绑定手机号
确认绑定









arXiv在2021年12月“BEVDet: High-Performance Multi-Camera 3D Object Detection in Bird-Eye-View“,作者是北京鉴智机器人公司。

自主驾驶能够感知周围环境进行决策,这是视觉感知最复杂的应用场景之一。本文提出BEVDet,根据在鸟瞰视图(BEV)中检测3D目标,因为BEV能方便地执行路线规划(route planning)。
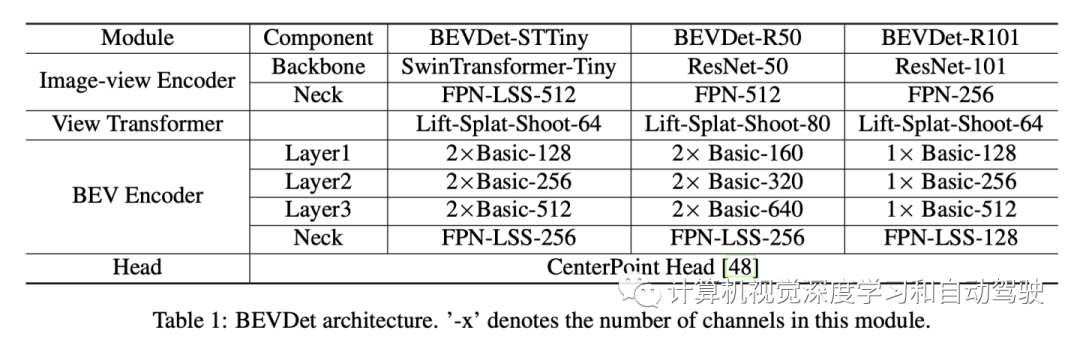
其包括四类模块:在图像视图编码特征的图像视图编码器、将特征从图像视图转换为BEV的视图transformer、在BEV中进一步编码特征的BEV编码器以及用于预测BEV中目标(target)的任务特定头。只需重复使用现有的模块来构建BEVDet,并通过构建专用的数据增强策略用于多摄像机3D目标检测。
BEVDet如图所示:图像视图编码器,包括主干和颈部,用于图像特征提取;视图transformer将特征从图像视图转换为BEV;BEV编码器进一步编码BEV特征;最后,基于BVE特征构建特定于任务的头部,并预测3D目标的目标值(target values)。
如下表是BEVDet的几个变型:
图像像素点加深度,可以得到其3-D空间坐标:

文章采用一个数据增强策略,即变换A:
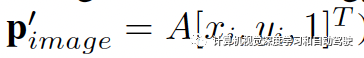
那么为保持图像像素与三维空间对应点之间的一致性,在视图变换过程中应采用A逆,即:
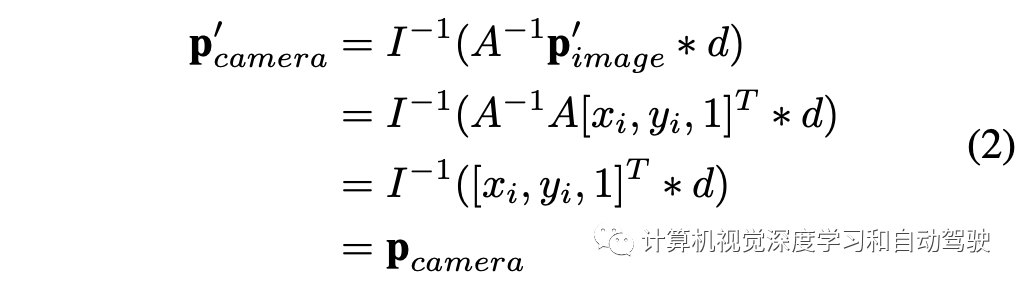
在BEV空间中的学习,数据量少于图像视图空间的数据量,因为每个样本包含多个摄像机图像(例如,nuScenses基准数据的每个样本包含6个图像)。因此,BEV空间中的学习容易陷入过拟合。
在增强角度看,视图transformer将两个视图空间隔离,为此构建另一个增强策略,专门为BEV空间学习的正则化。二维空间的常见数据扩充操作包括翻转、缩放和旋转。
在实践中,这些操作同时在视图transformer的输出特征和三维目标检测的目标上进行,保持其空间一致性。值得注意的是,这种数据增强策略建立于这样的前提,即视图transformer解耦图像视图编码器与后续模块。
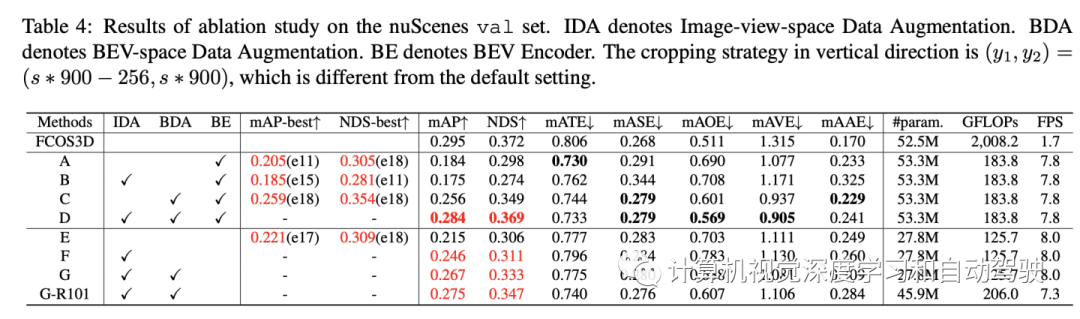
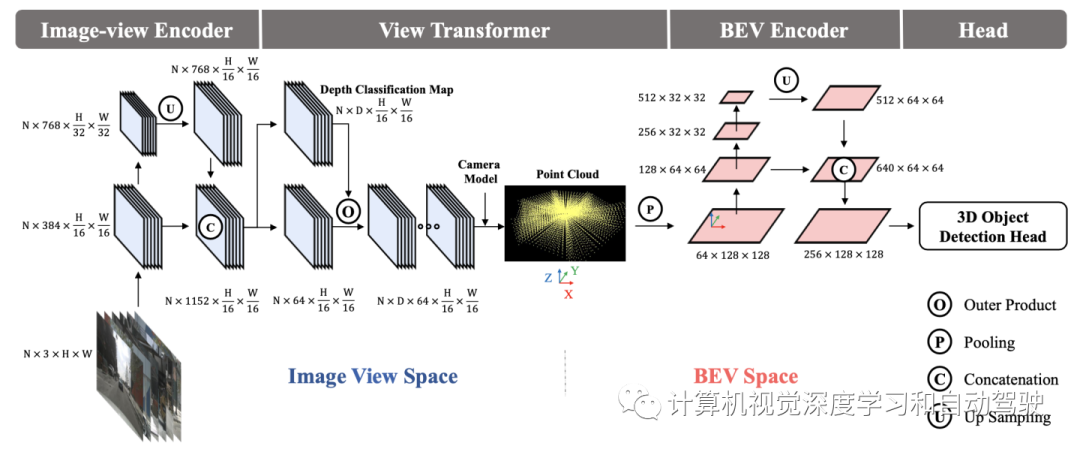
实验结果如下: