绑定手机号
确认绑定









arXiv上传2022年6月30日“PolarFormer: Multi-camera 3D Object Detection with Polar Transformers“,作者来自复旦大学张力教授团队。

自动驾驶中的3D目标检测旨在推理3D世界中感兴趣目标的“what”和“where”。现有的3D目标检测方法遵循以往2D目标检测的传统思路,通常采用垂直轴的标准笛卡尔坐标系。然而,这不符合自车透视几何性质,因为每个车载摄像机,都以径向(非垂直)轴成像几何楔形(wedge)内参,去感知世界。因此,本文提倡利用极坐标系,并提出一种极transformer(PolarFormer),以多摄像机2D图像作为输入,用于BEV空间更精确3D目标检测。
具体来说,设计一种不受输入结构形状限制、基于交叉注意的极检测头(Polar detection head),用于处理不规则的极网格(Polar grids)。为了解决沿极距离维度(Polar's distance dimension)的无约束目标尺度变化,进一步引入一种多尺度极表征(Polar representation)学习策略。通过几何约束下序列到序列(seq-to-seq)的方式,该模型从相应图像观测的光栅化最佳利用极表征。在nuScenes数据集上的全面实验表明,PolarFormer显著优于最先进的3D目标检测方案,并且在BEV语义分割任务上具有竞争力。
