绑定手机号
确认绑定










论文地址:https://github.com/aim-uofa/Poseur
在很早以前我就隐隐约约有种感觉,姿态估计任务跟目标检测实在是太像了,但是目标检测当中很多的技术姿态估计都没有用上,存在很多可以借鉴的地方,虽然也曾出现过YOLO-Pose这种工作,但我总归觉得差了很多意思,框架套得非常生硬,终于在这篇论文里我看到了一个不错的形式。
Poseur也是本次ECCV 2022的中稿论文,在大概半年前的时候我在arXiv上刷到以后读过,当时的感觉是点数很高,但堆砌的技术很多工程味比较重。我个人其实不排斥工程味重的工作,FAIR的很多论文也是工程味满满,读完还是会有很多眼前一亮的感觉。唯一的问题在于这种论文的内容会比较多,需要花费更多的时间和精力去梳理。
之前机缘巧合在群里认识了Poseur作者,当时他也表示后面准备重写一下论文。正好前两天我看到Poseur开源,并且更新了arXiv上的论文,于是花了一个下午边读边写了这篇笔记。
本篇笔记我强烈建议读者具有以下前置知识:
RLE
Transformer
DETR和Deformable DETR
当然,如果没有的话也没关系,我会对这些内容进行一些解释,但还是建议大家之后去学习一下,都是前沿的重要的知识。
RLE可以阅读我的专栏笔记,Transformer和DETR我推荐b站沐神的视频(搜索跟李沐学AI),Deformable DETR我推荐CW的文章《Deformable DETR: 基于稀疏空间采样的注意力机制,让DCN与Transformer一起玩!》
https://zhuanlan.zhihu.com/p/372116181
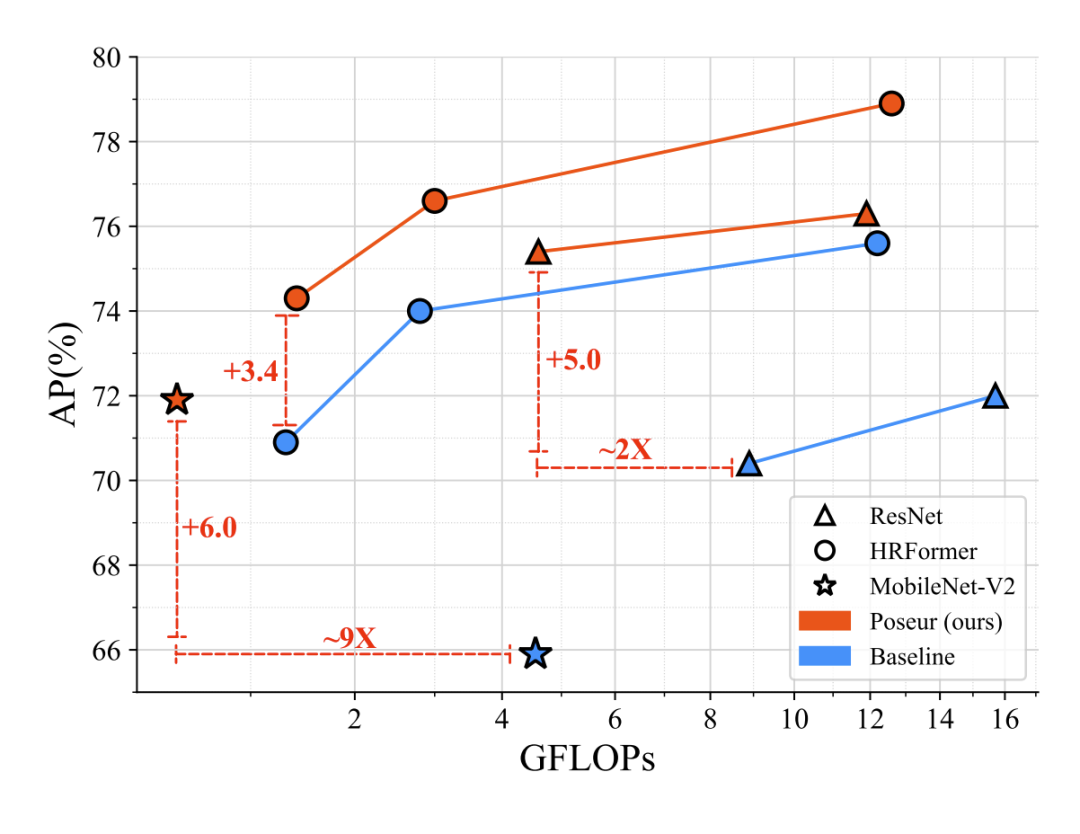
