绑定手机号
确认绑定









本文分享 CVPR2020 Oral 的一篇经典工作。论文为『Camouflaged Object Detection』,南开&武大Ð提出用于伪装目标检测SINet,代码已开源!
详细信息如下:

论文地址:https://openaccess.thecvf.com/content\_CVPR\_2020/papers/Fan\_Camouflaged\_Object\_Detection\_CVPR\_2020\_paper.pdf
代码地址:https://github.com/DengPingFan/SINet/
在本文中,作者提出了一项新任务伪装目标检测(COD)的综合研究,该任务旨在识别“无缝”嵌入其周围环境中的对象。目标和背景之间的高度内在相似性使得COD比传统的目标检测任务更具挑战性。
为了解决这个问题,作者精心收集了一个名为COD10K的新数据集,该数据集包含10000幅图像,涵盖了各种自然场景中的伪装对象,超过78个对象类别。所有图像都使用类别、边界框、对象/实例级别和matting级别标签进行密集标注。该数据集可以作为推进许多视觉任务的桥梁,例如定位、分割和alpha matting等。
此外,作者开发了一个简单但有效的COD框架,称为搜索识别网络(SINet)。SINet在所有测试数据集上的表现都优于各种最先进的目标检测baseline,因此它是一个健壮的通用框架,有助于促进COD的未来研究。最后,作者进行了大规模的COD研究,评估了13个前沿模型,提供了一些有趣的发现,并展示了一些潜在的应用。

上图中展示了一些目标与背景高度相容的图片,生物学家称这种背景匹配伪装( background matching camouflage),动物试图调整其身体的颜色以与周围环境“完美”匹配以避免被识别。

感官生态学家发现,这种伪装策略通过欺骗观察者的视觉感知系统而起作用。因此,解决伪装目标检测 (COD) 需要大量的视觉感知知识。如上图所示,目标对象和背景之间的高度内在相似性使得 COD 比传统的显着对象检测或通用对象检测更具挑战性。
除了科学价值外,COD 还有益于计算机视觉(用于搜救工作或稀有物种发现)、医学图像分割(例如息肉分割、肺部感染分割)、农业(例如,蝗虫检测以防止入侵)和艺术(例如,用于照片般逼真的混合或娱乐艺术)。
目前,由于缺乏足够大的数据集,伪装物体检测的研究并不完善。为了能够对这个主题进行全面研究,作者提供了两个贡献。首先,作者提出了专门为 COD 设计的新型 COD10K 数据集。
它与当前数据集的不同之处在于以下几个方面:
它包含 10K 图像,涵盖 78 个伪装对象类别,例如水生、飞行、两栖动物和陆地等。
所有伪装的图像都用类别、边界框、对象级和实例级标签进行分层标注,促进了许多视觉任务。
每个伪装的图像都被分配了在现实世界中发现的具有挑战性的属性和 matting级别标签。这些高质量的标注有助于更深入地了解算法的性能。
此外,作者提出了一个简单但有效的框架,名为 SINet(搜索和识别网络)。值得注意的是,SINet 的整体训练时间仅为 1 小时左右,并且在所有现有 COD 数据集上都达到了 SOTA 性能,这表明它可能是 COD 的潜在解决方案。

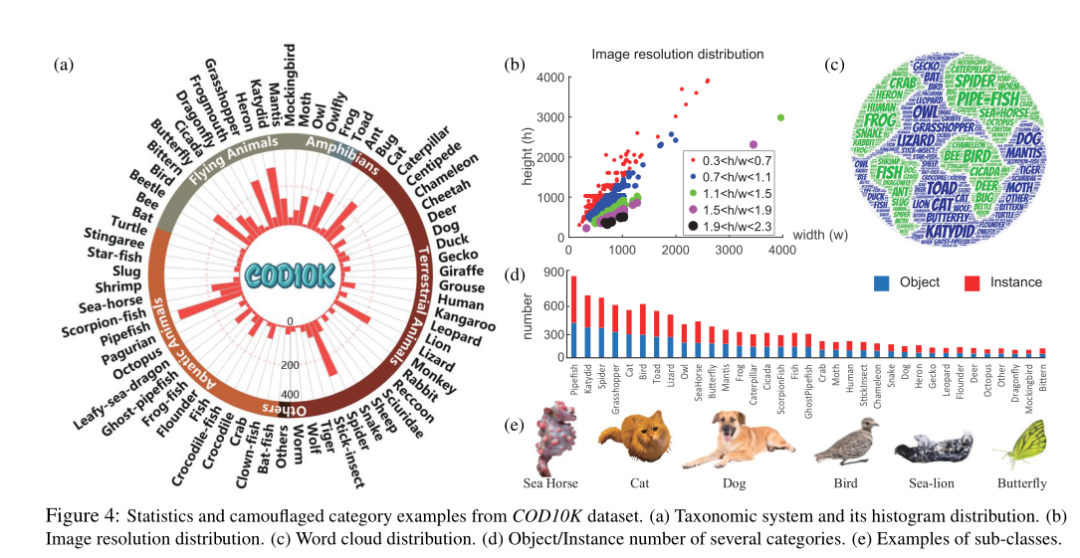
新任务和数据集的出现 导致了计算机视觉各个领域的快速发展。例如,ImageNet彻底改变了使用深度模型进行视觉识别。考虑到这一点,作者研究和开发 COD 数据集的目标是:(1) 提供新的具有挑战性的任务,(2) 促进新主题的研究,以及 (3) 激发新颖的想法。上图展示了本文提出的数据集(COD10K)的概况和样例。
3.1. Image Collection
标注的质量和数据集的大小是其作为基准的生命周期的决定因素。为此,COD10K包含10000张图像(5066张伪装,3000张背景,1934张非伪装),分为10个超类,78个子类(69个伪装,9个非伪装)。
大多数伪装图像来自 Flicker,并已通过以下关键字应用于学术用途:伪装的动物、不引人注意的动物、伪装的鱼、伪装的蝴蝶、隐藏的狼蛛、手杖、死叶螳螂、鸟、海马、猫、侏儒海马等,其余伪装图片(约 200 张图片)来自其他网站,包括 Visual Hunt、Pixabay、Unsplash、Free-images 等,这些网站发布公共领域的库存照片。为了避免选择偏差,作者还从 Flickr 收集了 3,000 张显着图像。为进一步丰富负样本,从互联网上选取了1934张非伪装图片,包括森林、雪地、草原、天空、海水等类别的背景场景。
最近发布的数据集表明,在创建大规模数据集时,建立分类系统至关重要。本文的标注(通过众包获得)是分层的(类别 → 边界框 → 属性 → 对象/实例)。
Categories
作者首先创建了五个超类类别。然后,根据收集的数据总结了 69 个最常出现的子类类别。最后,作者标记每个图像的子类和超类。如果候选图像不属于任何已建立的类别,将其归类为“其他”。
Bounding boxes
为了扩展伪装对象任务的 COD10K,作者还仔细标注了每个图像的边界框。
Attributes

作者用自然场景中面临的极具挑战性的属性来标记每个伪装的图像,例如遮挡、无法定义的边界。属性描述如上表所示,协属性分布如上图所示。
Objects/Instances
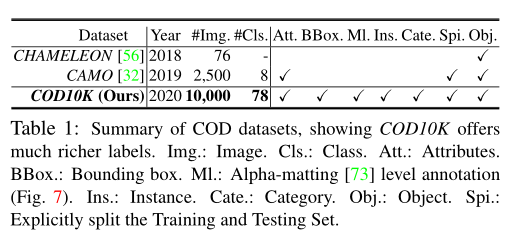
现有的 COD 数据集只关注对象级标签(如上表所示)。但是,能够将对象解析为其实例对于计算机视觉研究人员能够编辑和理解场景非常重要。为此,作者进一步在实例级标注对象,产生 5,069 个对象级掩码和 5,930 个实例级 GT。
3.3. Dataset Features and Statistics
Object size
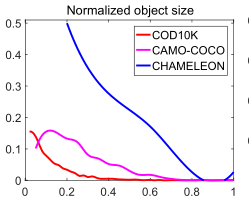
作者在上图中绘制了归一化的对象大小,即大小分布从 0.01% 到 80.74%(平均:8.94%),与 CAMO-COCO 和 CHAMELEON 相比,范围更广。
Global/Local contrast

