绑定手机号
确认绑定









通过比较输入样本与内存池中的内存样本的异同,对异常区域进行有效猜测;在推理阶段,MemSeg直接以端到端的方式确定输入图像的异常区域。
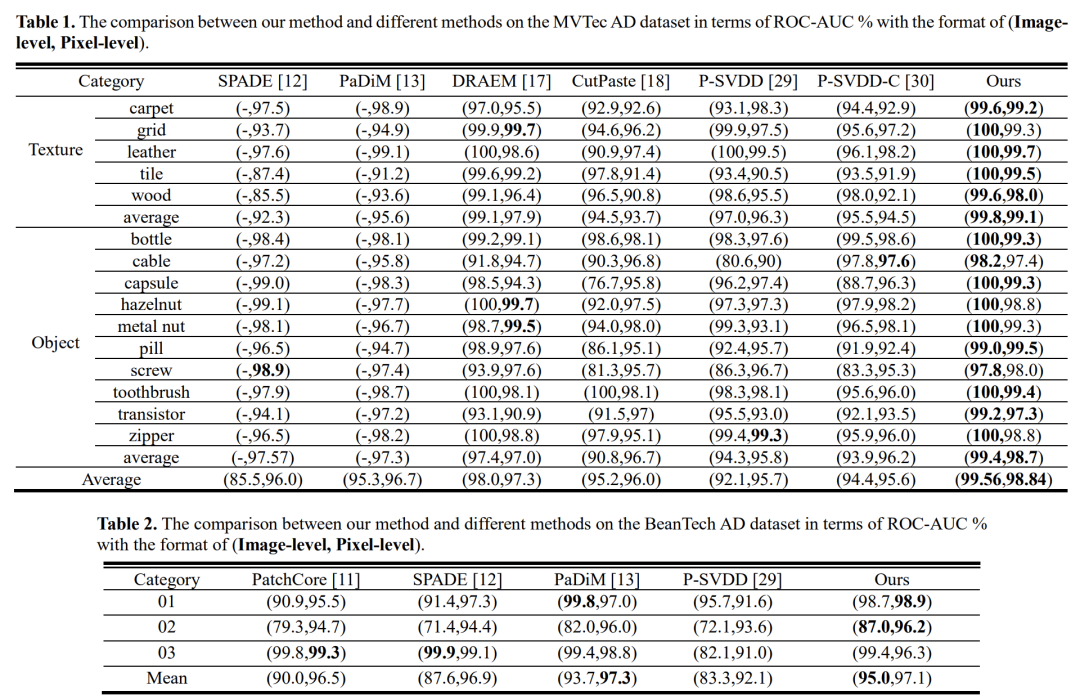
通过实验验证,MemSeg在MVTec AD数据集上实现了最先进的(SOTA)性能,图像级和像素级的AUC得分分别为99.56%和98.84%。此外,MemSeg得益于端到端、直截了当(straightforward)网络结构,在推理速度上也有明显优势,更好地满足工业场景的实时性要求。
工业场景下的产品表面异常检测对于工业智能的发展至关重要。 表面缺陷检测是在图像中定位异常区域的问题,例如划痕和污迹。 但在实际应用中,由于异常样本的概率低且异常形式多样,传统监督学习的异常检测难度更大。 因此,基于半监督技术的表面缺陷检测方法在实际应用中具有更显着的优势,在训练阶段只需要正常样本。
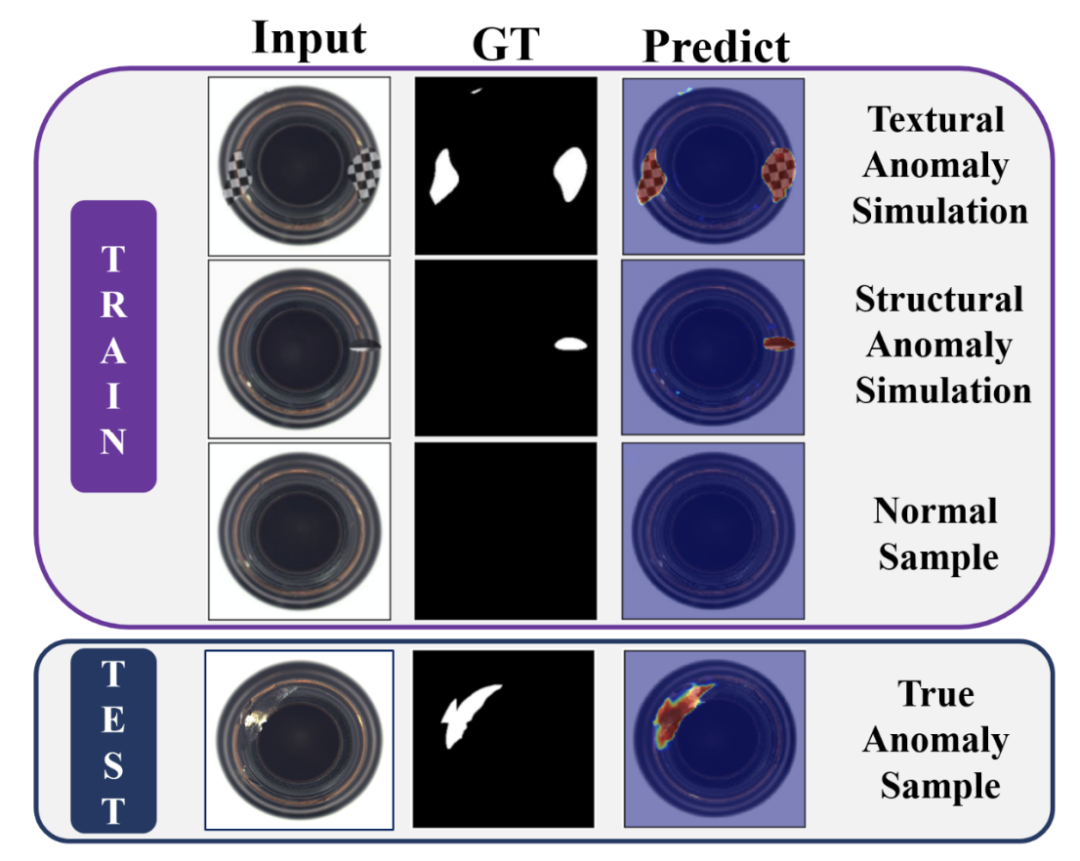
具体来说,从差异的角度来看,类似于自监督学习,MemSeg在训练阶段引入了人工模拟的异常,使模型有意识地区分正常和非正常,而不要求模拟的异常与真实场景中的一致。 缓解了半监督学习只能使用正常样本的不足,让模型获得了更鲁棒的决策边界。 MemSeg使用正常和模拟异常图像完成模型训练,直接判断输入图像的异常区域,在推理阶段无需任何辅助任务。 下图就显示了在训练和推理阶段的数据使用情况。
同时,从共性的角度,MemSeg引入了一个内存池来记录正常样本的一般模式。 在模型的训练和推理阶段,比较输入样本和记忆池中记忆样本的异同,为异常区域的定位提供更有效的信息。 此外,为了更有效地协调来自内存池的信息和输入图像,MemSeg引入了多尺度特征融合模块和新颖的空间注意力模块,大大提高了模型的性能。