首先从论文标题也可以看到,Poseur是属于Regression-based方法。我认为这篇工作最大的亮点在于,它在Regression方法和Transformer的结合上进行了细致的设计,最终在COCO val上刷到了AP79.6,test-dev上AP78.3,相较于之前的SOTA如HRFormer的77.8/76.2,和我介绍过的ViTPose取得的79.8/78.4已经完全不遑多让了。作为一种Regression-based方法,Poseur在计算量和运算速度上有着显著的优势,并且能用MobileNetv2作为backbone取得媲美ResNet50+SimpleBaseline的效果。
问题分析
本文分析了之前的Regression方法的不足,认为主要有三个方面限制了它的性能:
卷积特征后常见的GAP操作破坏了特征图的空间结构
局部卷积特征所在的区域,跟目标点位置存在错位问题
直接回归坐标值不能很好地捕捉到相连关节的结构信息
这里我用自己的话简单解释一下:
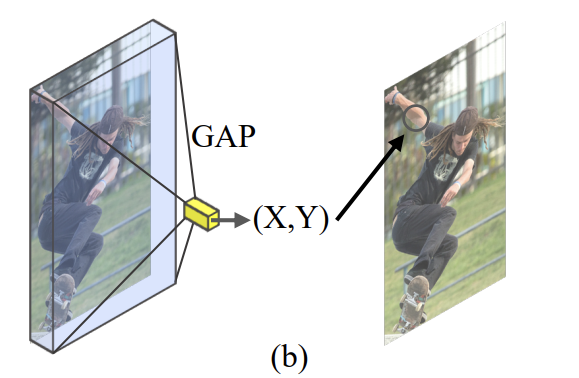
第一点针对的是Deeppose和RLE这种类似于分类网络的结构,backbone输出的特征图会送进GAP层压成一条向量,然后用全连接层把这个向量回归成坐标。这种方法存在的问题是,GAP操作非常粗暴,把一张平面上的所有像素压成一个像素,不难想到,会有无数张响应位置不同的图,压缩后的像素值是一样的,这让网络的学习目标变得不确定。
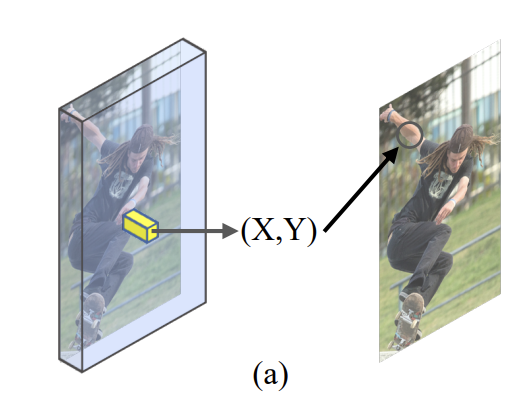
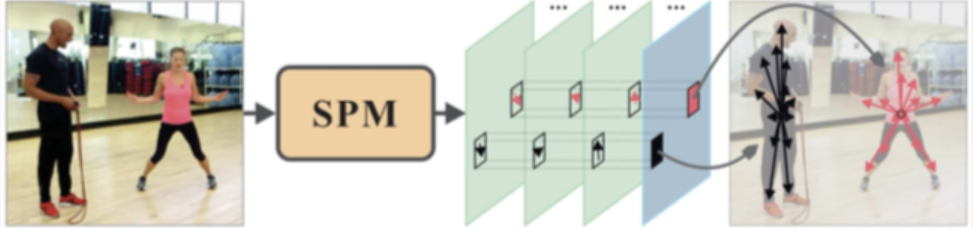
第二点针对的主要是一些利用局部卷积特征来回归坐标值的方法,比如SPM和UDP等检测+回归形式的方法。这种方法的问题在于,回归坐标值时使用的特征取决于heatmap响应点,而响应点往往是目标的几何中心,这就意味着网络要用这块区域的特征去预测一个比较远的坐标,这会使得特征所在的位置,跟目标位置之间存在一定的偏移,这种偏移会增加学习的不确定性和难度。论文里给的这张图其实我觉得不够直观,我再配一张带箭头的或许能帮助大家更好理解,SPM方法是用人体中心点那一块的卷积特征去预测箭头所指的位置:
