绑定手机号
确认绑定









这篇文章讲解一种通过知识蒸馏的方式来压缩视觉 Transformer 的工作。相关的工作自从 2021 年初的 DeiT 以来,还没有比较经典的视觉 Transformer 知识蒸馏的文章出现。MiniViT 的中心思想为复用连续变压器模块的权重。更具体地说,作者使得权重跨层共享,同时对权重进行变换以增加多样性。
MiniViT:通过权重复用压缩视觉 Transformer 模型(来自微软)48.1 MiniViT 论文解读
Transformer 是 Google 的团队在 2017 年提出的一种 NLP 经典模型,现在比较火热的 Bert 也是基于 Transformer。Transformer 模型使用了 Self-Attention 机制,不采用 RNN 的顺序结构,使得模型可以并行化训练,而且能够拥有全局信息。
视觉 Transformer 的一个发展趋势是扩大参数量,使之在基准任务上取得更好的性能;另一个发展的趋势是把模型变小,以支持其在手机和物联网端侧设备的部署。这篇文章讲解一种通过知识蒸馏的方式来压缩视觉 Transformer 的工作。相关的工作自从 2021 年初的 DeiT 以来,还没有比较经典的视觉 Transformer 知识蒸馏的文章出现。DeiT 使用的知识蒸馏方法是 distillation token + Hard distillation,只包含了 logit 维度的蒸馏,没有使用任何的中间特征信息。而本文在这个维度上,给出了新的解法。MiniViT 的中心思想还有复用连续变压器模块的权重。更具体地说,作者使得权重跨层共享,同时对权重进行变换以增加多样性。
论文名称:MiniViT: Compressing Vision Transformers with Weight Multiplexing
论文地址:
https://arxiv.org/pdf/2204.07154.pdf
ViT 数以亿计的参数消耗了大量的存储和内存,使得这些模型不适合涉及有限计算资源的应用,如端侧设备和物联网设备,或者需要实时预测的应用。因此,不损害性能的前提下,消除这些预训练模型的冗余参数和计算开销是必要的。
权重共享是一种简单而有效的减小模型尺寸的技术。神经网络中权重共享的最初想法是由 LeCun[1] 和 Hinton[2] 在20世纪90年代提出的,最近被重新应用于自然语言处理 (NLP) 中的 Transformer 模型压缩。最具代表性的工作,ALBERT 介绍了一种跨层参数共享方法,防止参数数量随网络深度增长。这种技术可以在不严重损害性能的情况下显著减小模型大小,从而提高参数效率。然而,重量共享在 ViT 模型的压缩中还没有被很好地探索。
为了验证这一点,作者在 DeiT-S 和 Swin-B 上执行跨层权重共享。出乎意料的是,直接使用权重共享会带来两个严重的问题:
1) 训练不稳定: 跨 Transformer 层的权重共享会使得训练变得不稳定,甚至随着共享层数量的增加而导致训练崩溃。具体而言,如图1所示,在权重共享之后,梯度的 \ell_2\ell_2 范数变大,而且这个值在不同的 Transformer 块中波动剧烈。
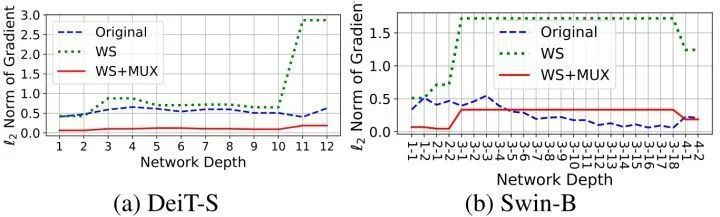
2) 性能下降: 与原始模型相比,权重共享视觉 Transformer 的性能显著下降。尽管权重共享可以将模型参数的数量减少4倍,它会导致 Swin-S 的精度下降 5.6%。
为了研究这些观察结果的潜在原因,作者分析了训练过程中,梯度的 \ell_2\ell_2 范数以及权重共享前后,模型的中间特征表示之间的相似性。作者发现不同层之间的权重严格一致是带来以上问题的主要原因。具体而言,不同 Transformer 块中的 LN 层在参数共享期间不应该相同,因为不同层的特征具有不同的幅值和统计信息。而且,在梯度共享之后,梯度的 \ell_2\ell_2 范数变大并在不同层之间波动,所以会导致训练不稳定。
最后作者同样检查了一个相似性的度量:Central Kernel Alignment (CKA) 值,发现在最后几层中显著下降 (如下图2所示),表明在权重共享之前和之后由模型生成的特征图变得更不相关,这可能是性能下降的原因。
 图2:不同策略下的模型特征相似度变化 (用 CKA 值衡量)
图2:不同策略下的模型特征相似度变化 (用 CKA 值衡量)权重复用
权重共享是提高参数效率的一种简单而有效的方法。核心思想是跨层共享参数,如图2(a)所示。在数学上,权重共享可以被公式化为一个 Transformer 块 ff 的递归更新过程:
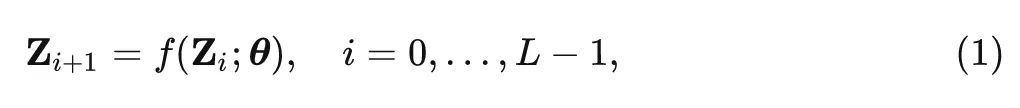
其中, 表示层 中序列的特征嵌入, 是层的总数, 表示所有层上的变换器块的共享权 重。权重共享可以在不严重损害网络性能的情况下, 防止参数数量随网络深度而增长, 从而提高参 数的利用效率。
为了解决以上问题,本文作者提出了一种新的技术,称为权重复用,以解决上述问题。具体而言,权重复用将多层权重合并为一个共享部分的单一权重,同时涉及变换 (Transformation) 和蒸馏 (distillation) 以增加参数多样性。它由权重变换 (weight transformation) 和权重蒸馏 (weight distillation) 两部分组成,共同压缩预训练好的 ViT 模型。
如图2(b)所示。在数学上,权重复用可以被公式化为一个 Transformer 块 ff 的递归更新过程:
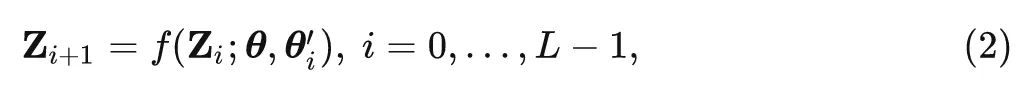
式中, 表示跨多个 Transformer 块的共享权重, 代表每一层的权重变换模块, 注意到 所 引入的额外参数量要比共享权重 的参数量少很多。
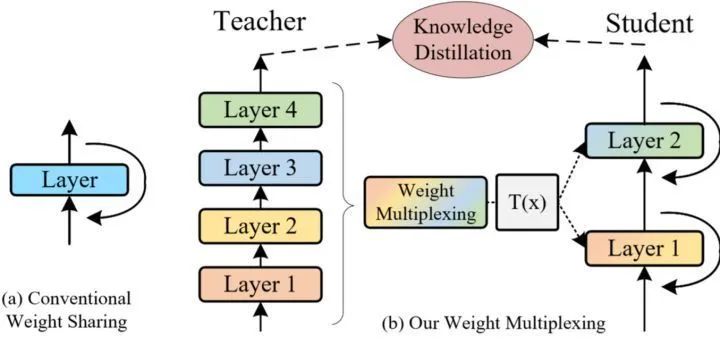 图3:经典的权重共享和权重复用
图3:经典的权重共享和权重复用权重变换
如图3所示,权重变换的关键思想是对共享的权重进行变换,使得不同的层具有稍微不同的权重,这样既能促进参数多样性,又能提高模型的表达能力和训练稳定性。具体而言,作者对 Self-attention 模块和 MLP 模块的权重施加简单的线性变换,用于每个权重共享的变换层。每一层包括单独的变换矩阵 (transformation matrix),因此 MLP 层的相应 Self-attention 模块和 MLP 模块的权重在各层之间是不同的。不同层的 LN 权重也是独立的,而不是共享相同的参数,这样使得权重复用的 ViT 的模型优化过程变得更加稳定。此外由于共享块占据了模型参数的绝大部分,因此在权重复用之后,模型大小仅略微增加。
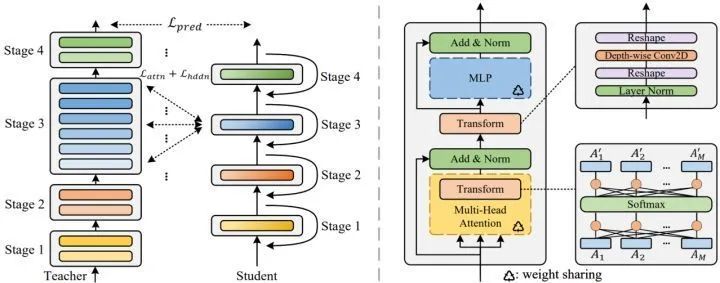 图4:(左):MiniViT 的流程框架。(右):MiniViT 每一块的详细架构
图4:(左):MiniViT 的流程框架。(右):MiniViT 每一块的详细架构MSA 的变换
作者在共享参数的 MSA 模块的 Softmax 层之前和之后分别插入了两个线性变换层,共享参数的 MSA 模块可以写成:
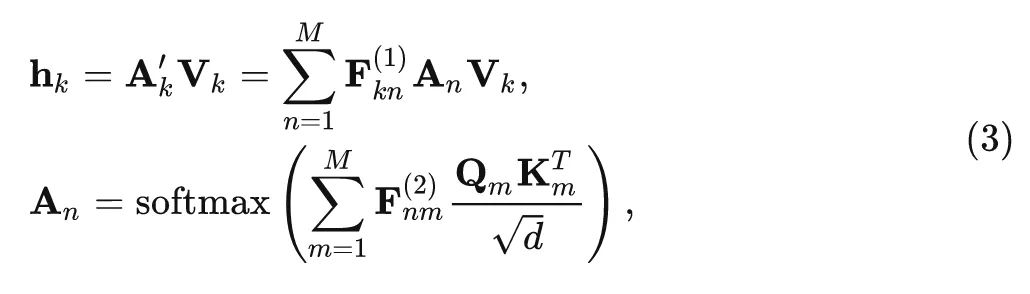
其中, 分别是 Softmax 层前后的线性变换矩阵, 这种线性变换可以使每个 注意力矩阵不同, 同时组合注意力头部的信息以增加参数的方差。
MLP 的变换
作者在共享参数的 MLP 模块的输入位置也放了一些线性变换来增加参数的多样性。假设输入为 , 其中 代表第 个位置的嵌入向量。作者在 个位置分别引入了 个线性 变换, 把 转换为 , 式中 为线性变换层的权重。共享参数的 MLP 模块可以写成:
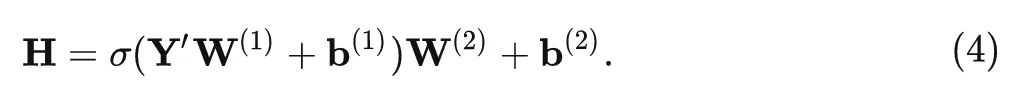
为了减少参数的数量并在线性变换中引入局部性, 作者使用 Depth-Wise Convolution, 取 是卷积核的大小, 使用了 DW 卷积之后参数量为 , 少于原来的 个参数。变换后, MLP 的输 出变得更加多样化, 提高了参数的效率。理论上, 通过这些转换, 权重共享层可以恢复预训练模型的行为。
权重蒸馏
为了减轻性能下降,作者进一步提出权重蒸馏技术,使得嵌入在预训练模型中的信息可以转移到权重共享的小模型中,这些小模型更加紧凑和轻量。权重蒸馏额外考虑了 attention-level 和 hidden-state 的提取,允许较小的模型去模仿原始预训练的大的教师模型的行为。
首先是 Prediction-Logit 蒸馏,这里使用教师和学生预测结果之间的 CE Loss 作为目标函数:

式中, 和 分别为学生模型和教师模型的输出结果, 取温度 。
然后是 Self-Attention 维度的蒸馏, 因为最近的文献表明, 利用 Transformer 层中的 Attention map 来指导学生模型的训练是有益的。为了解决教师和学生模型的 Embedding dimension 不一致的问题, 作者对 MSA 中的
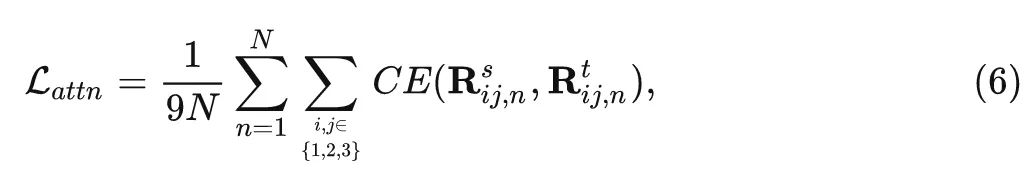
式中, 代表 的第 行。
最后是 Hidden-State 维度的蒸馏。作者进一步生成隐藏状态的关系矩阵,即 MLP 输出的特征。用表示 Transformer 层的隐藏状态,基于关系矩阵的隐藏状态蒸馏损失函数可以定义为:
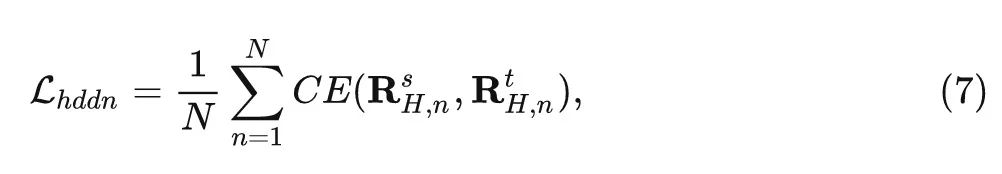
式中, 代表 的第 行, 且有 。
最终总的损失函数为:

式中, 默认为1和0.1。
实验设置
作者默认只在一个模型的每个 Stage 内部进行权重共享,因为不同阶段的参数的维数是不一致的 (由特征下采样引起)。对于 DeiT 这个各向同性的视觉骨干模型,只有一个 Stage,则连续的2层都会共享参数。作者还对 DeiT 做了一些修改:删除了 [class] token,并在模型的末尾使用 global average pooling + FC 层已完成分类任务。作者还通过相对位置编码来引入归纳偏置,以利于模型收敛。
作者直接继承来自 DeiT 或 Swin Transformer 的超参数,在 ImageNet-1K 上从头开始训练 MiniViT 模型。数据增强的方式包括 RandAugment, Cutmix, Mixup, Random Erasing 和 RepeatAug (仅用于 DeiT)。在应用于下游任务时,继续在 384×384 分辨率的图像上微调 30 Epoch。
优化器使用 AdamW,权重衰减为 1e-8,cosine scheduler,Batch Size 设为256。初始学习率分别是 2.5e-6 (DeiT) 和 1e-5 (Swin)。
为了压缩 Swin 模型,作者采用 88M 参数的 ImageNet-22K 预训练的 Swin-B 作为教师模型。因此,压缩模型仍然可以通过蒸馏操作来学习大规模数据集 ImageNet-22K 的知识,而不需要访问数据集。
对于 DeiT Z作者使用具有 84M 参数的 RegNet-16GF 作为教师,由于教师模型 (CNN) 和学生模型 (ViT) 之间的异构架构,仅执行 Prediction-Logit 蒸馏。对于 DeiT,连续的2层共享参数。对于 Swin,每个阶段的所有层共享参数。对于 MLP 的变换层,DW 卷积的 kernel size 与 window size 保持一致。
消融实验
权重变换消融实验
直接使用权重共享时,训练过程极易崩塌,同时会给模型带来严重的性能下降。首先作者研究训练过程的稳定性,
对于 DeiT-S 模型,每连续的两层使用权重共享,对于 Swin-B 模型,每个 Stage 的所有层进行权重共享,结果如上图1所示。权重共享之后,DeiT-S 和 Swin-B 中的梯度的 范数变大,而且这个值在不同的 Transformer 块中波动剧烈。而且,不同层之间梯度的波动剧烈会导致不同层参数的优化速度不同:一些权重更新速度很快,而其他权重几乎很难被优化,这使得模型可能收敛到局部最优,甚至在训练中不收敛。因此,如果使得各层之间的参数严格相同,则会导致训练不稳定。权重复用方法可以通过引入线性变换操作来改善参数多样性,从而得到更稳定的训练过程,从而降低梯度范数并增加跨层的平滑度。图2中也给出了关于权重共享和权重复用之间的 CKA 的特征相似性的比较。CKA 的值越高,代表着2个模型之间具有更高的特征相似性。但是使用权重共享以后,DeiT 和 Swin 的特征出现了较大的偏差,尤其是在最后几层,这可能是权重共享带来性能下降的原因之一。
下面是权重变换和权重蒸馏的消融实验结果。当使用了简单的权重共享方法后,两个模型的参数量都减半,而精度也降低了2%。而权重变换 (WT) 和权重蒸馏 (WD) 都可以带来性能的提高,证明了它们各自的有效性,最终的精度也优于原始的 DeiT-S 和 Swin-T 模型。
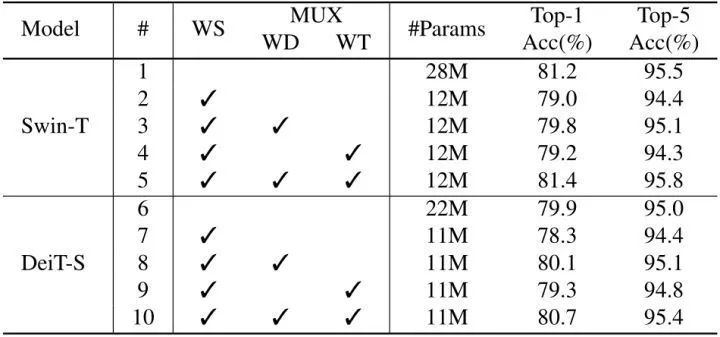 图5:权重变换和权重蒸馏的消融实验结果,WS: Weight Sharing, WD: Weight Distillation, WT: Weight Transformation
图5:权重变换和权重蒸馏的消融实验结果,WS: Weight Sharing, WD: Weight Distillation, WT: Weight Transformation蒸馏损失消融实验
作者尝试了三种方法:1. 只使用 GT 标签进行监督学习 2. 使用 GT 标签和教师模型的预测结果作为软标签 3. 使用 GT 标签,教师模型的预测结果作为软标签以及 Self-Attention 维度,Hidden-State 维度的蒸馏。
ImageNet 实验结果
如下图6所示为 ImageNet 实验结果,以上结果都是直接在 ImageNet-1K 上训练得到,无需使用 ImageNet-22K 进行预训练。Mini-Swin 和 Mini-DeiT 只需一半的参数就达到了原始 Swin 和 DeiT 的精度。特别地,使用46M 参数时,本文的 Mini-Swin-B 的精度比 ImageNet-1K 上的 Swin B高 0.8%。此外,Mini-DeiT-B 也减少了 50% 的参数数量,并实现了 1.8% 的性能提升。
 图6:ImageNet 实验结果
图6:ImageNet 实验结果与其他高效的 ViT 模型相比,Mini-ViT 的实验结果也很有竞争力。具体来说,只有 44M 参数的 Mini-DeiT-B 的Top-1 精度分别比 S2ViTE-B (57M) 和 VTP (48M) 高 1.0% 和 2.5%。此外,Mini-DeiT 也可以胜过一些 NAS 方法。比如 Mini-DeiT-B 仅使用 44M 参数,实现比 AutoFormer-B (54M) 高 0.8% 的精度。
迁移学习实验结果
为了进一步验证 MiniViT 的迁移性能,作者进一步在一些小数据集上进行了实验,如 CIFAR-10,CIFAR-100,Flowers,Stanford Cars 和 Oxford-IIIT Pets 等。采用的是 DeiT 默认的微调方法,即使用 SGD 优化器,5e-3 的初始学习率,Batch Size 为256,weight decay 设置为 5e-2,与最先进的 ConvNets 和基于 Transformer 的模型相比,Mini-DeiT-B↑384 仅使用 44M 参数就可以在所有数据集上获得相当甚至更好的结果。
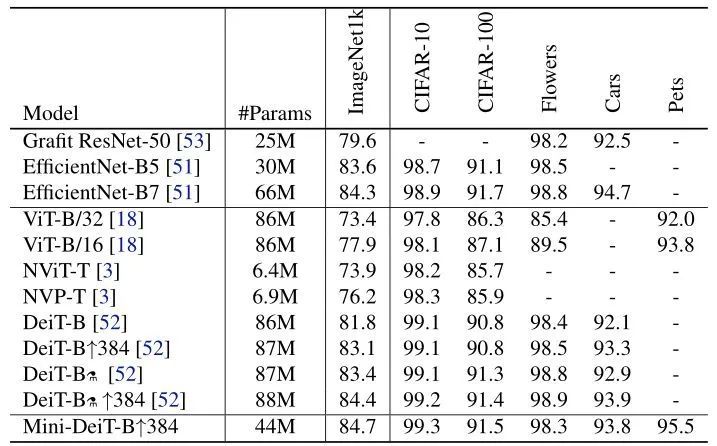
MiniViT 是一个 ViT 模型的压缩方法,它基于深度学习模型的权重共享思想,作者在 DeiT-S 和 Swin-B 上执行跨层权重共享。但是直接使用权重共享会带来两个严重的问题:训练不稳定和性能下降。这些问题主要是由于在权重共享之后,梯度的 范数变大,而且这个值在不同的 Transformer 块中波动剧烈,导致所有层的参数无法得到均匀且合适的优化。为了解决这些问题,作者在本文提出了权重复用方法,它主要是由权重变换 (weight transformation) 和权重蒸馏 (weight distillation) 两部分组成,共同压缩预训练好的 ViT 模型。权重变换主要是对 Self-attention 模块和 MLP 模块的权重施加简单的线性变换,用于每个权重共享的变换层。每一层包括单独的变换矩阵 (transformation matrix),因此 MLP 层的相应 Self-attention 模块和 MLP 模块的权重在各层之间是不同的。不同层的 LN 权重也是独立的,而不是共享相同的参数,这样使得权重复用的 ViT 的模型优化过程变得更加稳定。对于权重蒸馏方法,除了基本的 Prediction-Logit 蒸馏之外,作者额外考虑了 Self-Attention 维度的蒸馏和 Hidden-State 维度的蒸馏。通过以上两种技术,MiniViT 使得 ViT 模型在参数降低约2倍前提下不损失性能。
参考
^Generalization and network design strategies
^Simplifying neural networks by soft weight-sharing








