绑定手机号
确认绑定









很多网络相关的论文第一句通常是由于网卡buffer有限,所以xxxx,本文对buffer做了xxxx 但是为什么不直接在网卡上把Buffer变成内存呢?然而人们又会走入另一个误区,大buffer会带来大延迟,大延迟会带来低吞吐。
同样对比显卡上的显存,它出现了几十年了,所以我们先来回顾一下显存的发展史,如果显存是一个buffer结构,也就不会诞生GPU、同样也不会诞生CUDA了,然后就会非常清晰看到NetDAM赋予网卡内存的价值,等同于再造一个CUDA,当然这一次nVidia不会像GPU那么幸运,DoCA也不会那么简单的一统江湖,因为RDMA本身的生态会成为他们的绊脚石。
早期的计算机通常是以纸带的形式提供交互。阴极射线管(Cathode Ray Tube,CRT)的发明才带来了早期的显示器技术
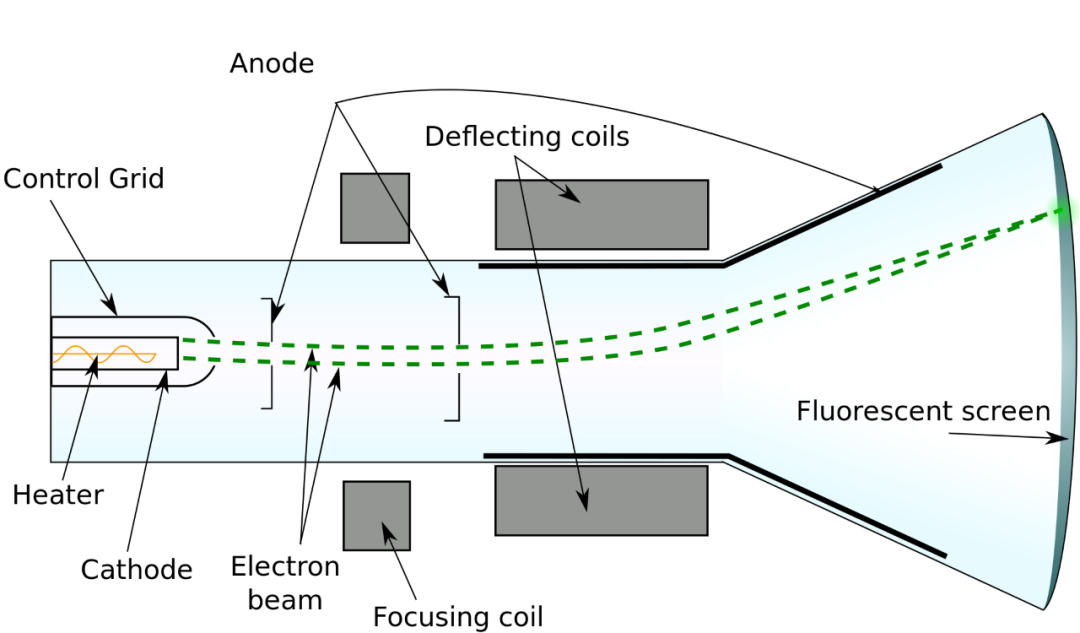
1960~1970年有了一些实验性质的显示器被发明出来,而真正的商用大概可以算到1971年的DataPoint 2200和1976年的Apple I,油管上有一段视频[1]

可以看到这个时期的电脑还是没有单独的显卡和显存的概念的,而显存本身的实现也只是一个移位寄存器的结构。wiki上有这段历史[2]的介绍.
真正的第一块显卡可能要从IBM1981年发布的PC说起,IBM做了一款叫做Monochrome Display Adapter[3]的设备,基于ISA总线,然后内涵一个Motorola 6845的显示控制器和一个4kB的内存。显示接口还是DB9接口

然后可以通过一个硬件实现的码表(Code page 437)来实现数字信号到像素渲染的转换过程,这块卡还很有趣的支持了打印机输出的功能,可以看到当时的I/O设计思维还是一个逐渐从纸质介质迁移到电子显示的过程,只不过还是以字符为主,然后便是CRT显示器分辨率逐渐提升,同时彩色显像管技术的逐渐普及而带来的I/O带宽提升 2.png
当然伴随着彩色显示器的使用,VGA接口也诞生了,三原色的各自输出信号配合VS、HS水平、垂直扫描同步信号可以非常简单的去控制阴极射线管偏转。而那时显存的形态还是以Frame Buffer的形式存在的,通常前面还有一个SRAM配合DSP进行模拟输出转换的器件(RAMDAC,Random Access Memory Digital-to-Analog Converter).
