绑定手机号
确认绑定









伴随着晶体管大小不断逼近原子的物理体积极限,传统摩尔定律下的2D微缩技术不再能同时改善芯片的性能、功率、面积成本和上市时间(即:PPACt),晶体管设计、互连微缩、图形化和设计技术协同优化(DTCO)成为横亘在逻辑微缩道路上的三座大山……
逻辑芯片,是电子产品中主要的处理引擎,功耗和性能对其至关重要。以苹果A14芯片为例,这颗采用5nm节点工艺制造的芯片,拥有约120亿个晶体管和240亿个晶体管触点,7个阈值电压的设计确保了产品的高性能、高可靠性和长续航能力。
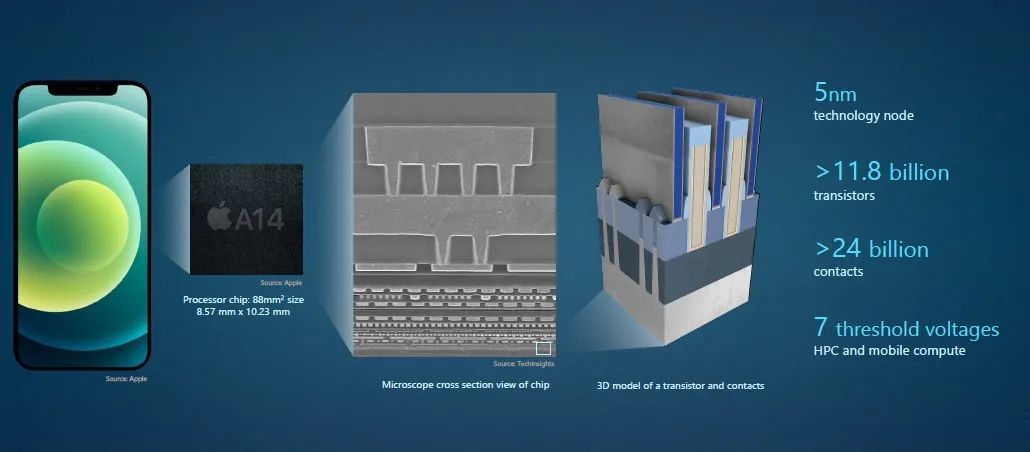
图1:苹果A14芯片拥有约120亿个晶体管和240亿个晶体管触点
然而,伴随着晶体管大小不断逼近原子的物理体积极限,传统摩尔定律下的2D微缩技术不再能同时改善芯片的性能、功率、面积成本和上市时间(即:PPACt),晶体管设计、互连微缩、图形化和设计技术协同优化(DTCO)成为横亘在逻辑微缩道路上的三座大山。我们需要综合地采用多种方法,更为确切地说,包括新的系统架构、新的3D结构、新型材料、缩小晶体管尺寸等新方法,以及能以新方式连接芯片的先进封装方案。
了解FinFET晶体管架构的人士都知道,FinFET包括三个主要模块:沟道和浅沟槽隔离、高K金属栅极(HKMG)和晶体管源极/漏极电阻。为了达到最佳性能,我们常常通过调整各种物理参数来提高晶体管的开关速度,例如鳍片高度、沟道栅极长度、沟道电子迁移率、开关时使用的阈值电压和帮助控制开关通断状态的栅极氧化物厚度等等。

图2:FinFET的主要模块是沟道和浅沟槽隔离(1)、高K金属栅极(2)和晶体管源极/漏极电阻(3)
在沟道和浅沟槽隔离模块中,业界之前的做法是在多个技术节点上增加鳍片高度并减小鳍片宽度以提高速度。然而,由于需要放置在鳍片之间的隔离氧化物会引起应变,鳍片越高、越窄,在制造过程中就越容易弯曲。这种弯曲会导致反作用应变,进而降低电子迁移率并影响阈值电压,由此增加晶体管的可变性。
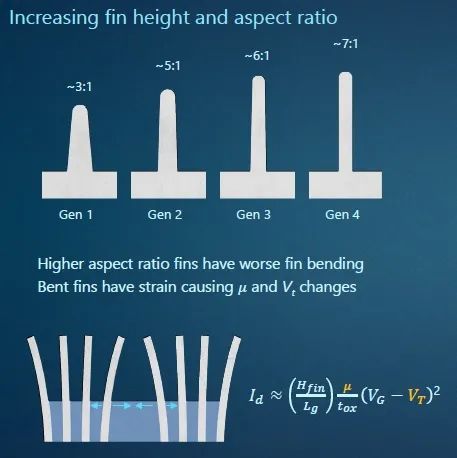
图3:随着FinFET不断扩容,形成晶体管栅极的鳍片变得越来越高、越来越窄,这使得它们在制造过程中变得更加脆弱、更加容易弯曲,因此降低了性能和功率效率
而在金属叠层非常复杂的HKMG模块中,包括界面层、高K层和金属栅极层在内的叠层数量最多可达七层。其中,界面和高K两层的微缩对于减少栅极氧化物至关重要,因为能否提高晶体管驱动电流将取决于此。但现实的问题是,由于14nm节点、接口和高K层的微缩速度与其他物理参数的微缩速度不同,就无法实现更高的晶体管驱动电流,我们因此需要能使接口和高K恢复同步微缩的创新方法。