为了评估一个对象是否易于检测,作者使用全局/局部对比策略来描述它。上图显示了 COD10K 中的对象比其他数据集中的对象更具挑战性。
Center bias

中心偏置通常发生在拍照时,因为人类自然倾向于专注于中心的物体。上图显示本文的数据集比其他数据集遭受更少的中心偏差。
Quality control

为了确保高质量的标注,作者邀请了三位人类参与标注过程,进行 10-fold交叉验证。上图显示了通过/拒绝的示例。这种实例级标注平均每张图像花费约 60 分钟。
Super/Sub-class distribution
COD10K 包括 5 个超类(陆地、空中生物、水生、两栖类、其他)和 69 个子类(例如,蝙蝠鱼、狮子、蝙蝠、青蛙等)。
Resolution distribution
高分辨率数据为模型训练提供更多对象边界细节,并在测试时产生更好的性能。COD10K 包括大量的全高清 1080p 图像。
Dataset splits
为了给深度学习模型提供大量的训练数据,COD10K被分割成6000张图像用于训练和4000张图像用于测试,从每个子类中随机抽取。
生物学研究表明,捕食者在捕猎时,会首先判断是否存在潜在猎物,即寻找猎物;然后,可以识别目标动物;最后,它可以被抓住。所提出的 SINet 框架的灵感来自于狩猎的前两个阶段。它包括两个主要模块:搜索模块(SM)和识别模块(IM)。前者负责搜索伪装的物体,而后者则用于精确检测它。
4.1. Search Module (SM)
神经科学实验已经证实,在人类视觉系统中,一组不同大小的群体感受野 (pRF) 有助于突出靠近视网膜中央凹的区域,该区域对小的空间变化很敏感。这促使作者在搜索阶段(通常在小/局部空间中)使用 RF组件来合并更具辨别力的特征表示。具体来说,对于输入图像,从 ResNet-50中提取了一组特征。为了保留更多信息,作者修改了 stride = 1 的参数,使其在第二层具有相同的分辨率。因此,每一层的分辨率为
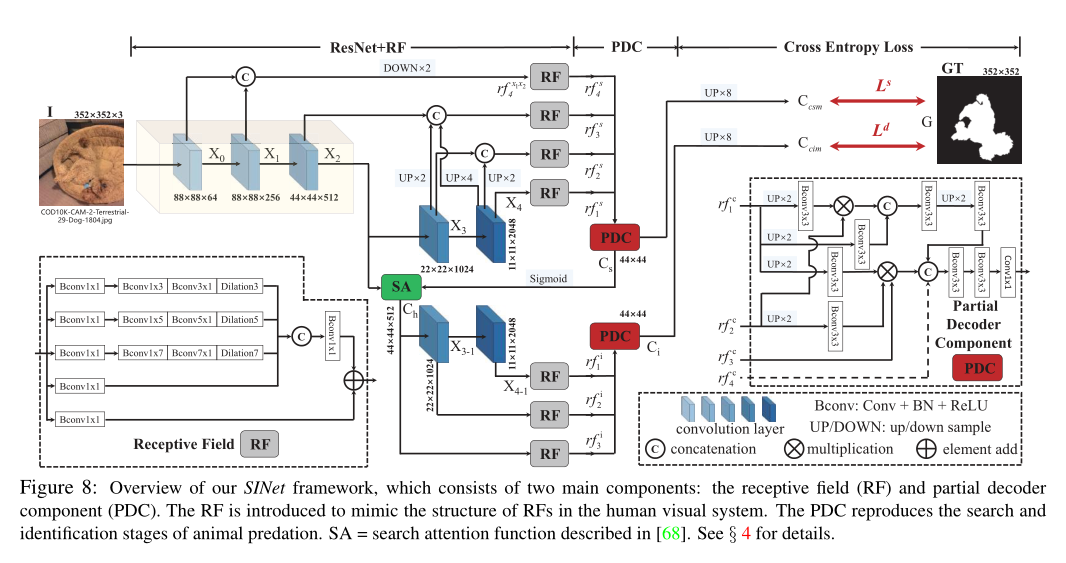
最近的工作表明,浅层中的低级特征保留了构建对象边界的空间细节,而深层中的高级特征保留了用于定位对象的语义信息。由于神经网络的这种固有特性,作者将提取的特征分为低级,中级,高级,并通过连接,上采样和下采样操作将它们组合起来。本文的 SINet 利用密集连接策略来保留来自不同层的更多信息,然后使用修改后的 RF组件来扩大感受野。
例如,作者使用concat操作融合低级特征,然后将分辨率降低一半。然后将这一新特征进一步馈入 RF 组件以生成输出特征。如上图所示,在结合了三个层次的特征之后,有一组增强的特征用于学习鲁棒的线索。
Receptive Field (RF)
RF分支包括五个分支。在每个分支中,第一个卷积 (Bconv) 层的尺寸为 1 × 1,以将通道大小减小到 32。接下来是另外两个层:一个Bconv 层和一个具有特定膨胀率 (2k − 1) 的 Bconv 层,其中 k > 2 。前四个分支concat起来,然后通过 1 × 1 Bconv 操作将它们的通道大小减小到 32。最后,添加第 5 个分支并将整个模块馈送到 ReLU 函数以获得特征。
4.2. Identification Module (IM)
从前面的搜索模块中获得候选特征后,在识别模块中,需要对伪装对象进行精确检测。作者扩展了具有密集连接特征的部分解码器组件(PDC)。更具体地说,PDC 集成了 SM 的四个级别的特征。因此,粗略伪装图可以通过下式计算:
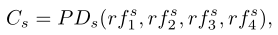
其中