显示技术的进步也为彩色图形化界面的操作系统诞生提供了必要条件,伴随着1985年Windows 1.0系统的发布,1987年成立的Trident和1989年成立的S3逐渐成了2D显卡的王者。而显存本身也逐渐出现了技术的融合,从专有的双端口DRAM结构也逐渐的换成了同时期的内存颗粒,例如EDO、到后期的SDRAM、DDR
1995年,3Dfx发布了第一块Voodoo显卡,算是将整个计算机图形业带入了3D时代:

这也是从传统的Frame-Buffer Memory到了一个可以计算的像素内存的转变过程
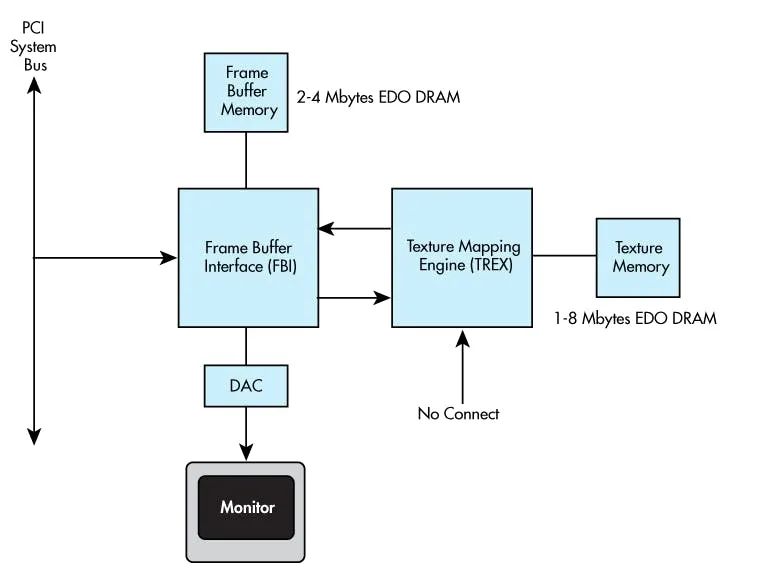
软硬件的融合也伴随着Windows95的发布出现了DirectX以及后期的OpenGL这样的2D、3D矢量图形渲染的API接口。而那一年nVidia也发布颇为成功的Riva 128,以及后续逐渐登上王者宝座的TNT,那一年Intel也还生产一个叫i740的显卡。只是一晃20多年过去了,2022年这场nVidia vs ATI(AMD) vs Intel的战争又悄然打响了。
而这个年代伴随着更为灵活和可编程的像素着色引擎和顶点着色引擎,使得计算机3D图形显示能力快速增长,新的算法也层出不穷。
但是这个阶段的图像处理还是有很明显的pipeline的特征:
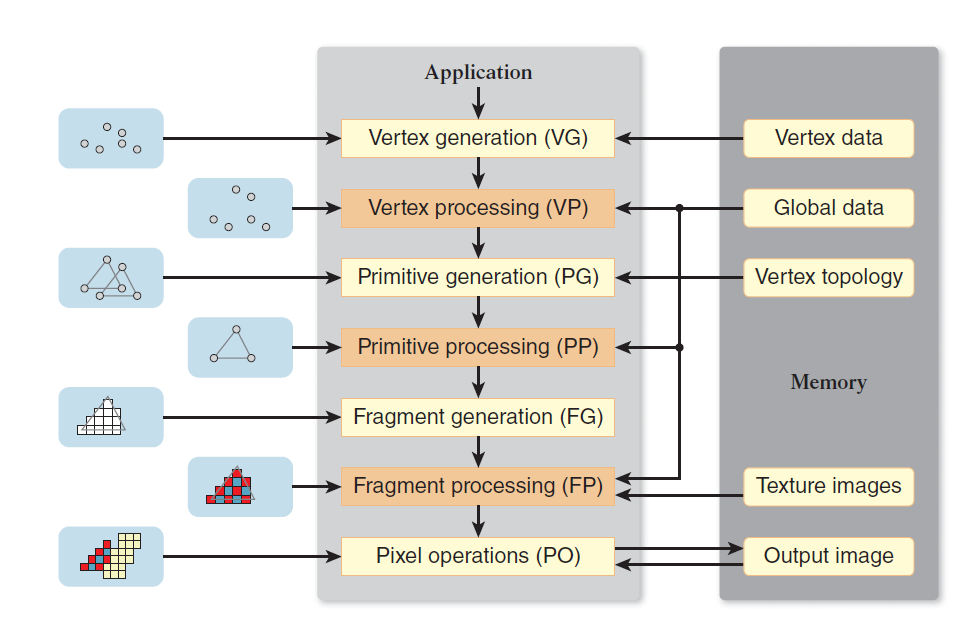
对于传统的显存操作,下面这本书有一段讲的非常清楚:

面对内存的一致性问题,一个架构师必须要在这个时候针对实现者和用户之间的冲突进行最优的权衡。而这样的权衡便是GP-GPU的诞生。显卡内出现了相应的指令集、ALU、Cache的架构:
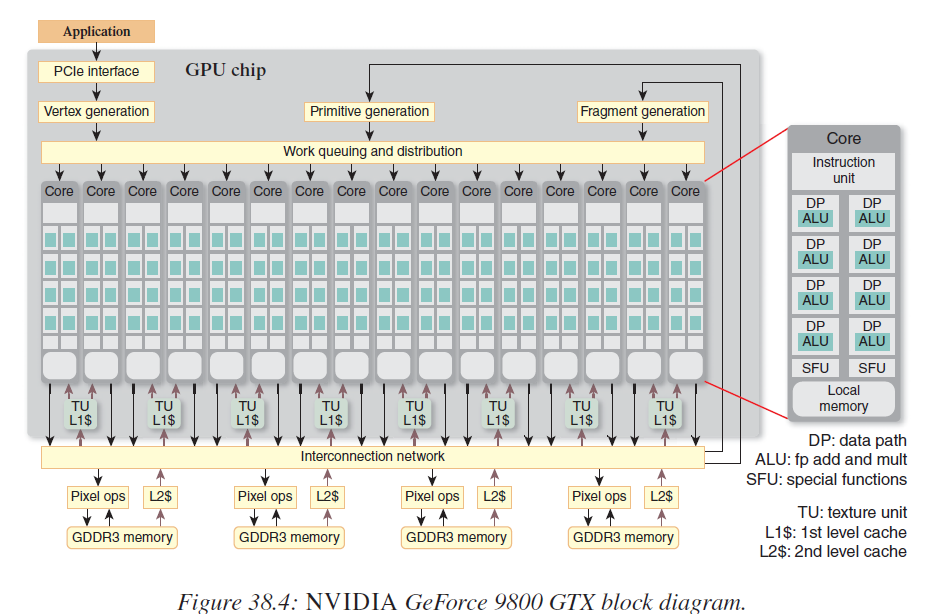
而与之对应的CUDA也就顺理成章的诞生了,潘多拉的墨盒就此打开。
回顾了整个GPU和显存的发展史,从buffer到pipeline的处理再到灵活的基于CUDA的可编程,显存的形态也伴随着GPU架构的变革产生了很多深远的影响。再来看看DPU的场景,只是比显卡可能更加复杂一些,因为GPU的诞生和数据密集性发生在终端,例如DisplayPort的带宽远高于现在很多PC的网络带宽。
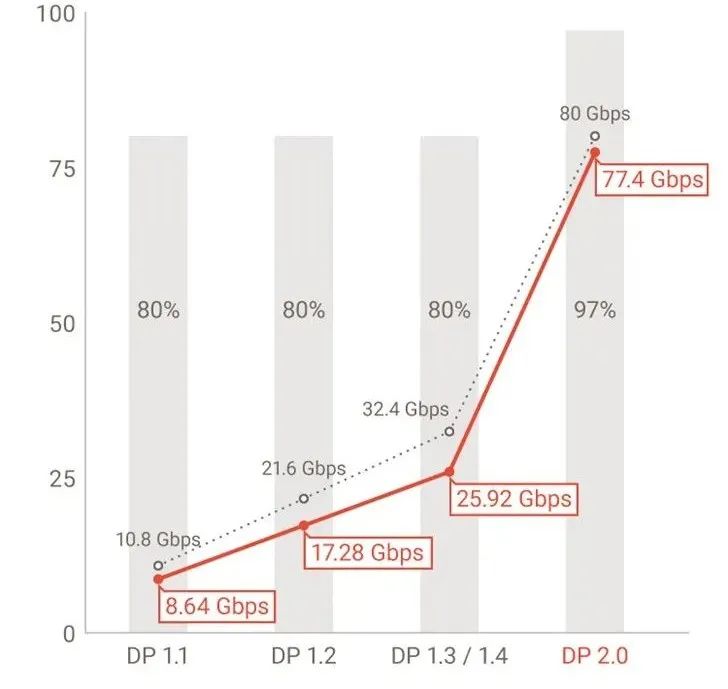
而网络的密集处理则最早发生于核心网上的网络处理器(NP),网络处理器也逐渐的经历了前述的进程,也曾因为I/O密集度的问题,采用过流水线的架构,并且深远的影响到了现代。同样也因为流水线架构内存访问的困难出现的各种多核并行计算的NP。而这些NP玩家现在又逐渐入局到DPU的产业中。
