绑定手机号
确认绑定










近些年,虚拟主播越来越火,虚拟人物的表演受到越来越多人的喜爱。驱动3D虚拟人物根据音乐跳舞也成为了非常热门的研究课题。
然而,想要自动化地为一段给定的音乐配舞仍然非常困难。其中难点有两个:
第一,舞蹈在空间上有一定规则和范式,并非是所有所有物理上可行的 3D 人体姿势都适用于舞蹈。舞蹈通常有着对身体有更严格要求的姿态标准,并且要具有表现力和感染力。我们可以随意产生一段人体姿态,但如果生成的姿态东倒西歪,就无法达到舞蹈的标准。
第二,生成的舞蹈动作,要在时间上同音乐保持连贯。舞蹈动作应该保持流畅,且能与不同节拍的音乐保持节奏一致。
大多数现有的舞蹈生成研究都试图设计一个巧妙的神经网络,把音乐信号直接映射到高维连续空间中的3D人体关键点序列,但是实践中通常不够稳定,比如经常会出现僵住或轻微的乱晃。这是因为,这些映射的目标空间,没有被显示地约束为符合舞蹈标准的子空间,因此容易回归到不符合舞蹈标准的姿态。
为了达到舞蹈的空间姿态标准,一些研究工作收集了很多真实舞蹈动作的片段,并通过拼接这些片段,编排成新的舞蹈。虽然这些方法可以通过直接操作真实数据保证生成的舞蹈的空间质量,但收集、剪裁这些舞蹈片段需要巨大的人工工作量。更关键的是,因为每一段舞蹈片段的时长、速度以及对应音乐的节奏是固定的,因此,没有办法复用于其他速度和节奏的音乐。比如,对应4/4拍音乐的片段可能无法被用于3/4拍的音乐,每分钟80拍的没法适用于每分钟60拍的。对于不同速度和节奏的音乐,这种方法就很难保证上述的时间一致性。
针对这两个难点,我们提出了一个“两阶段”的编舞框架Bailando。在第一阶段,我们利用量化自编码器(VQ-VAE)将符合空间标准的舞姿编码和量化到一个名为“舞蹈记忆”的编码本中;在第二阶段,我们利用生成预训练Transformer(GPT)将音乐转换为视觉上令人满意的舞蹈。我们还进一步通过引入评论家网络给生成的舞蹈打分,以指导 GPT 编排出与背景音乐节奏具有时间一致性的舞蹈动作。
1. 针对舞蹈序列的VQ-VAE和编舞记忆
与之前的方法不同,我们不学习从音频特征到 3D 关键点序列的连续域的直接映射。相反,我们先让神经网络“观看”大量的舞蹈数据,自己从里面“总结”出有意义的舞蹈元素,并且记录下来成为“编舞记忆”。编舞记忆中,每个元素都是从专业舞蹈中提取的符合空间要求的标准舞姿。具体来说,我们设计了一个针对人体姿态序列的VQ-VAE(Vector Quantized Variational Auto-Encoder)网络,对舞蹈数据的姿态序列进行编码和量化到一个编码本Z中。
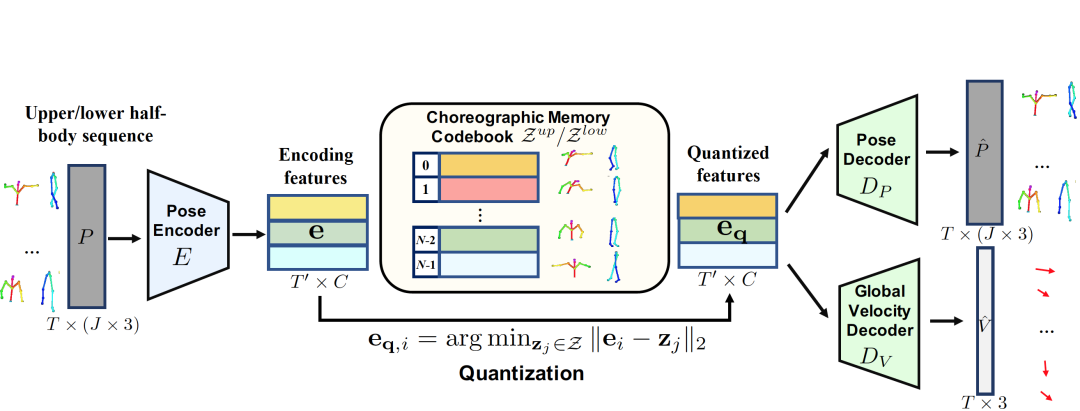
Z表示VQ-VAE的量化编码本,即“编舞记忆”,其中每一个元素都代表着一个标准的舞姿。为了使舞蹈记忆能涵盖更广泛的舞蹈动作,我们对舞蹈动作的上下身用独立的VQ-VAE进行学习,分别得到上下半身的编码本,并对上下半身进行组合式的拼接。我们还单独学习一个网络分支Dv,用于预测人体关键点的整体位移。
训练VQ-VAE的损失函数分为:
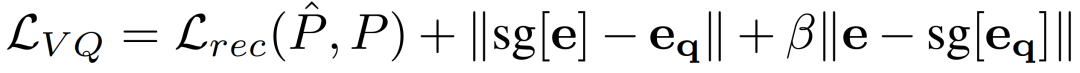
其中,重构函数不仅考虑到对关键点位置P的重构,还考虑到对一阶(速度)和二阶(加速度)导数的重构。
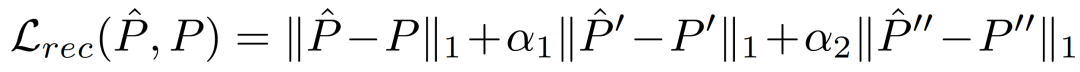
2. 动作GPT (motion GPT)
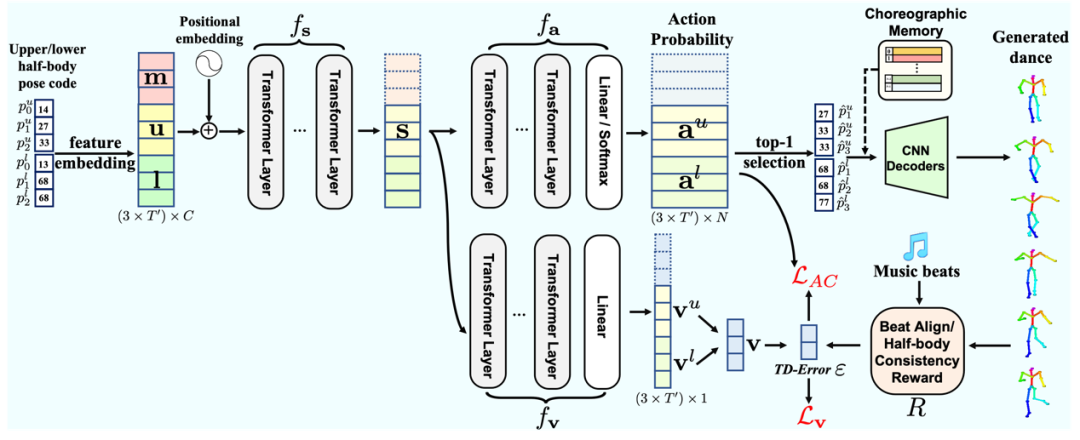
在我们从舞蹈数据中总结出了标准的舞姿库“编舞记忆”后,编舞的任务就变成了对音乐的每一时刻,选择一个合适的舞姿与之对应。这一步我们用到了GPT(Generative Pretrained Transformer)。

对于每一时刻t,GPT根据0到t-1时刻的音乐(m)、上半身(u)和下半身(l)信息来预测t时刻的上、下半身舞姿,并对每一个存在编舞记忆中的舞姿计算一个概率。而GPT的学习则是通过对预测的概率与真实动作之间的Cross-Entropy损失函数进行优化。
3. “演员-评论家”(Actor-Critic)学习
GPT的训练是直接而有效的。然而,这个框架有一个弊端,即很难向损失函数中加入一些人工定义的正则化项(比如希望让生成的舞蹈更加符合音乐节拍),因为GPT的学习的对象是舞姿在编舞记忆中的编号。为了解决这个问题,我们采用了一种名为“演员-评论家”的强化学习框架。具体来说,我们把GPT前3层视作一个表示当前状态的“状态网络”,后几层视作一个产生“动作”的“演员网络”,并单独引入一个新的GPT分支作为“评论家网络”。评论家网络的打分和人工设计的奖励函数R,将决定GPT生成的舞蹈是好的(应该鼓励),还是不好的(应该避免),并通过对相应损失函数的优化提升GPT的效果。
1. 对比实验
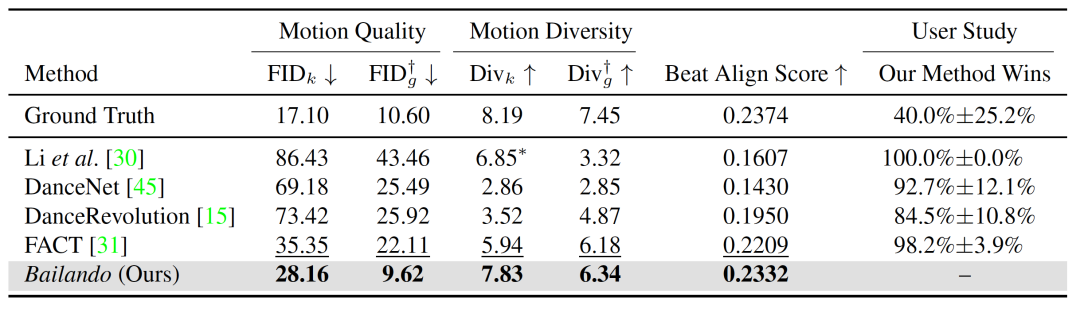
我们在AIST++ 数据集上分别对比了Bailando和其他模型的效果,如下表所示,可以看到Bailando相比于已有的方法的有很大优势。
以下是一些对比实验的视频:
2. 消融实验
为了验证每个模块的效果,我们进行了各种消融实验,实验结果也验证了我们提出的每个模块的有效性:

以下是消融实验的对比视频:
3. 为现实音乐伴舞
AIST++的音乐和现实中的音乐有一定差异(比如,没有歌词),但我们依然可以产生还不错的结果:
信息介绍
Bailando的相关代码目前已经开源,欢迎各位同学使用和交流。
作者信息
李思尧 | 南洋理工大学 S-Lab 一年级博士生,导师是Chen Change Loy副教授。以一作身份发表3篇顶会论文,曾连续获得ICCV 2019、ECCV 2020 AIM视频插帧赛道冠军。目前主要研究兴趣为内容生成。
论文地址
https://arxiv.org/abs/2203.13055
源码地址
https://github.com/lisiyao21/Bailando
MMLab@NTU
https://www.mmlab-ntu.com/