图4:高K金属栅极叠层的横截面。微缩接口和高K层对于减少栅极氧化层至关重要,而减少栅极氧化物会提高晶体管速度。
再来看看晶体管源极/漏极电阻模块。统计数据显示,每次新的制程微缩工艺可使每个节点的晶体管接触面积减少了大约25%。面积越小,电阻就越大,金属触点和硅晶体管之间的接口电阻,以及源极和漏极区域内的外部电阻是主要贡献因素。

图5:晶体管接触电阻的主要贡献因素是金属触点和硅晶体管之间的接口电阻,以及源极和漏极区域内的外部电阻
于是,业界正在迅速转向采纳一种称为环栅(GAA)的新架构,其中硅鳍片方向旋转,层层重叠起来。GAA晶体管通过取代基于光刻和刻蚀的传统控制方法,提供了一种解决鳍片可变性的新途径。改用外延和选择性去除可以极其精确地控制鳍片宽度。从性能角度来看,GAA 架构可降低可变性,同时支持栅极长度微缩,将驱动电流增加10%至15%,同时降低功耗。

图6:在环栅晶体管架构中,FinFET基本上旋转到侧面,鳍片宽度控制的方法从光刻和刻蚀变为外延和选择性去除
你可能有所不知,在苹果A14芯片88mm2的面积中,堆叠了超过15层不同尺寸的金属,铜互连线数量超过上百亿条。如果放任自流,这些互联电阻的耗电量就将占到整个芯片的三分之一,并造成75%以上的阻容延迟,晶体管改进带来的好处将会被完全抵消掉。因此,降低互连电阻成为提高整体器件性能的最佳方法。
但人们对“互连微缩”常见的一个误解,是会想当然的认为,“既然晶体管性能随着尺寸微缩而提高,那么互连的金属部件也理应如此。”但事实上,数据显示,随着晶体管尺寸的缩小,互连通孔的电阻值会增加10倍,这不仅会导致阻容延迟,降低性能,还会增加功耗。

图7:互连通孔电阻随着工艺节点变小而升高,这会影响设备性能和功耗
互连由两个关键金属部件组成:一是在同一器件层内传输电流的金属线;二是在各器件层之间传输电流的金属通孔。下图展示了典型的铜互连结构中使用的三层薄膜:氮化钽 (TaN)阻挡层沉积在由介电材料制成的侧壁上,附着力良好,可防止铜扩散到电介质中;之后,钴(Co)衬底层附着在氮化钽势垒上,方便后续的铜填充;最后,铜利用“铜回流”工艺沉积到剩余体积中。
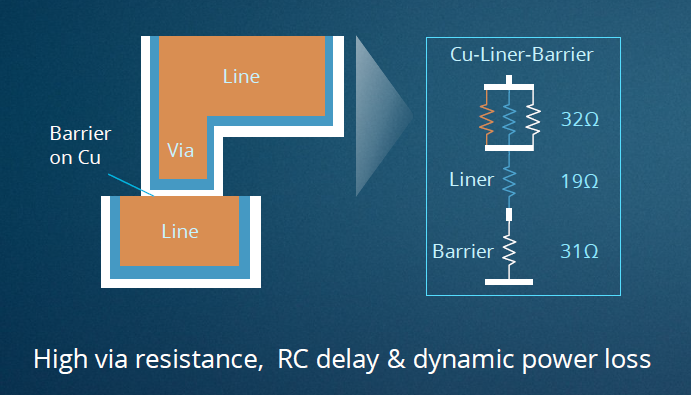
图8:典型铜互连结构的三层薄膜:氮化钽(白色)、钴衬里(蓝色)和铜填充材料(橙色)
这其中,氮化钽/铜界面对通孔总电阻的影响最大,降低电阻的最佳方法是完全消除该界面,但这只能通过开发选择性阻挡层沉积工艺,例如采用全新的铜回流技术,或是采用新的向晶体管传输功率的方式,例如“埋入式电源轨”。
那么,何谓“埋入式电源轨”?如图9所示,在当前的设计架构中,每个逻辑芯片都由标准单元组成,标准单元是提供特定逻辑功能的晶体管和互连结构组。每个单元也都需要空间,用于容纳信号线以及将电流从外部电源传输到晶体管的电源轨。但电源轨通常比最小的互连线大3倍,因此是影响单元尺寸的主要因素。

图9:电源轨通常比最小的互连线大三倍,因此是影响单元尺寸的主要因素
此外,在通往晶体管的途中,供电网络会穿过芯片的所有金属层,而金属层数量可以轻松达到12个或以上。这意味着,每通过一层,金属电阻都会导致电源电压显著下降。目前来看,设计人员能够承受大约10%的累积电压损失,但由于电阻随着每个节点的缩小而增加,如果没有新架构,配电网络可能会消耗50%的输入电源电压。
而“埋入式电源轨”架构的设计思路是将电源从晶体管下方的硅晶片背面传送到晶体管单元,从而带来以下三大好处:1. 将电压损失降低多达7倍;2. 允许晶体管单元面积微缩20-33%;3. 为信号线(也会因微缩而产生电阻)留出更多单元空间。

图10:具有背面供电网络架构的新型埋入式电源轨将配电网络移动到晶体管下方的硅晶片背面。采用这种架构,可以进一步微缩晶体管单元面积,允许信号线保持较大尺寸,将电阻保持在较低水平
众所周知,逻辑器件由大量执行基本逻辑功能的独立逻辑单元组成,每个单元都有几个晶体管栅极,通过金属线相互连接。从垂直方向上看,栅极之间相隔一定距离,我们称之为“栅极触点间距”;在水平方向上,金属线将栅极相互连接,而金属线之间的距离称之为“金属线间距”。将这两个间距相乘,就可以得出每个单元所占的面积。
在以前,业内使用光刻图形成像来缩小这些单元,使栅极和布线更薄、更细,使它们之间的距离更小,业内称之为“间距微缩”或“本征微缩”,这种方式带来了巨大收益。然而,随着工艺节点的不断缩小,物理空间迅速消失,导致无法继续将栅极和布线拉得更近。同时,将电气器件和结构放置在如此接近的位置也会导致信号干扰,进而降低设备性能和功率特性。
而如果通过设计技术协同优化(DTCO)技术,就能在无需改变光刻工序和间距的前提下降低面积成本,让逻辑设计人员利用新的材料和材料工程技术发挥巧妙创意,有望在未来节点中提供越来越大的整体微缩优势。
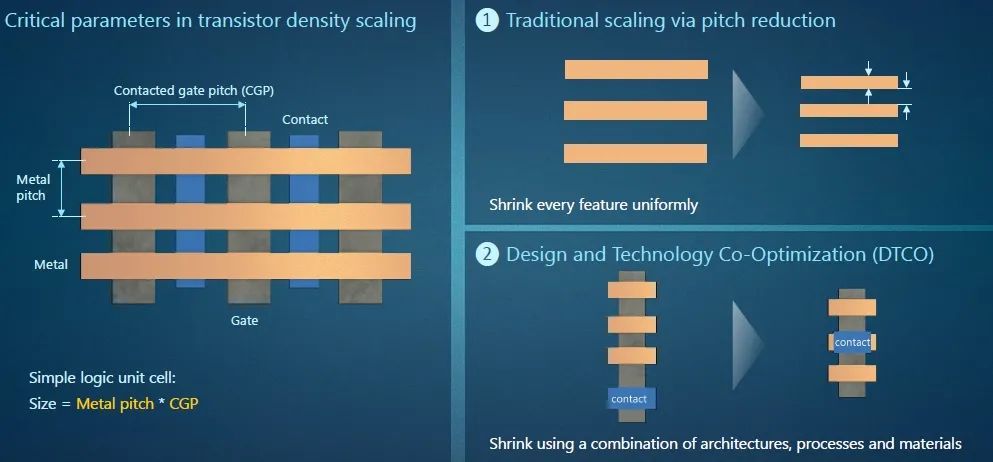
图11:栅极触点间距和金属线间距是决定逻辑密度的关键参数
我们可以用“房间改造”的例子来类比解释DTCO。简单来说,就是在土地面积有限的情况下,不用刻意缩小卧室来为办公室或游戏室腾出空间,而是通过加盖第二层楼或挖个地窖实现。当然,这可能需要额外的材料和工程,例如承重支撑材料以确保结构完整性,或者需要一些挖掘设备。
同样的逻辑,通过DTCO,我们可以在逻辑单元中将晶体管触点等关键元件从器件侧面移动到主动区顶部,然后即可在更小的空间内放置更多特征,这就是所谓的“有源栅极上接触”。此外,“单扩散区切断”也是逻辑芯片领域的最新发展成果之一,其中相邻晶体管之间的双绝缘结构被换作质量更高的单结构以节省空间。

图12:通过协同优化减少EUV曝光缺陷数量
不过,随着进一步微缩,另一个问题也日益凸显,那就是EUV图形化。如果能找到办法克服这一问题,就可以继续保持间距微缩的步伐。
理想状态下,为了实现可靠性和良品率,同时改善功率、性能、面积成本(PPAC),我们需要保持边缘平直、光滑。但实际上,每个特征的边缘都存在粗糙度和不均匀性。在以前,这不是什么大问题,因为边缘只占特征宽度的很小一部分,很大程度上可以忽略。然而,随着我们继续使用EUV进行微缩,边缘最多可以占到线宽的30%,光刻分辨率和线边缘粗糙度之间的取舍越来越重要。尤其是当我们增加多次图形化步骤的数量时,取舍变得更加重要,因为多图形化工序数量越多,对非均匀边缘的负面影响就越大。
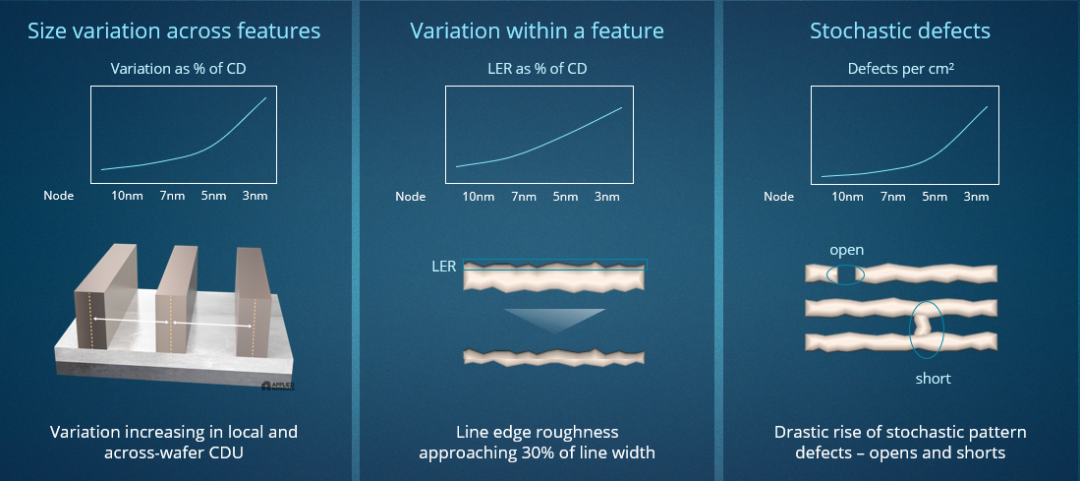
图14:EUV 图形化的主要挑战包括局部和跨晶圆临界尺寸均匀性(CDU)、线边缘粗糙度(LER)、开路和短路
有业内专家指出,“导致电气问题的图形化缺陷是采取这一路线所面临的挑战”。在某些位置,金属线两侧的边缘变化会产生极为细小的特征,以至于形成“夹断”,造成开路。而在其它位置,边缘粗糙度会导致相邻的线靠得太近,以至于相互接触并造成短路。
总结而言,改进逻辑器件中的PPACt需要在晶体管、触点和互连方面同时进行创新。虽然传统方法日益趋于极限,但我们可通过新的材料和材料工程技术实现新的解决方案。