而如今这个年代和1997年的GPU很像,固定的流水线处理,网卡上的内存更多的是以Buffer只读形态交付,可编程的难题依旧存在。而RDMA和当年的OpenGL更有几分形似,缺少更多灵活的可编程性。DPU也亟待像GTX9800那样使用ISA和ALU打开整个GP-GPU潘多拉魔盒的产品。
渣仰望nVidia这样的大厂,但是并不是很看得起Mellanox,RDMA会如同当年的Glide 3D拖死3Dfx那样给Mellanox带来大量的麻烦,IB虽然非常赚钱但是生态并不好。有些时候生态的变革要抛弃自己的过往,平滑的走向新世界。
RDMA的API本质上还是以内存操作为中心,对于存内计算等场景还缺少太多的支持 而后续虽然有DoCA,只是笑笑而已,ARM多核这样的RTC系统对于网络处理还是太重了,核太大并不是好事情,很多东西并不一定需要,而Tenstorrent则干的非常干净:
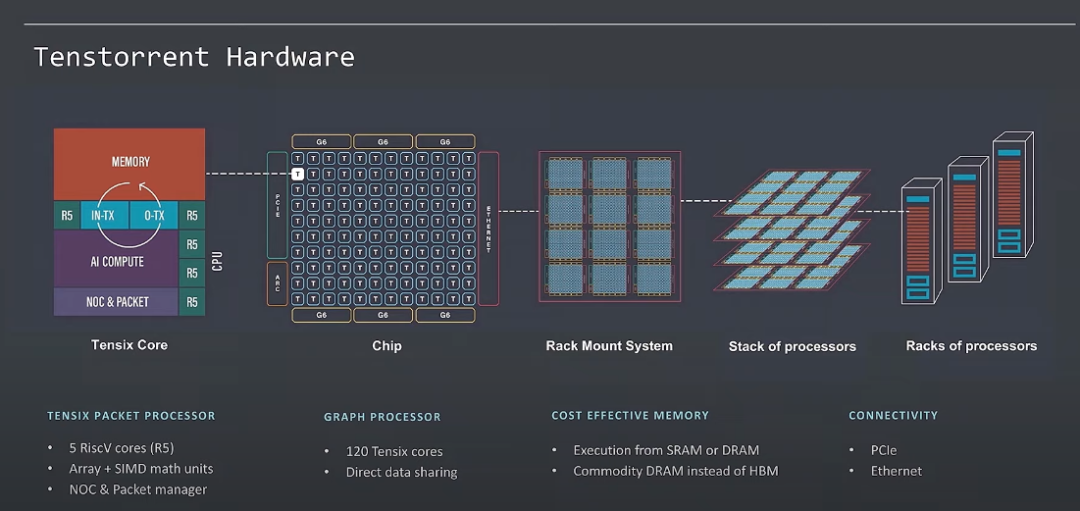
这也是我们很多年前设计Cisco QuantumFlow处理器总结的经验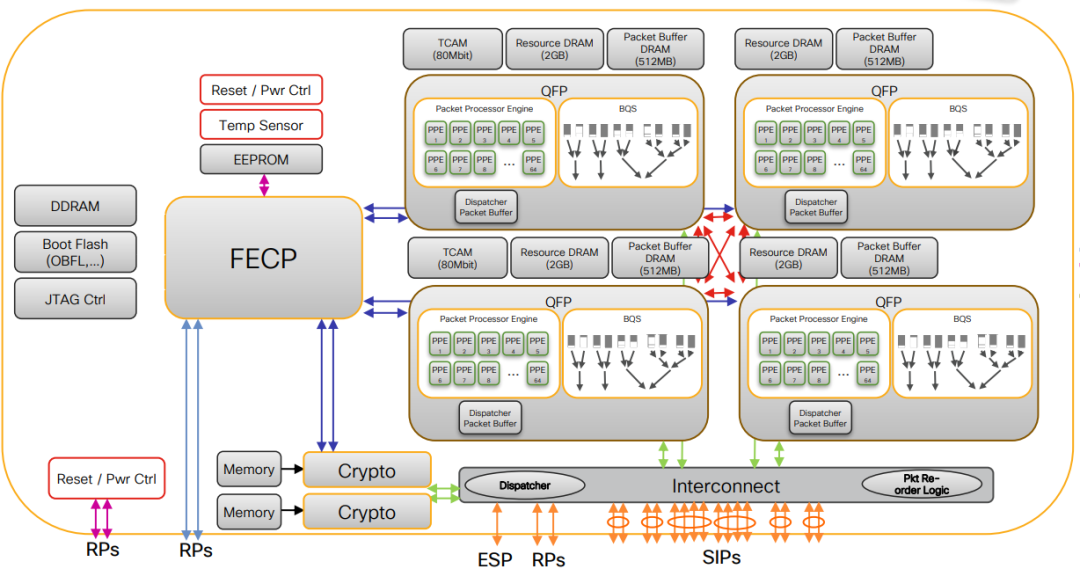
因此,把通用指令集引入网卡,在固化的pipeline和完全灵活的RTC之间寻求平衡,并且整合存内计算的能力,例如带有Samsung PIM-HBM的ASIC便成为DPU破局的关键。
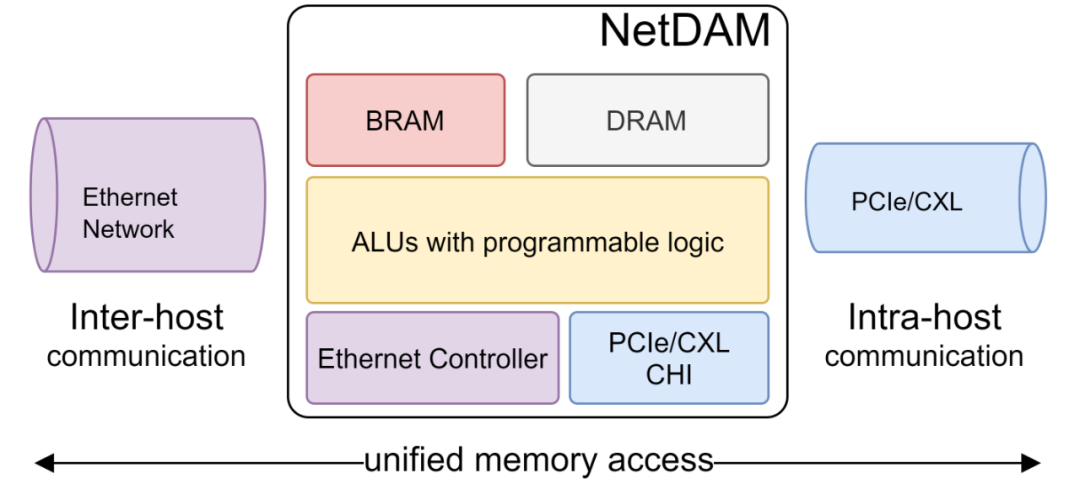
NetDAM深远的意义,如同当年的GTX8800+CUDA, 或许在它出生之年你并看不懂它,因为你还在RTC和Pipeline以及RDMA怎么处理的泥潭里纠缠。

但当你看完整个GPU、显存的发展历程,你就会明白我说的是对的了,唯一的选择只是要么一起当压路机,要不被后人慢慢碾压。
[1]Apple I working Demo: https://www.youtube.com/watch?v=4l8i_xOBTPg
[2]home computers by video hardware: https://en.wikipedia.org/wiki/List_of_home_computers_by_video_hardware[3]IBM Monochrome DIsplay Adapter: https://en.wikipedia.org/wiki/IBM_Monochrome_Display_Adapter