第三点其实可以扩展来讲,因为直接回归的方法严格来说是比Heatmap方法能学到更多的结构信息的,这也是为什么Regression方法对于遮挡、罕见姿态的鲁棒性更好,但是,Regression学到的这种结构信息是全局无差别的,换句话说,模型学到的是所有点之间的相对位置,并没有学到“哪些关节点是物理上相连的”这种知识。假如一个数据集里左手食指跟右手食指的关键点碰巧存在一定的相关性,模型在预测时也会倾向于让这两个点联动,仿佛是认为这两个点相连一样,这显然是不符合我们期望的。
既然明确了问题,本文给出的解决方案是什么呢?我尝试总结如下:
GAP有问题那么我们就不用,为了最大程度利用空间信息,我们甚至可以把backbone不同stage的特征都用起来(类比FPN)
检测+回归的结构天然会导致响应点跟目标点存在偏移,所以我们采用Deformable DETR提出的deformable attention去动态匹配局部特征
Regression缺乏关键点之间关联程度的学习,所以我们用Transformer中的self-attention来捕捉结构信息
而除了以上改进以外,本文还针对各种细节进行了优化,这也是为什么我认为本文工程性很强的原因:
训练时添加人工噪声来增强decoder解码的能力
用RLE回归预测的结果作为粗略位置指导deformable attention匹配局部特征,并且是把RLE结果作为位置编码加到特征里的形式完成的
改进deformable attention所用到的MSDA(multi-scale deformable attention)模块,用双线性插值来代替线性映射,保持性能不变的情况下降低计算量
改进score计算方式,用似然概率函数在均值附近区域的概率积分作为score,显著提升了AP分数
综合以上改进,最终便得到了Poseur的模型结构图:
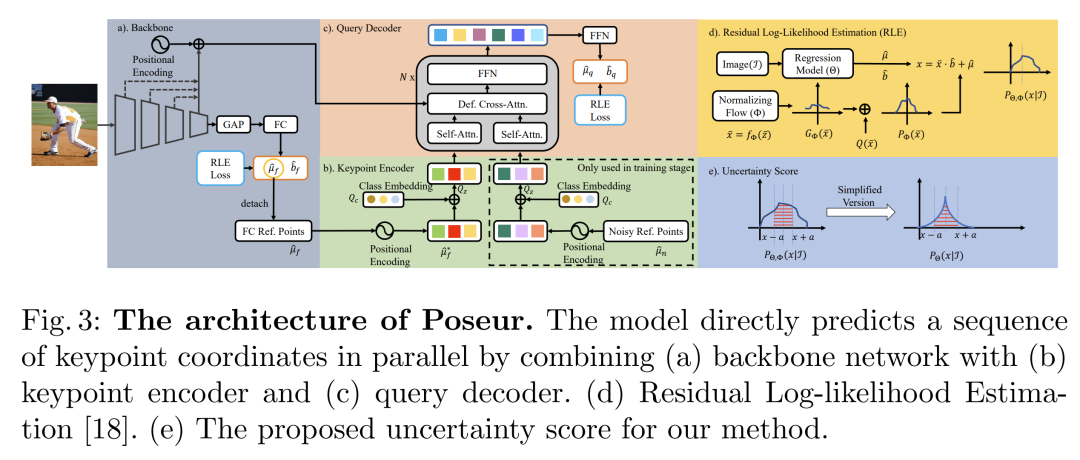
看到这张图有没有觉得头有点大?而且上面列出的改进内容也许有些技术点也是你不熟悉的,没关系,接下来我再逐个梳理一下。
根据这个模型图,首先我们庖丁解牛把模型拆分成三个部分:
Backbone
Keypoint Encoder
Query Decoder
Backbone
Backbone部分大致上是遵循了RLE的做法,卷积特征经过GAP后用FC来回归坐标值,不同之处有两个:
第一是此时FC出来的坐标并不会作为模型的最终预测结果,原因我们在前面解释过了,GAP对空间信息的破坏会损害模型精度,所以我们只把它作为一个粗略预测,用来引导特征匹配,也许你不清楚“引导特征匹配”是什么意思,没关系后面我会解释。
第二是使用Backbone本身的特征图,不同stage的特征图作为多尺度特征一起送入后面的decoder进行坐标预测,不再使用GAP,从而避开GAP的损害。
由于这部分整体上是遵循RLE范式的,因此作为特征提取器的Backbone可以任意变更,坐标值的监督也可以继续用flow模型来提升精度。
Keypoint Encoder
这部分开始我们用到了Transformer的知识了,Transformer中很重要的一个东西我认为是query思想,不同于CNN输出的特征图会在空间上跟输入图片一一对应,而Transformer会维护一组可学习的query参数,一般称为Token,输入图片经过转换后每一块区域也会作为一个Token(当然也可以称为embedding),于是这些query token就会像查字典一样去跟每一块图像token进行比对(cross-attention),query token之间也会互相比对进行区分(self-attention)。这种query token的训练某种程度上其实类似于在模型结尾放一个FC,但不同之处在于结尾放的FC只能根据模型的输出特征进行训练,而Transformer中的query token会在每一层都结合当前的特征进行调整,这个由粗到精的过程理论上来说能得到更好的结果。
这样一种形式在DETR中被用来作为目标检测anchor的学习方法,即一组query token代表了一组原始的没有指定类别的anchor,在一层层推理过程中赋予它类别和目标大小。在TokenPose中则是直接用query token对应每个关键点,让推理过程类似于token去特征图中挨个比对,找跟自己最相似的图像token获取信息,从而定位关键点。
