绑定手机号
确认绑定










论文地址:https://github.com/DingXiaoH/RepLKNet-pytorch
Transformer 目前在 CV 领域愈演愈烈,这份火热促使着优秀学者们思考一个更深层次的问题。部分学者认为 Transformer 之所以 work 更加本质的原因在于其大的感受野。根据有效感受野(ERF)理论,ERF 大小与 kernel 大小成正比关系,与模型深度的平方根也成正比关系。所以通过堆叠层数实现大感受野必然不如增加卷积 kernel 大小更高效。因此有学者提出超大 kernel 卷积的网络结构,并证明在目标检测和语义分割等任务上超过 Swin Transformer 而且远超传统小卷积模型。
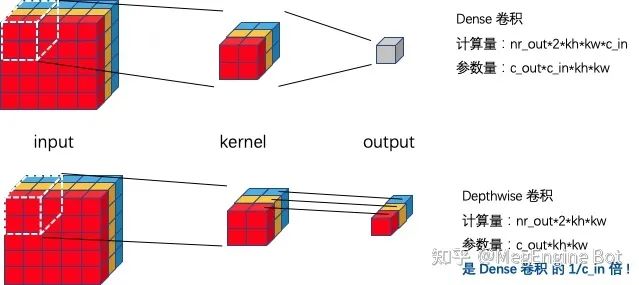
CNN 中最常见的卷积 kernel 大小有 2x2, 3x3, 5x5, 7x7 等,在本文中我们将卷积 kernel 大小超过 9x9 的视作大 kernel。我们不难看出随着卷积 kernel 大小的增加,卷积的参数量和计算量都呈平方增长,这往往也是大家不喜欢用大 kernel 卷积的其中一个原因。为了获得大 kernel 卷积带来的收益的同时降低其计算量和参数量,我们一般将大 kernel 卷积设计成 depthwise 卷积。如下图所示,depthwise 卷积通过逐通道(channel) 做卷积,可以将计算量和参数量降低到 Dense 卷积的 input channel 分之一。
Roofline Model
为了解释清楚为什么大 kernel 值得优化这个问题,我们需要借助 Roofline 模型的帮助。如下图所示,Roofline 尝试解释一件非常简单的事情,即模型在特定计算设备下能达到多快的计算速度。
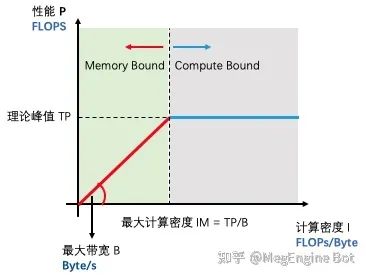
理论峰值 TP:描述了计算设备的性能上限,指的是一个计算设备每秒钟最多所能完成的浮点运算数,单位是 FLOPS。
最大带宽 B:描述计算设备的带宽上限,指的是一个计算设备每秒最多所能完成的内存交换量,单位是 Byte/s。
最大计算密度 IM:描述计算设备单位内存交换最多用来进行多少次运算,单位是 FLOPs/Byte。
"Roofline" 指的是由计算设备理论算力峰值和最大访存带宽这两个参数所决定的“屋顶”形态。其中设备理论峰值决定“屋顶”的高度(蓝色线段),设备最大访存带宽决定了“屋檐”的斜率(红色线段)。Roofline 模型划分出来两个瓶颈区域,分别为 Compute Bound 和 Memory Bound。
当应用的计算密度 I 超过最大计算密度 IM 时,此时无论应用的计算密度多大,它的性能最高只能达到计算设备的理论峰值 TP。此时应用的性能 P 被设备理论峰值限制无法和计算密度 I 成正比,所以叫做 Compute Bound。当应用的计算密度 I 小于最大计算密度 IM 时,此时性能 P 将由设备最大带宽和应用计算密度决定。不难看出对于处在 Memory Bound 区间的应用,增加设备带宽和增加计算密度可以使应用性能达到线性增长的目的。
为什么不是大 kernel Dense 卷积
现如今针对 Dense 卷积我们已经有了包括 Direct、im2col/implicit GEMM、Winograd 和 FFT 等多种优化手段,可以说已经足够成熟了。可是如果我们抛开模型参数量,仅仅从运行效率的角度思考一个问题,为什么我们不用大 kernel Dense 卷积而选择大 kernel depthwise 卷积呢?
为了探寻这个问题的答案,我们结合 Roofline 模型具体分析。本文选取 2080Ti 显卡为计算设备,它的实测 L2 cache 带宽为2.16TB/s,理论峰值性能为 4352 FFMA Cores * 1.545 GHZ * 2 = 13.447 TFLOPS。我们假设 CUDA 中每个 thread 负责计算的 output 数据都放在寄存器中累加,我们假设 L1 cache 100% 命中,忽略写回 output 的过程。由于现代计算设备的设计足够合理,实际卷积计算中足以抵消很多耗时较长的访存操作,同时为了简化分析复杂度,在这里我们假设 L2 cache 100% 命中,使用 L2 cache 的最大带宽作为分析参数。本文使用的卷积输入 shape 是(n, ic, ih, iw),kernel 是 (oc, ic, kh, kw),output 是 (n, oc, oh, ow)。
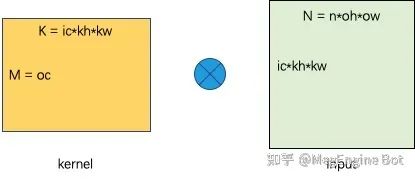
对 Dense 卷积而言,一种通用优化计算手段就是 im2col/implicit GEMM。由于其太经典了我们在这里不再赘述 im2col 的过程,感兴趣的可以翻阅我们之前写的文章《MegEngine TensorCore 卷积算子实现原理》。在经过了 im2col 变换之后,我们就成功的将卷积转换成了矩阵乘的形式。其中矩阵乘的 M = oc, N = n*oh*ow, K = ic*kh*kw,具体如下图所示。
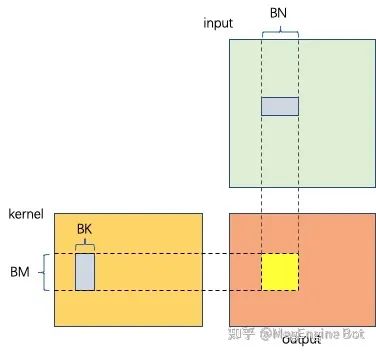
对于矩阵乘特别是大规模矩阵乘,cuBlas 等计算库已经优化的足够好了,基本上可以接近设备理论峰值,这里我们结合 Roofline 简单分析一下性能。为了充分适应硬件体系结构特征,充分利用多级存储增大访存带宽,我们需要对矩阵乘进行分块计算。如下图所示,假如 cuda 中每个 Thread Block 处理 BMxBN 的 output,此时 kernel 分块大小为 BMxBK,input 分块大小为 BKxBN。则计算量为 BM*BN*BK*2,访存量为 (BM*BK + BN*BK)*4。计算密度为 。按照 Roofline 模型的描述,计算设备的
对 Dense 卷积分析让我们得到了一个结论即 “随着 kernel 的增大,卷积时间呈平方增长”。很多人想当然的将这个结论平移到了 depthwise 卷积上,这其实是一种思维误区。
让我们同样尝试用 im2col/implicit GEMM 的方法分析 depthwise 卷积。由于 depthwise 是逐 channel 做卷积的,所以可以看做 channel 数量的单通道卷积。在经过 im2col 变换之后我们将获得一个 Batched GEMV,每个 batch 的 GEMV 如下图所示。
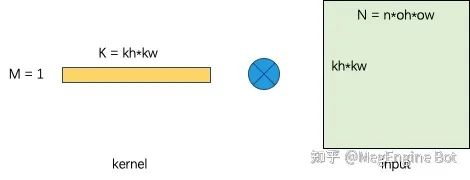
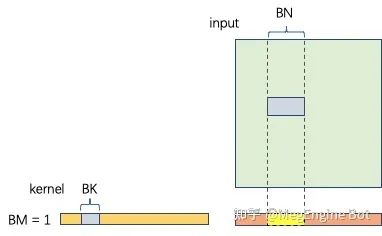
如果我们保持和 Dense 卷积一样的分块策略的话,每个 batch 的 GEMV 如下图所示。相应的此时的计算密度为
如果我们尝试使用 Direct 的方式处理 depthwise 卷积的话会不会好一点呢?例如我们让 cuda 中每个 warp 32 个线程负责计算 ohxow 的输出,kernel size 为 khxkw,此时:
计算量 = oh*ow*kh*kw*2 FLOPs
访存量 = (kh*kw + (oh+kh-1)*(ow+kw-1)) * 4 Bytes,分别为
kernel: kh*kw
input: (oh+kh-1)*(ow+kw-1)
计算密度为
我们以一个更具体的例子分析,假如我们让每个 thread 负责计算 4 个 output 的话,则一个 warp 负责计算 4x32 的 output,以 kernel (3, 3) 为例。则计算密度为 $\frac{432332}{(33+634)*4} = 2.7 $ FLOPs/Byte,最大可达到的性能为 2.16*2.7 = 5.84 TFLOPS,相比于理论峰值 13.447 TFLOPS 仍有很大差距。虽然增加 output 能继续增加计算密度,但是受限于卷积本身的输出大小和每个 SM 中有限的 register file 等计算资源,每个 warp 计算的 output 并不能无限增加。这也是 depthwise 卷积需要更加仔细的优化,否则一不小心性能就会很差的其中一个原因。
综合 im2col 和 Direct 两个方面的分析结论,我们认识到和 Dense 卷积不同的是 depthwise 卷积很多时候是一个 Memory Bound 的操作。而结合 Roofline 模型对 Memory Bound 瓶颈的分析和建议,此时增加计算密度和增加带宽都可以增加性能。在固定设备的情况下我们无法增加带宽了,所以看起来增加计算密度是一个可行的方案。通过观察计算密度公式我们不难发现,增加 depthwise 卷积的 kernel size 就是一个增加其计算密度的有效方案,例如保持每个 warp 4x32 的输出配置下 kernel size 31x31 的 depthwise 卷积计算密度将达到
综上所述,增加卷积 kernel size 会使得计算量增加。同时因为 Dense 卷积处于 Compute Bound 区域,所以其运行速度受限于设备理论峰值无法提升,因此针对 Dense 卷积我们不难归纳出 “随着 kernel 的增大,卷积时间呈平方增长” 的规律。但是 depthwise 卷积是一种 Memory Bound 的操作,而随着 kernel size 的增加其计算密度也会增大,所以其运行性能也会随之增大。此时的卷积的运行时间并不会显著增长,所以它并不适用 “随着 kernel 的增大,卷积时间呈平方增长” 这个结论。这也是我们认为大 kernel depthwise 还有较大的优化潜力,其运行时间并不会明显差于小 kernel depthwise 卷积的依据。
上一节我们已经解释了为什么 im2col/implicit GEMM 不适合 depthwise 卷积,direct 也需要付出很大精力才能写好。另外,提到大 kernel 则不能不提 FFT 算法,但 FFT 在计算 depthwise 卷积的时候只能逐通道计算,性能不如预期。并且 FFT 有其缺陷例如精度问题,对半精度计算并不友好,也不能被量化。我们在 2080Ti 上使用 input 和 output 形状都是 (n, c, h, w) = (64, 384, 32, 32) 的用例对 cudnn做了一次测速,我们遍历所有的 cudnn 算子(内含 FFT)并选择最快的那个算子进行测试。结果如下:
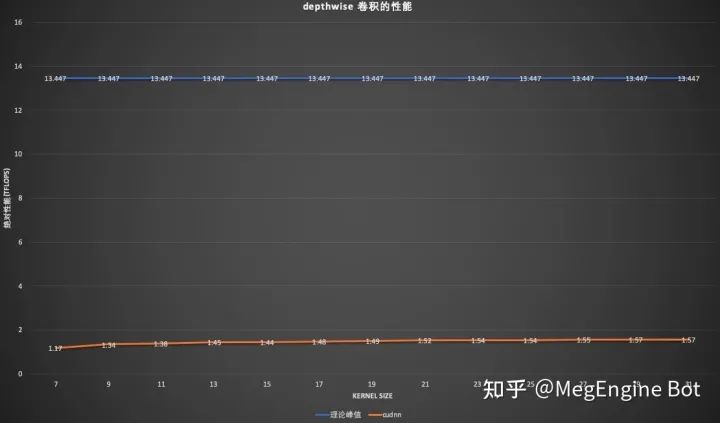
在大 kernel size 下 cudnn 的表现很差,主要原因是 cudnn 没有针对性优化。我们注意到很多时候 cudnn 调用到了内部的 implicit_gemm 实现,这并不是一个很好的行为。因为对于 depthwise 卷积而言,im2col 之后将会是一个 batch = channel,M = 1,N=n*h*w, K = kh*kw 的 batched GEMV,这种情况也很难打满设备峰值。

鉴于以上分析,大 kernel depthwise 卷积有很大的优化潜力,所以 MegEngine 紧跟学界动态对大 kernel depthwise 卷积进行了深度优化。如上图所示,经过我们的优化后,随着 kernel size 的增加,算子性能基本呈现线性增长的趋势,部分情况下算子可以逼近硬件的单精度浮点理论峰值。
如下图所示,优化后的大 kernel depthwise 卷积比 PyTorch 快 10.x 倍,代码附在文末,感兴趣的同学欢迎来体验一把。 而且我们不难发现,随着 kernel size 的增加模型训练时间并没有显著增加。原因就在于 kernel size 不够大的时候算子处于 Memory Bound 状态,远没有达到理论峰值,此时增加计算密度反而不会对算子运行时间造成很大影响。
想知道 MegEngine 是如何将 31*31 的 DWconv 优化快了 10 余倍? 还有 ConvNext,RepLKNet 为何不约而同将 kernel size 增大,更大的 kernel size 到底给模型带来了什么?来 MegEngine Meetup 一起聊聊吧。
北京时间本周六(3.19)上午 10:00,MegEngine Meetup 围绕“Large Kernel Makes CNN Great Again”主题,将为大家带来精彩线上分享,直播间地址:
http://live.bilibili.com/22436423
附:测试代码
import time
import megengine.module as M
import megengine.autodiff as ad
import megengine
import numpy as np
megengine.functional.debug_param.set_execution_strategy("PROFILE")
def benchmark_lknet(ksize, batch=64, dim=384, res=32, depth=24):
m = M.Sequential(
*[M.Conv2d(dim, dim, ksize, padding=ksize//2, groups=dim, bias=False) for _ in range(depth)]
)
x = megengine.tensor(np.ones([batch, dim, res, res]))
gm = ad.GradManager().attach(m.parameters())
for i in range(20):
t = time.perf_counter()
with gm:
y = m(x)
gm.backward(y.mean())
megengine._full_sync()
t = time.perf_counter() - t
if i > 9 and i % 10 == 0:
print(t)
return t
if __name__ == "__main__":
args = dict()
for k in (3, 5, 7, 9, 11, 13, 15, 17, 19, 21, 23, 25, 27, 29, 31):
t = benchmark_lknet(k, **args)
print("kernel size", k, "iter time", t * 1000, "ms")
PyTorch 测试代码
import torch
import torch.nn as nn
import torch.backends.cudnn as cudnn
import time
cudnn.benchmark = True
def benchmark_lknet(ksize, batch=64, dim=384, res=32, depth=24):
m = nn.Sequential(
*[nn.Conv2d(dim, dim, ksize, padding=ksize//2, groups=dim, bias=False) for _ in range(depth)]
).cuda()
x = torch.rand(batch, dim, res, res).cuda()
for i in range(20):
t = time.perf_counter()
y = m(x)
y.mean().backward()
torch.cuda.synchronize()
t = time.perf_counter() - t
if i > 9 and i % 10 == 0:
print(t)
return t
if __name__ == "__main__":
args = dict()
for k in (3, 5, 7, 9, 11, 13, 15, 17, 19, 21, 23, 25, 27, 29, 31):
t = benchmark_lknet(k, **args)
print("kernel size", k, "iter time", t * 1000, "ms")
延展阅读
论文地址:https://pan.baidu.com/share/init?surl=J3ISRFVkpK62rMt3mHSSLg&pwd=lknt
MegEngine TensorCore 卷积算子实现原理:https://zhuanlan.zhihu.com/p/372973726
深度学习算子优化-FFT:https://zhuanlan.zhihu.com/p/389325484
GitHub:MegEngine 天元:https://link.zhihu.com/?target=https%3A//github.com/MegEngine
官网:https://link.zhihu.com/?target=https%3A//megengine.org.cn/)









