绑定手机号
确认绑定









Mobileye痛失宝马大客户后,业内一致认为Mobileye掉队了,昨天Mobileye公布了其最新旗舰Ultra EyeQ芯片,Ultra EyeQ将取代EyeQ6H的地位,同时也提前1-2年到2023年提供样片。
UltraEyeQ芯片是Mobileye完全不同前任的设计风格,有着鲜明的英特尔痕迹。

图片来源:互联网
Ultra EyeQ可能采用台积电5纳米工艺制造,AI算力176TOPS,FP32算力4.2TFLOPS,ISP带宽2.4GPxl/s,功耗低于100瓦。指标来看,UltraEyeQ不算出彩,唯一能超过英伟达Orin的地方是FP32算力或者说GPU算力,Orin略低,为4.1TFLOPS。如果GPU也做AI加速,那AI算力是192.4TOPS,跟高通的AI加速器算力差不多。CPU方面很特殊,一般都是ARM架构,但Ultra EyeQ是RISC-V的,且是比较少见的多线程CPU,12核24线程,ARM架构里面只有很少人听说过的A65AE使用了多线程设计,大部分x86的CPU都是多线程设计,Mobileye背靠英特尔,做多线程设计自然轻松。多线程在某些场合下依靠设计良好任务分割完善的软件可以实现超越单线程的性能,但单线程任务时性能有所降低,自动驾驶的感知阶段,多线程任务较多,而决策阶段较少。Ultra EyeQ在多线程任务上有可能超越英伟达的Orin,同时Ultra EyeQ应该主打性价比。价格估计在100美元左右,甚至更低。

图片来源:互联网
如今SoC的设计更像是搭积木,买各种各样的IP然后自己整合在一起,这不仅降低开发周期,也降低开发成本。更进一步,IP也不需要,可以直接买裸晶粒做Chiplet小芯片,英特尔就非常擅长,英特尔和AMD是小芯片的高手,英伟达也将在2022年跟进。
Ultra EyeQ的关键模块有12核RISC-V的CPU,英特尔的Xe GPU内核,两个通用加速器,两个AI加速器,一个通用加速器采用ARM的NEON指令集,使用SIMD加速矢量运算;一个采用VLIW,以近似DSP的方式加速。
先来看CPU,这是全球首款高算力RISC-V的CPU。
阿里云、Andes(中国台湾晶心)、成为资本、Futurewei、谷歌、华为、中科院计算机所、中科院软件研究所、RIOS、RIVOS、中兴、赛昉 (StarFive)、SiFIVE、希姆计算、Syntacore、清华紫光、VENTANA MICRO、西部数据是RISC-V联盟的顶级会员,中国企业居多。
在2010年,伯克利研究团队要设计一款CPU,然而,英特尔对X86的授权卡的很严,ARM的指令集授权很贵,MIPS、SPARC、Open Power也都需要各自的公司授权。在选择很有限的情况下,伯克利的研究团队决定从零开始设计一套全新的指令集。而被很多媒体大肆宣扬也令人振奋的是,伯克利的研究团队4名成员仅用了3个月就完成了RISC-V的指令集开发。目前,该团队已完成了基于RISC-V指令集的顺序执行的64位处理器核心(代号为Rocket),并前后基于45nm与28nm工艺进行了12次流片。Rocket芯片主频1GHz,与ARM Cortex-A5相比,实测性能较之高10%,面积效率高49%,单位频率动态功耗仅为Cortex-A5的43%。在嵌入式领域,Rocket已经可以和ARM争市场了。
RISC-V指令集是基于精简指令集计算(RISC)原理建立的开放指令集架构(ISA),RISC-V是在指令集不断发展和成熟的基础上建立的全新指令。RISC-V指令集完全开源,设计简单,易于移植Unix系统,模块化设计,完整工具链,同时有大量的开源实现和流片案例,已在社区得到大力支持。目前RISC-V的处理器都比较低端,主要面向家用电器和工控及边缘运算领域。

图片来源:互联网
英特尔与SiFIVE关系密切,一直传言英特尔要20亿美元收购SiFIVE,2021年6月两者达成合作,英特尔使用SiFIVE的P550内核构建Horse Creek平台,SiFIVE使用英特尔先进的7纳米技术制造芯片。这也是Ultra EyeQ从MIPS平台转向RISC-V平台的原因,背后有英特尔的影子,也省了一笔架构授权费。Ultra EyeQ应该使用P550内核或P650内核,短期内没有人能超越SiFIVE的水平,高性能RISC-V CPU仅此一家,没得选。同时台积电也提供5纳米P550内核的Die,可以快速组成Chiplet。
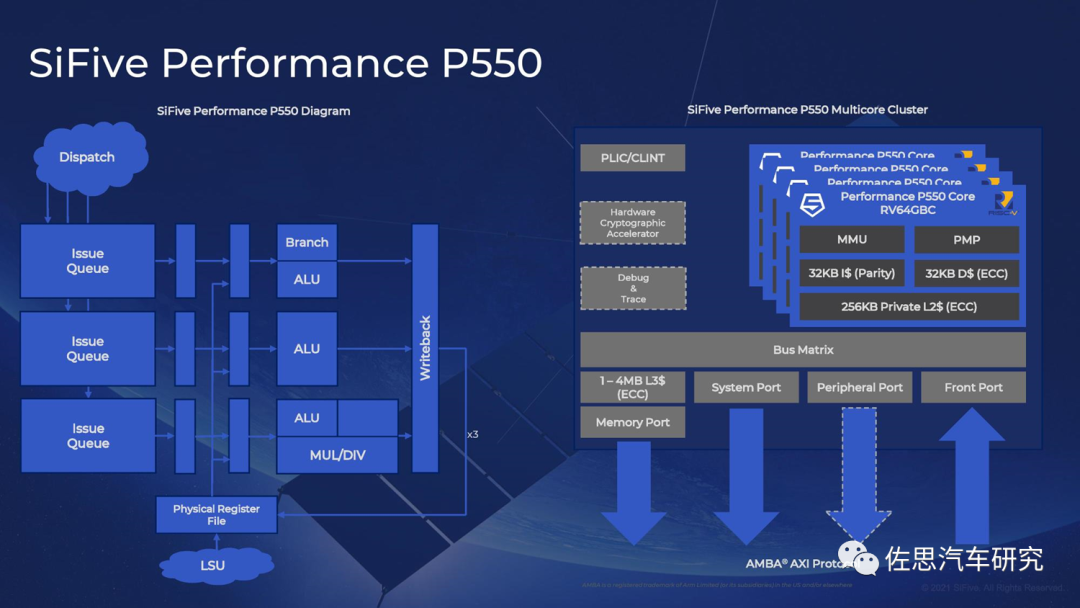
图片来源:互联网
P550支持3个簇,每个簇4个内核,也就是12个内核。L1指令与数据缓存都是32KiB,每个核心L2缓存为256KiB,L3缓存是8MiB。
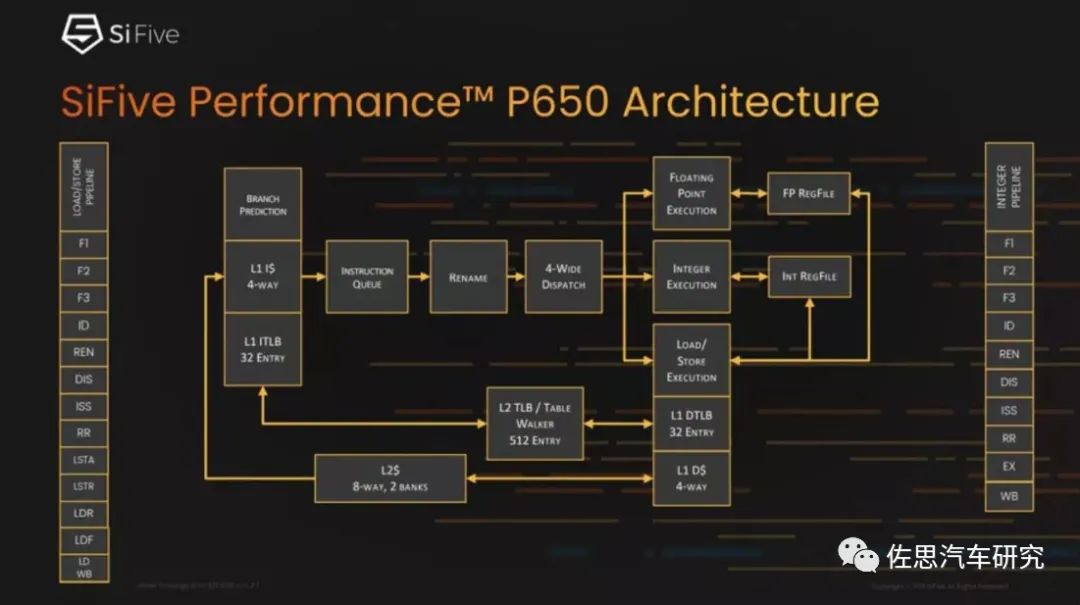
图片来源:互联网
SiFive于2021年12月底推出了P650内核,性能更强,跟P550比实际就是解码宽度从3位增加到4位。
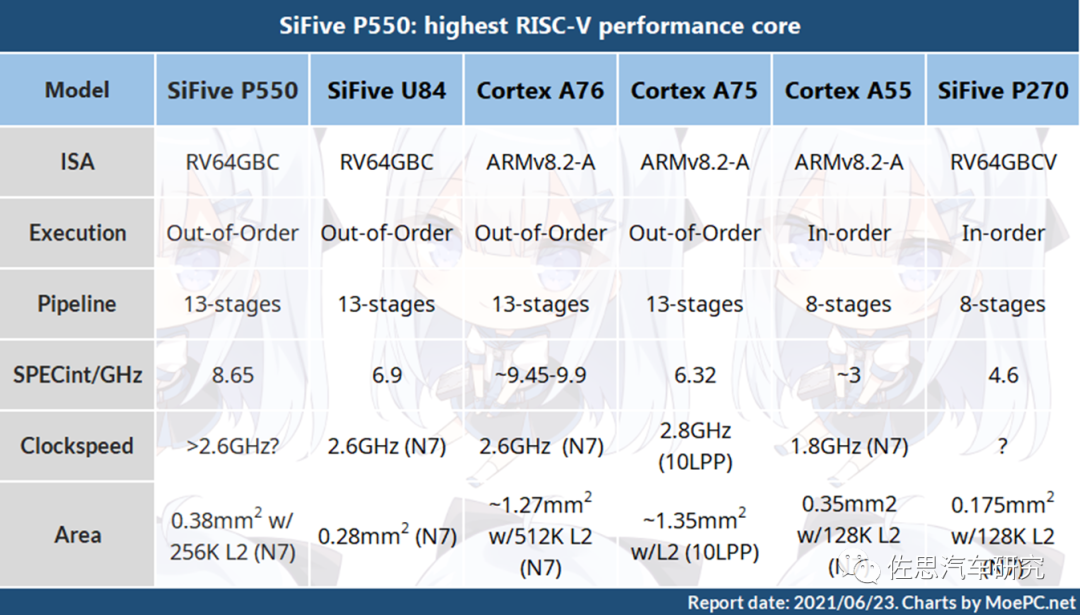
图片来源:互联网
P550介于ARMCortex A75和A76之间,不过面积要小许多,意味着成本也低很多。P650的SPECint/GHz跑分大约为11以上,近似于ARM Cortex A77。面积也稍大,自然成本也略高些。
GPU方面,市面上可选择的IP供应商也只有ARM,ARM目前最顶级的GPU是MALI G710。
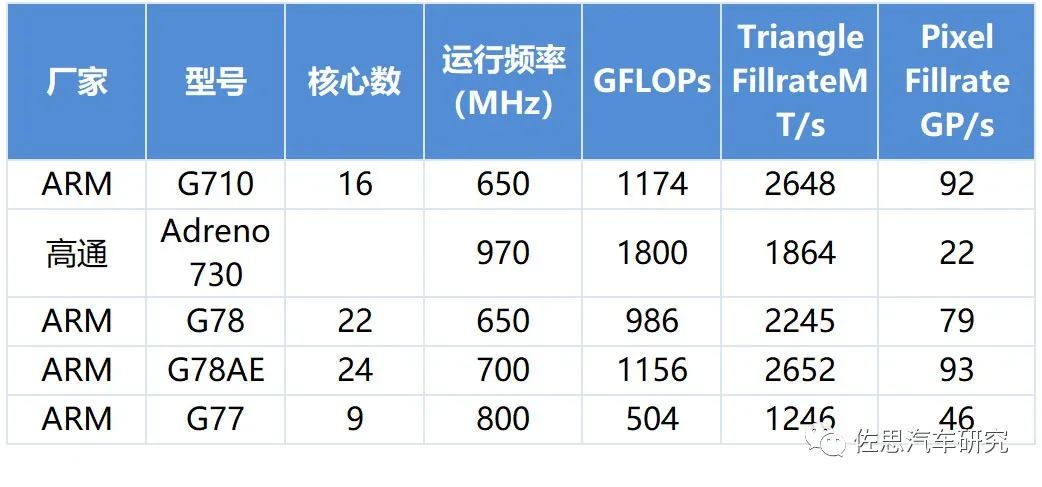
G710最多16核,且频率一般不超过800MHz,意味着Ultra EyeQ不会选择ARM的GPU。背靠英特尔大树,自然选英特尔。
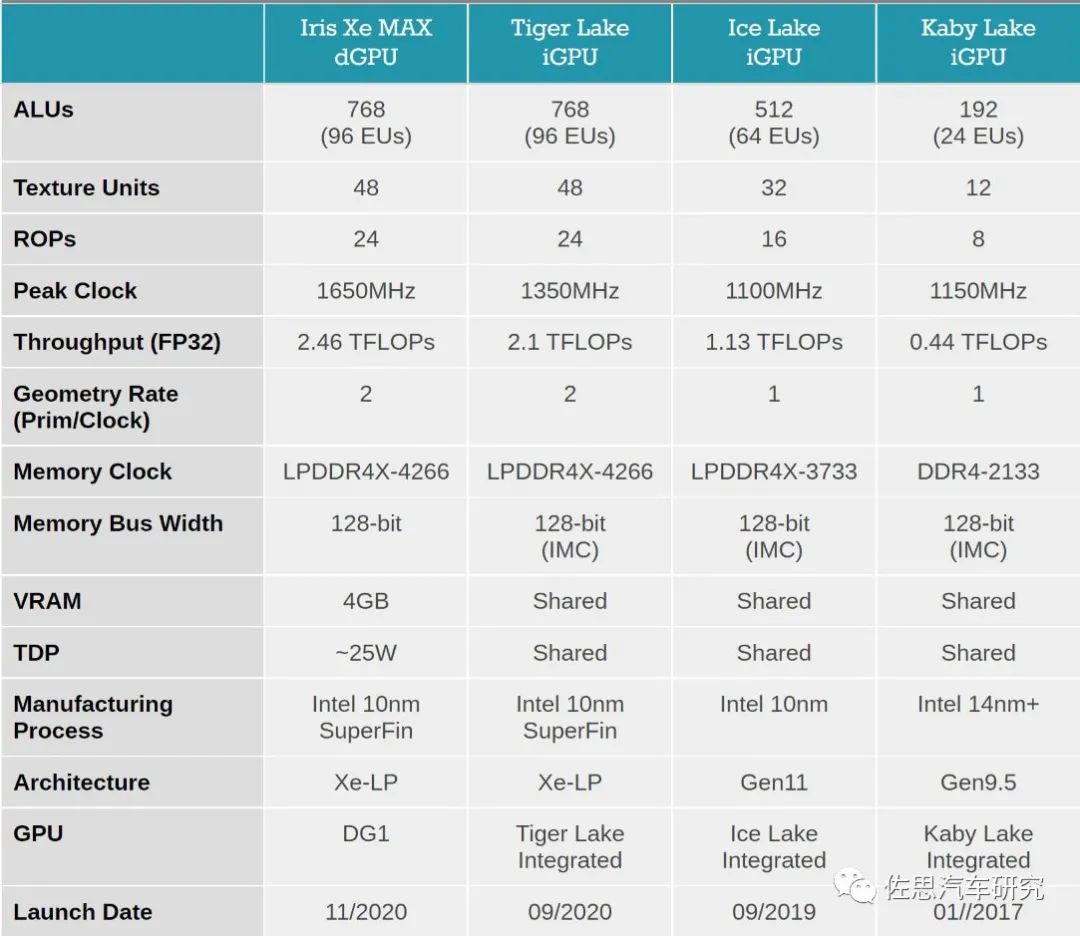
英特尔在2020年推出独立GPU,其中11代笔记本电脑处理器就内置了Xe-LP GPU。
图片来源:互联网
英特尔Xe系列显卡处理单元可任意配置,最高可做到15360个ALU,算力达到42TFLOPS,1536个就是4.2TFLOPS,UltraEyeQ应该就是这个配置。英伟达Orin是2048个CUDA核,比英特尔少,不过英伟达的GPU频率是1000MHz,比英特尔要低。但英伟达的GPU一向是偏大核设计,所占面积比较大,成本比较高,英特尔的成本要低的多。
通用加速器主要针对特定算法加速,主要针对激光雷达、毫米波雷达以及超声波雷达,主要算子有12个MPC即Multithreaded Processing Cluster,多线程处理簇。4个可编程宏阵列PMA(Programmable Macro Array),类似FPGA,主要对应毫米波雷达的FFT傅里叶变换。12个VMP(Vector MicrocodeProcessors,即矢量微码处理器)。
VMP的核心是SIMD。为增加通用性,引入了ARM的NEON指令集,这是专门针对矢量运算SIMD架构设计的指令集。
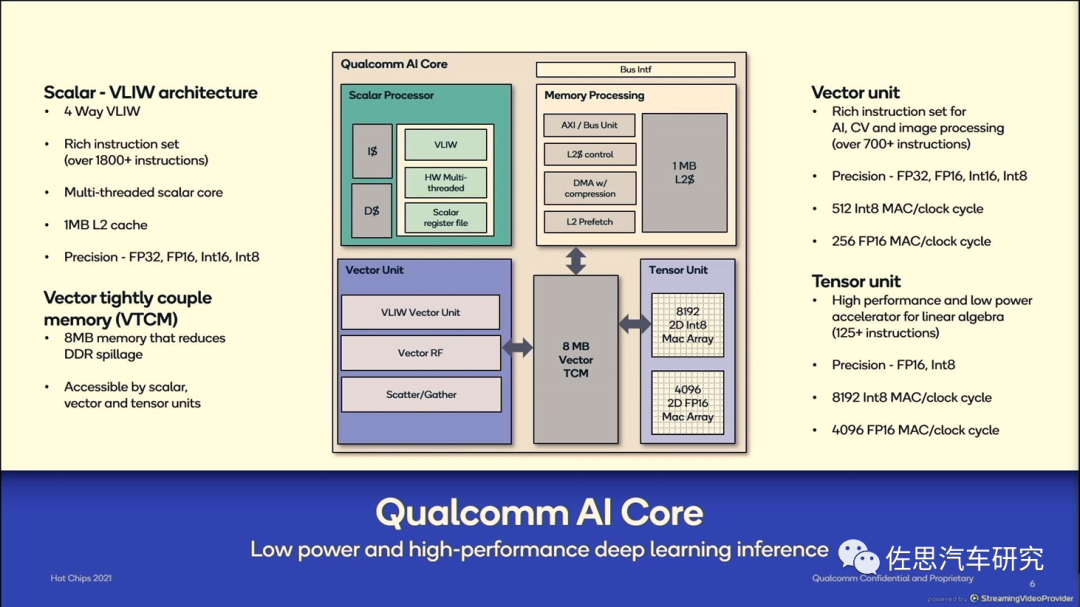
AI加速器方面,ARM主要是模仿DSP,核心技术就是VLIW。
依据指令长度的不同,指令系统可分为复杂指令系统(Complex Instruction Set Computer,简称CISC)、精简指令系统(Reduced Instruction Set Computer,简称RISC)和超长指令字(Very Long Instruction Word,简称 VLIW)指令集三种。CISC中的指令长度可变;RISC中的指令长度比较固定;VLIW本质上来讲是多条同时执行的指令的组合,其“同时执行”的特征由编译器指定,无须硬件进行判断。超标量处理器是动态调度,由硬件发现指令级并行机会并负责正确调度,VLIW是静态调度,由编译器发现指令级并行机会并负责正确调度。
VLIW 结构的最初思想是最大限度利用指令级并行(Instruction Level Parallelism,简称ILP ),VLIW的一个超长指令字由多个互相不存在相关性(控制相关、数据相关等)的指令组成,可并行进行处理。VLIW 可显著简化硬件实现,但增加了编译器的设计难度。由于AI和DSP领域,数据基本上是数据流,没有跳转,因此特别适合静态的VLIW,近期有不少AI芯片使用VLIW架构。
VLIW多采用哈佛架构,没有存储墙的问题,实际性能与理论性能非常接近。因为VLIW为了进行这些数据流密集计算任务,添加了一些固定算法指令,比如单周期乘加指令、逆序加减指令(FFT时特别有用,不是ARM的那种逆序),块重复指令(减少跳转延时)等等,甚至将很多常用的由几个操作组成的一个序列专门设计一个指令可以一周期完成(比如一指令作一个乘法,把结果累加,同时将操作数地址逆序加1),极大提高了信号处理的速度。由于数字处理的读数、回写量非常大,为了提高速度,采用指令、数据空间分开的方式,以两条总线来分别访问两个空间,同时,一般在内部有高速RAM,数据和程序要先加载到高速片内RAM中才能运行。为提高数字计算效率,牺牲了存储器管理的方便性,对多任务的支持要差的多,所以不适合作多任务控制作用。
图片来源:互联网
高通AI加速器也有使用VLIW,华为也是近似VLIW的技术。
最后用缓存一致性总线将这些模块联合起来,英特尔在图片中特别点出了Cache Coherency Fabric。在一个多处理器系统中,缓存和内存池可能对同一份数据有多份副本,如何保证这些副本的一致性(Coherency)是个必须严肃对待的问题。可以纯软件来处理这个问题,利用cache操作指令,但开销巨大十分复杂,而且操作系统的内存模型就需要全部改变,这对X86体系甚至绝大多数体系都是不能接受的。所以绝大多数计算机体系都是靠硬件来完成Cache Coherency的,硬件会自动保证各个副本的一致性,不需要软件操心。常规的做法是加一个Snoop偷窥过滤器。在内存控制器端;Cache Agent (CA),在L3 Cache端。他们都在Ring bus上监听和发送snoop消息。这种模型叫做Bus snooping模型,与之相对的还有Directory模型。
但是这种只解决芯片内部L3缓存一致性的问题,但主存和设备内存之间特别是Chiplet各Die之间的割裂问题远远没有得到解决,它们的地址不能统一编址,缓存一致性也不能保证。于是出现了各种标准,有以IBM牵头的OpenCAPI,ARM为代表支持的CCIX,英特尔为代表的CXL,AMD为代表的Gen-Z,英伟达的Nvlink。
Mobileye自然得支持英特尔,也就是CXL。
Compute Express Link简称CXL,2019年3月由英特尔牵头成立。

图片来源:互联网
CXL的顶级会员包括AMD、阿里、ARM、思科、戴尔、谷歌、惠普、华为、IBM、英特尔、Facebook(Meta)、微软、英伟达、Rambus、Xilinx。
除了推出旗舰产品外,Mobileye还推出两款打价格战的产品,分别是EyeQ6L和EyeQ6H,EyeQ6L是目前Mobileye主力产品EyeQ4的继任者,面积只有EyeQ4的55%,也就是说硬件成本降低了45%,价格估计在30美元上下,EyeQ6H则是L2+产品,内部包含两个EyeQ5。

最先表态支持Mobileye的是吉利旗下的极氪。Mobileye是否能再续辉煌,让我们拭目以待。








