绑定手机号
确认绑定









语言、视觉和多模态预训练的大融合正在出现。在这项工作中,作者引入了一个通用的多模态基础模型 BEIT-3,它在视觉和视觉语言任务上都实现了最先进的迁移性能。具体来说,作者从三个方面推进大融合:骨干架构、预训练任务和模型扩展。作者为通用建模引入了 Multiway Transformers,其中模块化架构支持深度融合和特定于模态的编码。基于共享主干,作者以统一的方式对图像(Imglish)、文本(English)和图像-文本对(“parallel sentences”)进行掩码“语言”建模。实验结果表明,BEIT-3 在对象检测 (COCO)、语义分割 (ADE20K)、图像分类 (ImageNet)、视觉推理 (NLVR2)、视觉问答 (VQAv2)、图像字幕方面获得了最先进的性能(COCO)和跨模态检索(Flickr30K,COCO)。

Image as a Foreign Language: BEIT Pretraining for All Vision and Vision-Language Tasks
论文地址:https://arxiv.org/abs/2208.10442[1]
代码地址:https://aka.ms/beit-3[2]
近年来,语言、视觉和多模态预训练大融合的趋势。通过对海量数据进行大规模预训练,可以轻松地将模型迁移到各种下游任务。可以预训练一个处理多种模态的通用基础模型,这很有吸引力。在这项工作中,作者从以下三个方面推进视觉语言预训练的收敛趋势。