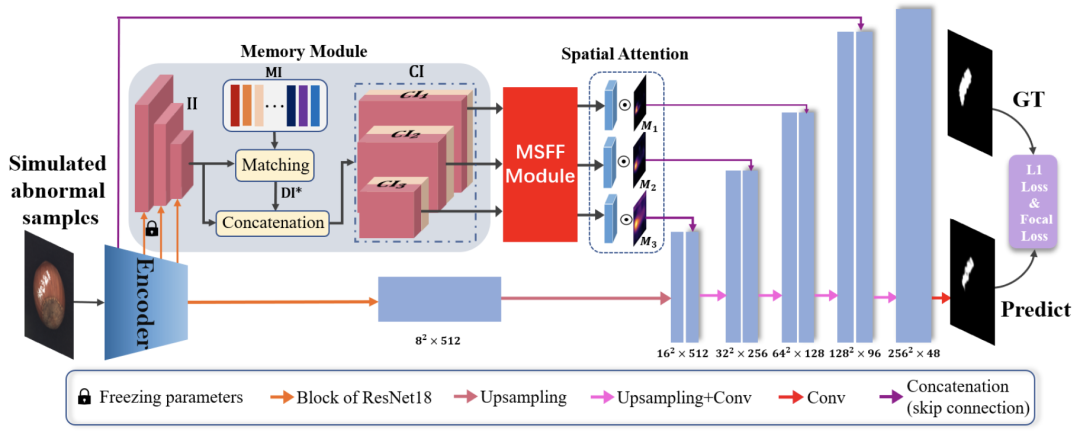
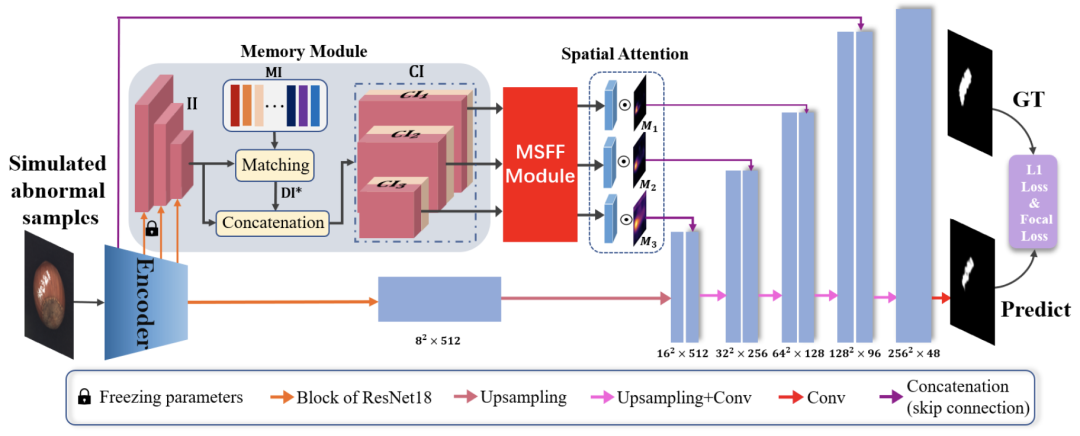
上图就是MemSeg整体框架图。MemSeg基于U-Net架构,使用预训练的ResNet18作为编码器。MemSeg从差异和共性的角度出发,引入模拟异常样本和记忆模块,以更有方向性的方式辅助模型学习,从而以端到端的方式完成半监督表面缺陷任务。 同时,为了将记忆信息与输入图像的高层特征充分融合,MemSeg引入了多尺度特征融合模块(MSFF Module)和新颖的空间注意力模块,大大提高了模型精度异常定位。
Anomaly Simulation Strategy
