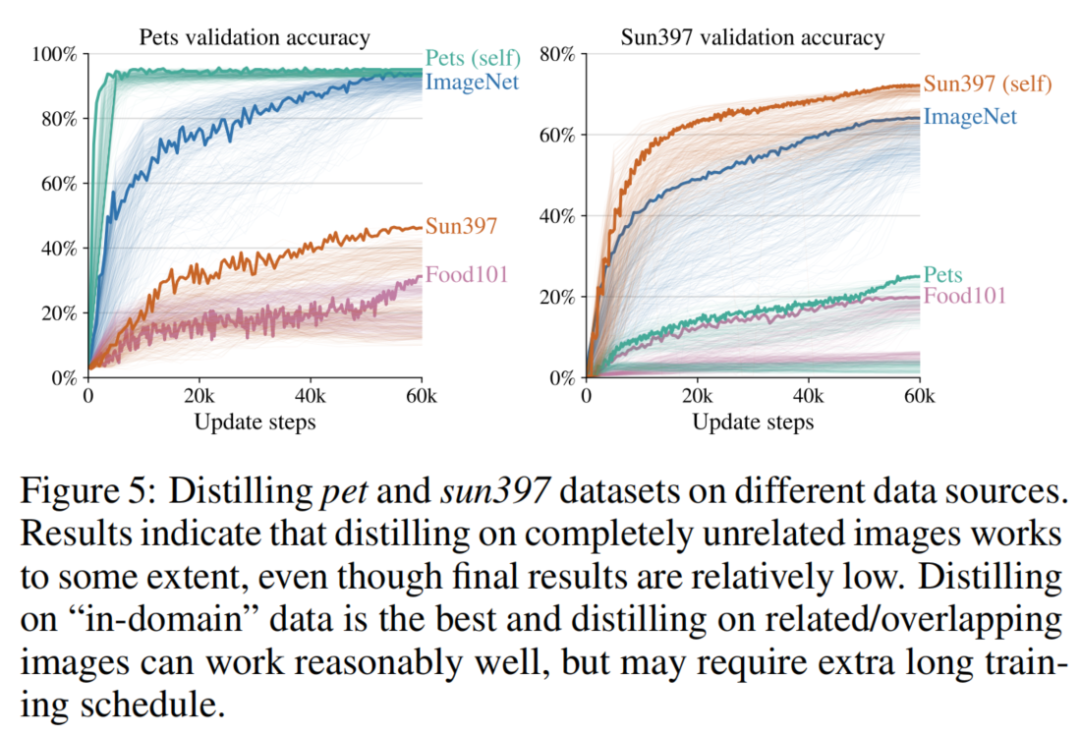
图5总结了结果。首先,观察到使用“域内”数据进行蒸馏效果最好。有点令人惊讶的是,即使图像完全不相关,蒸馏在某种程度上仍然有效,尽管结果会变糟。例如,这意味着学生模型可以通过仅查看标记为宠物品种的食物图像(轻柔地)以大约30%的准确率来学习对宠物进行分类。
最后,如果蒸馏图像与实际的“域内”图像(例如Pets和ImageNet,或sun397和ImageNet)有些相关或重叠,那么结果可能与使用“域内”一样好(或几乎一样好)数据,但可能需要超长的优化周期。
3.9 Finetuning ResNet-50 with mixup and augmentations
为了确保观察到的最先进的蒸馏结果不是精心调整的训练设置的人工产物,即非常长的时间表和积极的Mixup增强,训练了相应的Baseline ResNet-50模型。更具体地说,重用了精馏训练设置,在ImageNet数据集上进行监督训练,而不产生精馏损失。为了进一步加强Baseline,另外尝试了带有动量的SGD优化器,众所周知,这通常比Adam优化器对ImageNet工作得更好。
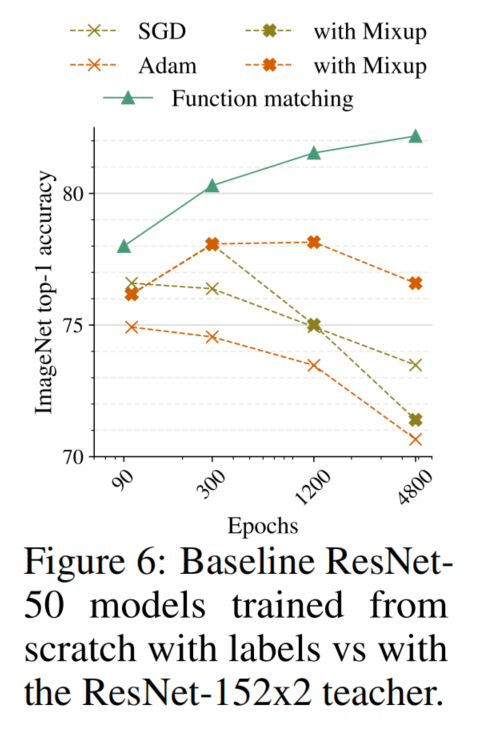 图6
图6结果如图6所示。可以观察到,有标签和没有蒸馏损失的训练会导致糟糕的结果,并开始过度拟合较长的训练时间表。因此,得出结论,蒸馏是必要的。
[1].Knowledge distillation:A good teacher is patient and consistent








