绑定手机号
确认绑定









kaiming 的 MoCo让自监督学习成为深度学习热门之一, Yann Lecun也在 AAAI 上讲 Self-Supervised Learning 是未来的大势所趋。本文延续上文详细介绍了 MoCo v2和MoCo v3。
1 MoCo v21.1 MoCo v2 的 Motivation1.2 MoCo 相对于 End-to-end 方法的改进1.3 MoCo v2实验
2 MoCo v32.1 MoCo v3 原理分析2.2 MoCo v3 自监督训练 ViT 的不稳定性2.3 提升训练稳定性的方法:冻结第1层 (patch embedding层) 参数2.4 MoCo v3 实验
科技猛兽:Self-Supervised Learning系列解读 (目录)
https://zhuanlan.zhihu.com/p/381354026
Self-Supervised Learning,又称为自监督学习,我们知道一般机器学习分为有监督学习,无监督学习和强化学习。而 Self-Supervised Learning 是无监督学习里面的一种,主要是希望能够学习到一种通用的特征表达用于下游任务 (Downstream Tasks)。其主要的方式就是通过自己监督自己。作为代表作的 kaiming 的 MoCo 引发一波热议, Yann Lecun也在 AAAI 上讲 Self-Supervised Learning 是未来的大势所趋。所以在这个系列中,我会系统地解读 Self-Supervised Learning 的经典工作。
论文名称:Improved Baselines with Momentum Contrastive Learning
论文地址:
https://arxiv.org/pdf/2003.04297.pdf
上篇文章我们介绍了 MoCo 这个系列的第一版 MoCo v1,链接如下所示。
MoCo v1的方法其实可以总结为2点
(a) 在 [1 原始的端到端自监督学习方法] 里面,Encoder 和 Encoder 的参数每个step 都更新,这个问题在前面也有提到,因为Encoder 输入的是一个 Batch 的 negative samples (N-1个),所以输入的数量不能太大,即dictionary不能太大,即 Batch size不能太大。
现在的 Momentum Encoder 的更新是通过动量的方法更新的,不涉及反向传播,所以 输入的负样本 (negative samples) 的数量可以很多,具体就是 Queue 的大小可以比较大,可以比mini-batch大,属于超参数。队列是逐步更新的在每次迭代时,当前mini-batch的样本入列,而队列中最老的mini-batch样本出列,那当然是负样本的数量越多越好了。这就是 Dictionary as a queue 的含义,即通过动量更新的形式,使得可以包含更多的负样本。而且 Momentum Encoder 的更新极其缓慢 (因为 很接近于1),所以Momentum Encoder 的更新相当于是看了很多的 Batch,也就是很多负样本。
(b) 在 [2 采用一个较大的memory bank存储较大的字典] 方法里面,所有样本的 representation 都存在 memory bank 里面,根据上文的描述会带来最新的 query 采样得到的 key 可能是好多个step之前的编码器编码得到的 key,因此丧失了一致性的问题。但是MoCo的每个step都会更新Momentum Encoder,虽然更新缓慢,但是每个step都会通过4式更新一下Momentum Encoder,这样 Encoder 和 Momentum Encoder 每个step 都有更新,就解决了一致性的问题。
SimCLR的两个提点的方法
今天介绍MoCo 系列的后续工作:MoCo v2 和 v3。MoCo v2 是在 SimCLR 发表以后相继出来的,它是一篇很短的文章, 只有2页。在MoCo v2 中,作者们整合 SimCLR 中的两个主要提升方法到 MoCo 中,并且验证了SimCLR算法的有效性。SimCLR的两个提点的方法就是:
使用强大的数据增强策略,具体就是额外使用了 Gaussian Deblur 的策略和使用巨大的 Batch size,让自监督学习模型在训练时的每一步见到足够多的负样本 (negative samples),这样有助于自监督学习模型学到更好的 visual representations。
使用预测头 Projection head。在 SimCLR 中,Encoder 得到的2个 visual representation再通过Prediction head ()进一步提特征,预测头是一个 2 层的MLP,将 visual representation 这个 2048 维的向量进一步映射到 128 维隐空间中,得到新的representation 。利用 去求loss 完成训练,训练完毕后扔掉预测头,保留 Encoder 用于获取 visual representation。