首先,Transformers的成功是从语言翻译运用到视觉和多模态的问题。网络架构的统一使我们能够无缝地处理多种模态。对于视觉语言建模,由于下游任务的不同性质,有多种方法可以应用 Transformer。例如,双编码器架构用于高效检索,编码器-解码器网络用于生成任务,融合编码器架构用于图像-文本编码。然而,大多数基础模型必须根据特定架构手动转换最终任务格式。此外,参数通常不能有效地跨模态共享。在这项工作中,作者采用** Multiway Transformers **进行通用建模,即为各种下游任务共享一个统一架构。模块化网络还综合考虑了特定于模态的编码和跨模态融合。
其次,基于掩码数据建模的预训练任务已成功应用于各种模态,例如文本 、图像和图像-文本对。当前的视觉语言基础模型通常会同时处理其他预训练目标(例如图像-文本匹配),从而导致放大不友好且效率低下。相比之下,本文只使用一个预训练任务,即 mask-then-predict,来训练一个通用的多模态基础模型。通过将图像视为一门外语(即 Imglish),作者以相同的方式处理文本和图像,而没有基本的建模差异。因此,图像-文本对被用作“平行句子”,以学习模态之间的对齐。作者还表明,这种简单而有效的方法学习了强大的可迁移表示,在视觉和视觉语言任务上都实现了最先进的性能。显着的成功证明了生成式预训练的优越性。
第三,扩大模型规模和数据规模普遍提高了基础模型的泛化质量,以便可以将它们转移到各种下游任务中。作者遵循这一理念并将模型规模扩大到数十亿个参数。此外,作者在实验中扩大了预训练数据的大小,同时仅将可公开访问的资源用于学术。尽管没有使用任何私人数据,但本文的方法在相当大的程度上优于依赖内部数据的最先进的基础模型。此外,扩大规模得益于将图像视为外语,因为作者可以直接重用为大规模语言模型预训练开发的管道。
在这项工作中,作者利用上述想法来预训练一个通用的多模态基础模型** BEIT-3**。通过对图像、文本和图像-文本对执行掩码数据建模来预训练 Multiway Transformer。在预训练期间,作者随机屏蔽一定比例的文本标记或图像块。自监督学习的目标是在给定损坏的输入的情况下恢复原始标记(即文本标记或视觉标记)。该模型是通用的,因为无论输入模态或输出格式如何,它都可以重新用于各种任务。
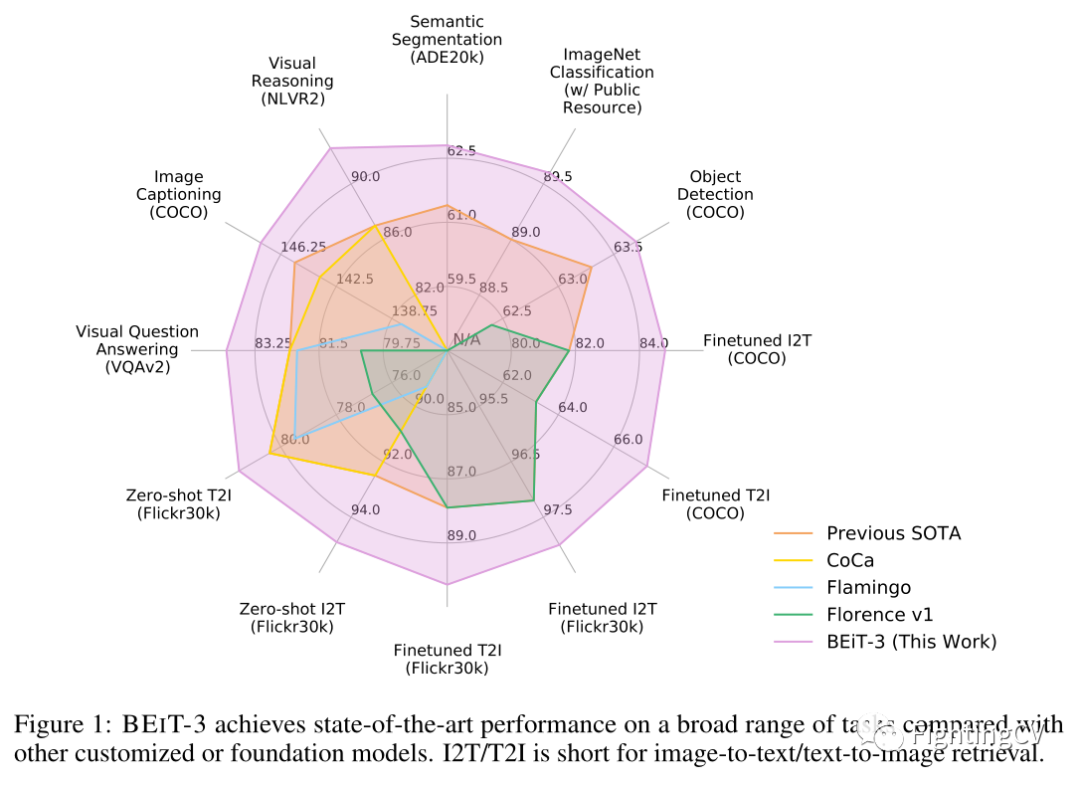
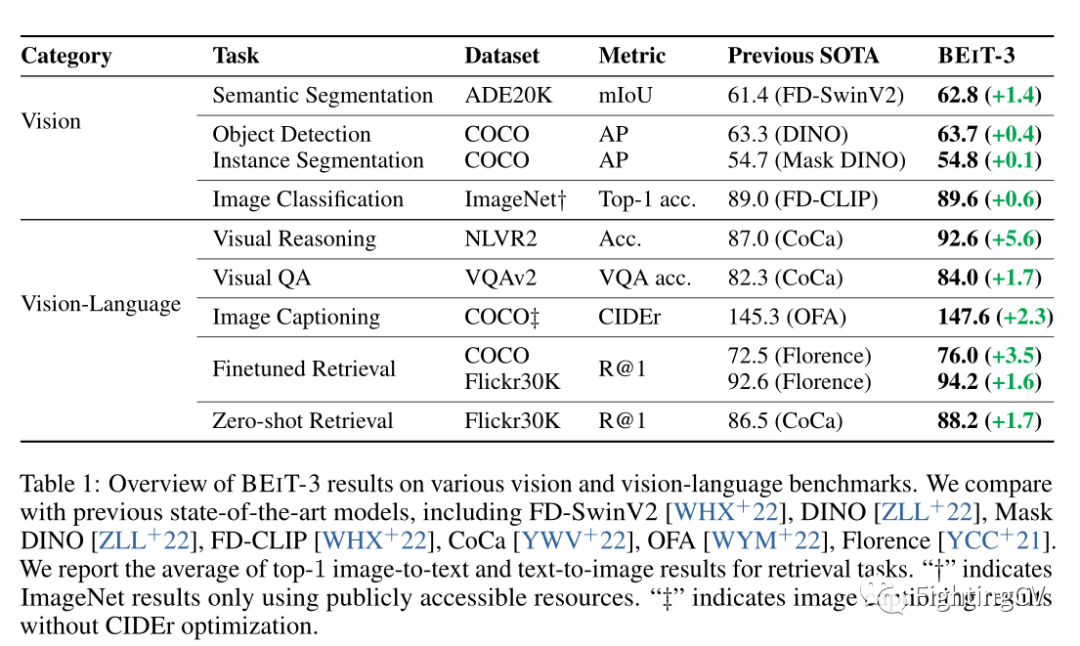
如上图和上表所示,BEIT-3 在广泛的视觉和视觉语言任务中实现了最先进的迁移性能。作者在广泛的下游任务和数据集上评估 BEIT-3,即对象检测 (COCO)、实例分割 (COCO)、语义分割 (ADE20K)、图像分类 (ImageNet)、视觉推理 (NLVR2)、视觉问答 (VQAv2) ,图像字幕(COCO)和跨模态检索(Flickr30K,COCO)。具体来说,尽管作者只使用公共资源进行预训练和微调,但本文的模型优于以前的强大基础模型。该模型也比专门的模型获得了更好的结果。此外,BEIT-3 不仅在视觉语言任务上表现出色,而且在视觉任务(如对象检测和语义分割)上也表现出色。

如上图所示,BEIT-3 使用共享的 Multiway Transformer 网络通过对单模态和多模态数据的掩码数据建模进行预训练。该模型可以转移到各种视觉和视觉语言下游任务。
3.1 Backbone Network: Multiway Transformers
作者使用 Multiway Transformers 作为主干模型来编码不同的模态。如上图所示,每个 Multiway Transformer 模块都由一个共享的自注意模块和一个用于不同模态的前馈网络(即模态专家)池组成。根据其形式将每个输入token路由给专家。在本文的实现中,每一层都包含一个视觉专家和一个语言专家。此外,前三层有专为融合编码器设计的视觉语言专家。使用模态专家池鼓励模型捕获更多特定于模态的信息。共享的自注意模块学习不同模态之间的对齐,并为多模态(例如视觉语言)任务实现深度融合。
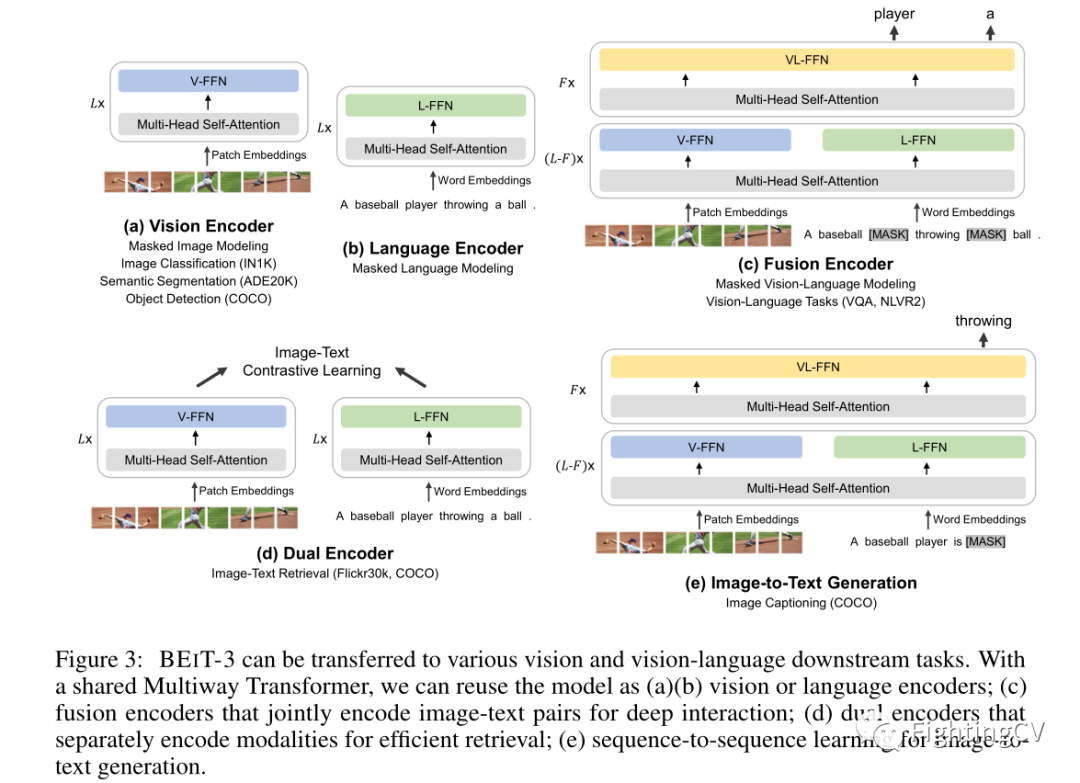
如上图所示,统一的架构使 BEIT-3 能够支持广泛的下游任务。例如,BEIT-3 可以用作各种视觉任务的图像主干,包括图像分类、对象检测、实例分割和语义分割。它还可以微调为双编码器,用于高效的图像-文本检索,以及用于多模态理解和生成任务的融合模型。
3.2 Pretraining Task: Masked Data Modeling
通过统一的掩码数据建模目标对单模态(即图像和文本)和多模态数据(即图像-文本对)进行预训练 BEIT-3。在预训练期间,作者随机屏蔽一定百分比的文本标记或图像块,并训练模型以恢复被屏蔽的标记。统一的掩码然后预测任务不仅学习表示,还学习不同模态的对齐。具体来说,文本数据由 SentencePiece 标记器 进行标记。图像数据通过 BEIT v2 的分词器进行分词,得到离散的视觉分词作为重建目标。作者从图像-文本对中随机屏蔽 15% 的单模态文本标记和 50% 的图文对中的文本标记。对于图像,作者使用 BEIT 中的分块屏蔽策略屏蔽 40% 的图像块。
作者只使用一个预训练任务,这使得训练过程的扩展友好。相比之下,以前的视觉语言模型通常采用多个预训练任务,例如图文对比、图文匹配和单词-patch/区域对齐。作者展示了一个小得多的预训练batch大小可以用于 mask-then-predict 任务。相比之下,基于对比的模型通常需要非常大的batch size进行预训练,这带来了更多的工程挑战,例如GPU内存成本。
3.3 Scaling Up: BEIT-3 Pretraining
Backbone Network
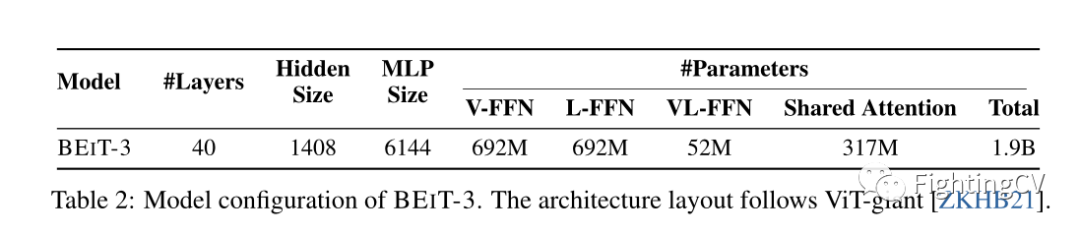
BEIT-3 是继 ViTgiant搭建之后的巨型基础模型。如上表所示,该模型由一个 40 层的 Multiway Transformer 组成,具有 1408 的隐藏大小、6144 的中间大小和 16 个注意力头。所有层都包含视觉专家和语言专家。视觉语言专家也采用于前三个 Multiway Transformer 层。自注意力模块在不同的模态中共享。BEIT-3总共由1.9B个参数组成,其中视觉专家参数692M,语言专家参数692M,视觉语言专家参数52M,共享自注意力模块参数317M。请注意,当模型用作视觉编码器时,仅激活与视觉相关的参数(即,与 ViT-giant 相当的大小;大约 1B)。
Pretraining Data

BEIT-3 在上表中显示的单模态和多模态数据上进行了预训练。对于多模态数据,从五个公共数据集中收集了大约 1500 万张图像和 2100 万张图文对:Conceptual 12M (CC12M)、Conceptual Captions (CC3M) 、SBU Captions (SBU) 、COCO 和视觉基因组 (VG) 。对于单模态数据,使用来自 ImageNet-21K 的 14M 图像和来自英语 Wikipedia、BookCorpus 、OpenWebText3、CC-News 和 Stories 的 160GB 文本语料库。
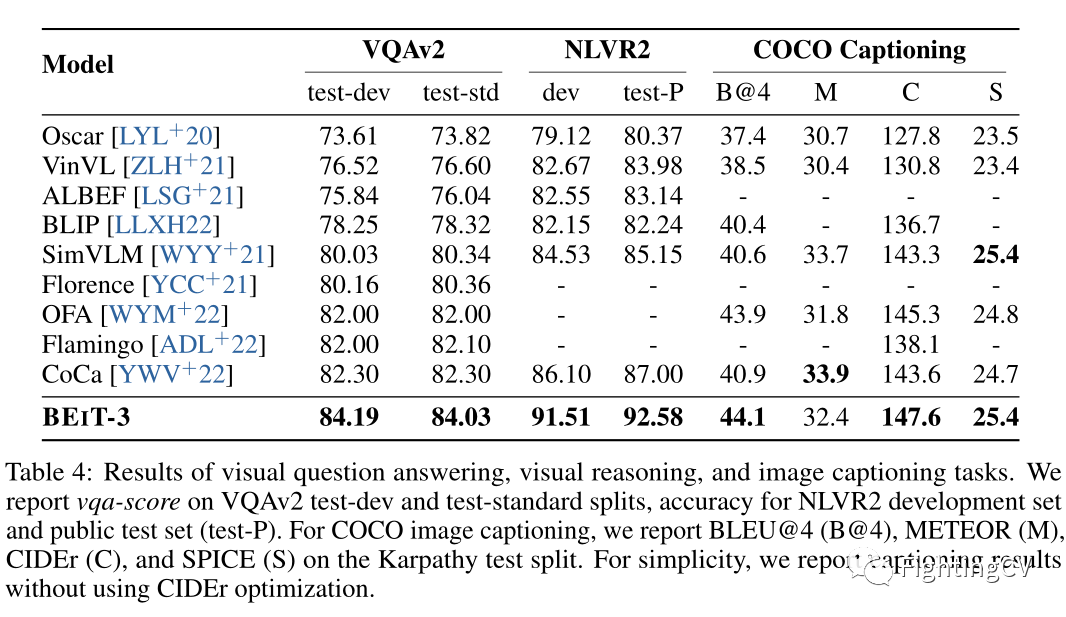
上表展示了本文方法在三个多模态数据集上的实验结果。
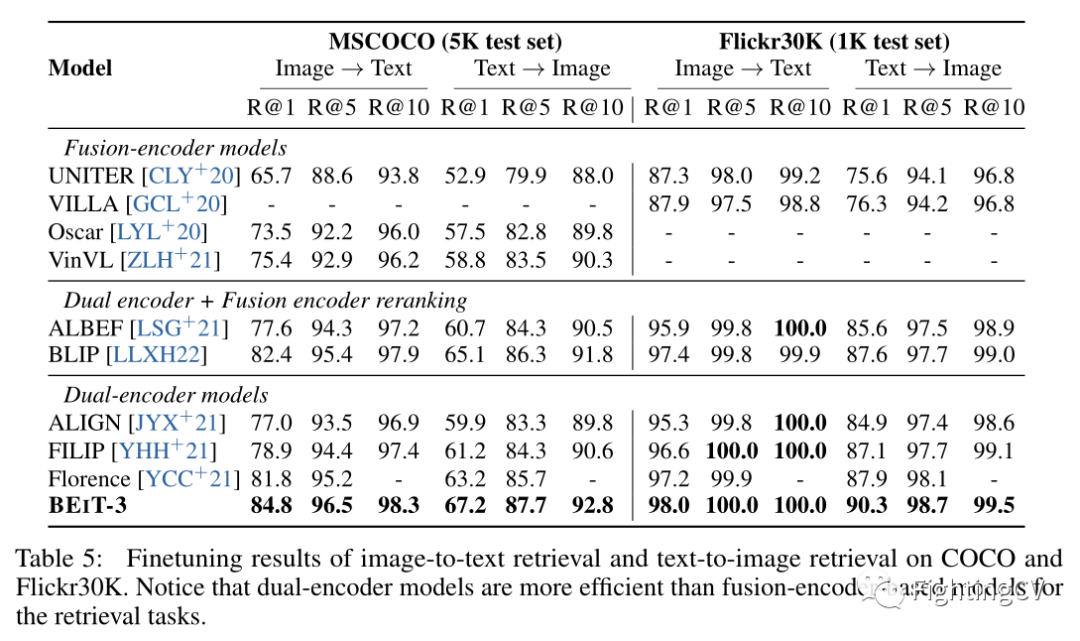
多模态检索数据集上的结果。
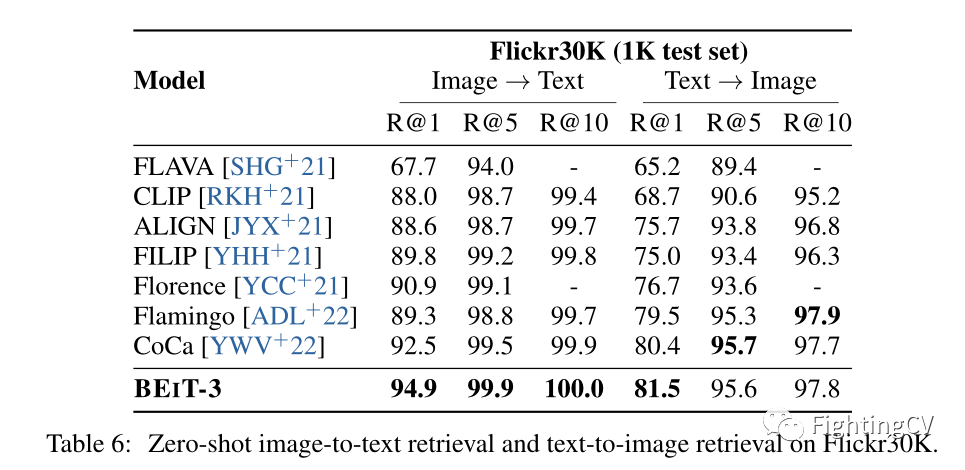
多模态检索数据集上的Zero-shot结果。
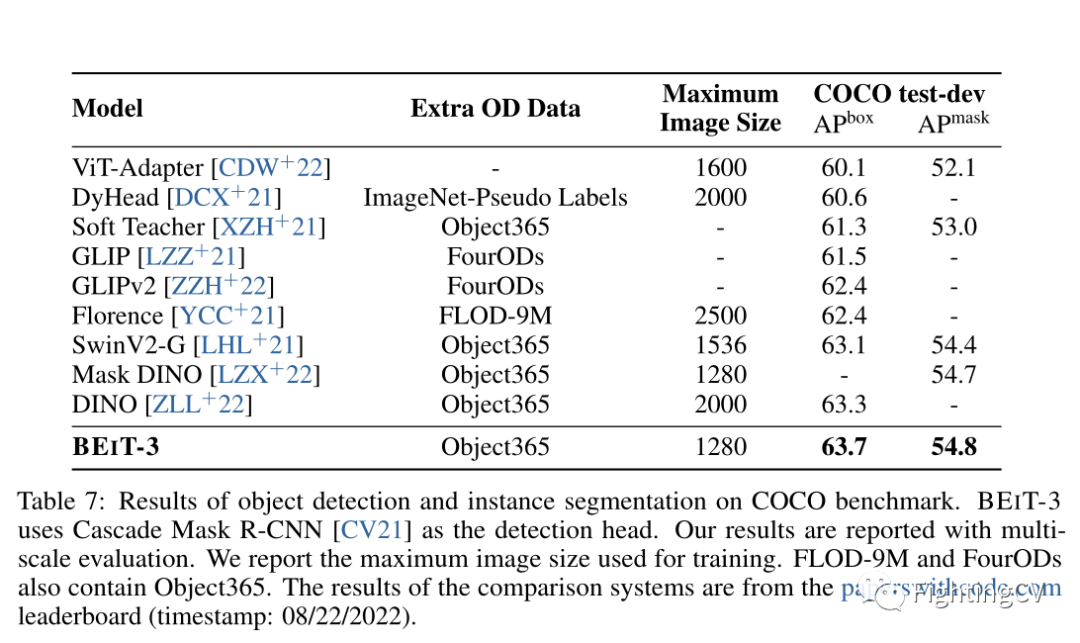
目标检测和实例分割的实验结果。
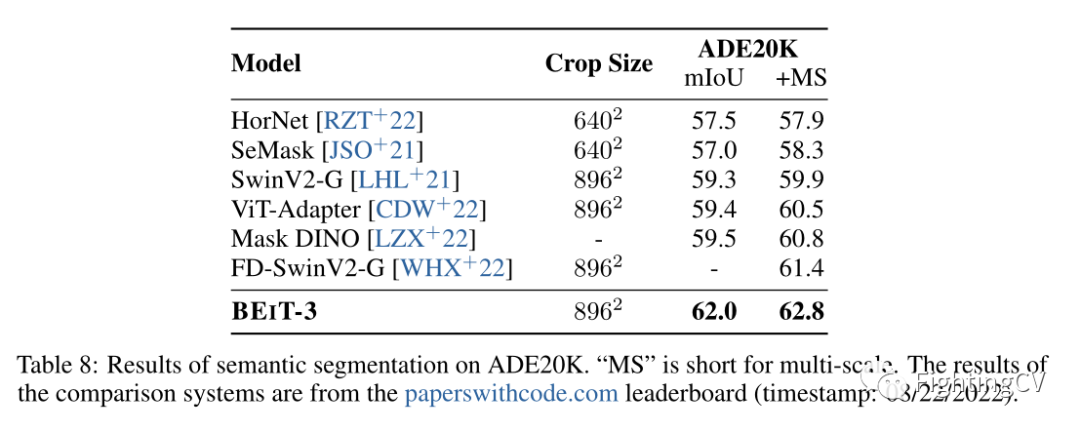
语义分割的实验结果。
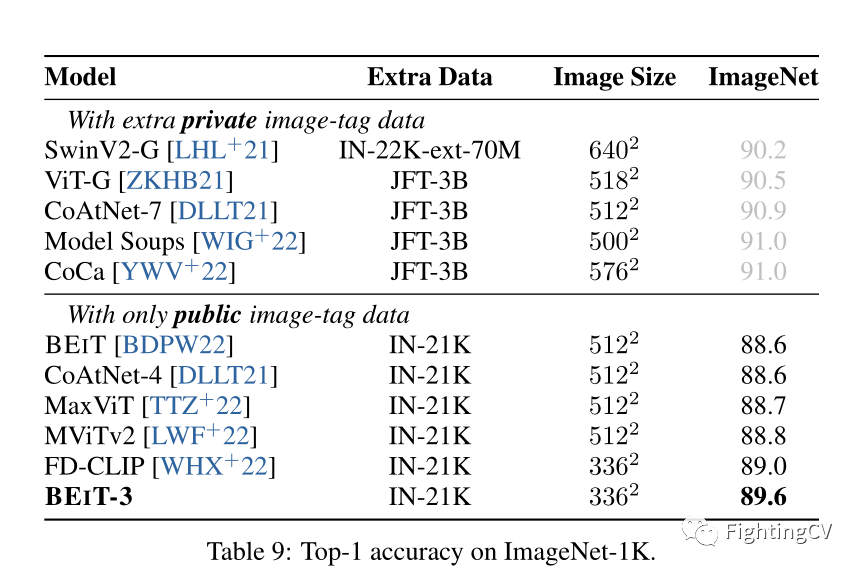
图像分类的实验结果。
在本文中,作者提出了 BEIT-3,这是一种通用的多模态基础模型,它在广泛的视觉和视觉语言基准测试中实现了最先进的性能。BEIT-3 的核心思想是图像可以建模为一门外语,这样就可以统一对图像、文本和图文对进行蒙版“语言”建模。作者还展示了 Multiway Transformers 可以有效地对不同的视觉和视觉语言任务进行建模,使其成为通用建模的有趣选择。BEIT-3简单有效,是扩大多模态基础模型的一个有前途的方向。对于未来的工作,作者正在努力对多语言 BEIT-3 进行预训练,并在 BEIT-3 中加入更多的模态(例如音频),以促进跨语言和跨模态的迁移,并推动大规模预训练跨任务的大融合、语言和方式。