在工业场景中,异常以多种形式出现,在进行数据收集时不可能将其全部覆盖,这限制了使用监督学习方法进行建模。 然而,在半监督框架中,仅使用正常样本而不与非正常样本进行比较不足以让模型了解什么是正常模式。
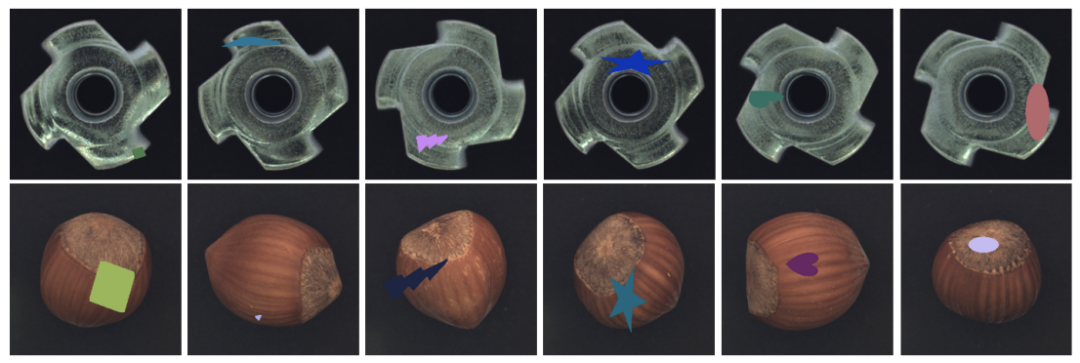
在今天分享中,受DRAEM的启发,研究者就设计了一种更有效的策略来模拟异常样本并在训练过程中引入它们以完成自监督学习。MemSeg通过比较非正态模式来总结正态样本的模式,以减轻半监督学习的弊端。 如下图所示,提出的异常模拟策略主要分为三个步骤。
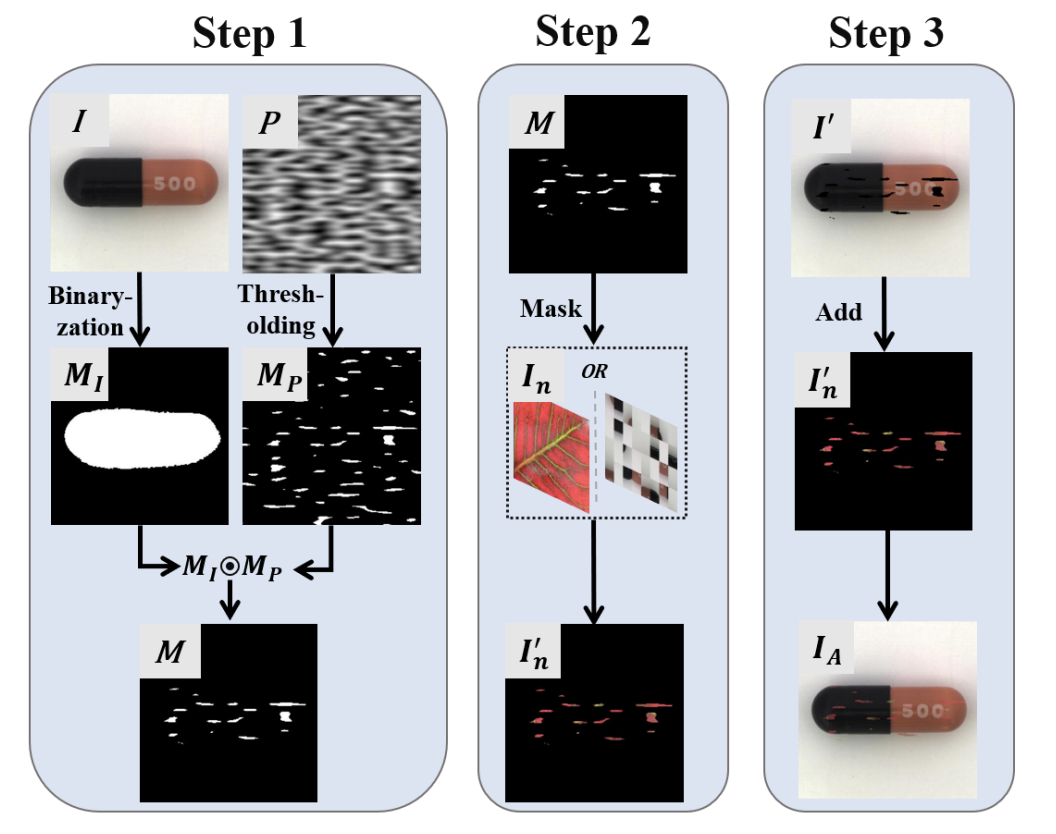
二维柏林噪声P二值化后生成Mp,正常图I二值化后生成MI,二者结合生成M,这种处理是为了让生成的异常图与真实异常图相似。
利用公式做正常图和M的融合使接近真实异常图:
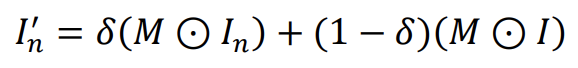