其中是 SA 函数,它实际上是一个标准差为 σ = 32 和核大小 λ = 4 的典型高斯滤波器,然后进行归一化操作。是一个最大值函数,它突出了的初始伪装区域。
为了整体获得高级特征,作者进一步利用 PDC 聚合另外三层特征,通过 RF 特征增强,并获得最终的伪装图:

其中。 和 的区别在于输入特征的数量。
Partial Decoder Component (PDC)
形式上,给定特征
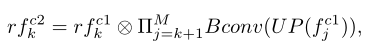
其中,Bconv(·) 是一个顺序操作,它结合了一个 3 × 3 卷积,然后是BatchNorm,以及一个 ReLU 函数。是具有比率的上采样操作。最后,作者通过concat操作将这些判别特征结合起来。训练 SINet 的损失函数是交叉熵损失。总损失函数 L 为:
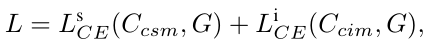
其中和是和上采样到 352×352 分辨率后得到的两个伪装对象图。

在CHAMELEON上,与 12 个 SOTA 目标检测baseline相比,本文的 SINet 在所有指标上都取得了最佳性能。作者还在最近提出的 CAMO数据集上测试了本文的模型,该数据集包括各种伪装对象。CAMO数据集比以前的数据集更具挑战性。SINet再次 获得了最佳性能,进一步证明了它的鲁棒性。使用 COD10K 数据集的测试集(2,026 张图像),再次观察到所提出的 SINet 始终优于其他模型。

上表展示了跨数据集的实验结果。每行列出一个模型,该模型在一个数据集上训练并在所有其他数据集上进行测试,表明用于训练的数据集的普遍性。每列显示一个模型在特定数据集上测试并在所有其他数据集上训练的性能,表明测试数据集的难度。可以发现本文的 COD10K 是最困难的(例如,最后一行 Mean others:0.589)。这是因为本文的数据集包含各种具有挑战性的伪装对象。

上图展示了本文的 SINet 和两个baseline之间的定性比较。可以看出,PFANet能够定位伪装的物体,但输出总是不准确的。通过进一步使用边缘特征,EGNet实现了比 PFANet 相对更准确的位置。尽管如此,它仍然遗漏了物体的细节,尤其是第一排的鱼。对于所有这些具有挑战性的情况(例如,无法定义的边界、遮挡和小物体),SINet 能够推断出真实的伪装物体。
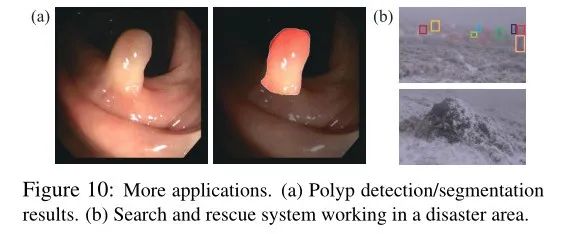
上图展示了伪装探测系统在自动分割息肉和在灾区工作的搜救系统中的应用。

上图显示了来自 Google 的搜索结果示例。从结果(上图a)中,可以注意到搜索引擎无法检测到隐藏的蝴蝶,因此只能提供具有相似背景的图像。有趣的是,当搜索引擎配备了伪装探测系统(这里,只是简单地改变了关键字),引擎可以识别伪装的物体,然后返回几个蝴蝶图像(上图b)。
在本文中,作者从伪装的角度提出了第一个完整的目标检测基准。具体来说,作者提供了一个新的具有挑战性和密集标注的 COD10K 数据集,进行了大规模评估,开发了一个简单但高效的端到端 SINet 框架,并提供了几个潜在的应用程序。与现有的前沿baseline相比,SINet 具有竞争力,并产生了视觉上更有利的结果。
[1]https://openaccess.thecvf.com/content_CVPR_2020/papers/Fan_Camouflaged_Object_Detection_CVPR_2020_paper.pdf[2]https://github.com/DengPingFan/SINet/