关于 SimCLR 的详细解读欢迎参考下面的链接:
深度了解自监督学习,就看这篇解读 !Hinton团队力作:SimCLR系列
SimCLR 的方法其实是晚于 MoCo v1 的。时间线如下:
MoCo v1 于 2019.11 发布于arXiv,中了CVPR 2020;SimCLR v1 于 2020.02 发布于arXiv,中了ICML 2020;MoCo v2 于 2020.03 发布于arXiv,是一个技术报告,只有2页。SimCLR v2 于 2020.06 发布于arXiv,中了NIPS 2020;
在 SimCLR v1 发布以后,MoCo的作者团队就迅速地将 SimCLR的两个提点的方法移植到了 MoCo 上面,想看下性能的变化,也就是MoCo v2。结果显示,MoCo v2的结果取得了进一步的提升并超过了 SimCLR v1,证明MoCo系列方法的地位。因为 MoCo v2 文章只是移植了 SimCLR v1 的技巧而没有大的创新,所以作者就写成了一个只有2页的技术报告。
MoCo v2 的亮点是不需要强大的 Google TPU 加持,仅仅使用 8-GPU 就能超越 SimCLR v1的性能。End-to-end 的方法和 MoCo v1的方法在本专栏的上一篇文章 Self-Supervised Learning 超详细解读 (四):MoCo系列 (1) 里面已经有详细的介绍,这里再简单概述下二者的不同,如下图1,2,3所示。
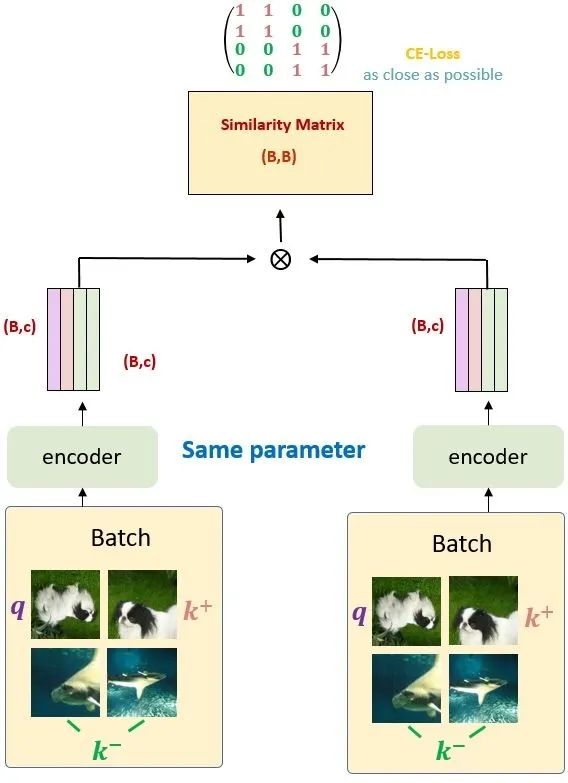 图1:早期的End-to-end的方法
图1:早期的End-to-end的方法 图2:MoCo v1/2 方法,图中n为Batch size
图2:MoCo v1/2 方法,图中n为Batch size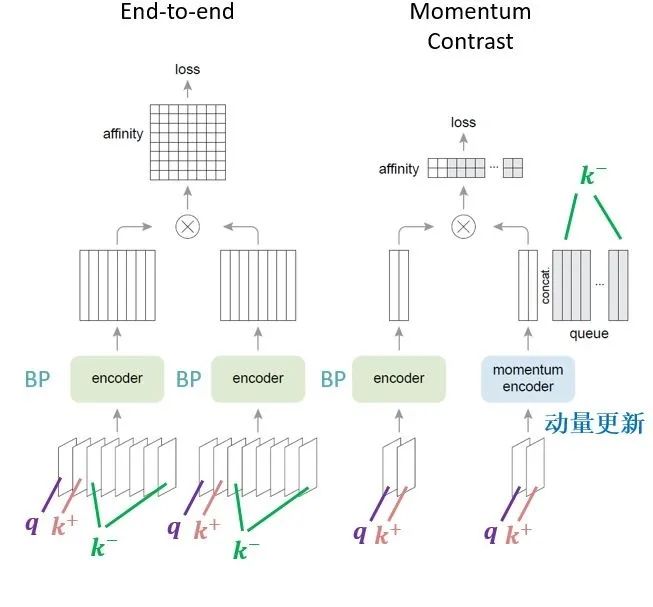 图3:早期的End-to-end的方法和MoCo方法的对比
图3:早期的End-to-end的方法和MoCo方法的对比End-to-end 的方法 (原始的端到端自监督学习方法): 一个Batch的数据假设有 个 image,这里面有一个样本 query 和它所对应的正样本 , 和 来自同一张图片的不同的 Data Augmentation,这个Batch剩下的数据就是负样本 (negative samples),如下图3所示。接着我们将这个 Batch 的数据同时输入给2个架构相同但参数不同的 Encoder 和 Encoder 。然后对两个 Encoder的输出使用下式 1 所示的 Contrastive loss 损失函数使得query 和正样本 的相似程度尽量地高,使得query 和负样本 的相似程度尽量地低,通过这样来训练Encoder 和 Encoder ,这个过程就称之为自监督预训练。训练完毕后得到的 Encoder 的输出就是图片的 visual representation。这种方法的缺点是:因为Encoder 和 Encoder 的参数都是通过反向传播来更新的,所以 Batch size 的大小不能太大,否则 GPU 显存就不够了。所以,Batch size 的大小限制了负样本的数量,也限制了自监督模型的性能。
 图4:End-to-end方法一个Batch的数据
图4:End-to-end方法一个Batch的数据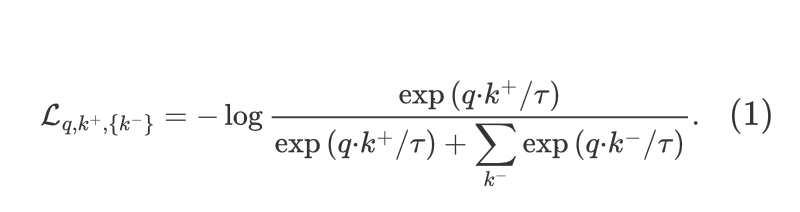
MoCo 的方法: 一个Batch的数据假设有 个 image,这里面有一个样本 query 和它所对应的正样本 , 和 来自同一张图片的不同的 Data Augmentation,这个Batch剩下的数据就是负样本 (negative samples)。 接着我们只把query 和正样本 输入给2个架构相同但参数不同的 Encoder 和 Momentum Encoder 。所有的负样本 都会保存在一个队列 Queue 里面。然后对两个 Encoder的输出使用上式 1 所示的 Contrastive loss 损失函数使得query 和正样本 的相似程度尽量地高,使得query 和负样本 的相似程度尽量地低。在任意一个 Epoch 的任意一个 step 里面,我们只使用反向传播来更新Encoder 的参数,然后通过2式的动量方法更新 Momentum Encoder 的参数。同时,队列删除掉尾部的一个 Batch 大小的负样本,再在头部进来一个 Batch 大小的负样本,完成这个step的队列的更新。这样,队列的大小可以远远大于 Batch size 的大小了,使得负样本的数量可以很多,提升了自监督训练的效果。而且,队列和 在每个 step 都会有更新,没有memory bank,也就不会存在更新不及时导致的 的更新和memory bank更新不一致的问题。
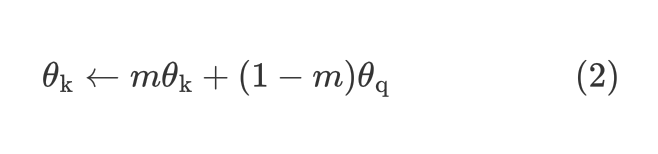
FAQ:MoCo方法里面这个队列 Queue 的内容是什么,是如何生成的?
答: 是负样本 通过Momentum Encoder ( 采用2式的动量更新方法,而不是反向传播) 之后输出的值,它代表所有负样本的 visual representation。队列 Queue 的是 Batch size 的数倍大,且每个step都会进行一次 Dequeue 和 Enqueue 的操作更新队列。
以上就是对 MoCo v1的概述,v2 将 SimCLR的两个提点的方法 (a 使用预测头 b 使用强大的数据增强策略) 移植到了 MoCo v1上面,实验如下。
训练集: ImageNet 1.28 张训练数据。
评价手段:
(1) Linear Evaluation (在 Self-Supervised Learning 超详细解读 (二):SimCLR系列 文章中有介绍,Encoder (ResNet-50) 的参数固定不动,在Encoder后面加分类器,具体就是一个FC层+softmax激活函数,使用全部的 ImageNet label 只训练分类器的参数,而不训练 Encoder 的参数)。看最后 Encoder+分类器的性能。
(2) VOC 目标检测 使用 Faster R-CNN 检测器 (C4 backbone),在 VOC 07+12 trainval set 数据集进行 End-to-end 的 Fine-tune。在 VOC 07 test 数据集进行 Evaluation。
a 使用预测头结果
预测头 Projection head 分类任务的性能只存在于无监督的预训练过程,在Linear Evaluation和下游任务中都是被去掉的。
Linear Evaluation 结果如下图5所示:
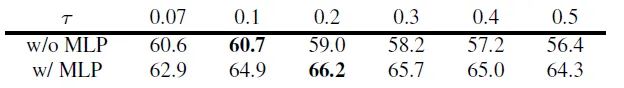 图5:使用预测头对比实验Linear Evaluation 结果
图5:使用预测头对比实验Linear Evaluation 结果图中的 就是式1中的 。在使用预测头且 时取得了最优的性能。
VOC 目标检测如下图6所示。在使用预测头且预训练的 Epoch 数为800时取得了最优的性能,AP各项指标也超越了有监督学习 supervised 的情况。
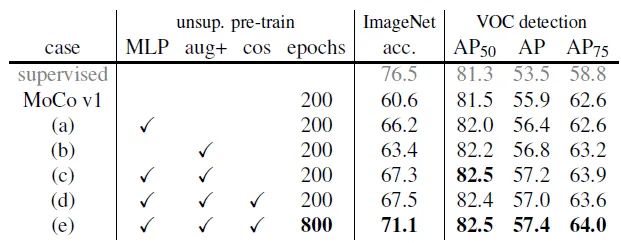 图6:使用预测头对比实验VOC 目标检测结果
图6:使用预测头对比实验VOC 目标检测结果b 使用强大的数据增强策略结果
如图4所示,对数据增强策略,作者在 MoCo v1 的基础上又添加了 blur augmentation,发现更强的色彩干扰作用有限。只添加 blur augmentation 就可以使得 ImageNet 分类任务的性能从60.6增长到63.4,再加上预测头 Projection head 就可以使性能进一步涨到67.3。从图 4 也可以看到:VOC 目标检测的性能和 ImageNet 分类任务的性能没有直接的联系。
与 SimCLR v1 的对比
如下图7所示为 MoCo v2 与 SimCLR v1 性能的直接对比结果。预训练的 Epochs 都取200。如果 Batch size 都取 256,MoCo v2在 ImageNet 有67.5的性能,超过了 SimCLR 的61.9的性能。即便 SimCLR 在更有利的条件下 (Batch size = 4096,Epochs=1000),其性能69.3也没有超过 MoCo v2 的71.1的性能,证明了MoCo系列方法的地位。
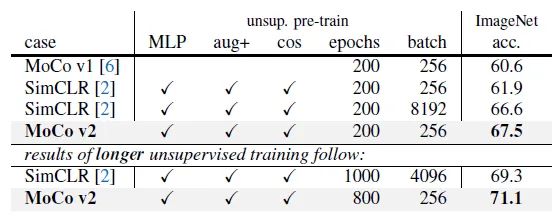 图7:与 SimCLR v1 的对比
图7:与 SimCLR v1 的对比MoCo v2 把 SimCLR 中的两个主要提升方法 (1 使用强大的数据增强策略,具体就是额外使用了 Gaussian Deblur 的策略 2 使用预测头 Projection head) 到 MoCo 中,并且验证了SimCLR算法的有效性。最后的MoCo v2的结果更优于 SimCLR v1,证明 MoCo 系列自监督预训练方法的高效性。
论文名称:An Empirical Study of Training Self-Supervised Vision Transformers
论文地址:
https://arxiv.org/pdf/2104.02057.pdf
自监督学习模型一般可以分成 Generative 类型的或者 Contrastive 类型的。在 NLP 里面的自监督学习模型 (比如本专栏第1篇文章介绍的BERT系列等等) 一般是属于 Generative 类型的,通常把模型设计成 Masked Auto-encoder,即盖住输入的一部分 (Mask),让模型预测输出是什么 (像做填空题),通过这样的自监督方式预训练模型,让模型具有一个不错的预训练参数,且模型架构一般是个 Transformer。在 CV 里面的自监督学习模型 (比如本专栏第2篇文章介绍的SimCLR系列等等) 一般是属于 Contrastive 类型的,模型架构一般是个 Siamese Network (孪生神经网络),通过数据增强的方式创造正样本,同时一个 Batch 里面的其他数据为负样本,通过使模型最大化样本与正样本之间的相似度,最小化与样本与负样本之间的相似度来对模型参数进行预训练,且孪生网络架构一般是个 CNN。
这篇论文的重点是将目前无监督学习最常用的对比学习应用在 ViT 上。作者给出的结论是:影响自监督ViT模型训练的关键是:instability,即训练的不稳定性。 而这种训练的不稳定性所造成的结果并不是训练过程无法收敛 (convergence),而是性能的轻微下降 (下降1%-3%的精度)。
首先看 MoCo v3 的具体做法吧。它的损失函数和 v1 和 v2 版本是一模一样的,都是 1 式:
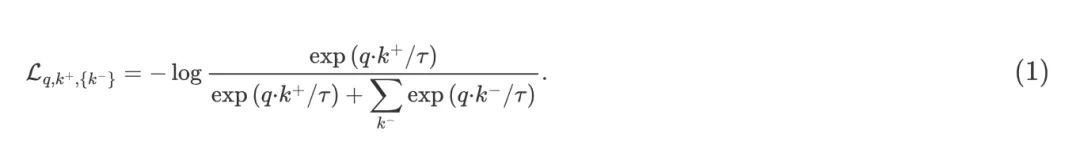
那么不一样的是整个 Framework 有所差异,MoCo v3 的整体框架如下图8所示,这个图比论文里的图更详细地刻画了 MoCo v3 的训练方法,读者可以把图8和上图2做个对比,看看MoCo v3 的训练方法和 MoCo v1/2 的训练方法的差异。
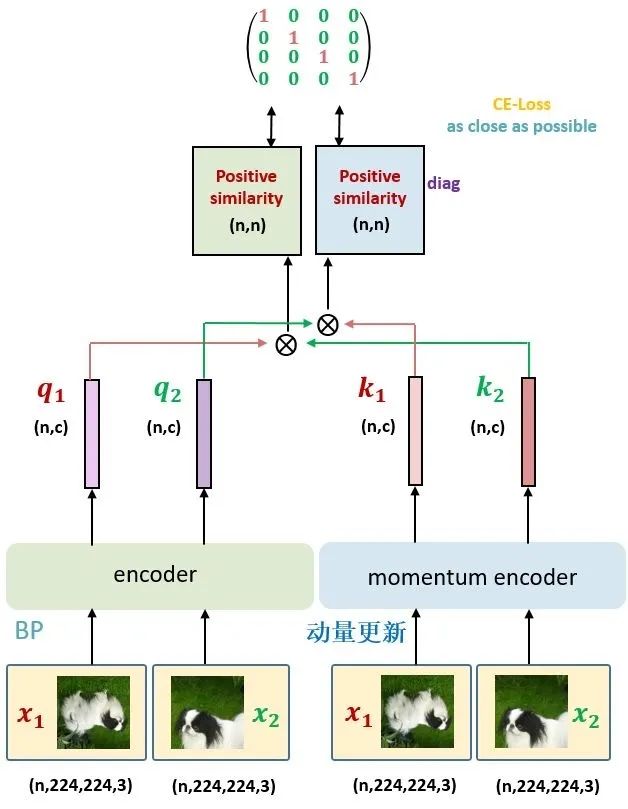 图8:MoCo v3方法,图中n为Batch size
图8:MoCo v3方法,图中n为Batch sizeMoCo v3 的训练方法和 MoCo v1/2 的训练方法的差异是:
取消了 Memory Queue 的机制: 你会发现整套 Framework 里面没有 Memory Queue 了,那这意味着什么呢?这就意味着 MoCo v3 所观察的负样本都来自一个 Batch 的图片,也就是图8里面的 n。换句话讲,只有当 Batch size 足够大时,模型才能看到足够的负样本。 那么 MoCo v3 具体是取了4096这样一个巨大的 Batch size。
Encoder 除了 Backbone 和预测头 Projection head 以外,还添加了个 Prediction head,是遵循了 BYOL 这篇论文的方法。
对于同一张图片的2个增强版本 ,分别通过 Encoder 和 Momentum Encoder 得到 和 。让 通过 Contrastive loss (式 1) 进行优化 Encoder 的参数,让 通过 Contrastive loss (式 1) 进行优化 Encoder 的参数。Momentum Encoder 通过式 2 进行动量更新。
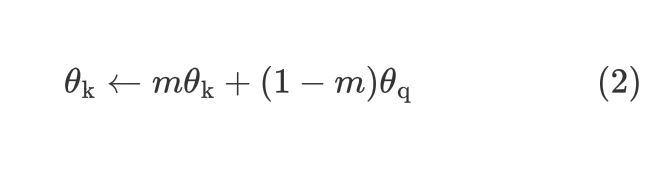
下面是伪代码, 和 在代码里面分别表示为:f_q , f_k。
1) 数据增强:
现在我们有一堆无标签的数据,拿出一个 Batch,代码表示为 x,也就是 张图片,分别进行两种不同的数据增强,得到 x_1 和 x_2,则 x_1 是 张图片,x_2 也是 张图片。
for x in loader: # load a minibatch x with N samples
x1, x2 = aug(x), aug(x) # augmentation
2) 分别通过 Encoder 和 Momentum Encoder:
x_1 分别通过 Encoder 和 Momentum Encoder 得到特征 q_1 和 k_1,维度是 ,这里特征空间由一个长度为 的向量表示。
x_2 分别通过 Encoder 和 Momentum Encoder 得到特征 q_2 和 k_2,维度是 ,这里特征空间由一个长度为 的向量表示。
q1, q2 = f_q(x1), f_q(x2) # queries: [N, C] each
k1, k2 = f_k(x1), f_k(x2) # keys: [N, C] each
3) 通过一个 Contrastive loss 优化 q_1 和 k_2,通过另一个 Contrastive loss 优化 q_2 和 k_1,并反向传播更新 f_q 的参数:
loss = ctr(q1, k2) + ctr(q2, k1) # symmetrized
loss.backward()
update(f_q) # optimizer update: f_q
4) Contrastive loss 的定义:
对两个维度是 (N,C) 的矩阵 (比如是q_1和k_2) 做矩阵相乘,得到维度是 (N,N) 的矩阵,其对角线元素代表的就是positive sample的相似度,就是让对角线元素越大越好,所以目标是整个这个 (N,N) 的矩阵越接近单位阵越好,如下所示。
def ctr(q, k):
logits = mm(q, k.t()) # [N, N] pairs
labels = range(N) # positives are in diagonal
loss = CrossEntropyLoss(logits/tau, labels)
return 2 * tau * loss
5) Momentum Encoder的参数使用动量更新:
f_k = m*f_k + (1-m)*f_q # momentum update: f_k
全部的伪代码 (来自MoCo v3 的paper):
# f_q: encoder: backbone + pred mlp + proj mlp
# f_k: momentum encoder: backbone + pred mlp
# m: momentum coefficient
# tau: temperature
for x in loader: # load a minibatch x with N samples
x1, x2 = aug(x), aug(x) # augmentation
q1, q2 = f_q(x1), f_q(x2) # queries: [N, C] each
k1, k2 = f_k(x1), f_k(x2) # keys: [N, C] each
loss = ctr(q1, k2) + ctr(q2, k1) # symmetrized
loss.backward()
update(f_q) # optimizer update: f_q
f_k = m*f_k + (1-m)*f_q # momentum update: f_k
# contrastive loss
def ctr(q, k):
logits = mm(q, k.t()) # [N, N] pairs
labels = range(N) # positives are in diagonal
loss = CrossEntropyLoss(logits/tau, labels)
return 2 * tau * loss
以上就是 MoCo v3 的全部方法,都可以概括在图8里面。它的性能如何呢?假设 Encoder 依然取 ResNet-50,则 MoCo v2,MoCo v2+,MoCo v3 的对比如下图9所示,主要的提点来自于大的 Batch size (4096) 和 Prediction head 的使用。
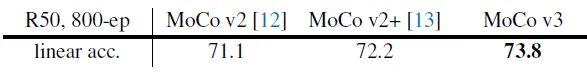 图9:MoCo v2,MoCo v2+,MoCo v3 的对比 (Backbone: ResNet-50)
图9:MoCo v2,MoCo v2+,MoCo v3 的对比 (Backbone: ResNet-50)上图9的实验结果证明了 MoCo v3 在 Encoder 依然取 ResNet-50 时的有效性。那么当 Encoder 变成 Transformer 时的情况又如何呢?如本节一开始所述,作者给出的结论是:影响自监督ViT模型训练的关键是:instability,即训练的不稳定性。 而这种训练的不稳定性所造成的结果并不是训练过程无法收敛 (convergence),而是性能的轻微下降 (下降1%-3%的精度)。
Batch size 过大使得训练不稳定
如下图10所示是使用 MoCo v3 方法,Encoder 架构换成 ViT-B/16 ,Learning rate=1e-4,在 ImageNet 数据集上训练 100 epochs 的结果。作者使用了4种不同的 Batch size:1024, 2048, 4096, 6144 的结果。可以看到当 bs=4096 时,曲线出现了 dip 现象 (稍稍落下又急速升起)。这种不稳定现象导致了精度出现下降。当 bs=6144 时,曲线的 dip 现象更大了,可能是因为跳出了当前的 local minimum。这种不稳定现象导致了精度出现了更多的下降。
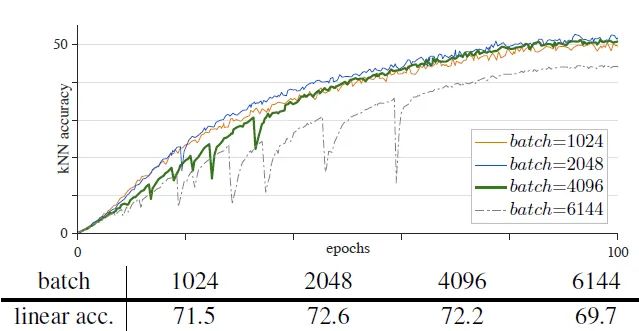 图10:Batch size过大使得训练不稳定
图10:Batch size过大使得训练不稳定Learning rate 过大使得训练不稳定
如下图11所示是使用 MoCo v3 方法,Encoder 架构换成 ViT-B/16 ,Batch size=4096,在 ImageNet 数据集上训练 100 epochs 的结果。作者使用了4种不同的 Learning rate:0.5e-4, 1.0e-4, 1.5e-4 的结果。可以看到当Learning rate 较大时,曲线出现了 dip 现象 (稍稍落下又急速升起)。这种不稳定现象导致了精度出现下降。
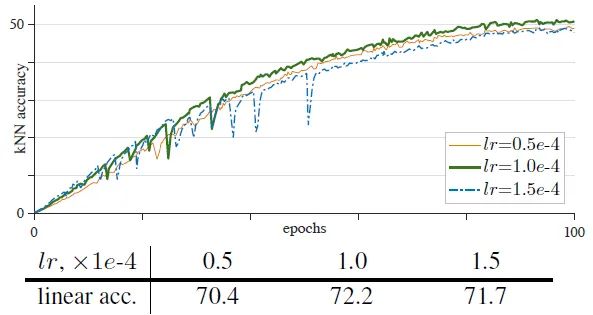 图11:Learning rate 过大使得训练不稳定
图11:Learning rate 过大使得训练不稳定LARS optimizer 的不稳定性
如下图12所示是使用 MoCo v3 方法,Encoder 架构换成 ViT-B/16 ,Batch size=4096,在 ImageNet 数据集上训练 100 epochs 的结果,不同的是使用了 LARS 优化器,分别使用了4种不同的 Learning rate:3e-4, 5e-4, 6e-4, 8e-4 的结果。结果发现当给定合适的学习率时,LARS的性能可以超过AdamW,但是当学习率稍微变大时,性能就会显著下降。而且曲线自始至终都是平滑的,没有 dip 现象。所以最终为了使得训练对学习率更鲁棒,作者还是采用 AdamW 作为优化器。因为若采用 LARS,则每换一个网络架构就要重新搜索最合适的 Learning rate。
 图12:LARS optimizer 的不稳定性
图12:LARS optimizer 的不稳定性上面图10-12的实验表明 Batch size 或者 learning rate 的细微变化都有可能导致 Self-Supervised ViT 的训练不稳定。作者发现导致训练出现不稳定的这些 dip 跟梯度暴涨 (spike) 有关,如下图13所示,第1层会先出现梯度暴涨的现象,结果几十次迭代后,会传到到最后1层。
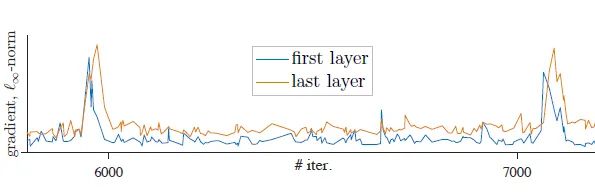 图13:第1层会先出现梯度暴涨的现象,结果几十次迭代后,会传到到最后1层
图13:第1层会先出现梯度暴涨的现象,结果几十次迭代后,会传到到最后1层所以说问题就出在第1层出现了梯度暴涨啊,一旦第1层梯度暴涨,这个现象就会在几十次迭代之内传遍整个网络。所以说想解决训练出现不稳定的问题就不能让第1层出现梯度暴涨!
所以作者解决的办法是冻结第1层的参数 ,也就是patch embedding那层,随机初始化后,不再更新这一层的参数,然后发现好使,如图14所示。
patch embedding那层具体就是一个 的卷积操作,输入 channel 数是3,输出 channel 数是embed_dim=768/384/192。
patch embedding 代码:
self.proj = nn.Conv2d(in_chans, embed_dim, kernel_size=patch_size, stride=patch_size)
如下图14,15所示是使用 MoCo v3 or SimCLR, BYOL 方法,Encoder 架构换成 ViT-B/16 ,Batch size=4096,在 ImageNet 数据集上训练 100 epochs 的结果,不同的是冻结了patch embedding那层的参数,使用了随机参数初始化。
图14和15表明不论是 MoCo v3 还是 SimCLR, BYOL 方法,冻结 patch embedding 那层的参数都能够提升自监督 ViT 的训练稳定性。除此之外, gradient-clip 也能够帮助提升训练稳定性,其极限情况就是冻结参数。
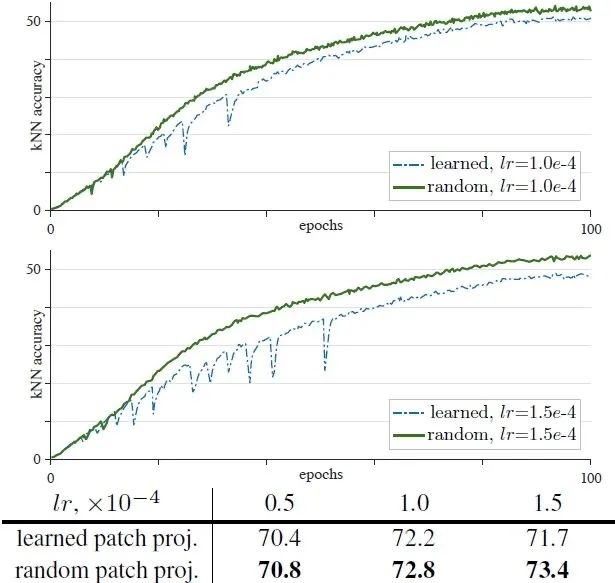 图14:提升训练稳定性的方法:冻结第1层 (patch embedding层) 的参数 (MoCo v3方法)
图14:提升训练稳定性的方法:冻结第1层 (patch embedding层) 的参数 (MoCo v3方法)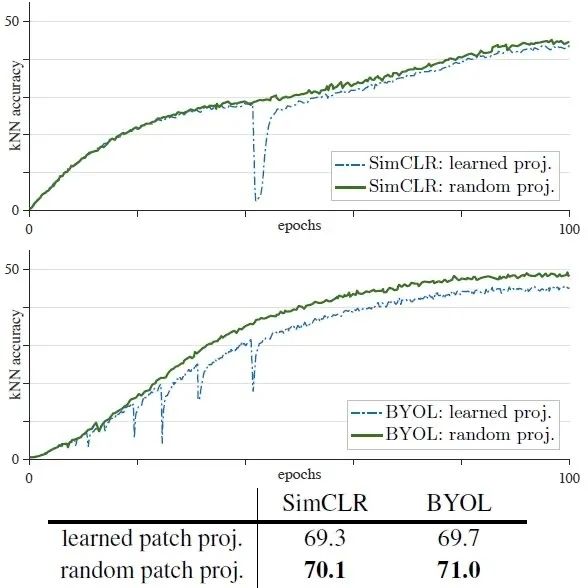 图15:提升训练稳定性的方法:冻结第1层 (patch embedding层) 的参数 (SimCLR, BYOL 方法)
图15:提升训练稳定性的方法:冻结第1层 (patch embedding层) 的参数 (SimCLR, BYOL 方法)超参数细节
超参数具体值
| Optimizer | AdamW,bs=4096,epochs=100,搜索lr和wd的最优解,warmup=40 epochs,cosine decay learning rate |
| Projection head | 3层的 MLP,激活函数ReLU, hidden dim=4096,output dim=256 |
| Prediction head | 2层的MLP,激活函数ReLU, hidden dim=4096,output dim=256 |
| loss | 超参数tau=0.2 |
| 评价指标 | Linear Evaluation (或者叫 Linear Classification,Linear Probing),在本专栏之前的文章介绍过,具体做法是:冻结Encoder的参数,在Encoder之后添加一个分类头 (FC层+softmax),使用全部的标签只训练这个分类头的参数,得到的测试集精度就是自监督模型的精度。 |
如下图16所示是ViT-S/16 和 ViT-B/16 模型在4种自监督学习框架下的性能对比。为了确保对比的公平性,lr 和 wd 都经过了搜索。结果显示 MoCo v3 框架具有最优的性能。
 图16:ViT-S/16 and ViT-B/16在不同框架的性能对比
图16:ViT-S/16 and ViT-B/16在不同框架的性能对比下图17展示的是不同的自监督学习框架对 ViT 和 ResNet 模型的偏爱,可以看出 SimCLR 和 MoCo v3 这两个自监督框架在 ViT 类的 Transformer 模型上的效果更好。
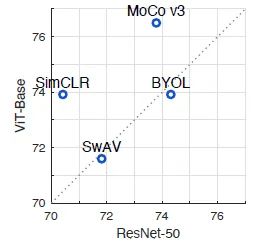 图17:不同的自监督学习框架对 ViT 和 ResNet 模型的偏爱不同
图17:不同的自监督学习框架对 ViT 和 ResNet 模型的偏爱不同1) 位置编码的具体形式
如下图18所示,最好的位置编码还是余弦编码 sin-cos。在无监督训练过程去除位置编码,效果下降了1个多点,说明 ViT 的学习能力很强,在没有位置信息的情况下就可以学习的很好;从另外一个角度来看,也说明 ViT 并没有充分利用好位置信息。
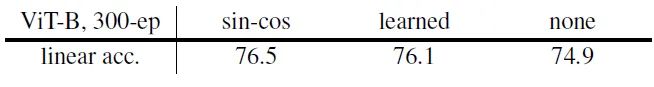 图18:位置编码的具体形式
图18:位置编码的具体形式2) class token 的必要性
如下图19所示,使用 class token 的性能是76.5,而简单地取消 class token,并换成 Global Average Pooling 会下降到69.7,这时候最后一层后面有个LN层。如果把它也去掉,性能会提升到76.3。说明 class token 并不是必要的,LN的选择也很重要。
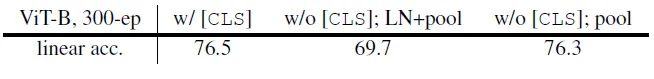 图19:class token 的必要性
图19:class token 的必要性3) Prediction head 的必要性
如下图20所示,去掉 Prediction head 会使性能稍微下降。
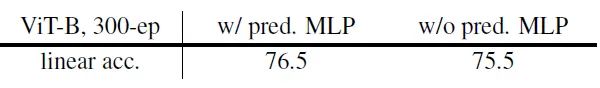 图20:Prediction head 的必要性
图20:Prediction head 的必要性4) momentum 超参数的影响
如下图21所示,momentum 超参数取0.99是最优的。m=0就是 Momentum Encoder 的参数和 Encoder 的参数完全一致,那就是 SimCLR 的做法了。
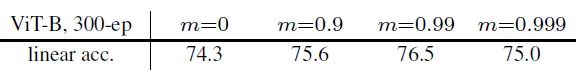 图21:momentum 超参数的影响
图21:momentum 超参数的影响MoCo v3与其他模型的性能对比
Self-supervised Transformer 的性能对比可以有两个方向,一个是跟 Supervised Transformer对比,另一个是跟 Self-supervised CNN对比。
第1个方向的对比如下图22所示。虽然 MoCo v3-VIT-L 参数量 比 VIT-B 大了很多,但 VIT-B训练的数据集比 ImageNet 大很多。
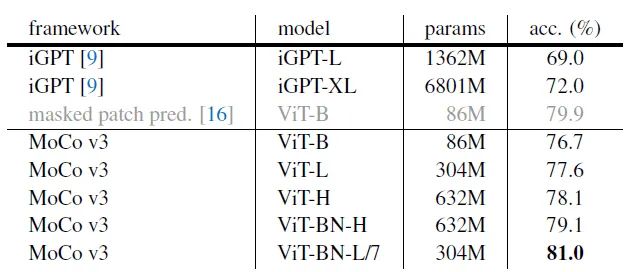 图22:跟 Supervised Transformer对比
图22:跟 Supervised Transformer对比第2个方向的对比如下图23所示。作者跟采用了 Big ResNet 的方法进行对比,以 VIT-L 为backbone的 MoCo v3 完胜。注意图23这个表的每一列表示的是把 MoCo v3的方法用在每一列对应的模型上的性能 (比如第2列就是在 ViT-B 这种模型使用 MoCo v3)。第1行就代表直接使用这个模型,第2行代表把 ViT 模型里面的 LN 全部换成 BN 的效果 (以ViT-BN 表示),第3行代表再把 ViT 模型的 patch 大小设置为7以获得更长的sequence (以ViT-BN/7 表示),但是这会使计算量变为6倍。而且这里没有列出各个模型的参数量,可能存在不公平对比的情况。
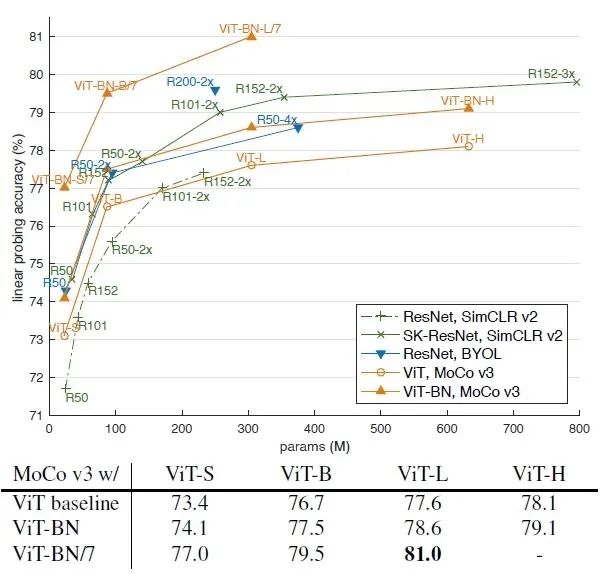 图23:跟 Self-supervised CNN对比
图23:跟 Self-supervised CNN对比MoCo v3 的改进如图8所示,取消了 Memory Queue 的机制,添加了个 Prediction head,且对于同一张图片的2个增强版本 ,分别通过 Encoder 和 Momentum Encoder 得到 和 。让 通过 Contrastive loss 进行优化 Encoder 的参数,让 通过 Contrastive loss 进行优化 Encoder 的参数。
在 Self-supervised 训练 Transformer 的过程中发现了 instablity 的问题,通过冻住patch embedding的参数,以治标不治本的形式解决了这个问题,最终Self-supervised Transformer 可以 beat 掉 Supervised Transformer 和 Self-supervised CNN。
本文亮点总结
1.MoCo v2 把 SimCLR 中的两个主要提升方法 (1 使用强大的数据增强策略,具体就是额外使用了 Gaussian Deblur 的策略 2 使用预测头 Projection head) 到 MoCo 中,并且验证了SimCLR算法的有效性。
2.MoCo v3重点是将目前无监督学习最常用的对比学习应用在 ViT 上。作者给出的结论是:影响自监督ViT模型训练的关键是:instability,即训练的不稳定性。 而这种训练的不稳定性所造成的结果并不是训练过程无法收敛 (convergence),而是性能的轻微下降 (下降1%-3%的精度)。
如果觉得有用,就请分享到朋友圈吧!
△点击卡片关注极市平台,获取最新CV干货
公众号后台回复“CVPR21检测”获取CVPR2021目标检测论文下载~
极市干货
YOLO教程:一文读懂YOLO V5 与 YOLO V4|大盘点|YOLO 系目标检测算法总览
实操教程:PyTorch vs LibTorch:网络推理速度谁更快?|只用两行代码,我让Transformer推理加速了50倍
算法技巧(trick):深度学习训练tricks总结(有实验支撑)|深度强化学习调参Tricks合集

# 极市平台签约作者#

科技猛兽
知乎:科技猛兽
清华大学自动化系19级硕士,目前实习于北京华为诺亚方舟实验室。
研究领域:AI边缘计算 (Efficient AI with Tiny Resource):专注模型压缩,搜索,量化,加速,加法网络,以及它们与其他任务的结合,更好地服务于端侧设备。
作品精选
搞懂 Vision Transformer 原理和代码,看这篇技术综述就够了
用Pytorch轻松实现28个视觉Transformer,开源库 timm 了解一下!(附代码解读)
轻量高效!清华智能计算实验室开源基于PyTorch的视频 (图片) 去模糊框架SimDeblur
投稿方式:
添加小编微信Fengcall(微信号:fengcall19),备注:姓名-投稿

△长按添加极市平台小编
觉得有用麻烦给个在看啦~ 








