绑定手机号
确认绑定









2022年的CVPR论文在月初就放榜了,共有2067篇论文被接收。
今天,给大家介绍几个,首先开始的好玩的算法。
算法的模型模型DualStyleGAN。
给定真人图片A:
 图片A
图片A再给一张图片B,就是要改变的风格:
 图片B
图片B算法图片A根据图片B的进行风格风格迁移,生成图片C:
 图片C
图片C这个效果还不错吧?
就可以根据自己喜欢的角色,对自己的风格进行这样的动漫风格迁移了。
一起看下更多的算法效果:




第一列原始图像,第二列参考的风格,第三列算法生成的效果。
算法,可以给一些有这种需求的场景,提供一些用户喜欢的漫画风格,生成自己喜欢的应用程序。
DualStyleGAN最初的算法,已经获得了近千丈300的明星。
项目地址:
https://github.com/williamyang1991/DualStyleGAN
算法运行官方提供了方法。
没有编程基础的小伙伴,可以选择体验Web网页。
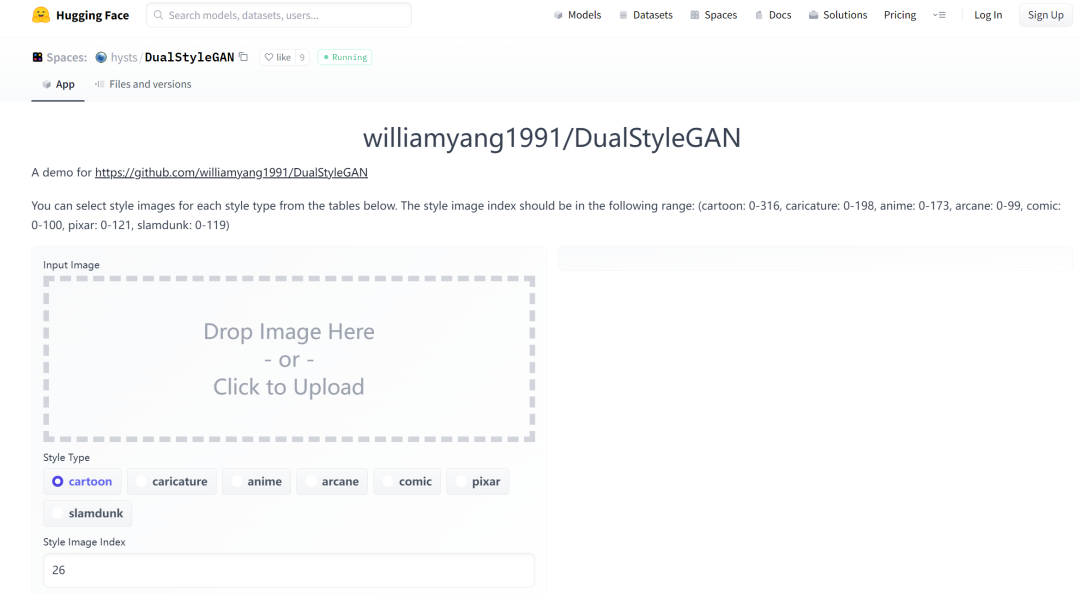
https://huggingface.co/spaces/hysts/DualStyleGAN
上传图片自动体验。
就是 Colab 的另外环境和本地类型。
Colab不需要自己安装可以直接依赖,有“梯子”打开运行。
https://colab.research.google.com/github/williamyang1991/DualStyleGAN/blob/master/notebooks/inference_playground.ipynb
想本地测试的小伙伴也可以就地部署,官方提供了 Conda 环境,直接创建一个虚拟环境的学习。
conda env create -f ./environment/dualstylegan_env.yaml
详细的内容,各位小伙伴直接README看吧。
再放听最后的效果。

看我的小伙伴,应该经常看到我写的文章的NÜWA(女娲)算法。
要今天介绍的算法RQ-VAE Transformer在文字转图片任务上效果更好。
任务就是根据一段文字描述,生成描述的图片。
译文:
A cheeseburger in front of a mountain range covered with snow.
雪山前的芝士堡。

算法根据我们的文字描述,生成的图片。
再如:
a cherry blossom tree on the blue ocean.
蓝色上海洋的樱花树。

算法主要分为两个阶段:RQ-VAE和RQ-Transformer。
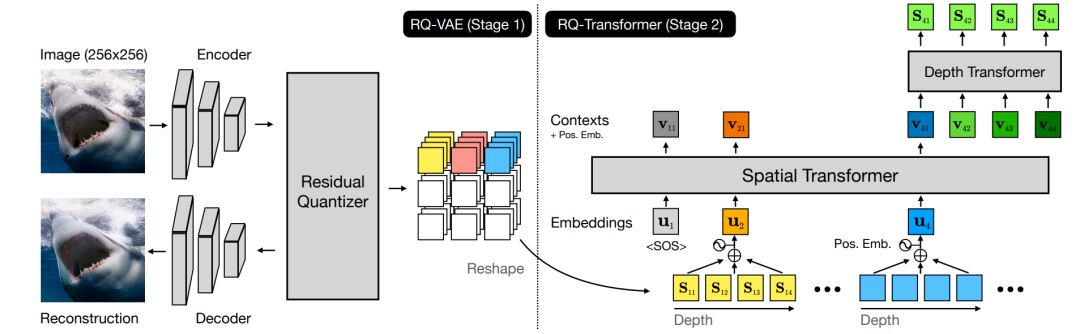
前者负责编码,后者负责生成。
算法第一名:
项目地址:
https://github.com/kakaobrain/rq-vae-transformer
本项目只支持本地环境,项目库可以直接根据需要requirements进行安装。
pip install -r requirements.txt
大家可以去下,有点反效果。

DeepFake 换脸技术越来越多。
换脸的图片和视频都太逼真了,肉眼识别严重。
VFD通过技术手段,可以帮助我们分析图片的真假。
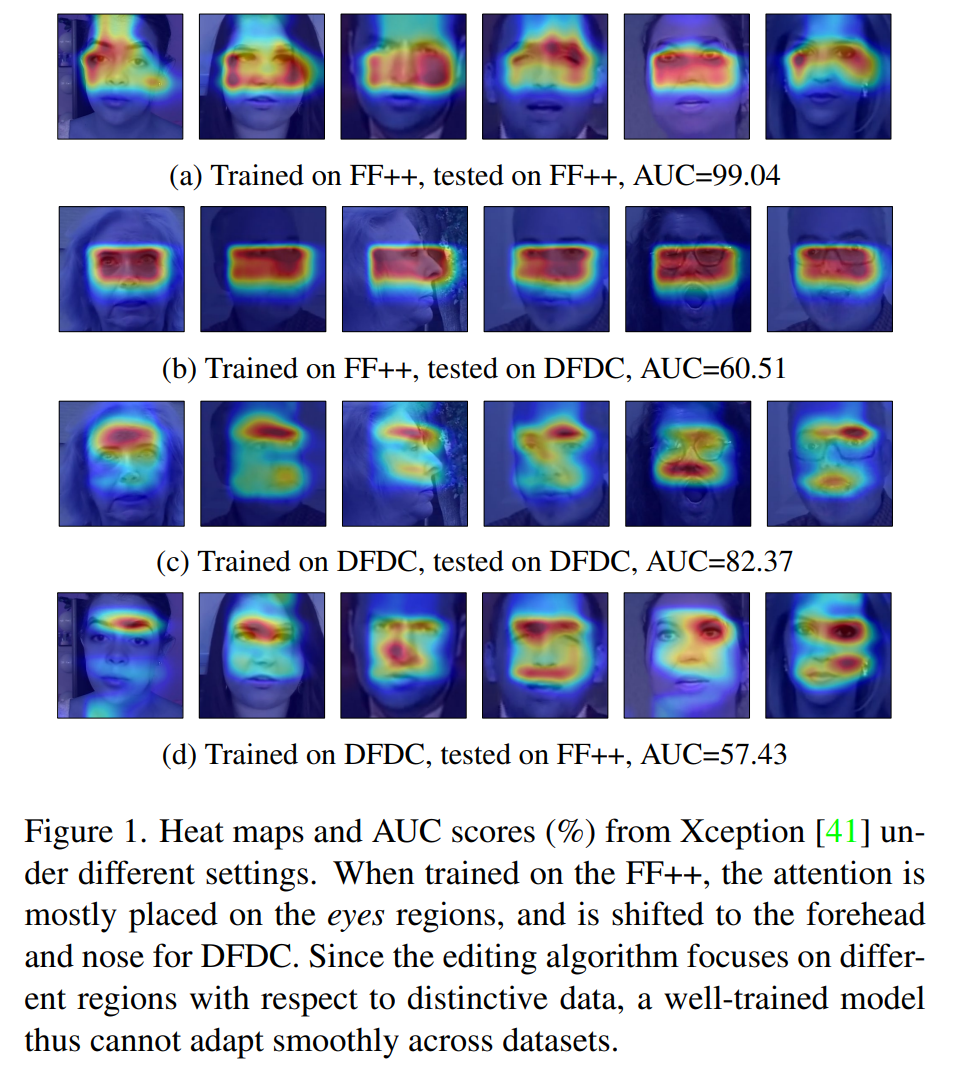
它也是2022年的CVPR,初心。
效果,大家就自己测试一下吧。
项目地址:
https://github.com/xaCheng1996/VFD