本文延续了类似的思想,用K个query token作为可学习的关键点token,不同之处,或者说高明之处在于,本文运用了Deformable DETR中提出的scale-level embedeing的思想。
在最原始的Transformer论文中,由于自注意力机制中token之间是没有位置信息的,因此提出了位置编码来标记token位置。而Deformable DETR中由于使用了多尺度特征,这种位置编码就会存在歧义了,因为不同层的特征点可能有相同的坐标,于是提出每一层都带一个可学习的embedding,在这个embedding上加位置编码从而区分开每一层。
本文运用类似的思想,巧妙地把RLE预测的结果用三角函数转成了位置编码,加到query token上,从而赋予了query token先验位置信息,让原本漫无目的全图找目标的query token有了更多可以参考的信息。
这个部分虽然称为Encoder,但是实际上跟我们一般模型中说的Encoder是有区别的,因为这部分只做了坐标编码转换和相加,没有别的计算层。我个人感觉如果在这部分嵌入一些Transformer Encoder对特征和query token进行学习,没准儿效果会更好,当然,参数量和计算量也会因此变得很高,从论文的角度来说这样会掩盖性能提升的说服力,毕竟增加了这么多参数。
Query Decoder
既然已经提到DETR和Deformable DETR了,接下来的Decoder依然是对二者思想的运用。
DETR之所以火,原因在于用query token作为anchor的形式可以免去NMS操作,100个query token输出100个bbox,自注意力和交叉注意力保证了这些anchor之间尽量不重复预测同一个对象。而匈牙利算法为预测的结果分配gt,带火了一系列动态匹配机制在目标检测中的运用。
到了Deformable DETR时,认为每个query都要跟全局每个token比对实在太重了,而且效率不高,应该动态地从全局位置采样一部分位置上的token来计算就够了。
那么采样位置怎么选择呢?简单来说,给一个参考点,然后围绕这个参考点取样。这个参考点从何而来呢?还记得前面我们得到的RLE预测的结果吗,那不正是参考点的绝佳选择。此时再运用动态卷积的思想,参考点周围的采样点并不一定要是规则排列的,我们可以为每一个采样点位置学习一个偏移量,从而就能根据图片在参考点周围不同位置采样。
有了采样点坐标后,我们就可以从特征图的不同位置上采样了,由于采样点坐标可能不是标准的整数,因此用到了双线性插值,来保证整数坐标之间的像素位置也能采样。基于这些采样点跟query token进行交叉注意力计算,更新query,如此一来,query token跟图片token的信息交互也高效地完成了。
最终Decoder输出的K个query token的结果,再用一个MLP回归成坐标值即可,对于这个坐标我们还能再玩一次RLE,用一个新的flow模型来强化最终预测坐标的监督。
除开主体以外,本文还做了很多其他的优化。
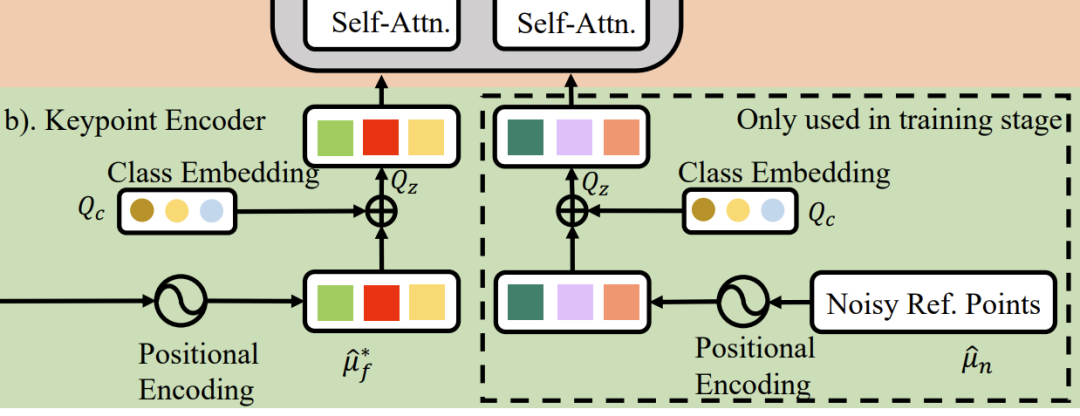
Noisy reference points sampling strategy
首先,由于我们知道RLE给出的预测结果是不够好的,于是自然而然地就需要Decoder的能力强一些,能即使在参考点不那么靠谱的情况下也能得到不错的采样结果,预测出更精确的坐标。
于是本文设计了一个人工噪声的模块,用人工生成的随机坐标作为预测参考点送进Decoder一起训练,要求模型预测正确的结果,给Decoder负重训练了属于是。在训练结束后扔掉,推理时使用RLE的结果作为参考点。
也就是下图的右边部分:
Efficient multi-scale deformable attention(EMSDA)
原始Deformable DETR中提出的MSDA模块在获取采样值时需要进行线性映射聚合特征,本文实验发现这一步可以用双线性插值代替,从而降低了计算量,实验结果显示这样做能取得相同的性能。
Human keypoint score
传统的Regression-based方法由于直接预测坐标值,对于每个结果实际上是没有score的,往往会直接把score设为1。而Heatmap-based方法则会选取响应值最大点周围的一块方形区域,计算响应值之和,实际上也是这块区域的似然概率积分,作为keypont score。
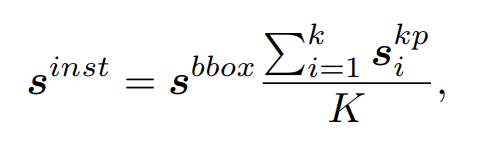
在RLE方法中用预测的sigma值作为score,但实际上并不是那么恰当。本文提出也应该使用似然概率函数在均值点附近的积分来作为score。
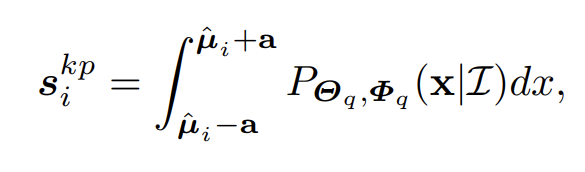
要得到似然概率值,就需要结果flow模型,但在RLE中,本来在推理阶段是不需要运行flow模型的,如果在本文把它加回来并不是一个好的做法,这样会平白增加很多运算量,而且对于模型部署也非常不利(flow模型这种冷门的东西如何部署我也没研究过)。最终本文发现,退而求其次,用标准Lapalce分布作为概率密度函数能取得差不多的性能,于是问题瞬间得到了简化:
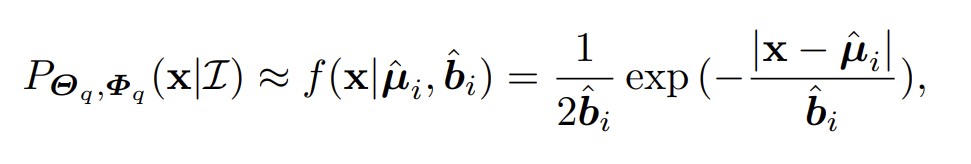
最终keypoint score能非常容易地计算得到:
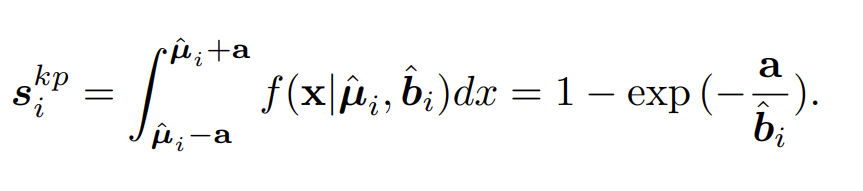
终于讲完了本文的核心方法,来看一下Poseur的表现:
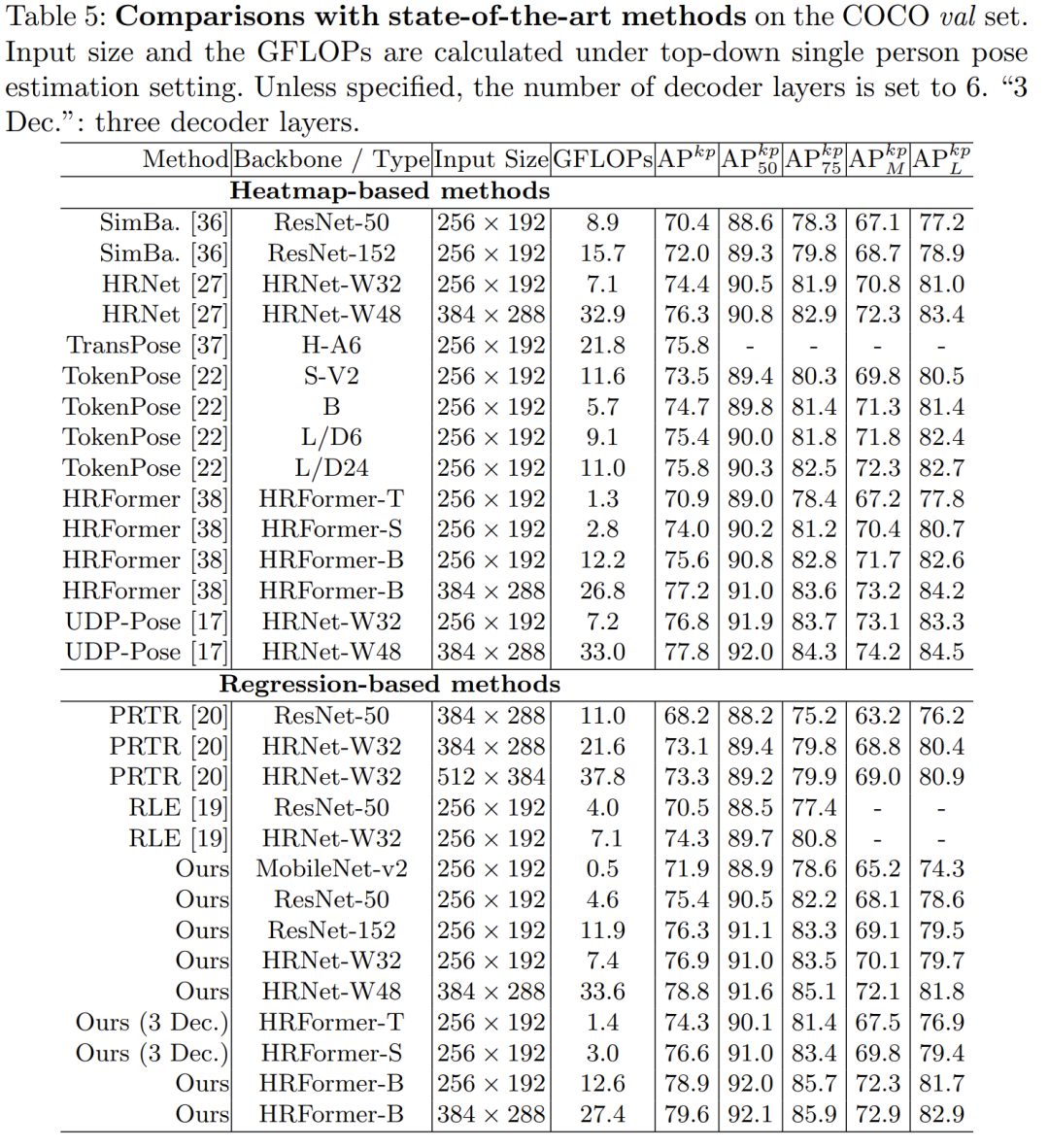
可以看到作为一个Regression-based方法使用相同的backbone能比之前的UDP-Pose高1个点,比起RLE有4.5个点的提升。
另外大家应该也感觉本文包含的技术真的不少,因此实验部分也很多,我挑选一些我比较关注的贴出来:
噪声参考点策略

噪声策略为模型带来了0.6个点的提升,因此看起来是的确能增强decoder的能力,我觉得换个角度也可以认为,就算采样点不那么准,那也就是跟之前SPM的情况差不多嘛,因此这种随机采样也可以看成是给decoder加正则了。
概率积分作为score
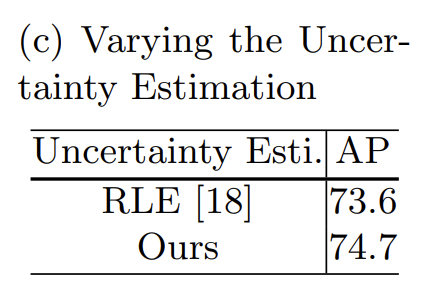
这一策略相较于RLE提升了0.9个点,相较于直接把score赋值为1提升了4.7个点。
Decoder层数选择
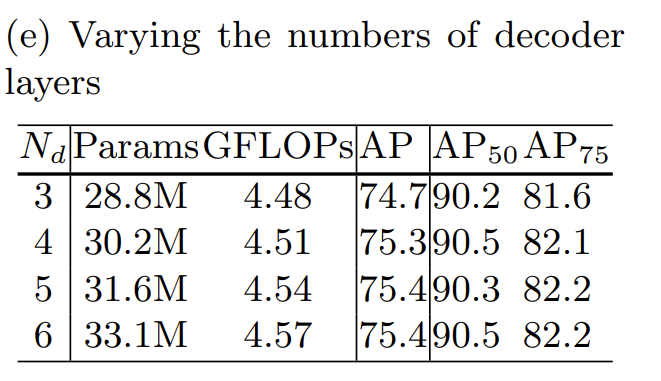
Decoder层数带来的性能提升在6层达到了饱和,但是如果不是刷榜打比赛的话,我感觉4层是一个比较经济实惠的选择。
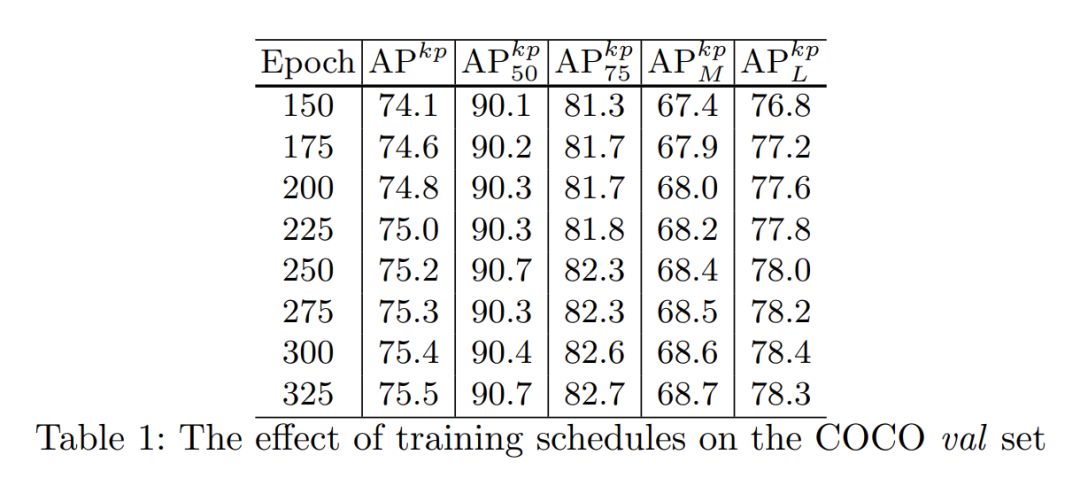
训练epoch
另一个需要说明的点是,本文报告的结果是训练了325epoch的结果,而过往的工作一般是270或者250epoch,本文在附录里也进行了解释,在250和270的时候本文的结果也已经超越之前的工作了:
自注意力可视化
对于各个关键点之间的自注意力权重可视化还挺有意思的,我第一次看到这种形式,之前都是相关性矩阵那种图:

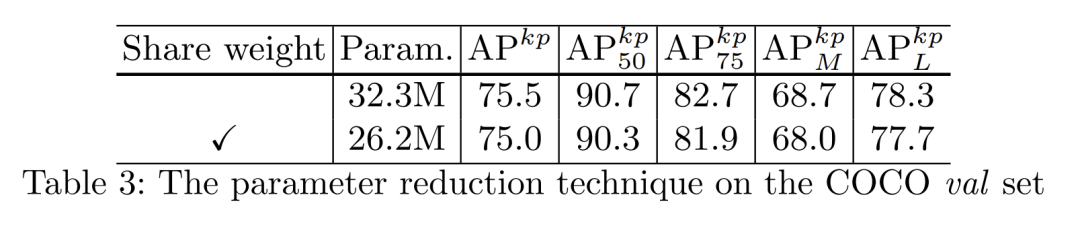
共享参数
在DETR中也指出,后面的decoder实际上是在做一个coarse-to-fine的过程,即对预测结果进行逐层精炼,因此decoder除了可以定义多个层,也可以只定义一层,然后循环执行,把每次输出的结果又送给自己推理做一遍。本文的实验显示这样做在本文的方法上同样有效,能用一点点性能下降换取不错的参数量降低:
EMSDA
关于MSDA的改进实验: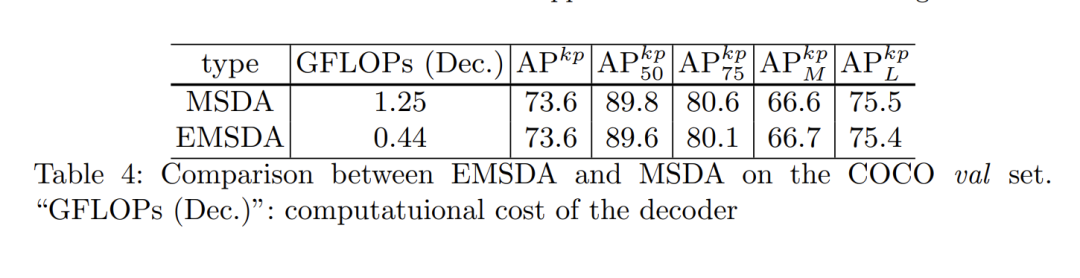
相信读到这里,你也会感慨这篇工作受目标检测的DETR和Deformable DETR影响之深,我在很早之前开始也一直有姿态估计的最终形态也许会是另一种目标检测的感觉,而且严格来说整个CV领域的技术共同性都是非常高的,因此我也一直不曾把自己的目光局限在姿态估计上,图像检索、目标检测、NAS、蒸馏、多模态等工作我也都常常保持着关注,我相信这会对我们都有所帮助。
另外本文作者已经表示之后会将Poseur整理好后贡献给MMPose,感兴趣的小伙伴可以期待一下,来给MMPose点个Star~