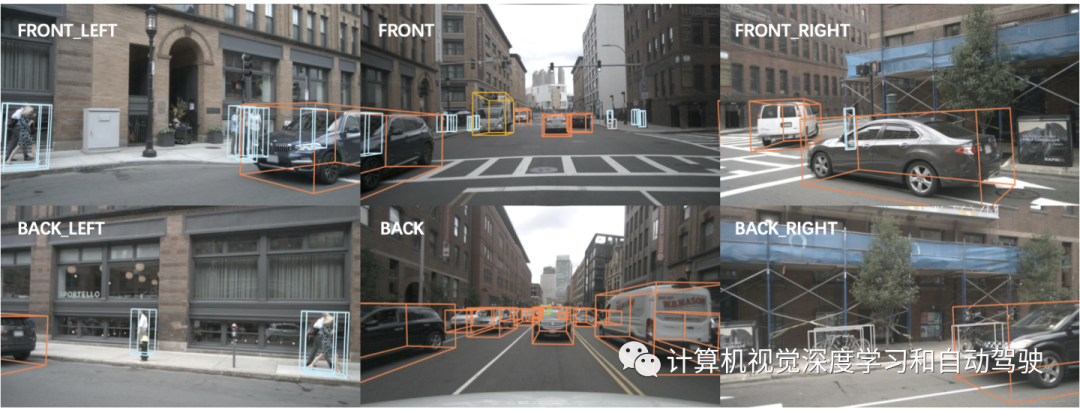
3D目标检测是在无约束的真实场景中实现自主驾驶的一种能力,旨在预测3D世界中感兴趣的单目标位置、尺寸和方向。尽管有良好的成本优势,但基于多摄像机的3D目标检测仍然有特别大的挑战性。为了获得3D表示,通常利用密集深度估计,但不仅计算成本高,而且容易出错。
为了绕过深度估计,最近的方法利用基于查询(query)的2D检测,学习一组稀疏和虚拟嵌入,用于多摄像机3D目标检测,但无法有效建模目标之间的几何结构。通常,在2D或3D空间中采用垂直轴的经典笛卡尔坐标系。这在很大程度上受到所用卷积模型的限制。
相反,在自车的透视图中,每个摄像机下感知的物理世界,是摄像机成像几何楔形内参的形状,具有径向非垂直轴。考虑到这种成像特性,极坐标系应该比通常采用的笛卡尔坐标系更合适、更自然地用于3D目标检测。事实上,极坐标已在一些基于激光雷达的3D感知方法中得到利用。然而,由于卷积网络仅限于矩形网格结构和局部感受野,其在算法上受到限制。
在3D目标检测中,得到了一组N个单目视图,包括输入图像和摄像头内外参。PolarFormer的目标是从多个摄像机视图中学习有效的极BEV表征,以便在极坐标系中预测目标的位置、大小、方向和速度。
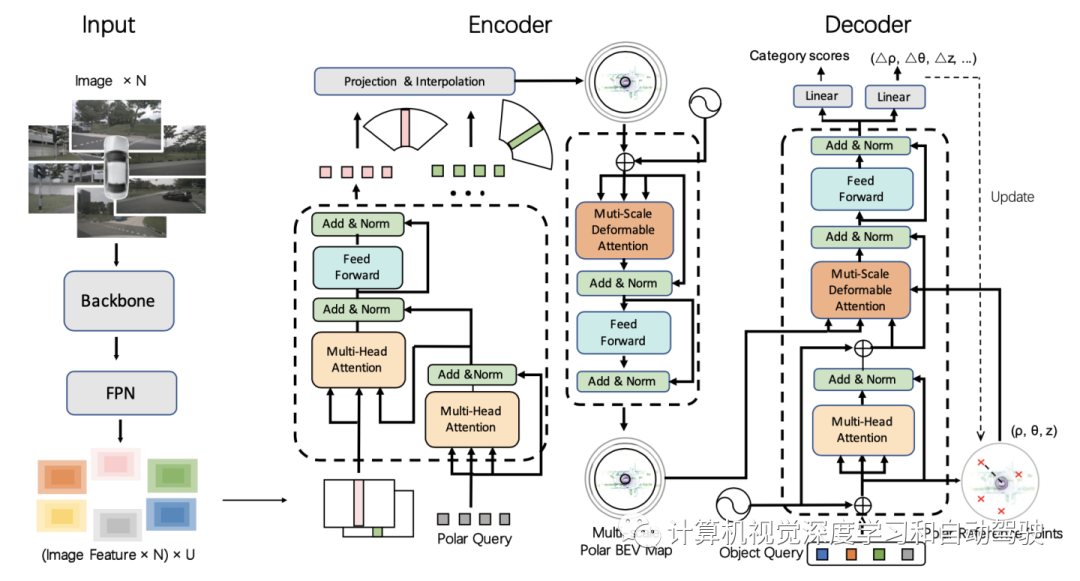
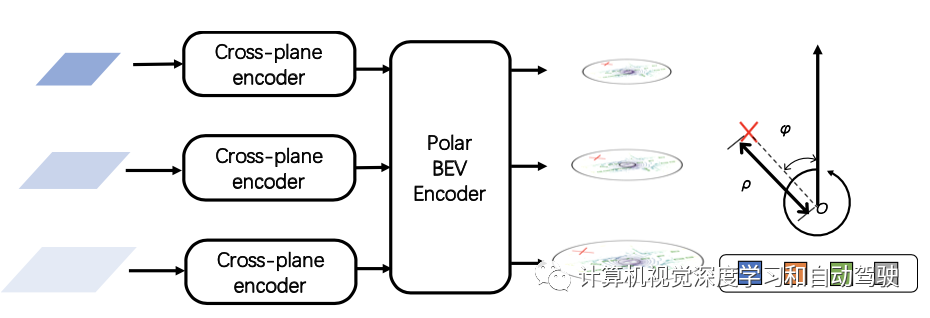
PolarFormer由以下部件组成:跨平面编码器首先生成每个输入图像的多尺度特征表示,具备一个跨平面注意机制,其中极查询(Polar queries )处理输入图像在BEV生成3D特征。然后,极对齐(Polar alignment)模块聚集来自多个摄像机视图的极射线(Polar rays),生成结构化极图(Polar map)。此外,极BEV编码器(Polar BEV encoder)通过多尺度特征交互增强极特征(Polar features)。最后,极检测头对极图(Polar map)进行解码,并在极坐标系中预测目标。
为解决具有多粒度细节的无约束目标尺度变化问题,考虑了一种多尺度极BEV表征结构。不同尺度的图像特征有独特的跨平面编码器,并在共享极BEV编码器中相互交互。然后,多尺度极BEV图由极解码头(Polar decoder head)查询。PolarFormer的总体架构如图所示:
跨平面编码器的目标是将图像与极射线相关联。根据摄像机的几何模型,对于任何摄像机坐标(x(C), y(C), z(C)),转换到图像坐标(x(I), y(I))可以描述为:

对任何极BEV坐标
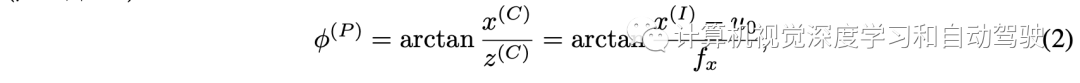
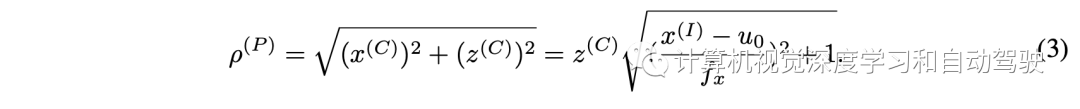
设fn,u,w表示来自第n摄像机、第u尺度和第w列的图像列,ṗn,u,w表示引入的相应极射线查询。跨平面注意力表述为:
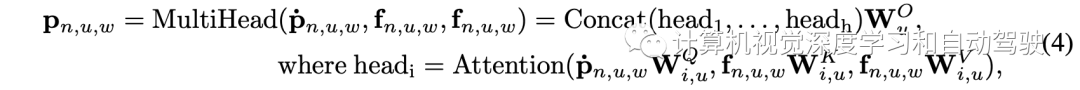
沿方位(azimuth)轴叠加极射线特征pn,u,w,得到第n个摄像机和和第u个尺度的极特征图(即极BEV表征)pn,u为:
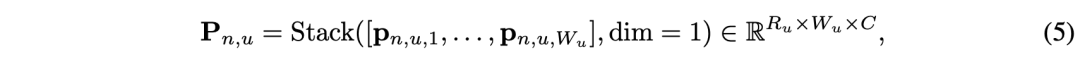
这种基于序列-到-序列交叉注意的编码器可以对几何成像进行先验编码,并隐式有效地学习深度的替代。
极对齐模块将极射线从不同的摄像机坐标转换为共享的世界坐标。以多视点极特征图和摄像机矩阵为输入,生成相干极BEV图,覆盖所有摄像机视图。具体来说,首先在柱坐标系中均匀生成一组三维点 G(P) = (ρ(P), φ(P), z(P)) 表示。然后将这些点投影到第n个摄像机的图像平面,检索极射线的索引如下:
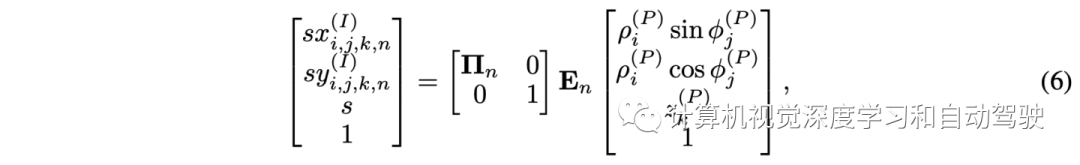
第u个尺度的相干极BEV图如下生成:

极对齐模块通过沿z轴生成这些点来整合不同高度的特征。学习极坐标表征优于笛卡尔坐标,因为信息损失最小,与原始视觉数据的一致性更高。
利用多尺度特征图处理极坐标中的目标尺度变化。为此,极BEV编码器在相邻像素之间跨多尺度特征地图执行信息交换。形式上,设{Gu}为输入的多尺度极特征图,xˆ为每个查询元素q的参考点的归一化坐标,引入一个多尺度可变形注意模块,如下所示:

作为查询,多尺度特征图中的每个像素利用相邻像素和跨尺度像素的信息。这样在所有特征尺度上学习更丰富的语义。
极解码器解码上述多尺度极特征,在极坐标中进行预测。构造有变形注意的极BEV解码器。
与编码器的2D参考点不同,这里的参考点位于3D柱坐标中,当投影到BEV时,等同于极坐标。每个解码器层的分类分支输出置信度分向量,回归分支的关键学习目标是极坐标,而不是笛卡尔坐标,如图所示:
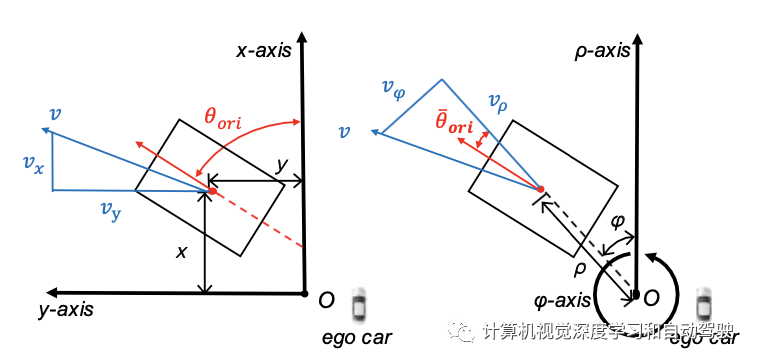
参考点(ρ,φ,z)在解码器中迭代细化。有了参考点,回归分支输出偏移量dρ、dφ和dz。方向θ和速度v的学习目标相对于目标的方位角,并分解除为正交分量θφ、θρ、vφ和vρ,定义如下:
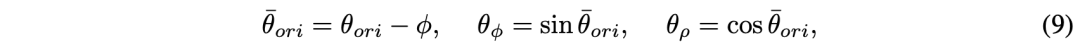
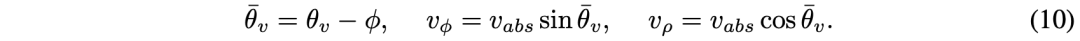
将目标大小l、w和h回归为对数l、对数w和对数h。分别采用focal loss和L1 loss进行分类和回归。如图是生成多尺度极BEV图的示意图:
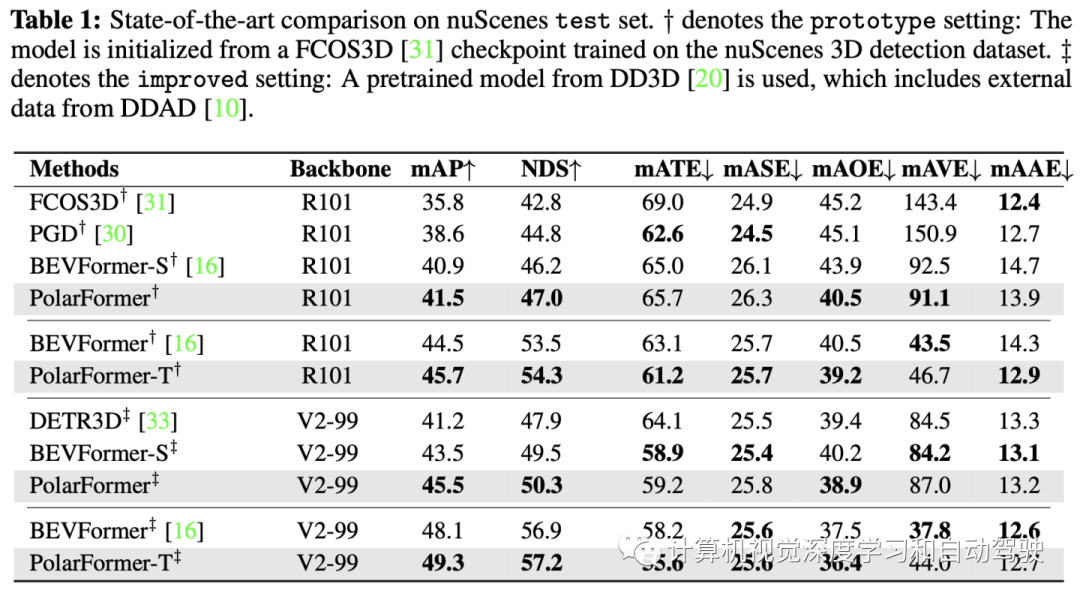
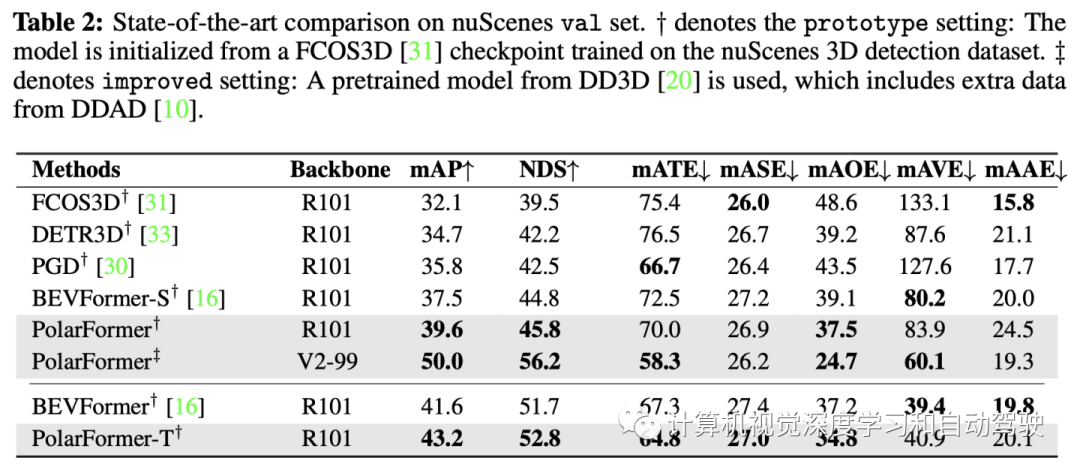
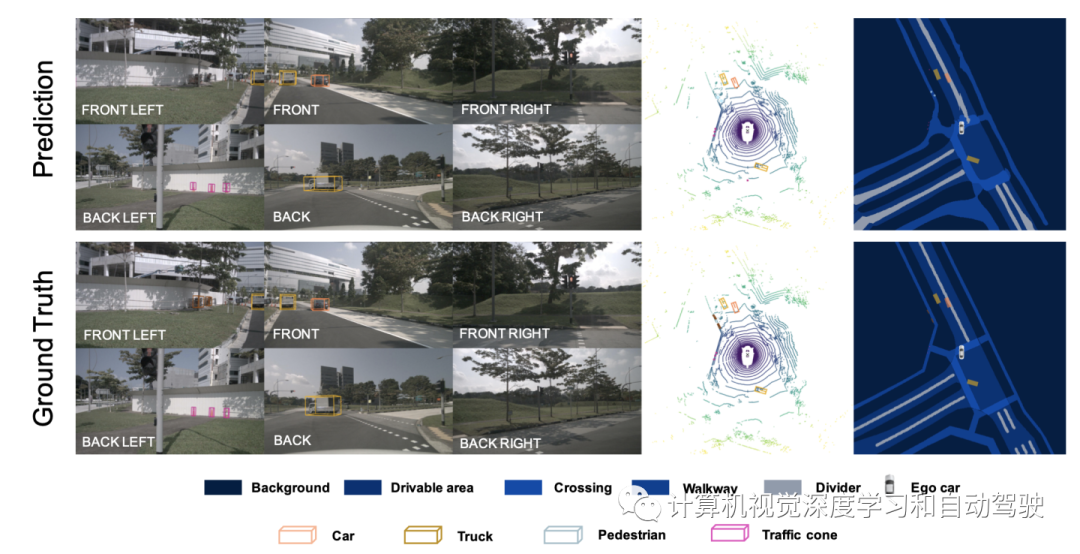
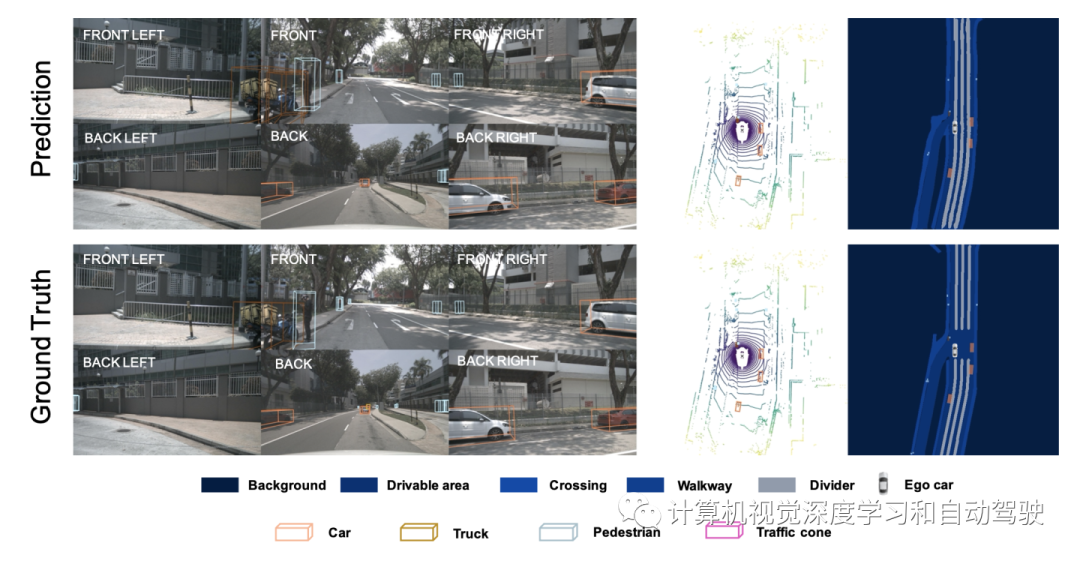
实验结果如下: