绑定手机号
确认绑定









缓存一致性——一种提高芯片性能的常用技术,现在正变得越来越没用。因为通用处理器经常会附加一些高度专业化的加速器和其他处理器,有时甚至被其取代。
虽然缓存一致性不会很快消失,但它越来越被视为一种奢侈品。因此在必要条件下,架构会开始限制它的使用。
缓存有效地将内存移到更靠近处理器的地方,减少了处理数据的等待时间,并提高了整体性能。连续内存空间是冯诺伊曼处理器架构的基本元素,相对便宜且易于实现,即使添加多个处理器时也是如此。但是还有其他方法可以提高处理速度,使用通用处理器和缓存来处理所有事情既不是最快的,也不是最有效的。
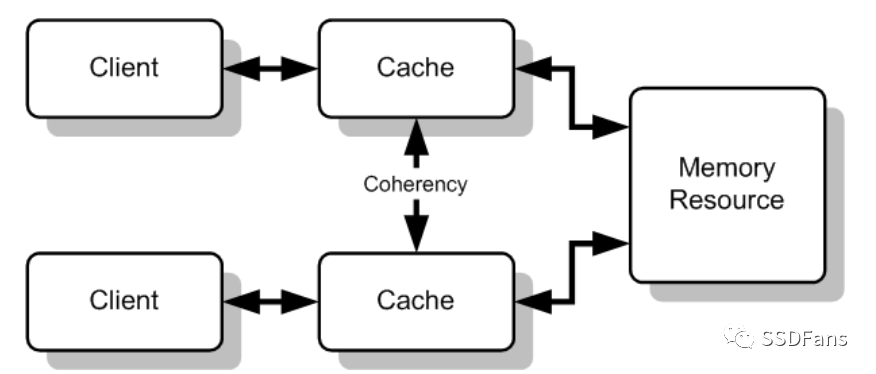
由于内存空间的某些部分可能有多个副本,缓存管理起来也很复杂。如果一个变量正在使用中,并且可以由多个处理器操作,那么硬件必须确保所有这些处理器看到的值都是相同的。
单芯片下可以用封装解决,基本能够满足需求。但当多个芯片需要一致性时,事情就变得更加困难了。最近出现了一些标准,如CCIX和CXL,它们确保了来自多个系统之间的兼容性。
Arteris IP的系统架构师MichaelFrank表示:“一致性是一种契约,它可以保证处理器获得的数据是最新的。当有很多处理器共享相同的数据集时,这是最重要的。平等同伴之间的一致性非常重要,而且不会消失。”
但随着越来越多的处理器被添加到设计中,这种解决方案的成本也在不断增加。BrekerVerification Systems CTO Adnan Hamid 表示:“异构的、数据流驱动的计算意味着在更多的数据上进行更多的计算。我们不仅要在更多的网络间共享这些数据,同时还要考虑数据安全和功耗。受限于冯诺依曼架构的存储瓶颈,高性能系统非但不会丢掉缓存,还必须在芯片、系统和数据中心内部或跨芯片、系统和数据中心实现多级分布式缓存。”
许多新的编程范式没有这个问题。内存提供给需要执行任务的处理器,完成后该内存的内容将开放给任何其它想要对其进行操作的处理元素。这样的处理方式简单、干净、快速、高效。
改变需要时间。Xilinx战略架构副总裁Millind Mittal表示:“处理的本质仍然是多个处理线程协作完成某些任务。即使对于异构架构,与CPU上的同构通用处理(GP)线程相比,工作协作是在包括GP线程和任务优化处理(TP)线程的多线程之间进行的。”
当任务被很好地理解时,缓存一致性是可以避免的。Frank说:“在一个数据流引擎中,一致性就不那么重要了,因为我们是把边缘数据直接从一个加速器传输到另一个加速器。如果划分数据集,一致性会变得很碍事,因为它需要花费额外的周期来查找并提供更新信息。”
缓存一致性简化了设计过程。Mittal表示:“协作线程之间总是需要共享数据结构。缓存一致性在两个方面有优势:易于实现共享数据结构的内存一致性(不需要软件驱动一致性操作);当多个线程频繁访问一个数据结构时可以提高性能。但基于硬件的一致性解决方案可能存在扩展性和复杂性问题。”
对于特定的工作流,有些方案可能会变得更加复杂。Frank解释道:“我们需要缓存是因为需要成倍的带宽吗?如果必须向多个引擎提供相同的数据,但不能从一个缓存中提供,我们就需要将数据从主存复制到多个缓存副本中。现在必须考虑如何保证这些副本彼此保持一致,因为必须确保共享数据的多个CPU或加速器之间的一致性。有时候它们就像彼此的复制品一样简单,如果数据是一次性使用的,就不需要纠结于一致性。为了确保数据的一致性而付出的努力可能会过于昂贵。”
当最初添加一致性时,每个节点的成本是相对线性的。Frank补充道:“随着节点数量的增加,必须确保每个节点都可以询问并确保和其他处理器的数据是一致的。这意味着需要在每个节点之间建立通信,同时要确保协议中不会出现故障,如竞态。我们在检查某个位置的数据和获得响应之间,有可能系统的状态已经发生了变化,这样会得到过时的信息。节点越多,竞争出现的机会就越多,针对这种情况必须创建一个安全的协议。为了避免一次去询问每个节点(这种做法浪费功耗和时延),可以在某个中心点建一个目录,记录系统中是否有多个缓存线的副本、缓存线是否在节点之间共享、某缓存线是否唯一等。成本绝对是线性增长的。”
必须充分考虑全部成本。Imperas软件公司的创始人Simon Davidmann表示:“在硅上实现一致性是非常复杂和昂贵的。当使用多级缓存时,内存层次结构就会变得越来越复杂,漏洞也越来越多,功耗也会越来越大。”
Hamid表示:“只关心缓存一致性的日子已经一去不复返了,现在我们必须验证系统的一致性。关键的脏数据不仅在很远的缓存中,而且很可能在网络的某个地方传输。所有这些数据必须通过跨网络安全防火墙保持一致,数据途径的各个子系统都要进行时钟和电压控制,以完成电源管理。”
性能
添加缓存的主要原因是为了提高性能。Frank说:“这要归功于Dave Patterson,他将著名的分析方法引入了性能分析,这种方法是艺术和科学的混合体。我们需要理解要做的是什么,然后分析算法的数据流和执行序列。当确定了流模式后,就可以开始构建模型了。利用经验和粗略计算提出一个体系结构,然后针对它运行模型验证我们的假设。”
这其中涉及多少艺术?Davidmann表示:“我们可以做一些性能计算,但永远无法对缓存子系统的细节进行建模。我们可以从功能的角度出发,但不能从性能的角度出发,而且只能提供近似值。例如,对于指令模型,我们不需要对指令流水线进行建模,因此我们不知道内存访问的顺序,原因包括预取、分支预测和投机执行等,每个都可能改变缓存中的数据。”
为了得到更准确的结果,必须做更多的工作。Frank补充道:“我们可以做出明确的决定,包括把数据放在哪里、如何在内存中组织数据、在哪里处理数据、如何处理数据等。从中可以看到,有些数据是共享的但很少更新,有些数据从一个引擎传递到另一个引擎。有时芯片上有足够的内存,所以可以将数据保存在芯片上,或者如果必须将数据送到芯片外,必须弄清楚是否有足够的带宽。”
一致性的未来
未来一致性是怎样的?Mittal表示:“我们认为缓存一致性仍然是可取的。但是硬件一致性仍将局限于双socket、加速器或小范围的内存扩展解决方案。另外,硬件一致性将被限制在数据结构的一个子集。数据共享将通过部分数据的硬件一致性来实现,其他数据则通过软件一致性来实现。”
软件一致性正受到越来越多的关注。Davidmann表示:“软件可以控制一致性,我们可以使用指令来刷新缓存,而不是用硬件。已经有解决方案做到了这一点,并得到了很好的推广。当观察现代处理器架构时,我们会发现它们具有软件控制的能力。RISC -V有关于原子性的指令,可以锁定区域。也许未来仍然需要某种程度的一致性,但趋势肯定是让软件做更多工作。”
这需要一种不同的思维方式。Frank问道:“未来我们将如何为加速器编程?我们生产的是像第一代GPU那样连在一起的硬连线引擎吗?或者是否会构建具有自己指令集的可编程引擎?如果必须分别对这些程序进行编程,那么可以用一个数据流将这些引擎连接起来,每个引擎都执行特定的任务。编译器会根据数据流描述划分和调度算法。我们必须进行完整的系统分析,以了解数据流及需求,何时数据必须对哪个引擎可见,以及这些数据和可见性有多少是可预测的。”
这使得一致性在某些应用程序中用处不大。Mittal 表示:“如今,主机间的数据共享是通过远程DMA或消息传递来复制数据实现的。未来,无论是否有硬件一致性,跨主机的数据共享很可能使用load/store来访问主机间数据。当存在硬件一致性时,硬件一致性可能会限制共享数据结构的大小。另一个可能发生的进化是加速器中处理线程的上下文管理(任务优化处理),类似于CPU上GP线程的上下文管理。”
随着任务变得越来越容易理解,同时体系结构也为此进行了微调,数据流变得更加可预测,一致性也变得更有针对性。现代机器学习体系结构表明,它对向量矩阵乘法等任务的附加价值很小。
但系统的某些部分仍将不可预测。Frank表示:“首先是考虑如何让数据进入或离开芯片,这意味着要考虑总的内存带宽、接口、支持的内存大小等。从这里开始,我们可以接近编程引擎,考虑是否需要缓存,因为系统中可能有大量的重用数据。”
结论
为了提高处理速度要让内存更接近处理器,而这就需要缓存。多处理器系统要求靠近每个处理器的缓存之间具有一致性,但这种解决方案过于昂贵,不到万不得已不能使用这种方案。幸运的是,随着许多任务变得更加面向数据,而不是面向控制,系统中的数据流可以被更好地理解和处理。在某些情况下,软件可以比硬件更有效地管理缓存一致性;另一些情况下,体系结构可以确保不需要一致性。
原文链接:
https://semiengineering.com/the-high-but-often-unnecessary-cost-of-coherence








