绑定手机号
确认绑定









本文围绕网络部署时面临的内存和资源问题,分享了如何从可视化和大量实验结果中得到Ghost特征的思想。作者设计出相比C-Ghost更适用于GPU等设备的G-Ghost,在实际延迟与性能
本文针对网络部署时面临的内存和资源有限的问题,提出两种不同的Ghost模块,旨在利用成本低廉的线性运算来生成Ghost特征图。C-Ghost模块被应用于CPU等设备,并通过简单的模块堆叠实现C-GhostNet。适用于GPU等设备的G-Ghost模块利用阶段性特征冗余构建。最终实验结果表明两种模块分别实现了对应设备上精度和延迟的最佳权衡。

论文地址:https://arxiv.org/abs/2201.03297
代码地址:https://github.com/huawei-noah/CV-Backbones
在GhostNet(CVPR 2020)出现之前,笔者对冗余特征一直保持刻板的偏见。但不管是过分的抑制冗余,还是过分的增加冗余,都会对架构性能造成不好的影响(存在即合理)。在GhostNet中,作者的等人通过细致的实验观察,提出“以有效方式接受冗余特征图”的思想,将以往的特征生成过程用更廉价的线性运算来替代,从而在保证性能的同时实现轻量化。
如下图所示,对中间特征图进行可视化之后,可以明显看出一些特征表达近似(图中用相同颜色标出的方框),因此作者等人提出,近似的特征图可以通过一些廉价的操作来获得。
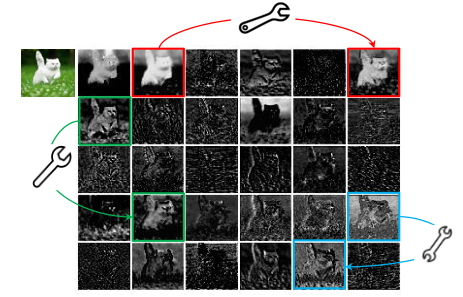
图1:ResNet50中第一个残差组产生的一些特征图的可视化。
据此,作者等人提出GhostNet,并在本文中称作C-GhostNet,因此笔者将解读的重点放在G-Ghost,对C-Ghost仅做回顾。
C-GhostNet中为实现轻量化,使用了一些低运算密度的操作。低运算密度使得GPU的并行计算能力无法被充分利用,从而导致C-GhostNet在GPU等设备上糟糕的延迟,因此需要设计一种适用于GPU设备的Ghost模块。
作者等人发现,现有大多数CNN架构中,一个阶段通常包括几个卷积层/块,同时在每个阶段中的不同层/块,特征图的尺寸大小相同,因此一种猜想是:特征的相似性和冗余性不仅存在于一个层内,也存在于该阶段的多个层之间。下图的可视化结果验证了这种想法(如右边第三行第二列和第七行第三列的特征图存在一定相似性)。
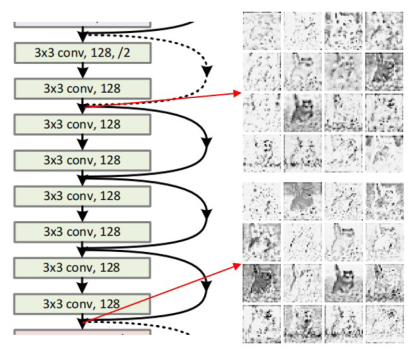
图2:左边为ResNet34第二阶段的所有卷积块,右边为该阶段的第一块和最后一块的特征图。
作者等人利用观察到的阶段性特征冗余,设计G-Ghost模块并应用于GPU等设备,实现了一个在GPU上具有SOTA性能的轻量级CNN。
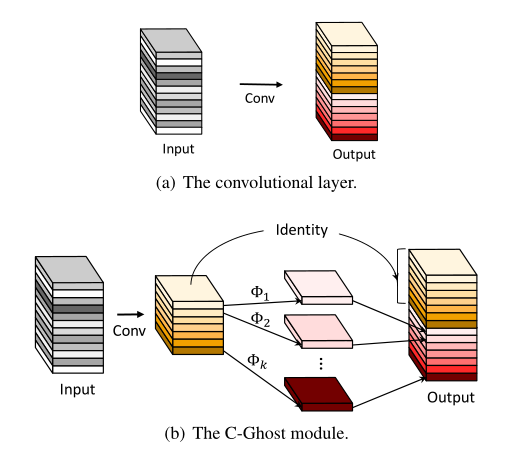
图3:卷积层和C-Ghost模块的示意图。
如图3,给定输入,一个普通的卷积过程可以表示为:
其中,,表示由尺寸为的特征图生成尺寸为的特征图。由可视化结果可知,输出特征图中包含一些冗余存在,因此可以使用更廉价的操作来实现冗余生成。
作者等人将输出的特征图看做内在特征与Ghost特征的组合,其中Ghost特征可以通过作用于内在特征的廉价操作获得,具体过程如下:
对于需要的输出尺寸,首先利用一次普通卷积生成m个本征特征图,即,其中,。接着对中的每一个特征图进行廉价操作以生成s个Ghost特征(n=m×s),可用公式表示:
代表中的第i个特征图,是生成第j个鬼魂特征图的第j个(最后一个除外)廉价操作,不进行廉价操作,而使用恒等映射来保留内在特征。
一份简单的C-Ghost模块代码示例如下所示:
class GhostModule(nn.Module): def __init__(self, in_channel, out_channel, kernel_size=1, ratio=2, dw_size=3, stride=1, relu=True): super(GhostModule, self).__init__() self.out_channel = out_channel init_channels = math.ceil(out_channel / ratio) new_channels = init_channels*(ratio-1) # 生成内在特征图 self.primary_conv = nn.Sequential( nn.Conv2d(in_channel, init_channels, kernel_size, stride, kernel_size//2, ), nn.BatchNorm2d(init_channels), nn.ReLU(inplace=True) if relu else nn.Sequential(), ) # 利用内在特征图生成Ghost特征 self.cheap_operation = nn.Sequential( nn.Conv2d(init_channels, new_channels, dw_size, 1, dw_size//2, groups=init_channels), nn.BatchNorm2d(new_channels), nn.ReLU(inplace=True) if relu else nn.Sequential(), ) def forward(self, x): x1 = self.primary_conv(x) x2 = self.cheap_operation(x1) out = torch.cat([x1,x2], dim=1) return out[:,:self.out_channel,:,:]
上述示例代码中使用低运算密度的depth-wise卷积作为生成Ghost特征的廉价操作,对于GPU等设备来说,无法充分利用其并行计算能力。另一方面,如果能去除部分特征图并减少激活,便可以概率地减少 GPU 上的延迟。
Radosavovic等人引入激活度(所有卷积层的输出张量的大小)来衡量网络的复杂性,对于GPU的延迟来说,激活度比 FLOPs更为相关。
如何实现这一目标?就得利用导读部分提及的“特征的相似性和冗余性不仅存在于一个层内,也存在于该阶段的多个层之间”。由于现有流行CNN架构中,同一阶段的不同层,其输出特征图的尺寸大小不会发生变化,因此一种跨层的廉价替代便可以通过这一特点来实现。其具体实现过程如下:
在CNN的某个阶段中,深层特征被分为Ghost特征(可通过浅层廉价操作获得)和复杂特征(不可通过浅层廉价操作获得),以图2为例:
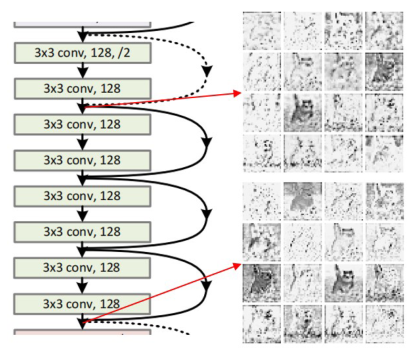
图2:左边为ResNet34第二阶段的所有卷积块,右边为该阶段的第一块和最后一块的特征图。
将第二阶段从浅到深的八个层分别记作,···,,假定的输出为,此时设定一个划分比例,那么输出的Ghost特征即为,复杂特征为。
其中复杂特征依次通过8个卷积层获得,具有更丰富的抽象语义信息,Ghost特征直接由的输出通过廉价操作获得,最终的输出通过通道拼接得以聚合。如下图所示():

图4:λ = 0.5 的 G-Ghost 阶段示意图。
但是,直接的特征拼接带来的影响是显而易见的。复杂特征经过逐层提取,包含更丰富的语义信息;而Ghost特征由浅层进行廉价操作所得,可能缺乏一部分深层信息。因此一种信息补偿的手段是有必要的,作者等人使用如下操作来提升廉价操作的表征能力:
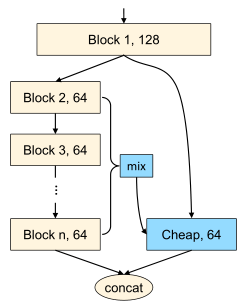
图5:λ = 0.5 的含有mix操作的 G-Ghost 阶段示意图。
如图5,复杂特征经过连续的n个卷积块生成,Ghost特征则由第一个卷积块经过廉价操作所得。其中mix模块用于提升廉价操作表征能力,即先将复杂特征分支中第2至第n层的中间特征进行拼接,再使用变换函数,变换至与廉价操作的输出同域,最后再进行特征融合(如简单的逐元素相加)。
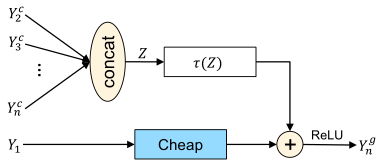
图6:mix操作的示意图。
下面以图6为例进行详细说明。如图,有至共n个同一阶段的卷积块输出,其中代表最后一层,即复杂特征;代表第一层,即廉价操作所应用的层。现将至的特征进行拼接,得到特征,并利用函数将Z变换至与廉价操作分支的输出一致的域,函数用公式表示如下:
代表对Z进行全局平均池化得到,和表示权重和偏差,即将Z池化后,通过一个全连接层进行域变换。
图6中两个分支的输出进行简单的逐元素相加,并应用非线性得到Ghost特征。
官方公布的g_ghost_regnet文件中,廉价操作的代码段为:
self.cheap = nn.Sequential( nn.Conv2d(cheap_planes, cheap_planes, kernel_size=1, stride=1, bias=False), nn.BatchNorm2d(cheap_planes),# nn.ReLU(inplace=True), )
除了大小为1的卷积核,廉价操作还可以用3×3、5×5的卷积核,或者直接的恒等映射来计算。
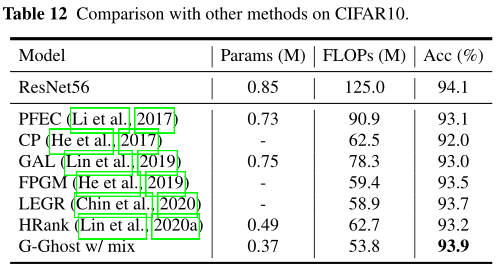
表1:ImageNet各方法比较。
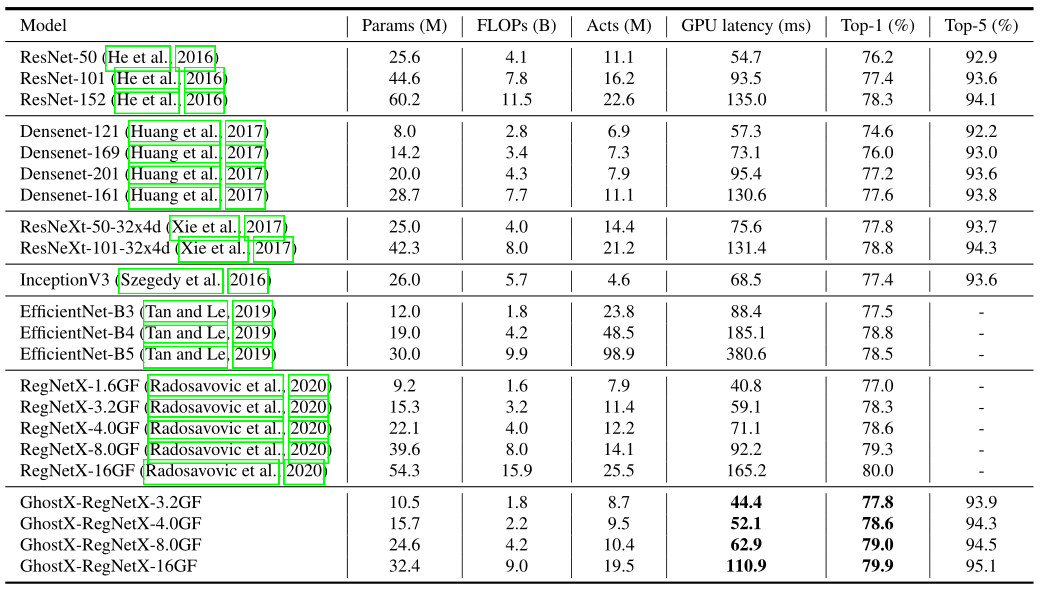
表2:ImageNet各方法比较(GhostX-RegNet)
本文利用可视化观察到的现象和大量的实验结果,提出了Ghost特征的思想,利用“特征的相似性和冗余性不仅存在于一个层内,也存在于该阶段的多个层之间”这一猜测,设计出相比C-Ghost更适用于GPU等设备的G-Ghost,并在实际延迟与性能之间取得了良好的权衡。
同时在G-Ghost中,合理的中间特征聚合模块有效缓解了Ghost特征信息损失的问题。但是Ghost特征与复杂特征的划分比例却需要手动调整,不同的对精度、延迟都有不同的影响,在作者等人的实际测试中,保持着精度与延迟的良好权衡。
另外关于使用C-Ghost、G-Ghost模块构建GhostNet整体网络,论文及代码中均有说明,感兴趣的读者可以自行阅览~








