绑定手机号
确认绑定









本文接着《必看部署系列-神经网络量化教程:第一讲!》这一篇接着来说。上一篇主要说了量化的一些基本知识、为啥要量化以及基本的对称量化这些概念知识点。按理说应该继续讲下非对称量化、量化方式等等一些细节,不过有一段时间在做基于TensorRT的量化,需要看下TensorRT的量化细节,就趁这次机会讲一下。

算是量化番外篇。
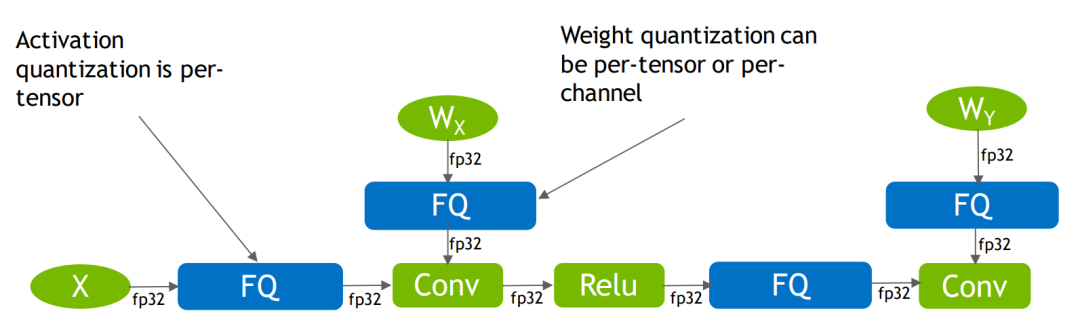
这是偏实践的一篇,主要过一下TensorRT对于explict quantization的流程和通用的量化思路。
都2022年了,量化技术已经很成熟了,各种量化框架[1]和量化算法层出不穷。我之前接触过几个量化框架,大部分都是在算法层面模拟一下,实际上无法直接部署到具体的硬件层,也只是停留在算法的层面。而现在成熟的量化框架已经不少,开源的也有很多,无论是pytorch、TVM还是TensorRT,基于这些框架的GPU和CPU量化已经应用了不少,我也看了看最近商汤新开源的量化框架ppq,同样也挺成熟了,最起码用起来是的的确确可以实际部署,为我们带来性能的提升。
上一篇主要是理论细节比较多,那么这一篇主要说说实际的量化流程。要实际用起来、跑起来才有意义。因为有一段时间在用TensorRT,所以就说说TensorRT的量化细节和实际量化流程吧!
 你懂得
你懂得TensorRT的量化工具也比较成熟了。支持PTQ和QAT量化,官方也提供了一些工具[2]去帮助我们实现量化(无论是基于trt本身还是基于周边工具)。
当然除了TensorRT我也用过一些其他的量化框架,也写过一些代码。其实大部分量化方式基本大同小异,大方向都是读取模型,转化为IR进行图分析,做一些优化策略等等,关于怎么组织图,怎么优化结构可能会不一样。还有具体的校准算法的不同,不过总体上,量化的整体思路是差不多的。
因此,了解TensorRT的量化过程是是挺重要的,也有助于理解其他框架的量化方式,毕竟万变不离其宗。
TensorRT有两种量化模式,分别是implicitly以及explicitly量化。前者是隐式量化,在trt7版本之前用的比较多。而后者显式量化是在8版本后才完全支持,具体就是可以加载带有QDQ信息的模型然后生成对应量化版本的engine。
两种量化模型的一些支持情况:
 TensorRT中两种量化流程
TensorRT中两种量化流程与隐式量化相关性较强的是训练后量化。
训练后量化即PTQ量化,trt的训练后量化算法第一次公布在2017年,NVIDIA放出了使用交叉熵量化的一个PPT,简单说明了其量化原理和流程,其思想集成在trt内部供用户去使用。对我们是闭源的,我们只能通过trt提供的API去量化。
不需要训练,只需要提供一些样本图片,然后在已经训练好的模型上进行校准,统计出来需要的每一层的scale就可以实现量化了,大概流程就是这样:
 PTQ量化流程
PTQ量化流程具体使用就是,我们导出ONNX模型,转换为TensorRT的过程中可以使用trt提供的Calibration方法去校准,这个使用起来比较简单。可以直接使用trt官方提供的trtexec命令去实现,也可以使用trt提供的python或者C++的API接口去量化,比较容易。
目前,TensorRT提供的后训练量化算法也多了好多,分别适合于不同的任务:
EntropyCalibratorV2
Entropy calibration chooses the tensor’s scale factor to optimize the quantized tensor’s information-theoretic content, and usually suppresses outliers in the distribution. This is the current and recommended entropy calibrator and is required for DLA. Calibration happens before Layer fusion by default. It is recommended for CNN-based networks.
MinMaxCalibrator
This calibrator uses the entire range of the activation distribution to determine the scale factor. It seems to work better for NLP tasks. Calibration happens before Layer fusion by default. This is recommended for networks such as NVIDIA BERT (an optimized version of Google's official implementation).
EntropyCalibrator
This is the original entropy calibrator. It is less complicated to use than the LegacyCalibrator and typically produces better results. Calibration happens after Layer fusion by default.
LegacyCalibrator
This calibrator is for compatibility with TensorRT 2.0 EA. This calibrator requires user parameterization and is provided as a fallback option if the other calibrators yield poor results. Calibration happens after Layer fusion by default. You can customize this calibrator to implement percentile max, for example, 99.99% percentile max is observed to have best accuracy for NVIDIA BERT.
通过上述这些算法量化时,TensorRT会在优化网络的时候尝试INT8精度,假如某一层在INT8精度下速度优于默认精度(FP32或者FP16)则优先使用INT8。这个时候我们无法控制某一层的精度,因为TensorRT是以速度优化为优先的(很有可能某一层你想让它跑int8结果却是fp32)。即使我们使用API去设置也不行,比如set_precision这个函数,因为TensorRT还会做图级别的优化,它如果发现这个op(显式设置了INT8精度)和另一个op可以合并,就会忽略你设置的INT8精度。
说白了就是不好控制。我也尝试过这种方式,简单情况,简单模型问题不大(resnet系列),涉及到比较复杂的(transformer)这个设置精度可能不管用,谁知道TensorRT内部是怎么做优化的呢,毕竟是黑盒子。
训练中量化(QAT)是TensorRT8新出的一个“新特性”,这个特性其实是指TensorRT有直接加载QAT模型的能力。QAT模型这里是指包含QDQ操作的量化模型。实际上QAT过程和TensorRT没有太大关系,trt只是一个推理框架,实际的训练中量化操作一般都是在训练框架中去做,比如我们熟悉的Pytorch。(当然也不排除之后一些优化框架也会有训练功能,因此同样可以在优化框架中做)
TensorRT-8可以显式地load包含有QAT量化信息的ONNX模型,实现一系列优化后,可以生成INT8的engine。
QAT量化信息的ONNX模型长这样:
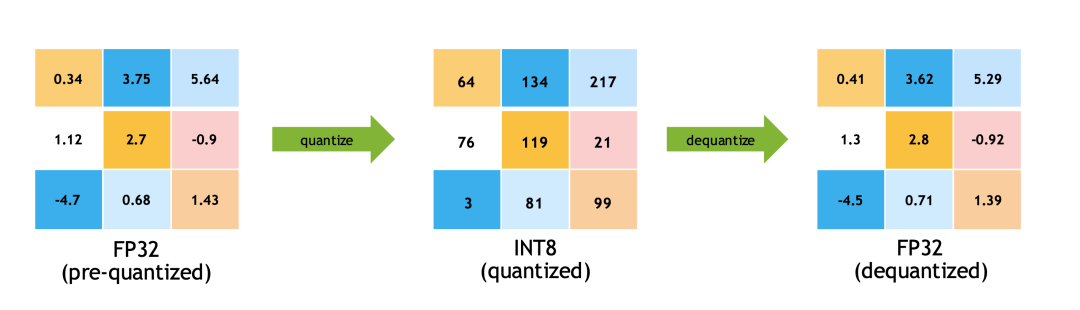
 多了quantize和dequanzite算子
多了quantize和dequanzite算子可以看到有QuantizeLiner和DequantizeLiner模块,也就是对应的QDQ模块,包含了该层或者该激活值的量化scale和zero-point。QDQ模块会参与训练,负责将输入的FP32张量量化为INT8,随后再进行反量化将INT8的张量在变为FP32。实际网络中训练使用的精度还是FP32,只不过这个量化算子在训练中可以学习到量化和反量化的尺度信息,这样训练的时候就可以让模型权重和量化参数更好地适应量化这个过程(当然,scale参数也是可以学习的),量化后的精度也相对更高一些。
 感知量化过程中的qdq模块
感知量化过程中的qdq模块QAT量化中最重要的就是fake量化算子,fake算子负责将输入该算子的参数和输入先量化后反量化,然后记录这个scale,就是模拟上图这个过程。
比如我们有一个网络,精度是FP32,输入和权重因此也是FP32:
 普通模型的训练过程
普通模型的训练过程我们可以插入fake算子:
 QAT模型的训练过程
QAT模型的训练过程FQ(fake-quan)算子会将FP32精度的输入和权重转化为INT8再转回FP32,记住转换过程中的尺度信息。
这些fake-quan算子在ONNX中可以表示为QDQ算子:
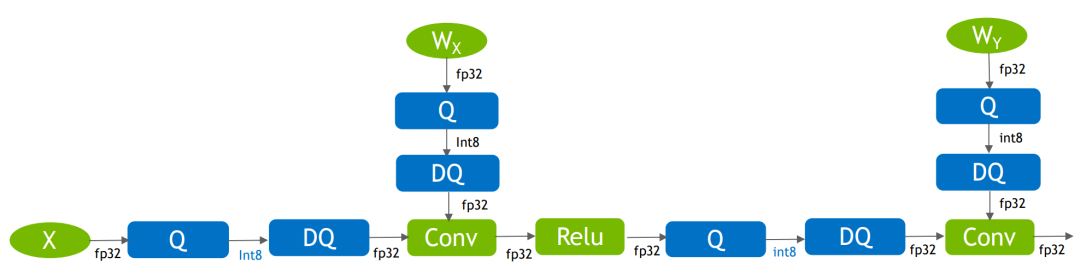 ONNX中的QDQ-fake-quantize
ONNX中的QDQ-fake-quantize什么是QDQ呢,QDQ就是Q(量化)和DQ(反量化)两个op,在网络中通常作为模拟量化的op,比如:
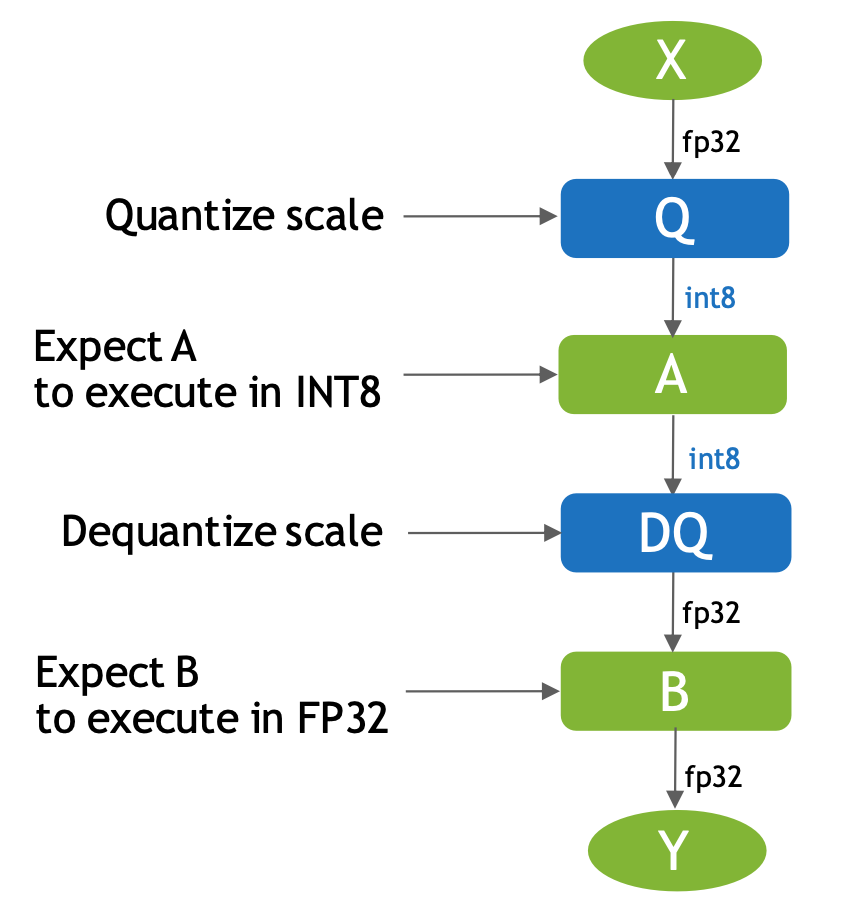 QDQ操作示例
QDQ操作示例输入X是FP32类型的op,输出是FP32,然后在输入A这个op时会经过Q(即量化)操作,这个时候操作A我们会默认是INT8类型的操作,A操作之后会经过DQ(即反量化)操作将A输出的INT8类型的结果转化为FP32类型的结果并传给下一个FP32类型的op。
那么QDQ有啥用呢?
第一个是可以存储量化信息,比如scale和zero_point啥的,这些信息可以放在Q和QD操作中
第二个可以当做是显式指定哪一层是量化层,我们可以默认认为包在QDQ操作中间的op都是INT8类型的op,也就是我们需要量化的op
比如下图,可以通过QDQ的位置决定每一层OP的精度:
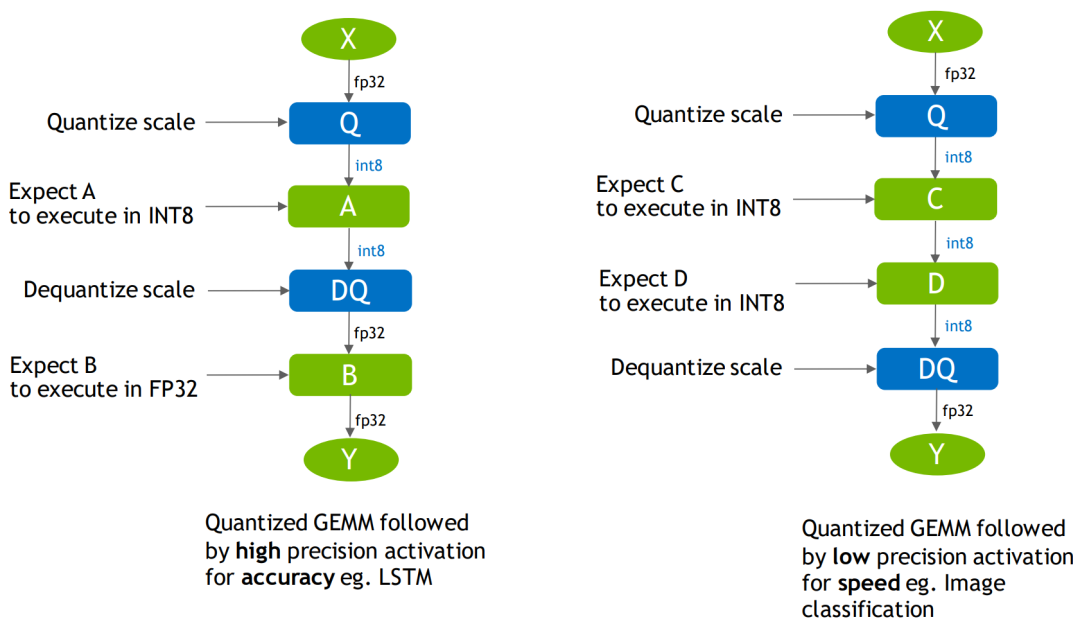 QDQ决定量化细节
QDQ决定量化细节因此对比显式量化(explicitly),trt的隐式量化(implicitly)就没有那么直接,在trt-8版本之前我们一般都是借助trt的内部的量化算法去量化,在构建engine的时候传入图像进行校准,执行的是训练后量化的过程。
而有了QDQ信息,TensorRT在解析模型的时候会根据QDQ的位置找到(我们给予提示的)可量化的op,然后与QDQ融合(吸收尺度信息到OP中):
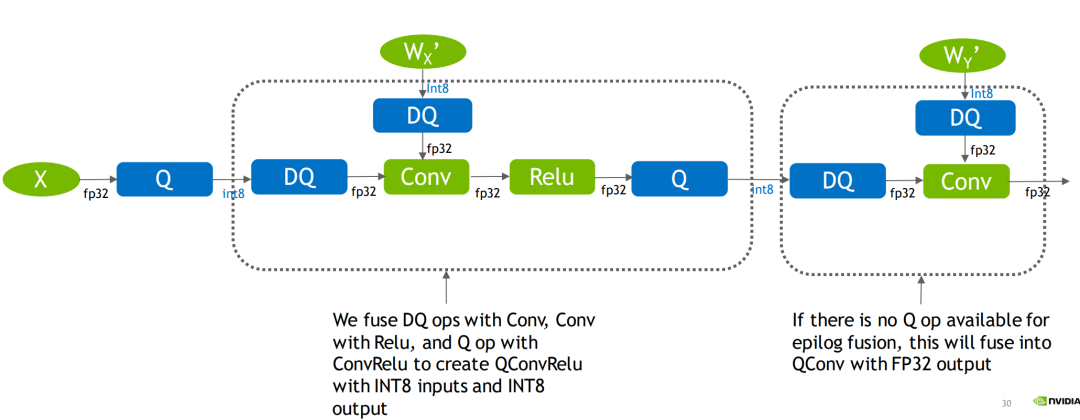 QDQ融合基本策略
QDQ融合基本策略融合后该算子就是实打实的INT8算子,我们也可以通过调整QDQ的位置来设置网络每一个op的精度(某些op必须高精度,因此QDQ的位置要放对):
 QDQ决定量化细节
QDQ决定量化细节也可以显式地插入QDQ告诉TensorRT哪些层是INT8,哪些层可以被fuse:
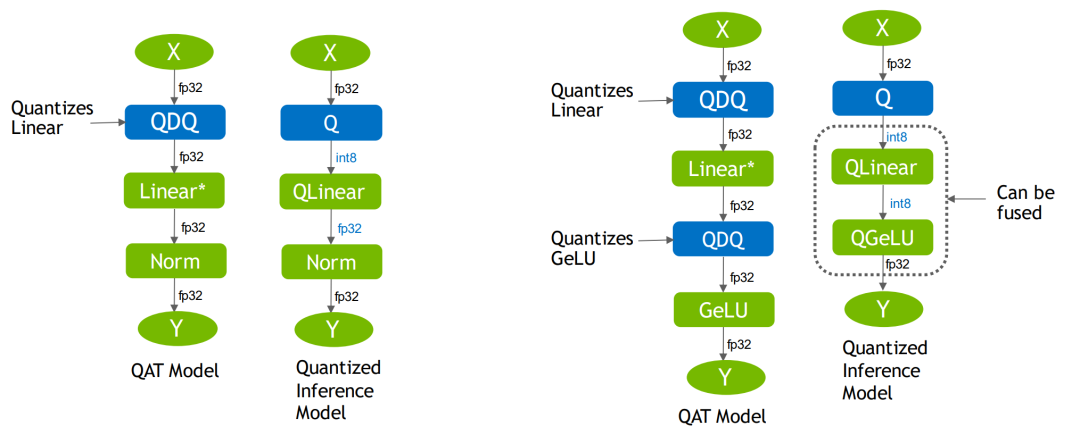 QAT模型和TensorRT优化后的模型
QAT模型和TensorRT优化后的模型经过一系列融合优化后,最终生成量化版的engine:
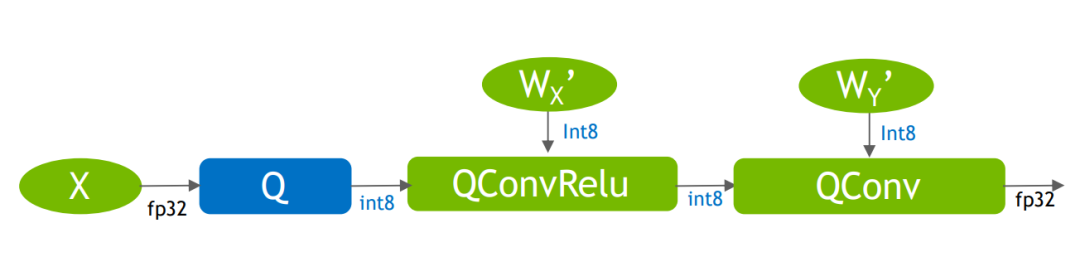 最终的量化后的网络
最终的量化后的网络总得来说,TensorRT加载QAT的ONNX模型并且优化的整理流程如下:
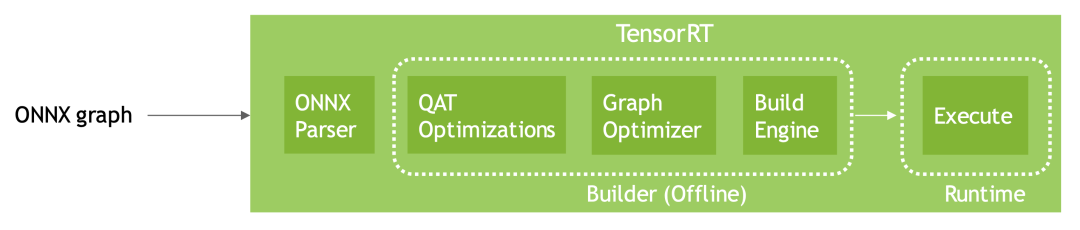 量化流程
量化流程因为TensorRT8可以直接加载通过QTA量化后且导出为ONNX的模型,官方也提供了Pytorch量化配套工具,可谓是一步到位。
TensorRT的量化性能是非常好的,可能有些模型或者op已经被其他库超越(比如openppl或者tvm),不过TensorRT胜在支持的比较广泛,用户很多,大部分模型都有前人踩过坑,经验相对较多些,而且支持dynamic shape,适用的场景也较多。
不过TensorRT也有缺点,就是自定义的INT8插件不是很好搞,很多坑要踩,也就是自己添加新的支持难度稍大一些。对于某些层不支持或者有bug的情况,除了在issue中催一下官方尽快更新之外,也没有其他办法了。
在官方文档的Layer specific restrictions这一节中有详细的说明,常见的卷积、反卷积、BN、矩阵乘法等等都是支持的,更多可以自己去查:
传送门:
https://docs.nvidia.com/deeplearning/tensorrt/developer-guide/index.html
TensorRT显式量化主要参与的op是IQuantizeLayer和IDequantizeLayer这俩,即Q和DQ。在构建TensorRT-network的时候就可以通过这两个op来控制网络的量化细节。
这个层就是将浮点型的Tensor转换为,通过add_quantize这个API添加:
执行output = clamp(round(input / scale) + zeroPt)
Clamping is in the range [-128, 127]
API参考:https://docs.nvidia.com/deeplearning/tensorrt/api/python_api/infer/Graph/Layers.html#iquantizelayer
与IQuantizeLayer作用相反,通过add_dequantize添加。
执行𝑜𝑢𝑡𝑝𝑢𝑡=(𝑖𝑛𝑝𝑢𝑡−𝑧𝑒𝑟𝑜𝑃𝑡)∗𝑠𝑐𝑎𝑙𝑒
输入INT8输出FP32
API:https://docs.nvidia.com/deeplearning/tensorrt/api/python_api/infer/Graph/Layers.html#tensorrt.IDequantizeLayer
上述两个TensorRT的layer与ONNX中的QuantizeLinear和Dequantizelinear对应,在使用ONNX2trt工具的时候,ONNX中的这两个op会被解析成IQuantizeLayer和IDequantizeLayer:
 ONNX中的QDQ
ONNX中的QDQ当TensorRT检测到模型中有QDQ算子的时候,就会触发显式量化。以下quantize算子简称Q,dequantize算子简称DQ。
Q算子一般输入是FP32类型的,然后会有一个Q的scale,相反DQ也会有一个scale,这个scale参数就是per-tensor或者per-channel的尺度信息,不清楚的可以复习下上一篇内容。
如下图:
 带QDQ的ONNX模型
带QDQ的ONNX模型好了,那么TensorRT载入带有QDQ算子的模型怎么处理呢?首先当然是要保证其模型的正确性,也就是计算顺序不能变。当然s*a+b*s -> (a+b)*s这种是可以的,对结果不会有很大的影响(小的影响是有的,对于浮点运算,这种变化也会造成结果一点点的不一样,不信你试试)。
之前也提到过,有QDQ算子的算是显式量化,既然都是显式了那就是很明显啊。Q算子负责FP32->INT8,而DQ算子负责INT8->FP32,被QDQ包起来的算子理所应当就是量化算子(或者说准备被量化、可以被量化的算子,这句话有待揣摩...)。最终QDQ算子的scale要被吸收进量化算子中:
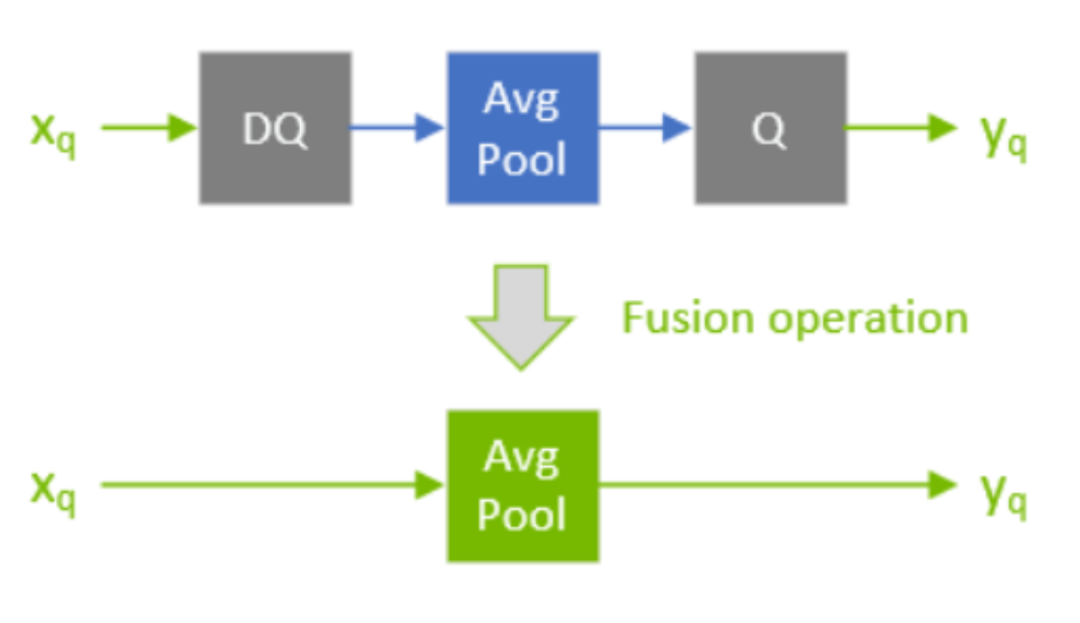 官方文档-QDQ合并
官方文档-QDQ合并上图绿色AvgPool就是量化版本的算子了。
我们的QDQ-ONNX网络在输入到TensorRT中的时候,TensorRT的算法会propagate整个网络,根据一些规则适当移动Q/DQ算子的位置,(毕竟我们的网络往往比较复杂,并不是很多结构都刚好QDQ-pair了,需要尽可以拼凑出QDQ结构,使整个网络尽可能多的op变为量化算子)然后再执行QDQ融合策略。
这些规则简单说就是:
尽可能将DQ算子推迟,推迟反量化操作
尽可能将Q算子提前,提前量化操作
光说可能不大明白,看个图:
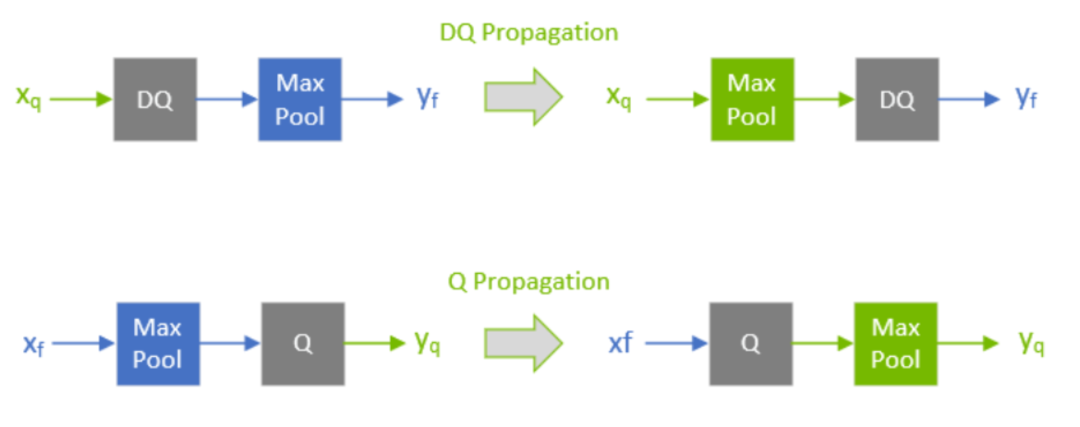 官方文档-QDQ-propagation
官方文档-QDQ-propagation第一个将DQ挪到MaxPool后面,这样MaxPool就从FP32->INT8了,第二个将Q从MaxPool后面移到前面,这样MaxPool也就从FP32->INT8了。这样搞完有助于下一步的优化。
至于为什么可以把Q、DQ在MaxPool周围移动呢?这里有一个简单的证明:
 MaxPool
MaxPool有一点注意,需要区分quantizable-layers and commuting-layers,大概意思就是quantizable-layers是会实际计算可量化算子,比如Conv、BN啥的;而commuting-layers中不涉及到计算,仅仅是根据某些规则将输入来的Tensor过滤一部分再输出出来,比如上述的maxpool。这种操作的过滤规则和量化操作可以互动。
为什么移动QDQ呢,毕竟QDQ模型是我们产出的,QDQ算子也是我们亲手插的,这个插得位置其实也是有讲究的。毕竟这个QDQ模型是要经过TensorRT进行解析优化(或者其他推理框架进行解析),而解析算法也是人写的,难免会有一些case没有考虑到,而这些badcase或者hardcase往往与我们QDQ插得位置有关。
因此TensorRT针对他们优化器的优化细节,提出了一些建议,这些建议或者说规则吧,感觉是比较通用的,其他类似的量化框架中也会遇到同样的思想。
下面详细展开说说。
我们常见的操作,比如Convolution, Transposed Convolution and GEMM,这些都是带参数的。所以在量化的时候最好把这些op的输入和权重都量化了,这样可以达到速度最大化。
下图中TensorRT会根据QDQ的分布进行不同的优化,比如左边的conv融合后输入INT8但输出为FP32,而右边的输入输出皆为INT8(两者的区别只是因为右面的conv后头跟了一个Q)。
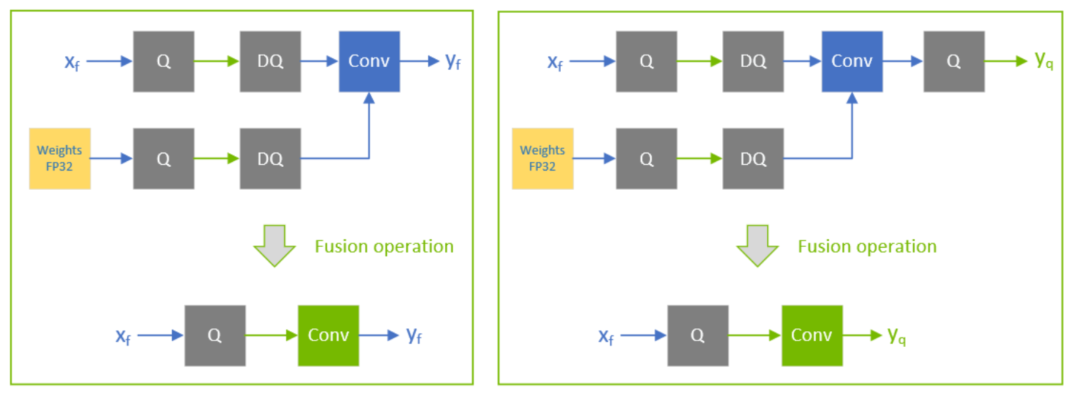 不同情况下conv融合策略
不同情况下conv融合策略通常情况下,我们常见的weighted-operations,一般都是卷积、矩阵相乘、反卷积等等,而这些op后头一般都会跟着BN层或者激活层。BN层的话,比较特殊,不论是在PTQ场景还是QAT场景都比较重要(这里咱不展开)。而激活层的话,除了常见的RELU,其他的一些激活层比如SILU,因为不好量化,所以就保持浮点型(比如sigmoid在TensorRT中仅支持FP16量化)。
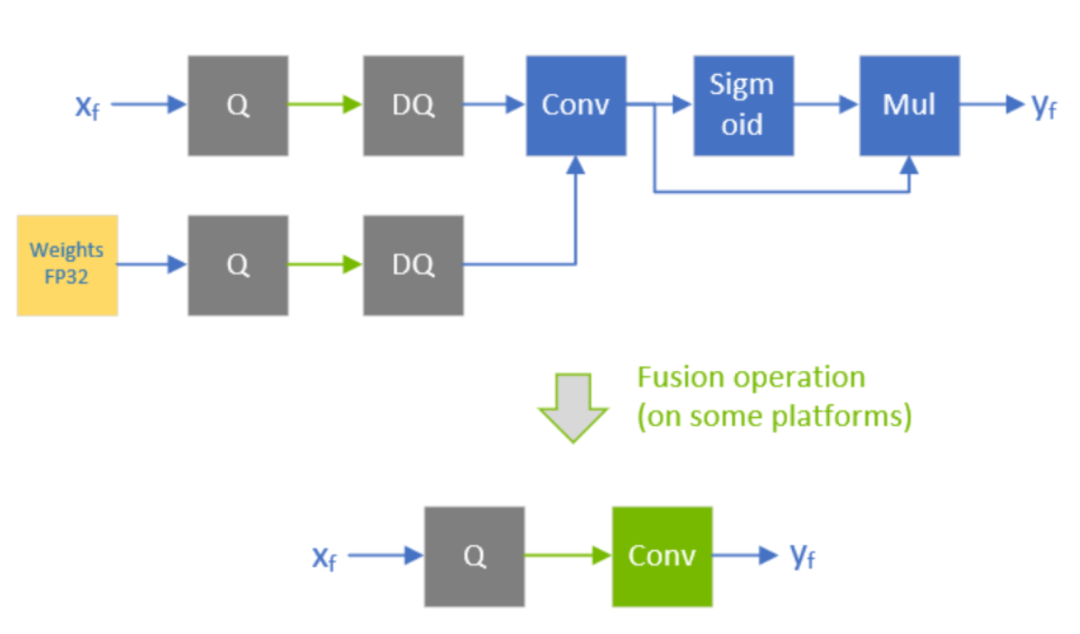 conv与FP32激活函数的合并
conv与FP32激活函数的合并TensorRT在优化网络的过程中会顺手将CONV+BN+RELU合并,所以我们在导出ONNX模型时候没必要自己融合,特别是在QAT的时候可以保留BN层。
不过你融合了也没关系。
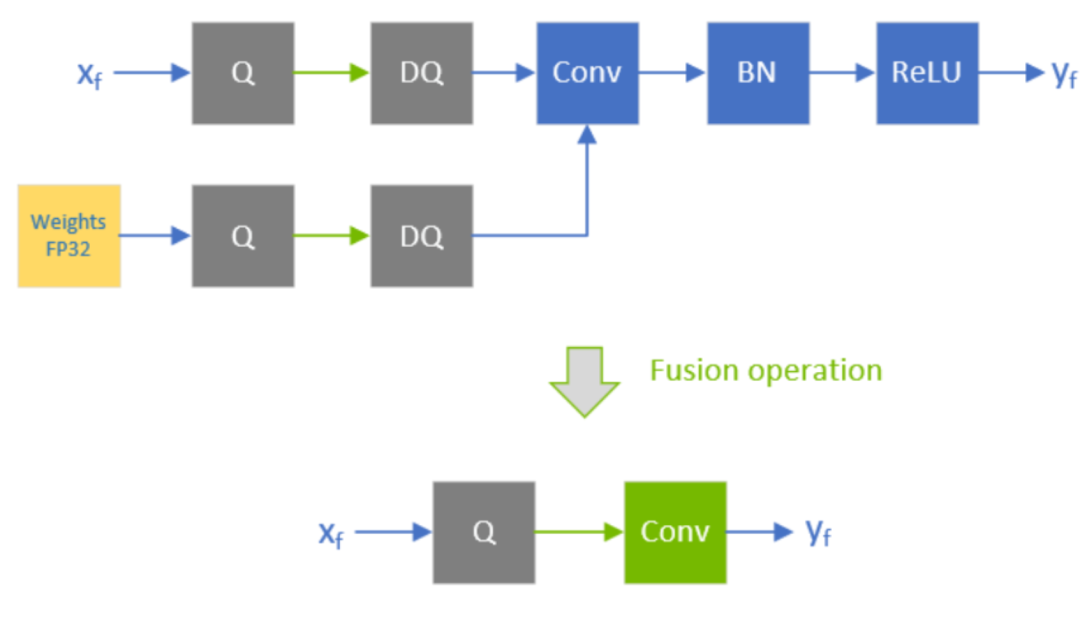 CONV+BN+RELU合并
CONV+BN+RELU合并TensorRT的融合策略也会受到模型中OP的精度影响。
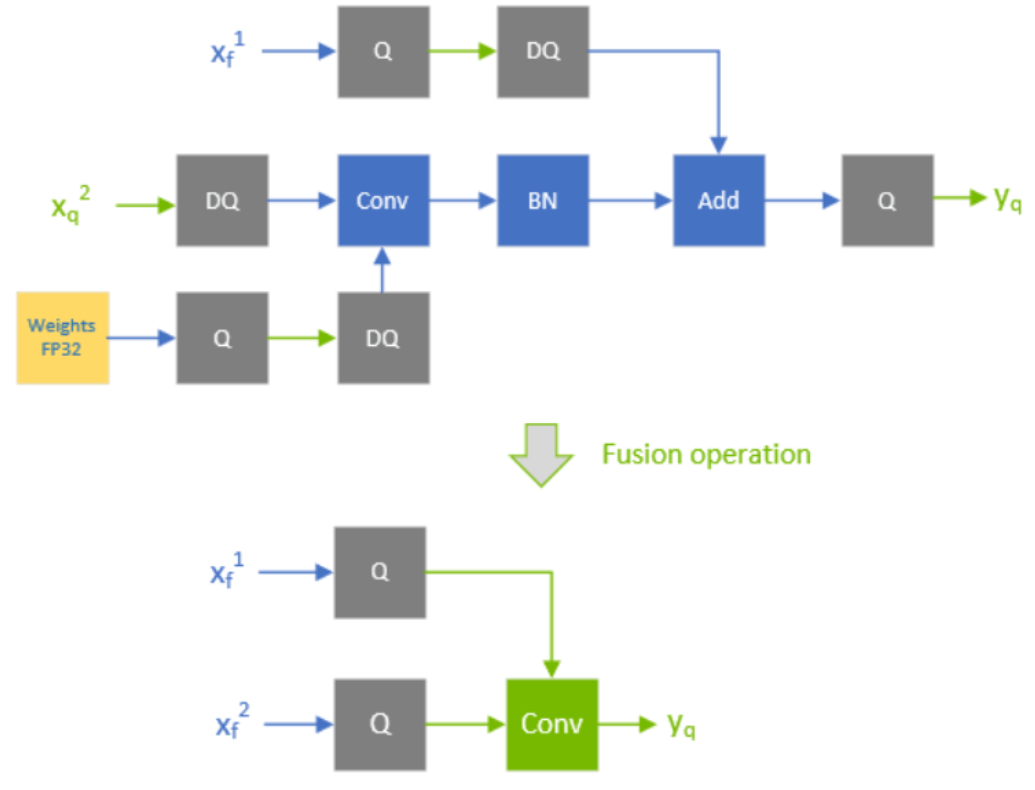 适当QDQ条件下conv+bn+add的融合
适当QDQ条件下conv+bn+add的融合上图中,当 被QDQ显式指定为INT8类型,另一个分支的fused-conv的输出也是INT8,那么跟在后头的Q-layer也会被融合到conv里头。需要注意, 在fusion operation之后变为了 。
因为TensorRT可以对weighted layers之后的element-wise addition执行融合(这种一般都是有skip connections,比如Resnet和EfficientNet)。但是这个add层输出的精度是由第一个输入(这里的第一个如何判断值得商榷)的精度决定。
比如下图的add输入是 ,所以融合后的conv输出也必须是FP32(这里理解为融合后的conv输出是add的第二个输入,第二输入类型必须与第一个一致),这样输入和输出就都是FP32,所以最后一个Q-layer无法(像上一种情况一样)被融合了。
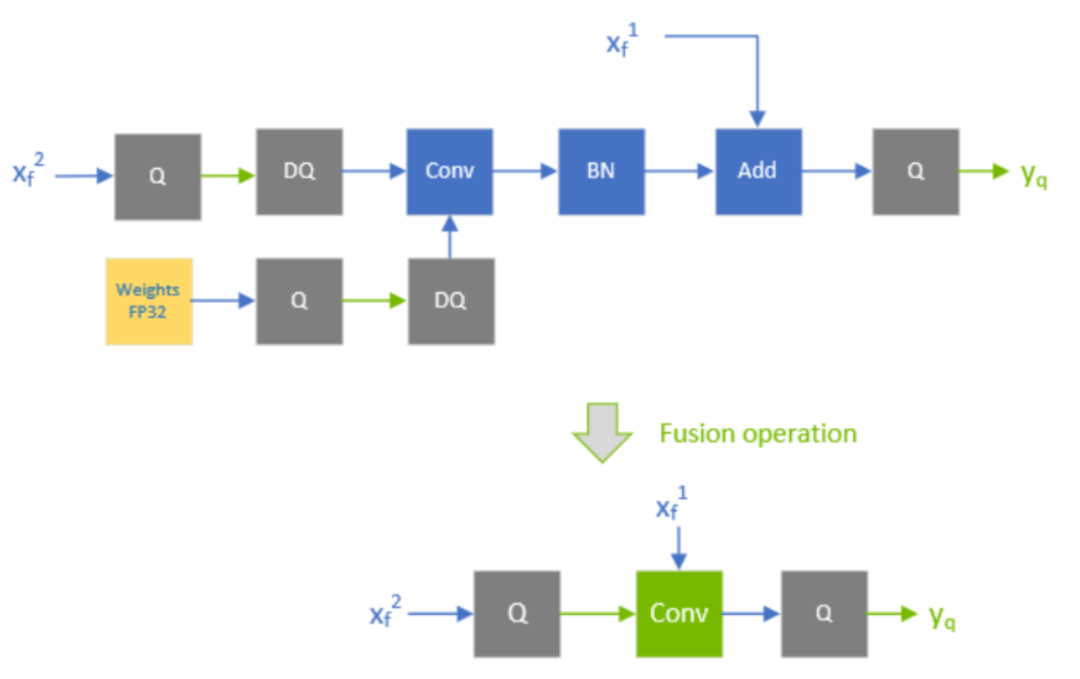 conv+bn+add融合
conv+bn+add融合像add这类的操作,最好是输入输出都是INT8,这样性能能达到最大化。
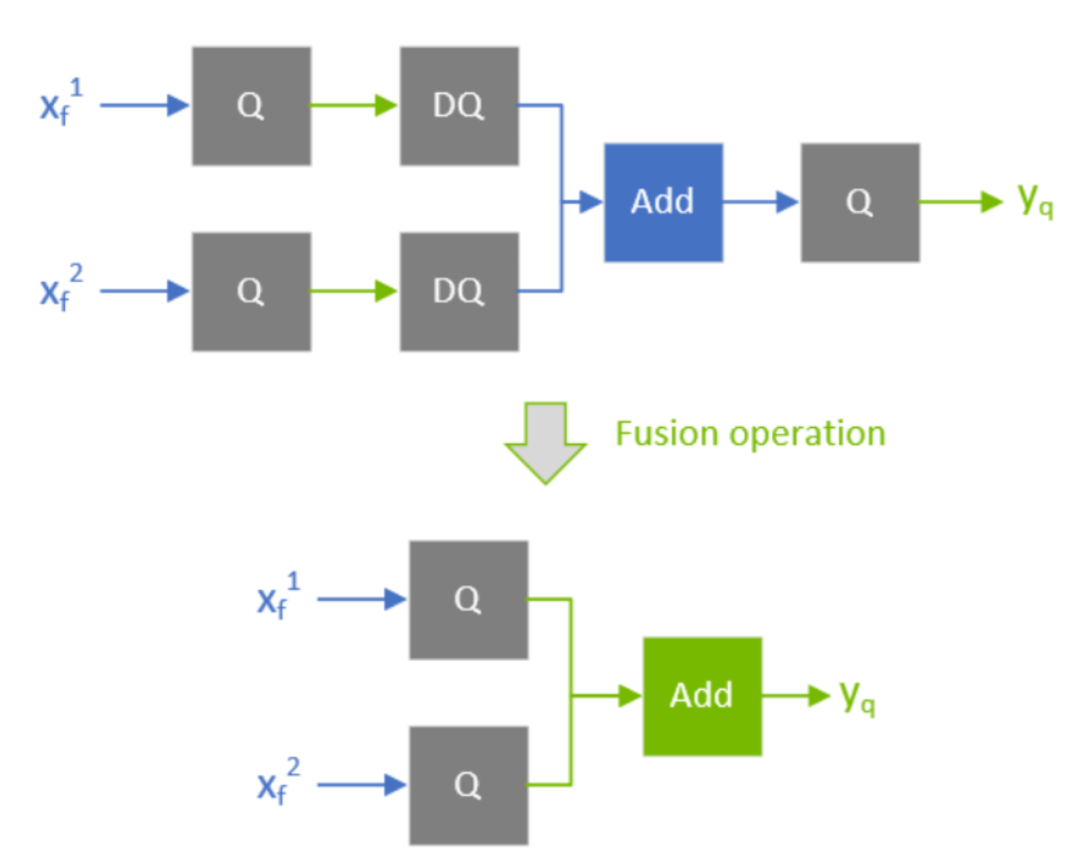 add和QDQ的优化
add和QDQ的优化上图fusion之后,Add操作的输入和输出类型都是INT8。
绝大部分情况,融合QDQ可以带来性能提升,不过有些情况就不行了,毕竟这个优化过程是编好的程序,badcase或者hardcase肯定是有的。
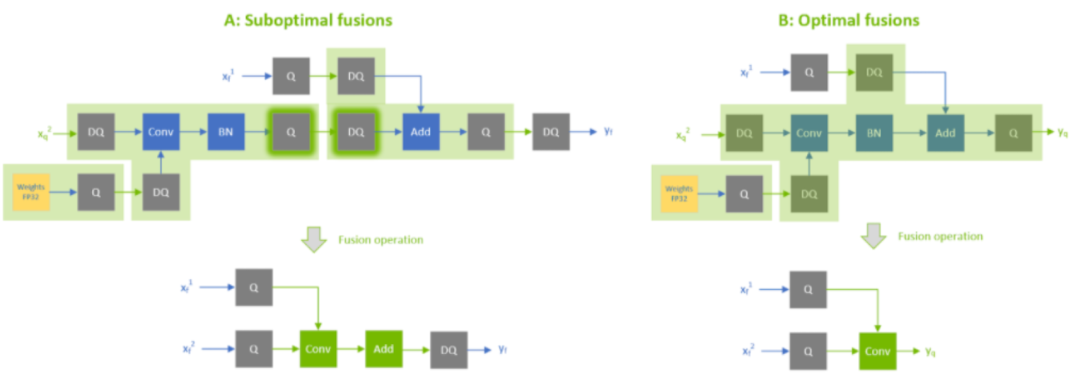 次优融合和最优综合
次优融合和最优综合另外一些情况,因为有一些QDQ的优化需要比较其中两个或者多个QDQ算子的scale重新计算scale(比如常见的add或者concat,我们需要对多个输入的scale进行requantize,这里暂时不细说)。如果这个trt模型是支持refitted(简单来说就是支持修改模型参数的trt模型),那么我们也是可以修改这些QDQ的scale值的,但修改之后之前重新计算的scale可能就不适用了,这时候该过程就会报错。
比如下图,TensorRT对整个网络进行遍历的时候会比较concat中两个Q的scale是否一致,如果一致的话就可以将concat之后的两个Q放到前面来:
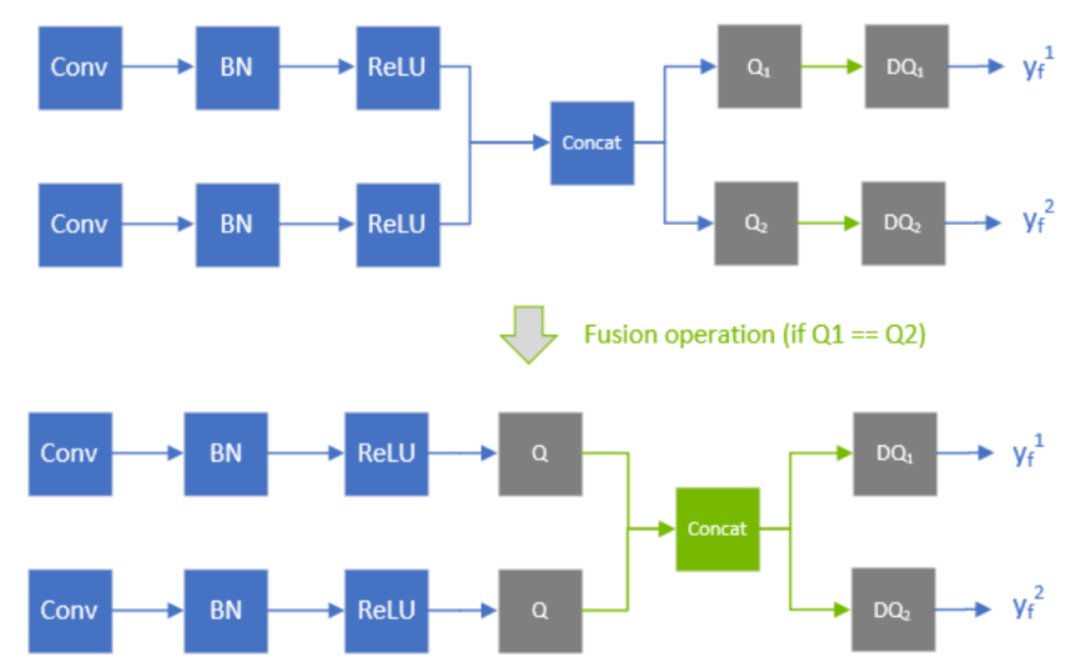 concat融合条件
concat融合条件到这里关于QDQ的说明就结束了,通过上述例子,不难认为下面红色圈圈内的OP精度都可以为INT8。
 显式指定量化op
显式指定量化op因为QDQ是显式量化,所以QDQ的放置位置很重要,有几点规则:
Recommend QDQ ops insertion at Inputs of quantizable ops
Matches QLinear/QConv semantics i.e. low precision input, high precision output.
No complexity in deciding whether to quantize output or not. Just Don't.
Let the ops decide what precision input they want.
这里就不转述了,原文看起来更准确些,这些内容之后可能也会更新。
Inserting QDQ ops at inputs (recommended)
Explicit quantization. No implicit rule eg. "Quantize operator input if output is quantized”.
No special logic for Conv-BN or Conv-ReLU
Just insert QDQ in front of quantizable ops. Leave the rest to the back end (TensorRT).
Makes life easy for frameworks quantization tools
Makes life easy for back end optimizers (TensorRT)
Inserting QDQ ops at outputs (not recommended, but supported)
Some frameworks quantization tools have this behavior by default.
Sub-optimal performance when network is "partial quantization" i.e. not all ops are quantized.
Optimal performance when network is "fully quantized" i.e. all ops in network are quantized.
再详细点,我们举个实际的例子。
接下来我们过一下TensorRT对于导出带有QQQ节点的ONNX模型,是如何一步一步转化为engine的。
这里通过分析TensorRT的官方转换工具trtexec执行的产生verbose信息来描述trt的量化过程,经常用trt的伙伴应该也比较熟悉。verbose信息可以通过指定--verbose参数开启,verbose信息包含TensorRT在执行转换中的一些信息:
解析onnx模型的过程
优化onnx模型op的过程
onnx中op转换为engine中op的过程
优化engine中op的过程
因为这里使用的ONNX已经拥有QDQ信息,即不需要Calibrator了,TensorRT会出现以下信息:
[08/25/2021-17:30:06] [W] [TRT] Calibrator won't be used in explicit precision mode. Use quantization aware training to generate network with Quantize/Dequantize nodes.
接下来开始优化。
首先优化一些无用的node(置空的等啥的op),正常模型(正常导出的没有bug)一般没有这种问题,所以优化前后模型总层数一致。
[08/25/2021-17:30:06] [V] [TRT] Applying generic optimizations to the graph for inference.
[08/25/2021-17:30:06] [V] [TRT] Original: 863 layers
[08/25/2021-17:30:06] [V] [TRT] After dead-layer removal: 863 layers
[08/25/2021-17:30:06] [V] [TRT] Removing (Unnamed Layer* 1) [Constant]
...
[08/25/2021-17:30:06] [V] [TRT] Removing (Unnamed Layer* 853) [Constant]
[08/25/2021-17:30:06] [V] [TRT] Removing (Unnamed Layer* 852) [Constant]
[08/25/2021-17:30:06] [V] [TRT] After Myelin optimization: 415 layers
[08/25/2021-17:30:06] [V] [TRT] After scale fusion: 415 layers
常量信息即各种模型中的参数,比如BN层中一些参数:
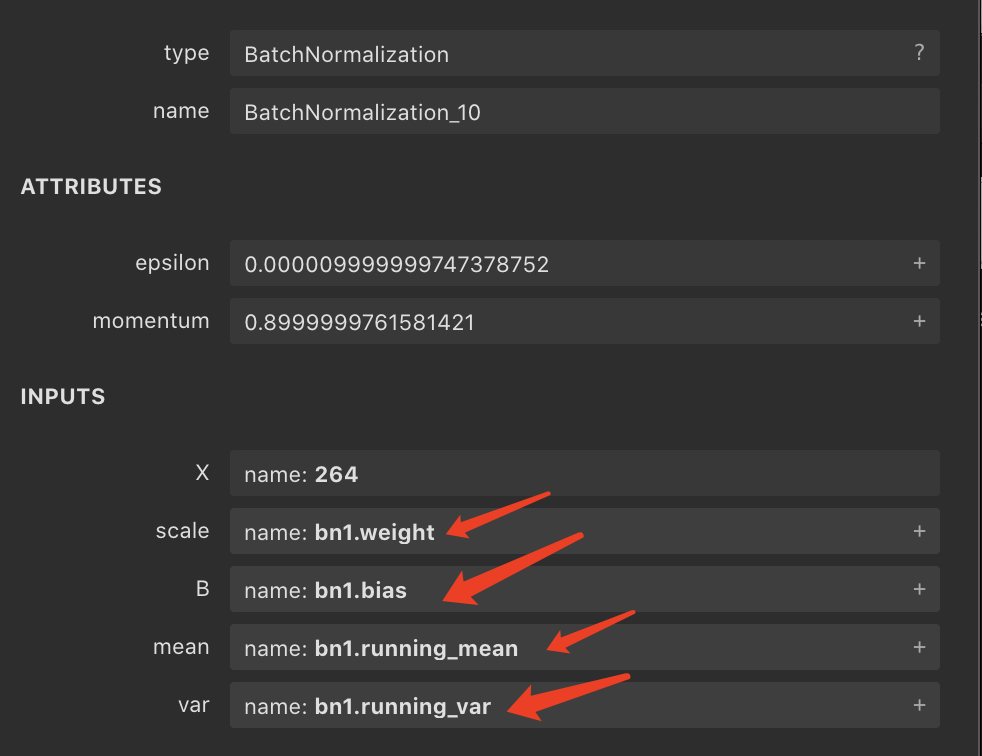 模型中的常量op
模型中的常量op或者QDQ中的scale和zero_point信息,这些信息的类型一般是Constant或者initializers。
 y_scale就是1/s
y_scale就是1/s
[08/25/2021-17:30:06] [V] [TRT] QDQ graph optimizer - constant folding of Q/DQ initializers
[08/25/2021-17:30:06] [V] [TRT] QDQ graph optimizer forward pass - DQ motions and fusions
很常见的合并。
[08/25/2021-17:30:06] [V] [TRT] EltReluFusion: Fusing Add_42 with Relu_43
[08/25/2021-17:30:06] [V] [TRT] EltReluFusion: Fusing Add_73 with Relu_74
[08/25/2021-17:30:06] [V] [TRT] EltReluFusion: Fusing Add_104 with Relu_105
[08/25/2021-17:30:06] [V] [TRT] EltReluFusion: Fusing Add_146 with Relu_147
[08/25/2021-17:30:06] [V] [TRT] EltReluFusion: Fusing Add_177 with Relu_178
[08/25/2021-17:30:06] [V] [TRT] EltReluFusion: Fusing Add_208 with Relu_209
...
[08/25/2021-17:30:06] [V] [TRT] EltReluFusion: Fusing Add_540 with Relu_541
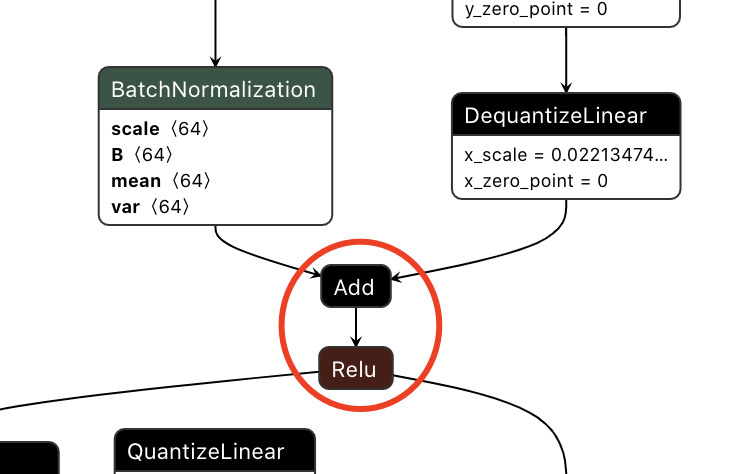 合并Add和relu
合并Add和reluFP32->INT8。转换模型权重的精度。
[08/25/2021-17:30:06] [V] [TRT] ConstWeightsQuantizeFusion: Fusing conv1.weight with QuantizeLinear_7_quantize_scale_node
[08/25/2021-17:30:06] [V] [TRT] ConstWeightsQuantizeFusion: Fusing layer1.0.conv1.weight with QuantizeLinear_20_quantize_scale_node
[08/25/2021-17:30:06] [V] [TRT] ConstWeightsQuantizeFusion: Fusing layer1.0.conv2.weight with QuantizeLinear_32_quantize_scale_node
[08/25/2021-17:30:06] [V] [TRT] ConstWeightsQuantizeFusion: Fusing layer1.1.conv1.weight with QuantizeLinear_51_quantize_scale_node
[08/25/2021-17:30:06] [V] [TRT] ConstWeightsQuantizeFusion: Fusing layer1.1.conv2.weight with QuantizeLinear_63_quantize_scale_node
[08/25/2021-17:30:06] [V] [TRT] ConstWeightsQuantizeFusion: Fusing layer1.2.conv1.weight with QuantizeLinear_82_quantize_scale_node
[08/25/2021-17:30:06] [V] [TRT] ConstWeightsQuantizeFusion: Fusing layer1.2.conv2.weight with QuantizeLinear_94_quantize_scale_node
[08/25/2021-17:30:06] [V] [TRT] ConstWeightsQuantizeFusion: Fusing layer2.0.conv1.weight with QuantizeLinear_113_quantize_scale_node
[08/25/2021-17:30:06] [V] [TRT] ConstWeightsQuantizeFusion: Fusing layer2.0.conv2.weight with QuantizeLinear_125_quantize_scale_node
[08/25/2021-17:30:06] [V] [TRT] ConstWeightsQuantizeFusion: Fusing layer2.0.downsample.0.weight with QuantizeLinear_136_quantize_scale_node
[08/25/2021-17:30:06] [V] [TRT] ConstWeightsQuantizeFusion: Fusing layer2.1.conv1.weight with QuantizeLinear_155_quantize_scale_node
[08/25/2021-17:30:06] [V] [TRT] ConstWeightsQuantizeFusion: Fusing layer2.1.conv2.weight with QuantizeLinear_167_quantize_scale_node
[08/25/2021-17:30:06] [V] [TRT] ConstWeightsQuantizeFusion: Fusing layer2.2.conv1.weight with QuantizeLinear_186_quantize_scale_node
[08/25/2021-17:30:06] [V] [TRT] ConstWeightsQuantizeFusion: Fusing layer2.2.conv2.weight with QuantizeLinear_198_quantize_scale_node
[08/25/2021-17:30:06] [V] [TRT] ConstWeightsQuantizeFusion: Fusing layer2.3.conv1.weight with QuantizeLinear_217_quantize_scale_node
[08/25/2021-17:30:06] [V] [TRT] ConstWeightsQuantizeFusion: Fusing layer2.3.conv2.weight with QuantizeLinear_229_quantize_scale_node
[08/25/2021-17:30:06] [V] [TRT] ConstWeightsQuantizeFusion: Fusing layer3.0.conv1.weight with QuantizeLinear_248_quantize_scale_node
[08/25/2021-17:30:06] [V] [TRT] ConstWeightsQuantizeFusion: Fusing layer3.0.conv2.weight with QuantizeLinear_260_quantize_scale_node
[08/25/2021-17:30:06] [V] [TRT] ConstWeightsQuantizeFusion: Fusing layer3.0.downsample.0.weight with QuantizeLinear_271_quantize_scale_node
[08/25/2021-17:30:06] [V] [TRT] ConstWeightsQuantizeFusion: Fusing layer3.1.conv1.weight with QuantizeLinear_290_quantize_scale_node
[08/25/2021-17:30:06] [V] [TRT] ConstWeightsQuantizeFusion: Fusing layer3.1.conv2.weight with QuantizeLinear_302_quantize_scale_node
[08/25/2021-17:30:06] [V] [TRT] ConstWeightsQuantizeFusion: Fusing layer3.2.conv1.weight with QuantizeLinear_321_quantize_scale_node
[08/25/2021-17:30:06] [V] [TRT] ConstWeightsQuantizeFusion: Fusing layer3.2.conv2.weight with QuantizeLinear_333_quantize_scale_node
[08/25/2021-17:30:06] [V] [TRT] ConstWeightsQuantizeFusion: Fusing layer3.3.conv1.weight with QuantizeLinear_352_quantize_scale_node
[08/25/2021-17:30:06] [V] [TRT] ConstWeightsQuantizeFusion: Fusing layer3.3.conv2.weight with QuantizeLinear_364_quantize_scale_node
[08/25/2021-17:30:06] [V] [TRT] ConstWeightsQuantizeFusion: Fusing layer3.4.conv1.weight with QuantizeLinear_383_quantize_scale_node
[08/25/2021-17:30:06] [V] [TRT] ConstWeightsQuantizeFusion: Fusing layer3.4.conv2.weight with QuantizeLinear_395_quantize_scale_node
[08/25/2021-17:30:06] [V] [TRT] ConstWeightsQuantizeFusion: Fusing layer3.5.conv1.weight with QuantizeLinear_414_quantize_scale_node
[08/25/2021-17:30:06] [V] [TRT] ConstWeightsQuantizeFusion: Fusing layer3.5.conv2.weight with QuantizeLinear_426_quantize_scale_node
[08/25/2021-17:30:06] [V] [TRT] ConstWeightsQuantizeFusion: Fusing layer4.0.conv1.weight with QuantizeLinear_445_quantize_scale_node
[08/25/2021-17:30:06] [V] [TRT] ConstWeightsQuantizeFusion: Fusing layer4.0.conv2.weight with QuantizeLinear_457_quantize_scale_node
[08/25/2021-17:30:06] [V] [TRT] ConstWeightsQuantizeFusion: Fusing layer4.0.downsample.0.weight with QuantizeLinear_468_quantize_scale_node
[08/25/2021-17:30:06] [V] [TRT] ConstWeightsQuantizeFusion: Fusing layer4.1.conv1.weight with QuantizeLinear_487_quantize_scale_node
[08/25/2021-17:30:06] [V] [TRT] ConstWeightsQuantizeFusion: Fusing layer4.1.conv2.weight with QuantizeLinear_499_quantize_scale_node
[08/25/2021-17:30:06] [V] [TRT] ConstWeightsQuantizeFusion: Fusing layer4.2.conv1.weight with QuantizeLinear_518_quantize_scale_node
[08/25/2021-17:30:06] [V] [TRT] ConstWeightsQuantizeFusion: Fusing layer4.2.conv2.weight with QuantizeLinear_530_quantize_scale_node
[08/25/2021-17:30:06] [V] [TRT] ConstWeightsQuantizeFusion: Fusing deconv_layers.0.weight with
...
常规合并没什么好说的。
[08/25/2021-17:30:06] [V] [TRT] ConvReluFusion: Fusing Conv_617 with Relu_618
[08/25/2021-17:30:06] [V] [TRT] ConvReluFusion: Fusing Conv_638 with Relu_639
[08/25/2021-17:30:06] [V] [TRT] ConvReluFusion: Fusing Conv_659 with Relu_660
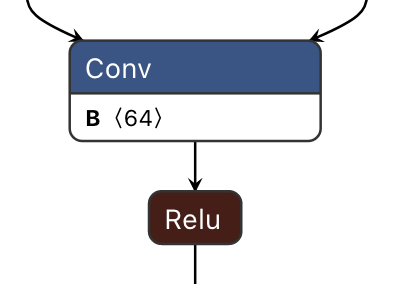 合并conv和relu
合并conv和relu为啥要移动,移动完Relu的精度就从FP32->INT8了,便于之后继续优化,符合上一节介绍的规则。
[08/25/2021-17:30:06] [V] [TRT] Swapping Relu_55 with QuantizeLinear_58_quantize_scale_node
[08/25/2021-17:30:06] [V] [TRT] Swapping Relu_86 with QuantizeLinear_89_quantize_scale_node
[08/25/2021-17:30:06] [V] [TRT] Swapping Relu_117 with QuantizeLinear_120_quantize_scale_node
[08/25/2021-17:30:06] [V] [TRT] Swapping Relu_159 with QuantizeLinear_162_quantize_scale_node
[08/25/2021-17:30:06] [V] [TRT] Swapping Relu_190 with QuantizeLinear_193_quantize_scale_node
[08/25/2021-17:30:06] [V] [TRT] Swapping Relu_221 with QuantizeLinear_224_quantize_scale_node
[08/25/2021-17:30:06] [V] [TRT] Swapping Relu_252 with QuantizeLinear_255_quantize_scale_node
[08/25/2021-17:30:06] [V] [TRT] Swapping Relu_294 with QuantizeLinear_297_quantize_scale_node
[08/25/2021-17:30:06] [V] [TRT] Swapping Relu_325 with QuantizeLinear_328_quantize_scale_node
[08/25/2021-17:30:06] [V] [TRT] Swapping Relu_356 with QuantizeLinear_359_quantize_scale_node
[08/25/2021-17:30:06] [V] [TRT] Swapping Relu_387 with QuantizeLinear_390_quantize_scale_node
[08/25/2021-17:30:06] [V] [TRT] Swapping Relu_418 with QuantizeLinear_421_quantize_scale_node
[08/25/2021-17:30:06] [V] [TRT] Swapping Relu_449 with QuantizeLinear_452_quantize_scale_node
[08/25/2021-17:30:06] [V] [TRT] Swapping Relu_491 with QuantizeLinear_494_quantize_scale_node
[08/25/2021-17:30:06] [V] [TRT] Swapping Relu_522 with QuantizeLinear_525_quantize_scale_node
[08/25/2021-17:30:06] [V] [TRT] Swapping Relu_563 with QuantizeLinear_566_quantize_scale_node
[08/25/2021-17:30:06] [V] [TRT] Swapping Relu_585 with QuantizeLinear_588_quantize_scale_node```
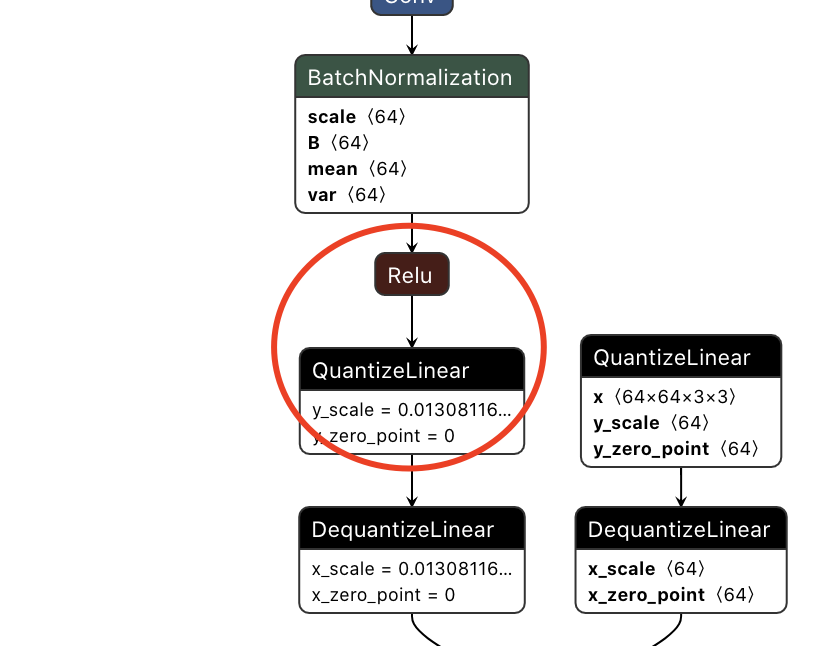 交换这两个节点
交换这两个节点...
[08/25/2021-17:30:06] [V] [TRT] Eliminating QuantizeLinear_38_quantize_scale_node which duplicates (Q) QuantizeLinear_15_quantize_scale_node
[08/25/2021-17:30:06] [V] [TRT] Removing QuantizeLinear_38_quantize_scale_node
[08/25/2021-17:30:06] [V] [TRT] Eliminating QuantizeLinear_69_quantize_scale_node which duplicates (Q) QuantizeLinear_46_quantize_scale_node
[08/25/2021-17:30:06] [V] [TRT] Removing QuantizeLinear_69_quantize_scale_node
...
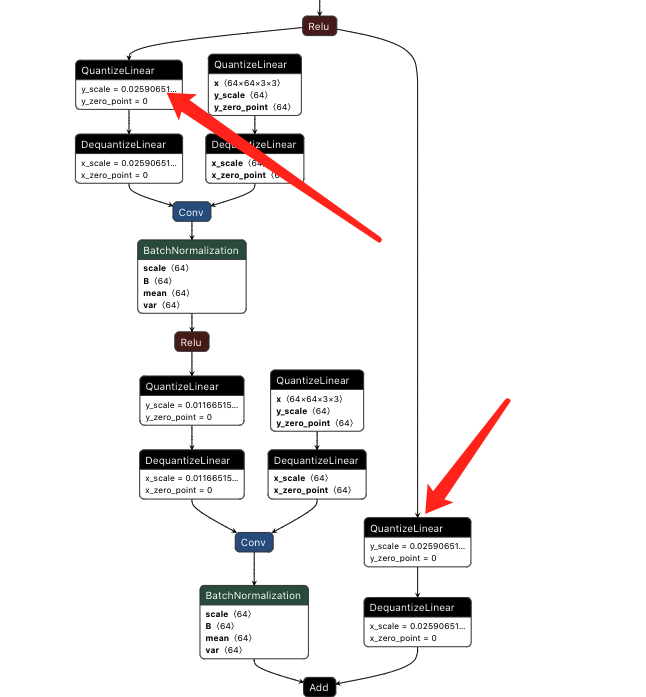
可以看到右面的Q其实是个左面的Q一样的,毕竟从同一个op出来的scale必须一致,因此这两个可以去掉一个(下图去掉了右面的) 。
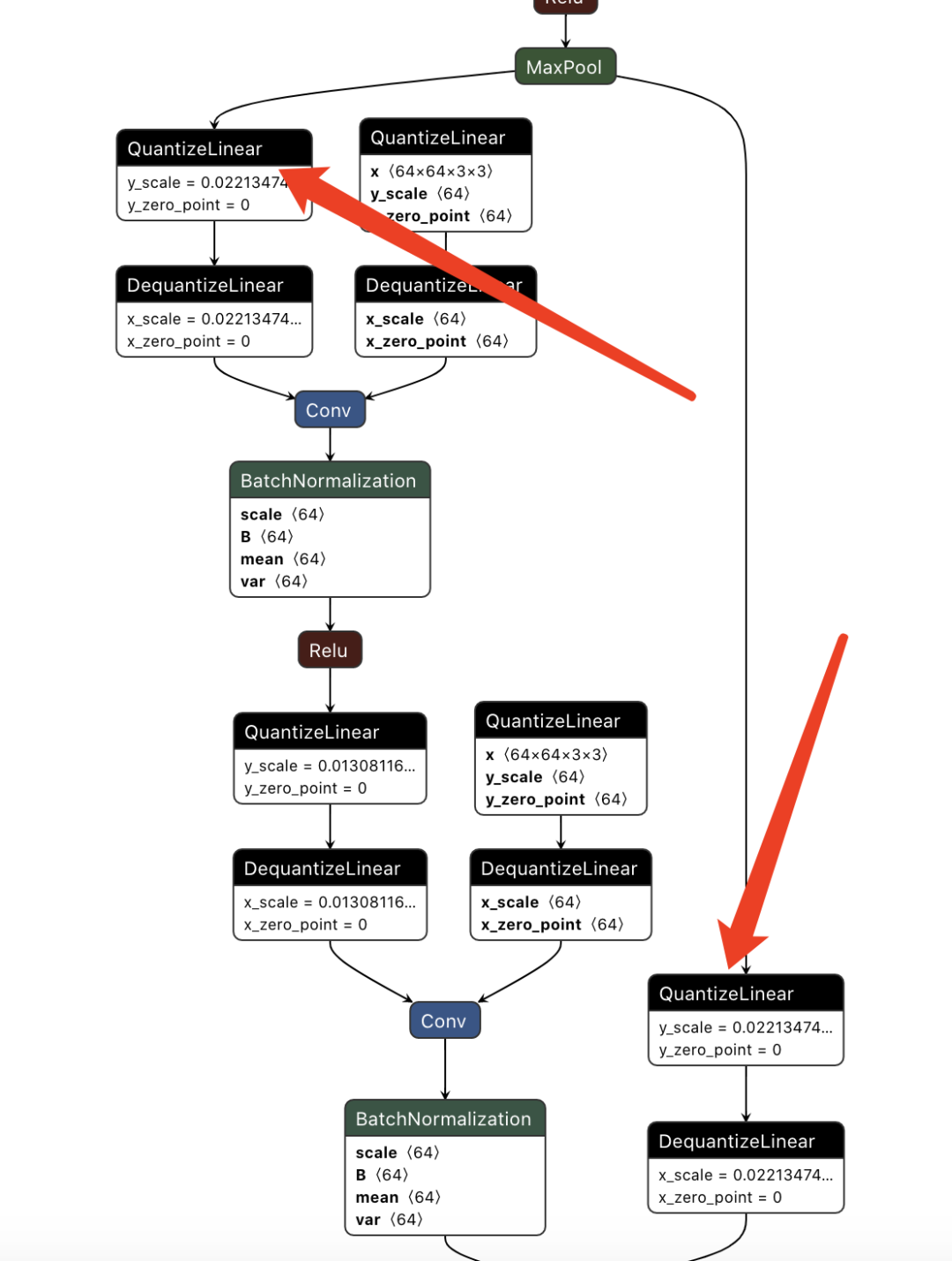 去掉一个相同scale的quan节点
去掉一个相同scale的quan节点这里将Q从maxpool的后面移动到了relu的前面,符合上节已经讲过的规则。
[08/25/2021-17:30:06] [V] [TRT] Swapping MaxPool_12 with QuantizeLinear_15_quantize_scale_node
[08/25/2021-17:30:06] [V] [TRT] Swapping Relu_607 with QuantizeLinear_610_quantize_scale_node
[08/25/2021-17:30:06] [V] [TRT] Swapping Relu_11 with QuantizeLinear_15_quantize_scale_node
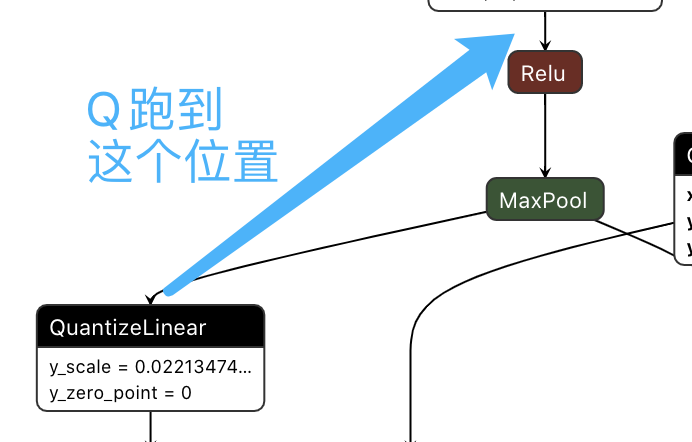 移动Q的位置
移动Q的位置[08/25/2021-17:30:06] [V] [TRT] QDQ graph optimizer quantization pass - Generate quantized ops
吸BN操作,没什么好说的。不清楚的可以看我之前的一篇:不看必进坑~不论是训练还是部署都会让你踩坑的Batch Normalization.
[08/25/2021-17:30:06] [V] [TRT] Removing BatchNormalization_10
[08/25/2021-17:30:06] [V] [TRT] Removing BatchNormalization_23
[08/25/2021-17:30:06] [V] [TRT] Removing BatchNormalization_35
[08/25/2021-17:30:06] [V] [TRT] Removing BatchNormalization_54
[08/25/2021-17:30:06] [V] [TRT] Removing BatchNormalization_66
[08/25/2021-17:30:06] [V] [TRT] Removing BatchNormalization_85
[08/25/2021-17:30:06] [V] [TRT] Removing BatchNormalization_97
[08/25/2021-17:30:06] [V] [TRT] Removing BatchNormalization_116
...
[08/25/2021-17:30:07] [V] [TRT] Swapping Add_42 + Relu_43 with QuantizeLinear_46_quantize_scale_node
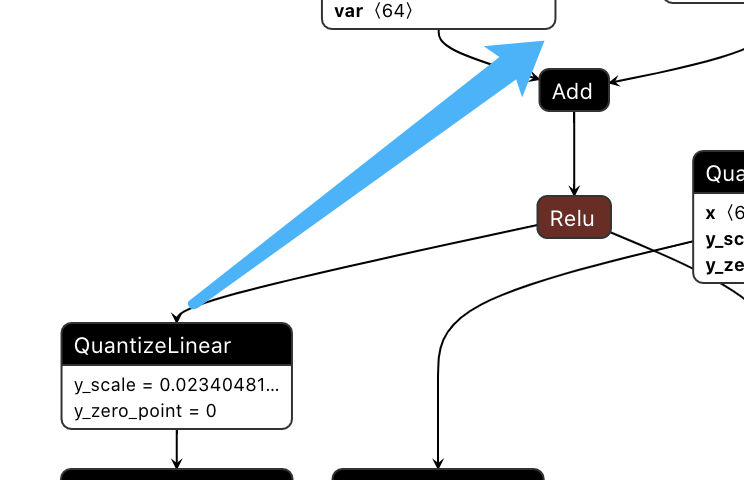 移动Q到合适位置
移动Q到合适位置同样将Q移动到Add_42 + Relu_43,使“量化操作尽可能提前”。
[08/25/2021-17:30:07] [V] [TRT] QuantizeDoubleInputNodes: fusing QuantizeLinear_46_quantize_scale_node into Conv_34
[08/25/2021-17:30:07] [V] [TRT] QuantizeDoubleInputNodes: fusing (DequantizeLinear_30_quantize_scale_node and DequantizeLinear_33_quantize_scale_node) into Conv_34
有两段。
[08/25/2021-17:30:07] [V] [TRT] Removing QuantizeLinear_46_quantize_scale_node
[08/25/2021-17:30:07] [V] [TRT] Removing DequantizeLinear_30_quantize_scale_node
[08/25/2021-17:30:07] [V] [TRT] Removing DequantizeLinear_33_quantize_scale_node
[08/25/2021-17:30:07] [V] [TRT] ConstWeightsFusion: Fusing layer1.0.conv2.weight + QuantizeLinear_32_quantize_scale_node with Conv_34
[08/25/2021-17:30:07] [V] [TRT] ConvEltwiseSumFusion: Fusing layer1.0.conv2.weight + QuantizeLinear_32_quantize_scale_node + Conv_34 with Add_42 + Relu_43
[08/25/2021-17:30:07] [V] [TRT] Removing DequantizeLinear_41_quantize_scale_node
...
[08/25/2021-17:30:07] [V] [TRT] QuantizeDoubleInputNodes: fusing QuantizeLinear_27_quantize_scale_node into Conv_22
[08/25/2021-17:30:07] [V] [TRT] QuantizeDoubleInputNodes: fusing (DequantizeLinear_18_quantize_scale_node and DequantizeLinear_21_quantize_scale_node) into Conv_22
[08/25/2021-17:30:07] [V] [TRT] Removing QuantizeLinear_27_quantize_scale_node
...
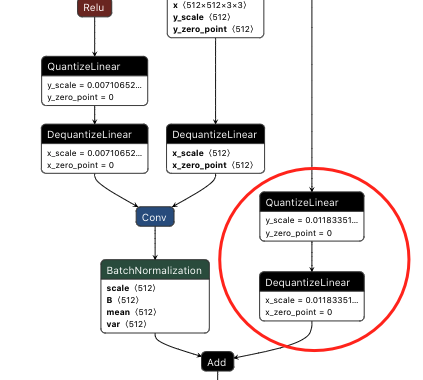
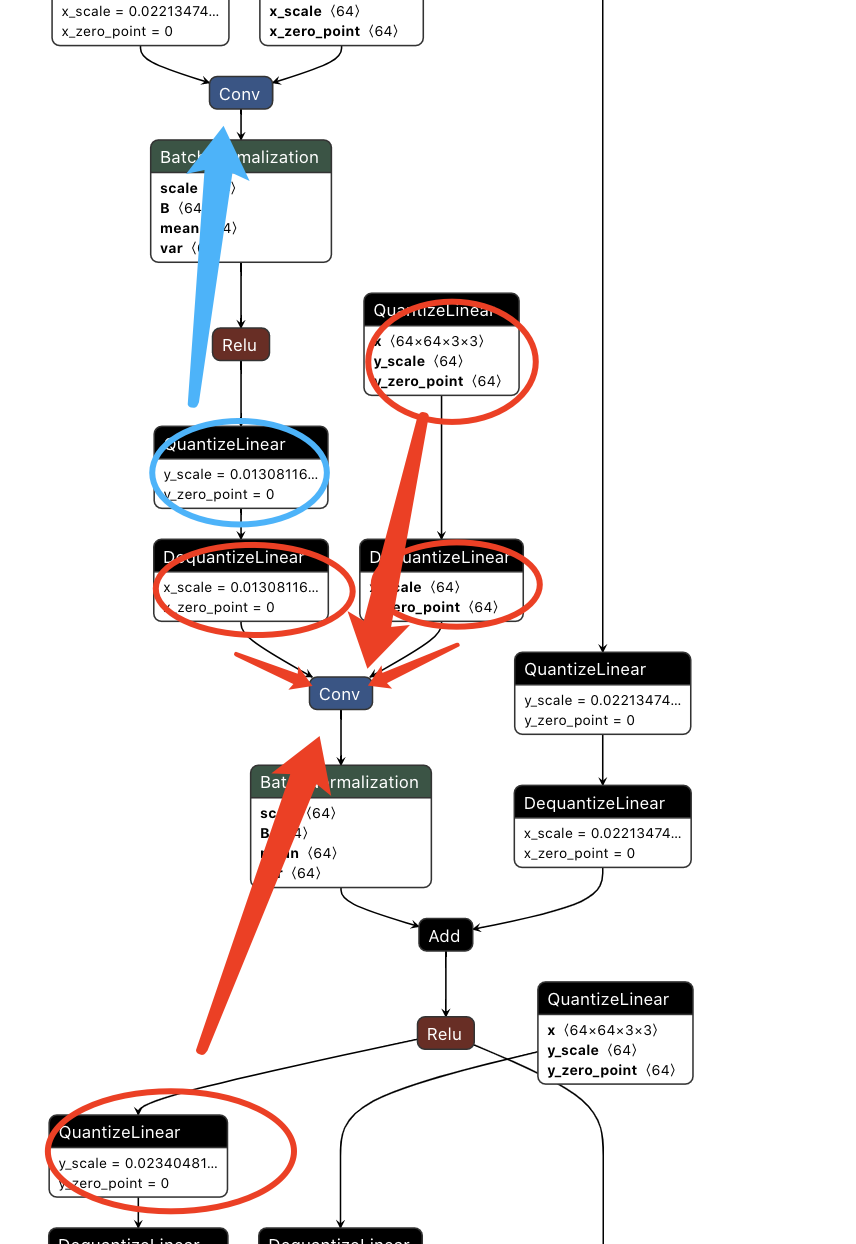 conv吸收融合
conv吸收融合如上图,红色圈圈里头的所有op融入到Conv_34中,蓝色的Q被吸入上一个conv中。
差不多一些与上一个相同的操作。
[08/25/2021-17:30:07] [V] [TRT] ConstWeightsFusion: Fusing conv1.weight + QuantizeLinear_7_quantize_scale_node with Conv_9
[08/25/2021-17:30:07] [V] [TRT] ConstWeightsFusion: Fusing layer1.0.conv1.weight + QuantizeLinear_20_quantize_scale_node with Conv_22
[08/25/2021-17:30:07] [V] [TRT] ConstWeightsFusion: Fusing layer1.1.conv1.weight + QuantizeLinear_51_quantize_scale_node with Conv_53
[08/25/2021-17:30:07] [V] [TRT] ConstWeightsFusion: Fusing layer1.2.conv1.weight + QuantizeLinear_82_quantize_scale_node with Conv_84
[08/25/2021-17:30:07] [V] [TRT] ConstWeightsFusion: Fusing layer2.0.conv1.weight + QuantizeLinear_113_quantize_scale_node with Conv_115
[08/25/2021-17:30:07] [V] [TRT] ConstWeightsFusion: Fusing layer2.0.downsample.0.weight + QuantizeLinear_136_quantize_scale_node with Conv_138
[08/25/2021-17:30:07] [V] [TRT] ConstWeightsFusion: Fusing layer2.1.conv1.weight + QuantizeLinear_155_quantize_scale_node with Conv_157
[08/25/2021-17:30:07] [V] [TRT] ConstWeightsFusion: Fusing layer2.2.conv1.weight + QuantizeLinear_186_quantize_scale_node with Conv_188
[08/25/2021-17:30:07] [V] [TRT] ConstWeightsFusion: Fusing layer2.3.conv1.weight + QuantizeLinear_217_quantize_scale_node with Conv_219
[08/25/2021-17:30:07] [V] [TRT] ConstWeightsFusion: Fusing layer3.0.conv1.weight + QuantizeLinear_248_quantize_scale_node with Conv_250
[08/25/2021-17:30:07] [V] [TRT] ConstWeightsFusion: Fusing layer3.0.downsample.0.weight + QuantizeLinear_271_quantize_scale_node with Conv_273
[08/25/2021-17:30:07] [V] [TRT] ConstWeightsFusion: Fusing layer3.1.conv1.weight + QuantizeLinear_290_quantize_scale_node with Conv_292
[08/25/2021-17:30:07] [V] [TRT] ConstWeightsFusion: Fusing layer3.2.conv1.weight + QuantizeLinear_321_quantize_scale_node with Conv_323
[08/25/2021-17:30:07] [V] [TRT] ConstWeightsFusion: Fusing layer3.3.conv1.weight + QuantizeLinear_352_quantize_scale_node with Conv_354
[08/25/2021-17:30:07] [V] [TRT] ConstWeightsFusion: Fusing layer3.4.conv1.weight + QuantizeLinear_383_quantize_scale_node with Conv_385
[08/25/2021-17:30:07] [V] [TRT] ConstWeightsFusion: Fusing layer3.5.conv1.weight + QuantizeLinear_414_quantize_scale_node with Conv_416
[08/25/2021-17:30:07] [V] [TRT] ConstWeightsFusion: Fusing layer4.0.conv1.weight + QuantizeLinear_445_quantize_scale_node with Conv_447
[08/25/2021-17:30:07] [V] [TRT] ConstWeightsFusion: Fusing layer4.0.downsample.0.weight + QuantizeLinear_468_quantize_scale_node with Conv_470
[08/25/2021-17:30:07] [V] [TRT] ConstWeightsFusion: Fusing layer4.1.conv1.weight + QuantizeLinear_487_quantize_scale_node with Conv_489
[08/25/2021-17:30:07] [V] [TRT] ConstWeightsFusion: Fusing layer4.2.conv1.weight + QuantizeLinear_518_quantize_scale_node with Conv_520
[08/25/2021-17:30:07] [V] [TRT] ConstWeightsFusion: Fusing deconv_layers.0.weight + QuantizeLinear_549_quantize_scale_node with ConvTranspose_551
[08/25/2021-17:30:07] [V] [TRT] ConstWeightsFusion: Fusing deconv_layers.1.weight + QuantizeLinear_559_quantize_scale_node with Conv_561
[08/25/2021-17:30:07] [V] [TRT] ConstWeightsFusion: Fusing deconv_layers.4.weight + QuantizeLinear_571_quantize_scale_node with ConvTranspose_573
[08/25/2021-17:30:07] [V] [TRT] ConstWeightsFusion: Fusing deconv_layers.5.weight + QuantizeLinear_581_quantize_scale_node with Conv_583
[08/25/2021-17:30:07] [V] [TRT] ConstWeightsFusion: Fusing deconv_layers.8.weight + QuantizeLinear_593_quantize_scale_node with ConvTranspose_595
[08/25/2021-17:30:07] [V] [TRT] ConstWeightsFusion: Fusing deconv_layers.9.weight + QuantizeLinear_603_quantize_scale_node with Conv_605
[08/25/2021-17:30:07] [V] [TRT] ConstWeightsFusion: Fusing hm.0.weight + QuantizeLinear_615_quantize_scale_node with Conv_617 + Relu_618
[08/25/2021-17:30:07] [V] [TRT] ConstWeightsFusion: Fusing hm.2.weight + QuantizeLinear_626_quantize_scale_node with Conv_628
[08/25/2021-17:30:07] [V] [TRT] ConstWeightsFusion: Fusing wh.0.weight + QuantizeLinear_636_quantize_scale_node with Conv_638 + Relu_639
[08/25/2021-17:30:07] [V] [TRT] ConstWeightsFusion: Fusing wh.2.weight + QuantizeLinear_647_quantize_scale_node with Conv_649
[08/25/2021-17:30:07] [V] [TRT] ConstWeightsFusion: Fusing reg.0.weight + QuantizeLinear_657_quantize_scale_node with Conv_659 + Relu_660
[08/25/2021-17:30:07] [V] [TRT] ConstWeightsFusion: Fusing reg.2.weight + QuantizeLinear_668_quantize_scale_node with Conv_670
[08/25/2021-17:30:07] [V] [TRT] ConvReluFusion: Fusing conv1.weight + QuantizeLinear_7_quantize_scale_node + Conv_9 with Relu_11
[08/25/2021-17:30:07] [V] [TRT] ConvReluFusion: Fusing layer1.0.conv1.weight + QuantizeLinear_20_quantize_scale_node + Conv_22 with Relu_24
[08/25/2021-17:30:07] [V] [TRT] ConvReluFusion: Fusing layer1.1.conv1.weight + QuantizeLinear_51_quantize_scale_node + Conv_53 with Relu_55
[08/25/2021-17:30:07] [V] [TRT] ConvReluFusion: Fusing layer1.2.conv1.weight + QuantizeLinear_82_quantize_scale_node + Conv_84 with Relu_86
[08/25/2021-17:30:07] [V] [TRT] ConvReluFusion: Fusing layer2.0.conv1.weight + QuantizeLinear_113_quantize_scale_node + Conv_115 with Relu_117
[08/25/2021-17:30:07] [V] [TRT] ConvReluFusion: Fusing layer2.1.conv1.weight + QuantizeLinear_155_quantize_scale_node + Conv_157 with Relu_159
[08/25/2021-17:30:07] [V] [TRT] ConvReluFusion: Fusing layer2.2.conv1.weight + QuantizeLinear_186_quantize_scale_node + Conv_188 with Relu_190
[08/25/2021-17:30:07] [V] [TRT] ConvReluFusion: Fusing layer2.3.conv1.weight + QuantizeLinear_217_quantize_scale_node + Conv_219 with Relu_221
[08/25/2021-17:30:07] [V] [TRT] ConvReluFusion: Fusing layer3.0.conv1.weight + QuantizeLinear_248_quantize_scale_node + Conv_250 with Relu_252
[08/25/2021-17:30:07] [V] [TRT] ConvReluFusion: Fusing layer3.1.conv1.weight + QuantizeLinear_290_quantize_scale_node + Conv_292 with Relu_294
[08/25/2021-17:30:07] [V] [TRT] ConvReluFusion: Fusing layer3.2.conv1.weight + QuantizeLinear_321_quantize_scale_node + Conv_323 with Relu_325
[08/25/2021-17:30:07] [V] [TRT] ConvReluFusion: Fusing layer3.3.conv1.weight + QuantizeLinear_352_quantize_scale_node + Conv_354 with Relu_356
[08/25/2021-17:30:07] [V] [TRT] ConvReluFusion: Fusing layer3.4.conv1.weight + QuantizeLinear_383_quantize_scale_node + Conv_385 with Relu_387
[08/25/2021-17:30:07] [V] [TRT] ConvReluFusion: Fusing layer3.5.conv1.weight + QuantizeLinear_414_quantize_scale_node + Conv_416 with Relu_418
[08/25/2021-17:30:07] [V] [TRT] ConvReluFusion: Fusing layer4.0.conv1.weight + QuantizeLinear_445_quantize_scale_node + Conv_447 with Relu_449
[08/25/2021-17:30:07] [V] [TRT] ConvReluFusion: Fusing layer4.1.conv1.weight + QuantizeLinear_487_quantize_scale_node + Conv_489 with Relu_491
[08/25/2021-17:30:07] [V] [TRT] ConvReluFusion: Fusing layer4.2.conv1.weight + QuantizeLinear_518_quantize_scale_node + Conv_520 with Relu_522
[08/25/2021-17:30:08] [V] [TRT] ConvReluFusion: Fusing deconv_layers.1.weight + QuantizeLinear_559_quantize_scale_node + Conv_561 with Relu_563
[08/25/2021-17:30:08] [V] [TRT] ConvReluFusion: Fusing deconv_layers.5.weight + QuantizeLinear_581_quantize_scale_node + Conv_583 with Relu_585
[08/25/2021-17:30:08] [V] [TRT] ConvReluFusion: Fusing deconv_layers.9.weight + QuantizeLinear_603_quantize_scale_node + Conv_605 with Relu_607
还是融合Q或者QD到附近的conv中。
最终模型结构如下,这些信息来自trt的verbose信息,关键词是Engine Layer Information。当然我们也可以使用graphvis将这些模型画出来:
[08/25/2021-17:30:37] [V] [TRT] Engine Layer Information:
Layer(Scale): QuantizeLinear_2_quantize_scale_node, Tactic: 0, input[Float(1,3,-17,-18)] -> 255[Int8(1,3,-17,-18)]
Layer(CaskConvolution): conv1.weight + QuantizeLinear_7_quantize_scale_node + Conv_9 + Relu_11, Tactic: 4438325421691896755, 255[Int8(1,3,-17,-18)] -> 267[Int8(1,64,-40,-44)]
Layer(CudaPooling): MaxPool_12, Tactic: -3, 267[Int8(1,64,-40,-44)] -> Reformatted Output Tensor 0 to MaxPool_12[Int8(1,64,-21,-24)]
Layer(Reformat): Reformatting CopyNode for Output Tensor 0 to MaxPool_12, Tactic: 0, Reformatted Output Tensor 0 to MaxPool_12[Int8(1,64,-21,-24)] -> 270[Int8(1,64,-21,-24)]
Layer(CaskConvolution): layer1.0.conv1.weight + QuantizeLinear_20_quantize_scale_node + Conv_22 + Relu_24, Tactic: 4871133328510103657, 270[Int8(1,64,-21,-24)] -> 284[Int8(1,64,-21,-24)]
Layer(CaskConvolution): layer1.0.conv2.weight + QuantizeLinear_32_quantize_scale_node + Conv_34 + Add_42 + Relu_43, Tactic: 4871133328510103657, 284[Int8(1,64,-21,-24)], 270[Int8(1,64,-21,-24)] -> 305[Int8(1,64,-21,-24)]
Layer(CaskConvolution): layer1.1.conv1.weight + QuantizeLinear_51_quantize_scale_node + Conv_53 + Relu_55, Tactic: 4871133328510103657, 305[Int8(1,64,-21,-24)] -> 319[Int8(1,64,-21,-24)]
Layer(CaskConvolution): layer1.1.conv2.weight + QuantizeLinear_63_quantize_scale_node + Conv_65 + Add_73 + Relu_74, Tactic: 4871133328510103657, 319[Int8(1,64,-21,-24)], 305[Int8(1,64,-21,-24)] -> 340[Int8(1,64,-21,-24)]
Layer(CaskConvolution): layer1.2.conv1.weight + QuantizeLinear_82_quantize_scale_node + Conv_84 + Relu_86, Tactic: 4871133328510103657, 340[Int8(1,64,-21,-24)] -> 354[Int8(1,64,-21,-24)]
Layer(CaskConvolution): layer1.2.conv2.weight + QuantizeLinear_94_quantize_scale_node + Conv_96 + Add_104 + Relu_105, Tactic: 4871133328510103657, 354[Int8(1,64,-21,-24)], 340[Int8(1,64,-21,-24)] -> 375[Int8(1,64,-21,-24)]
Layer(CaskConvolution): layer2.0.conv1.weight + QuantizeLinear_113_quantize_scale_node + Conv_115 + Relu_117, Tactic: -1841683966837205309, 375[Int8(1,64,-21,-24)] -> 389[Int8(1,128,-52,-37)]
Layer(CaskConvolution): layer2.0.downsample.0.weight + QuantizeLinear_136_quantize_scale_node + Conv_138, Tactic: -1494157908358500249, 375[Int8(1,64,-21,-24)] -> 415[Int8(1,128,-52,-37)]
Layer(CaskConvolution): layer2.0.conv2.weight + QuantizeLinear_125_quantize_scale_node + Conv_127 + Add_146 + Relu_147, Tactic: -1841683966837205309, 389[Int8(1,128,-52,-37)], 415[Int8(1,128,-52,-37)] -> 423[Int8(1,128,-52,-37)]
Layer(CaskConvolution): layer2.1.conv1.weight + QuantizeLinear_155_quantize_scale_node + Conv_157 + Relu_159, Tactic: -1841683966837205309, 423[Int8(1,128,-52,-37)] -> 437[Int8(1,128,-52,-37)]
Layer(CaskConvolution): layer2.1.conv2.weight + QuantizeLinear_167_quantize_scale_node + Conv_169 + Add_177 + Relu_178, Tactic: -1841683966837205309, 437[Int8(1,128,-52,-37)], 423[Int8(1,128,-52,-37)] -> 458[Int8(1,128,-52,-37)]
Layer(CaskConvolution): layer2.2.conv1.weight + QuantizeLinear_186_quantize_scale_node + Conv_188 + Relu_190, Tactic: -1841683966837205309, 458[Int8(1,128,-52,-37)] -> 472[Int8(1,128,-52,-37)]
Layer(CaskConvolution): layer2.2.conv2.weight + QuantizeLinear_198_quantize_scale_node + Conv_200 + Add_208 + Relu_209, Tactic: -1841683966837205309, 472[Int8(1,128,-52,-37)], 458[Int8(1,128,-52,-37)] -> 493[Int8(1,128,-52,-37)]
Layer(CaskConvolution): layer2.3.conv1.weight + QuantizeLinear_217_quantize_scale_node + Conv_219 + Relu_221, Tactic: -1841683966837205309, 493[Int8(1,128,-52,-37)] -> 507[Int8(1,128,-52,-37)]
Layer(CaskConvolution): layer2.3.conv2.weight + QuantizeLinear_229_quantize_scale_node + Conv_231 + Add_239 + Relu_240, Tactic: -1841683966837205309, 507[Int8(1,128,-52,-37)], 493[Int8(1,128,-52,-37)] -> 528[Int8(1,128,-52,-37)]
Layer(CaskConvolution): layer3.0.conv1.weight + QuantizeLinear_248_quantize_scale_node + Conv_250 + Relu_252, Tactic: -8431788508843860955, 528[Int8(1,128,-52,-37)] -> 542[Int8(1,256,-59,-62)]
Layer(CaskConvolution): layer3.0.downsample.0.weight + QuantizeLinear_271_quantize_scale_node + Conv_273, Tactic: -5697614955743334137, 528[Int8(1,128,-52,-37)] -> 568[Int8(1,256,-59,-62)]
Layer(CaskConvolution): layer3.0.conv2.weight + QuantizeLinear_260_quantize_scale_node + Conv_262 + Add_281 + Relu_282, Tactic: -496455309852654971, 542[Int8(1,256,-59,-62)], 568[Int8(1,256,-59,-62)] -> 576[Int8(1,256,-59,-62)]
Layer(CaskConvolution): layer3.1.conv1.weight + QuantizeLinear_290_quantize_scale_node + Conv_292 + Relu_294, Tactic: -8431788508843860955, 576[Int8(1,256,-59,-62)] -> 590[Int8(1,256,-59,-62)]
Layer(CaskConvolution): layer3.1.conv2.weight + QuantizeLinear_302_quantize_scale_node + Conv_304 + Add_312 + Relu_313, Tactic: -496455309852654971, 590[Int8(1,256,-59,-62)], 576[Int8(1,256,-59,-62)] -> 611[Int8(1,256,-59,-62)]
Layer(CaskConvolution): layer3.2.conv1.weight + QuantizeLinear_321_quantize_scale_node + Conv_323 + Relu_325, Tactic: -8431788508843860955, 611[Int8(1,256,-59,-62)] -> 625[Int8(1,256,-59,-62)]
Layer(CaskConvolution): layer3.2.conv2.weight + QuantizeLinear_333_quantize_scale_node + Conv_335 + Add_343 + Relu_344, Tactic: -496455309852654971, 625[Int8(1,256,-59,-62)], 611[Int8(1,256,-59,-62)] -> 646[Int8(1,256,-59,-62)]
Layer(CaskConvolution): layer3.3.conv1.weight + QuantizeLinear_352_quantize_scale_node + Conv_354 + Relu_356, Tactic: -8431788508843860955, 646[Int8(1,256,-59,-62)] -> 660[Int8(1,256,-59,-62)]
Layer(CaskConvolution): layer3.3.conv2.weight + QuantizeLinear_364_quantize_scale_node + Conv_366 + Add_374 + Relu_375, Tactic: -496455309852654971, 660[Int8(1,256,-59,-62)], 646[Int8(1,256,-59,-62)] -> 681[Int8(1,256,-59,-62)]
Layer(CaskConvolution): layer3.4.conv1.weight + QuantizeLinear_383_quantize_scale_node + Conv_385 + Relu_387, Tactic: -8431788508843860955, 681[Int8(1,256,-59,-62)] -> 695[Int8(1,256,-59,-62)]
Layer(CaskConvolution): layer3.4.conv2.weight + QuantizeLinear_395_quantize_scale_node + Conv_397 + Add_405 + Relu_406, Tactic: -496455309852654971, 695[Int8(1,256,-59,-62)], 681[Int8(1,256,-59,-62)] -> 716[Int8(1,256,-59,-62)]
Layer(CaskConvolution): layer3.5.conv1.weight + QuantizeLinear_414_quantize_scale_node + Conv_416 + Relu_418, Tactic: -8431788508843860955, 716[Int8(1,256,-59,-62)] -> 730[Int8(1,256,-59,-62)]
Layer(CaskConvolution): layer3.5.conv2.weight + QuantizeLinear_426_quantize_scale_node + Conv_428 + Add_436 + Relu_437, Tactic: -496455309852654971, 730[Int8(1,256,-59,-62)], 716[Int8(1,256,-59,-62)] -> 751[Int8(1,256,-59,-62)]
Layer(CaskConvolution): layer4.0.conv1.weight + QuantizeLinear_445_quantize_scale_node + Conv_447 + Relu_449, Tactic: -6371781333659293809, 751[Int8(1,256,-59,-62)] -> 765[Int8(1,512,-71,-72)]
Layer(CaskConvolution): layer4.0.downsample.0.weight + QuantizeLinear_468_quantize_scale_node + Conv_470, Tactic: -1494157908358500249, 751[Int8(1,256,-59,-62)] -> 791[Int8(1,512,-71,-72)]
Layer(CaskConvolution): layer4.0.conv2.weight + QuantizeLinear_457_quantize_scale_node + Conv_459 + Add_478 + Relu_479, Tactic: -2328318099174473157, 765[Int8(1,512,-71,-72)], 791[Int8(1,512,-71,-72)] -> 799[Int8(1,512,-71,-72)]
Layer(CaskConvolution): layer4.1.conv1.weight + QuantizeLinear_487_quantize_scale_node + Conv_489 + Relu_491, Tactic: -2328318099174473157, 799[Int8(1,512,-71,-72)] -> 813[Int8(1,512,-71,-72)]
Layer(CaskConvolution): layer4.1.conv2.weight + QuantizeLinear_499_quantize_scale_node + Conv_501 + Add_509 + Relu_510, Tactic: -2328318099174473157, 813[Int8(1,512,-71,-72)], 799[Int8(1,512,-71,-72)] -> 834[Int8(1,512,-71,-72)]
Layer(CaskConvolution): layer4.2.conv1.weight + QuantizeLinear_518_quantize_scale_node + Conv_520 + Relu_522, Tactic: -2328318099174473157, 834[Int8(1,512,-71,-72)] -> 848[Int8(1,512,-71,-72)]
Layer(CaskConvolution): layer4.2.conv2.weight + QuantizeLinear_530_quantize_scale_node + Conv_532 + Add_540 + Relu_541, Tactic: -2328318099174473157, 848[Int8(1,512,-71,-72)], 834[Int8(1,512,-71,-72)] -> 869[Int8(1,512,-71,-72)]
Layer(CaskDeconvolution): deconv_layers.0.weight + QuantizeLinear_549_quantize_scale_node + ConvTranspose_551, Tactic: -3784829056659735491, 869[Int8(1,512,-71,-72)] -> 881[Int8(1,512,-46,-47)]
Layer(CaskConvolution): deconv_layers.1.weight + QuantizeLinear_559_quantize_scale_node + Conv_561 + Relu_563, Tactic: -496455309852654971, 881[Int8(1,512,-46,-47)] -> 895[Int8(1,256,-46,-47)]
Layer(CaskDeconvolution): deconv_layers.4.weight + QuantizeLinear_571_quantize_scale_node + ConvTranspose_573, Tactic: -3784829056659735491, 895[Int8(1,256,-46,-47)] -> 907[Int8(1,256,-68,-55)]
Layer(CaskConvolution): deconv_layers.5.weight + QuantizeLinear_581_quantize_scale_node + Conv_583 + Relu_585, Tactic: -8431788508843860955, 907[Int8(1,256,-68,-55)] -> 921[Int8(1,256,-68,-55)]
Layer(CaskDeconvolution): deconv_layers.8.weight + QuantizeLinear_593_quantize_scale_node + ConvTranspose_595, Tactic: -2621193268472024213, 921[Int8(1,256,-68,-55)] -> 933[Int8(1,256,-29,-32)]
Layer(CaskConvolution): deconv_layers.9.weight + QuantizeLinear_603_quantize_scale_node + Conv_605 + Relu_607, Tactic: -8431788508843860955, 933[Int8(1,256,-29,-32)] -> 947[Int8(1,256,-29,-32)]
Layer(CaskConvolution): hm.0.weight + QuantizeLinear_615_quantize_scale_node + Conv_617 + Relu_618, Tactic: 4871133328510103657, 947[Int8(1,256,-29,-32)] -> 960[Int8(1,64,-29,-32)]
Layer(CaskConvolution): wh.0.weight + QuantizeLinear_636_quantize_scale_node + Conv_638 + Relu_639, Tactic: 4871133328510103657, 947[Int8(1,256,-29,-32)] -> 985[Int8(1,64,-29,-32)]
Layer(CaskConvolution): reg.0.weight + QuantizeLinear_657_quantize_scale_node + Conv_659 + Relu_660, Tactic: 4871133328510103657, 947[Int8(1,256,-29,-32)] -> 1010[Int8(1,64,-29,-32)]
Layer(CaskConvolution): hm.2.weight + QuantizeLinear_626_quantize_scale_node + Conv_628, Tactic: -7185527339793611699, 960[Int8(1,64,-29,-32)] -> Reformatted Output Tensor 0 to hm.2.weight + QuantizeLinear_626_quantize_scale_node + Conv_628[Float(1,2,-29,-32)]
Layer(Reformat): Reformatting CopyNode for Output Tensor 0 to hm.2.weight + QuantizeLinear_626_quantize_scale_node + Conv_628, Tactic: 0, Reformatted Output Tensor 0 to hm.2.weight + QuantizeLinear_626_quantize_scale_node + Conv_628[Float(1,2,-29,-32)] -> hm[Float(1,2,-29,-32)]
Layer(CaskConvolution): wh.2.weight + QuantizeLinear_647_quantize_scale_node + Conv_649, Tactic: -7185527339793611699, 985[Int8(1,64,-29,-32)] -> Reformatted Output Tensor 0 to wh.2.weight + QuantizeLinear_647_quantize_scale_node + Conv_649[Float(1,2,-29,-32)]
Layer(Reformat): Reformatting CopyNode for Output Tensor 0 to wh.2.weight + QuantizeLinear_647_quantize_scale_node + Conv_649, Tactic: 0, Reformatted Output Tensor 0 to wh.2.weight + QuantizeLinear_647_quantize_scale_node + Conv_649[Float(1,2,-29,-32)] -> wh[Float(1,2,-29,-32)]
Layer(CaskConvolution): reg.2.weight + QuantizeLinear_668_quantize_scale_node + Conv_670, Tactic: -7185527339793611699, 1010[Int8(1,64,-29,-32)] -> Reformatted Output Tensor 0 to reg.2.weight + QuantizeLinear_668_quantize_scale_node + Conv_670[Float(1,2,-29,-32)]
Layer(Reformat): Reformatting CopyNode for Output Tensor 0 to reg.2.weight + QuantizeLinear_668_quantize_scale_node + Conv_670, Tactic: 0, Reformatted Output Tensor 0 to reg.2.weight + QuantizeLinear_668_quantize_scale_node + Conv_670[Float(1,2,-29,-32)] -> reg[Float(1,2,-29,-32)]
[08/25/2021-17:30:37] [I] [TRT] [MemUsageSnapshot] Builder end: CPU 1396 MiB, GPU 726 MiB
简单总结一下大家拿到模型想要在TensorRT量化部署的一般步骤吧:
大部分模型来说,PTQ工具就够用了,准备好校准数据集,直接使用trt提供的接口进行PTQ量化(少量代码)或者使用python-API接口进行PTQ量化
如果trt提供的PTQ集中量化方法对你的模型效果不好,可以考虑使用自己的量化方式导出带有量化信息的模型让trt去加载(需要写一些代码,可以通过训练框架比如pytorch导出已经量化好的模型让trt加载),带有量化信息的模型就是上文提到的QDQ的ONNX模型
简单记录了一下TensorRT量化过程中的一些问题,其实大部分问题大家可以在官方issue中搜到,关键词int8或者quan。这里仅是记录了一些我遇到的。
如果使用TensorRT提供的Pytorch量化库,需要修改resnet50的网络结构代码,参考 https://docs.nvidia.com/deeplearning/tensorrt/pytorch-quantization-toolkit/docs/tutorials/quant_resnet50.html:
def __init__(self,
inplanes: int,
planes: int,
stride: int = 1,
downsample: Optional[nn.Module] = None,
groups: int = 1,
base_width: int = 64,
dilation: int = 1,
norm_layer: Optional[Callable[..., nn.Module]] = None,
quantize: bool = False) -> None:
# other code...
self._quantize = quantize
if self._quantize:
self.residual_quantizer = quant_nn.TensorQuantizer(quant_nn.QuantConv2d.default_quant_desc_input)
def forward(self, x: Tensor) -> Tensor:
# other code...
if self._quantize:
out += self.residual_quantizer(identity)
else:
out += identity
out = self.relu(out)
return out
QDQ结构中如果RELU后面有QDQ则会报错(升级到TensorRT-8.2可以解决这个问题)
 QDQ结构中如果RELU后面有QDQ则会报错
QDQ结构中如果RELU后面有QDQ则会报错[TensorRT] ERROR: 2: [graphOptimizer.cpp::sameExprValues::587] Error Code 2: Internal Error (Assertion lhs.expr failed.)
Traceback (most recent call last):
File "yolov3_trt.py", line 678, in <module>
test()
File "yolov3_trt.py", line 660, in test
create_engine(engine_file, 'int8', qat=True)
File "yolov3_trt.py", line 601, in create_engine
ctx.build_engine(engine_file)
关于Deconvolution,量化INT8中反卷积的权重OIHW中I和O的通道必须大于1
[optimizer.cpp::computeCosts::1981] Error Code 10: Internal Error (Could not find any implementation for node quantize_per_channel_110_input + [QUANTIZE]-[acc_ops.quantize_per_channel]-[(Unnamed Layer* 647) [Constant]_output_per_channel_quant] + [DECONVOLUTION]-[acc_ops.conv_transpose2d]-[conv_transpose2d_9].)
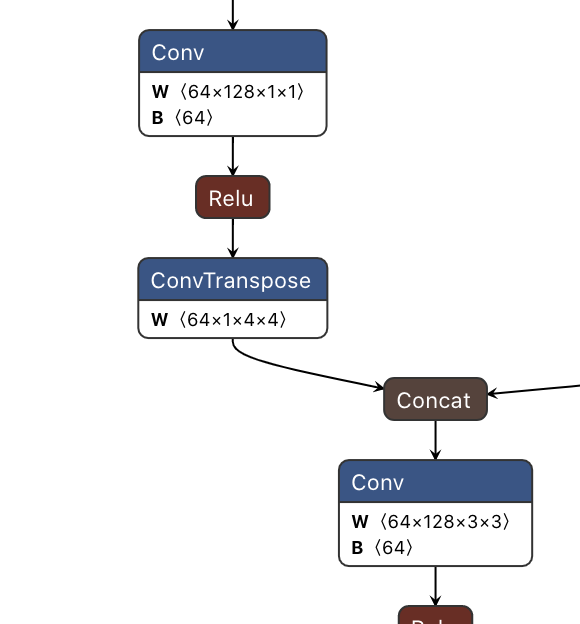 这种反卷积结构量化会报错
这种反卷积结构量化会报错还有个问题,deconv输入通道和输出通道如果不一致在TensorRT8.2EA之前会报错:
然后如果ConvTranspose的输入channel和输出channel如果有某种关系,也会报错:
issue查了下,遇到相同问题的人还挺多:
https://github.com/NVIDIA/TensorRT/issues/1556
https://github.com/NVIDIA/TensorRT/issues/1519
目前来看还是无法解决的:
thanks for update, we will check, and the c%4 will not work for ConvTranspose , it is for depthConv.
部分量化结果会错误解析 tactic : ampere_scudnn_128x64_relu_interior_nn_v1
这篇文章整理了好些天,总算是搞完了,其实去年10月份的时候已经打好了草稿,但是一拖再拖就到现在了hh。

除了TensorRT,也用过一些其他的框架,不管是PPL还是TVM,发现INT8的性能在我的模型上还是不如TensorRT,或者一些case上没有TensorRT支持全。但TensorRT比较麻烦的是INT8的plugin不好debug,坑比较多。
最近一段时间在使用TVM做一些INT8的优化,准备把torch.fx的已经PTQ后的模型搞到TVM上进行量化加速,之后也会写一些相关的文章。
近期也在迁移自己的笔记(或者说草稿吧)到github.io上,用MKDocs做成了网页,其中的文章会随时更新,放个链接:
https://ai.oldpan.me/
和博客不同,这里分类更加规整一些,重点是依旧AI部署加速优化这块,现在可能比较乱,因为在随时更新,近期也会找个时间整理一下。一些新的文章会先发在这里,大家闲来无事可以翻翻看。
量化这块的文章会继续写,鸽了这么久了,之后的发文频率也会上来。感谢大家的支持~
https://zhuanlan.zhihu.com/p/451105341
https://github.com/NVIDIA/TensorRT/issues/1552
https://github.com/NVIDIA/TensorRT/issues/1165
[1]
量化框架: https://zhuanlan.zhihu.com/p/355598250
[2]工具: https://github.com/NVIDIA/TensorRT/tree/main/tools/pytorch-quantization