将M反转(黑变白,白变黑),与I做元素积,与I'做元素和,生成IA。
通过上述异常模拟策略,从纹理和结构两个角度获取模拟异常样本,并且大部分异常区域都生成在目标前景上,最大限度地提高了模拟异常样本与真实异常样本的相似度。
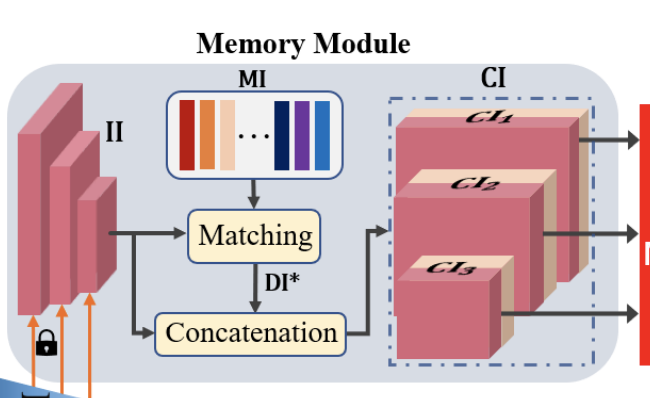
Memory Module
选N个正常图经ResNet作为存储的信息,冻结ResNet的block1/2/3的参数保证高维特征与记忆信息统一,其余部分仍可训练。训练及推理阶段,通过下公式比较距离:

N个存储信息中,每个包括块1/2/3生成的三张特征图,将输入的三张特征图与N中所有的三个特征图比较找出距离最小的N中的三张特征图。将输入的三张特征图与和其距离最小的三张特征图连接形成CI。后经多尺度特征融合块,经U-Net跳跃连接进入解码器。
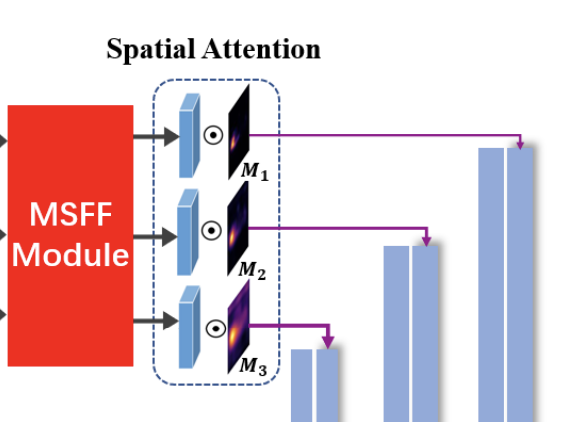
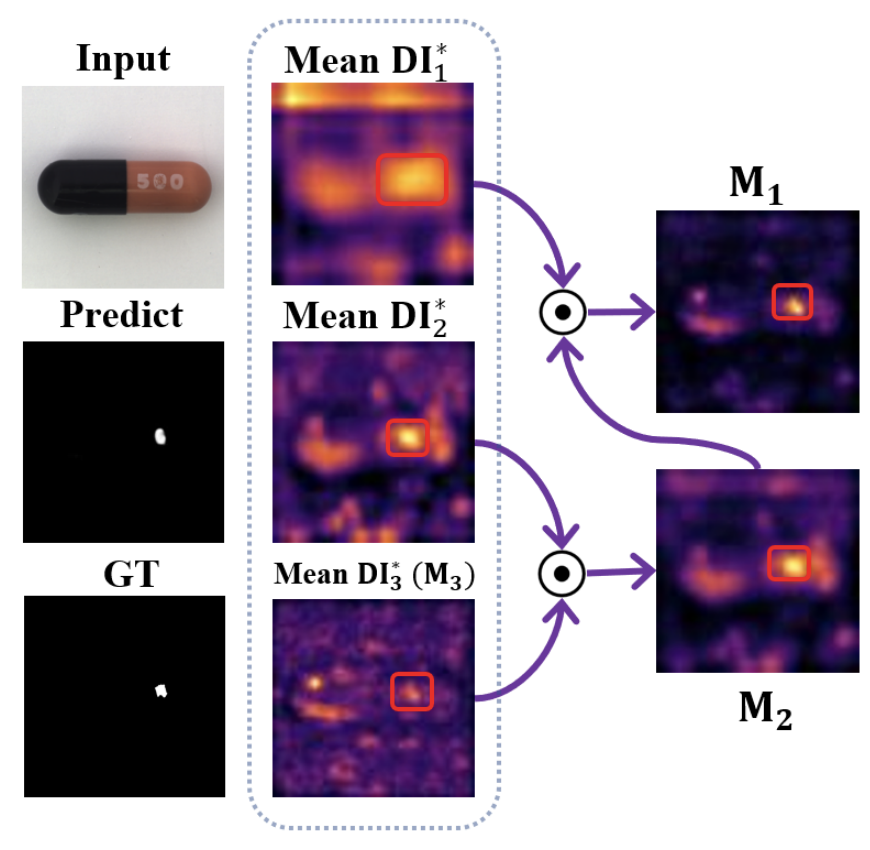
Spatial Attention Maps
涉及到空间注意力块,由下公式为三个特征图增加权重,降低特征冗余:

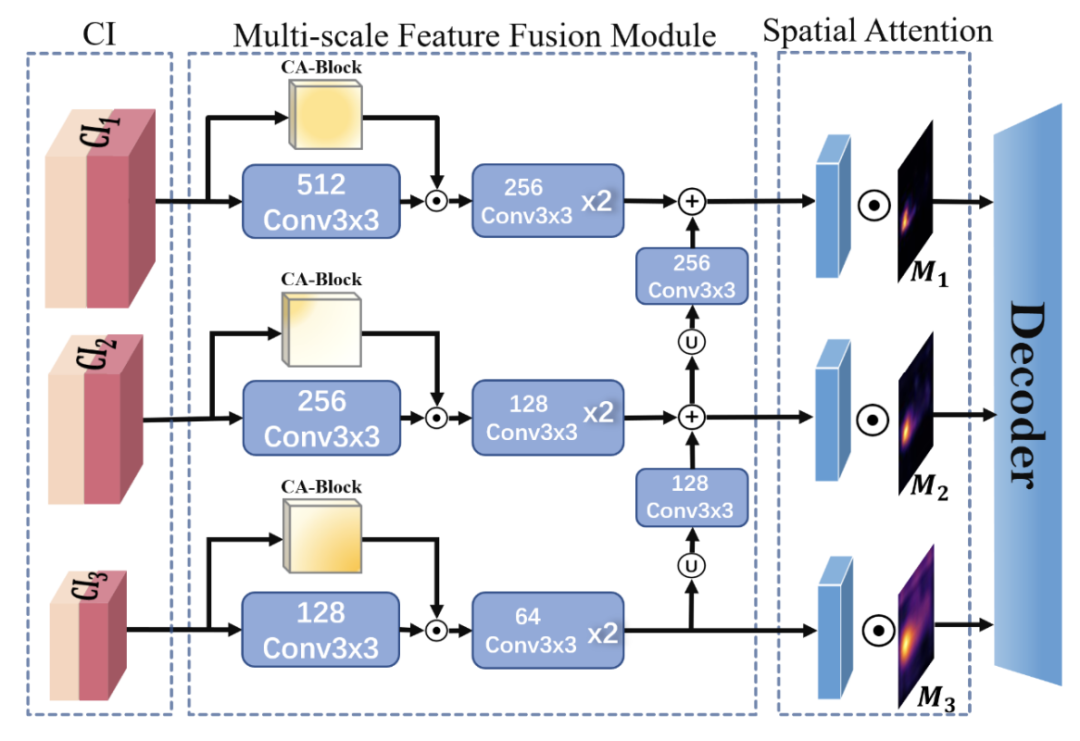
Multi-Scale Feature Fusion Module
考虑到它是通道维度上两种信息的串联,并且来自编码器的不同位置,具有不同的语义信息和视觉信息,因此使用通道注意力CA-Block和多尺度策略进行特征融合。
Training Constraints(训练损失)
L1损失和focal损失。L1比L2保留更多边缘信息,focal缓解样本不平衡问题,使模型专注于分割本身而不是样本的情况。
可视化: