绑定手机号
确认绑定









昨天,arXiv上出现了一篇非常硬核的论文“How to Understand Masked Autoencoder”。该论文为何恺明的最新一作论文“Masked Autoencoders Are Scalable Vision Learners”提供了理论解释和相关数学证明。
对于不满于CV常被调侃只是调参,喜欢较真“算法可解释性”的朋友来说,这无疑是一篇不容错过的佳作。两位华人作者曹书豪、徐鹏分别来自华盛顿大学和牛津大学。

原文链接:https://arxiv.org/abs/2202.03670
背景介绍:
如果要盘点2021年计算机视觉领域中最受关注的研究工作,很多人首先会想到何恺明于去年11月份发布的新作“Masked Autoencoders Are Scalable Vision Learners”。这项工作刚一发布,便在业内引起了极其热烈的反响和讨论。
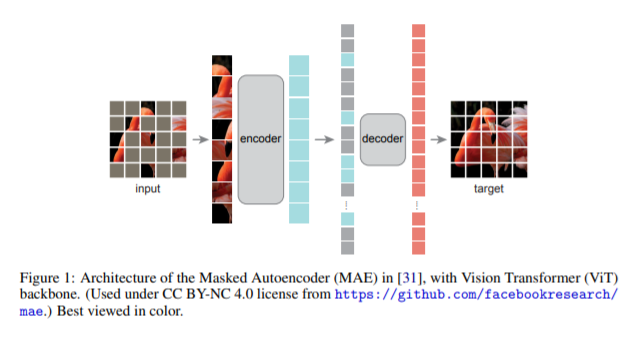
然而,MAE原文并没有提供理论分析和数学解释。广大学者们近两个月来在网上纷纷直呼期待相关的理论分析。就在昨天,大家的这个心愿实现了。“How to Understand Masked Autoencoder”为MAE提供了理论解释和相关数学证明。
论文梗概:
“How to Understand Masked Autoencoder”这篇论文从积分方程算子角度出发,针对MAE模型提出了5个关键的问题,相应地进行了理论分析,给出了明确的答案,并提供了数学推导和证明。
这五个问题是:
1. MAE模型的表示空间(representation space)是如何形成的、优化的?这个表示空间是如何在Transformer结构中跨层传播的?
2. 对图像的分片处理(patchifying)为什么有助于MAE模型的学习?
3. 为什么MAE模型内部低层和高层输出的特征表示之间没有显著的差异?
4. 解码器(decoder)对于MAE模型不重要吗?
5. MAE对每一个被随机遮盖的分片(masked patch)的重建仅仅是依据其最近邻的未被遮盖的分片进行推断的吗?
相信这篇振奋人心的论文会为我们打开一扇新的窗户,提供了对MAE进行理论分析的一些理论入口。这篇论文必然会鼓励广大从业者更加坚定地去更深入地探索MAE模型及其衍生模型。








