绑定手机号
确认绑定









拍照时,我们可能辛辛苦苦地找了个角度,却忘记了调整光线,拍出了黑乎乎的照片:

这种情况下,最常见的补救方法是P图。打开PhotoShop,按下"ctrl+m",就能够打开调整图像亮度的界面:
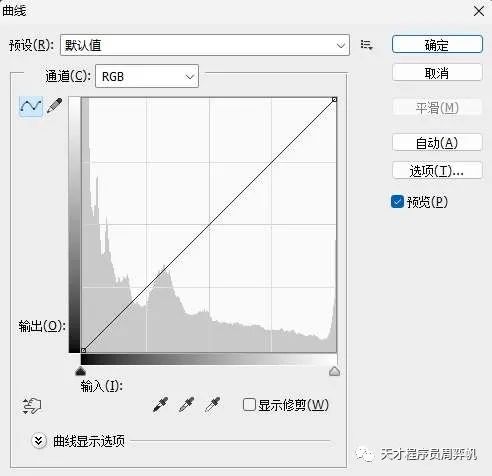
这个界面中间灰色的区域表示图像的亮度分布。坐标轴横轴表示亮度,纵轴表示对应亮度的像素的数量。可以看出,整幅图片非常暗,亮度低的像素占了大多数。
为了提亮图片,我们可以调整中间那条曲线。这条曲线表示如何把某一种亮度映射到另一种亮度上。初始情况下,曲线是,也就是不改变原图片的亮度。由于低亮度的像素占比较多,我打算构造一个对低亮度像素进行较大增强,而尽可能保持高亮度像素的曲线。其运行结果如下:
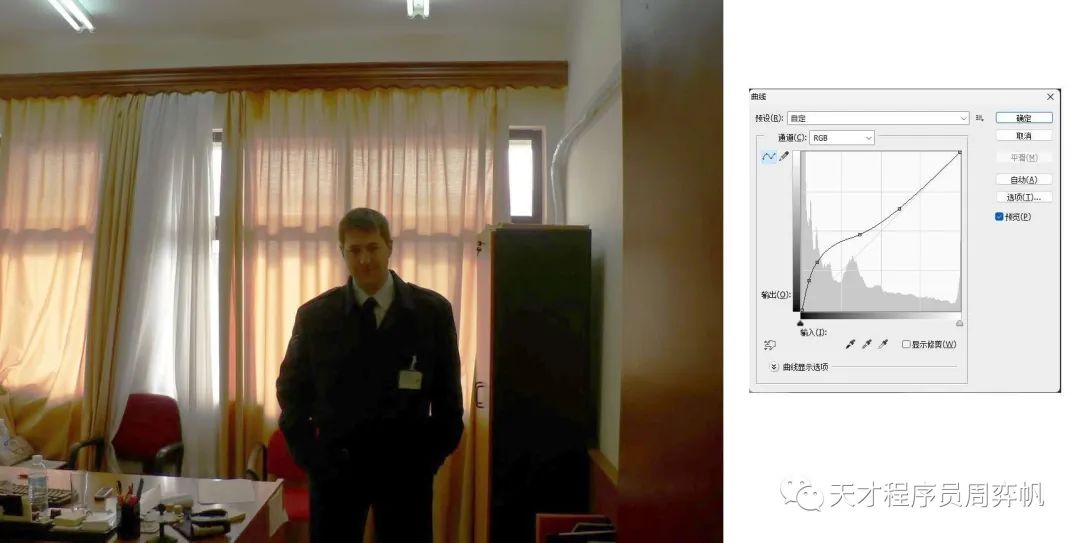
嗯,不错。看起来图像确实变亮了不少。但感觉图片看上去还不够自然。有没有一种自动帮我们提亮图像的工具呢?
Zero-DCE就是一个利用深度学习自动调亮图片的算法。让我们看看它的运行结果:

哇!这也太强了。除了效果好之外,Zero-DCE还有许多亮点:
不需要带标注的数据,甚至不需要参考数据(这里的参考数据指一张暗图对应的亮图)!
训练数据少,训练时间短,只需约30分钟。
推理速度极快。在手机上也能实时运行。
让我们来读一下Zero-DCE的论文,看看这个算法是怎么实现的。看完论文后,我还会解读一下官方的PyTorch代码实现。
核心思想
自从CNN(卷积神经网络)火了以后,很多图像问题都可以用CNN来解决:把图像输入进CNN,乱卷一通,最后根据任务的需要,输出分类的概率(图像分类)、检测框和类别(目标检测)或另一幅图像(超分辨率)。
同时,对于输出也是一幅图像的问题,人们会利用GAN(生成对抗网络)能生成图像的特性,尝试用GAN来解决问题。比如在超分辨率任务中,GAN就得到了广泛的使用。
而图像提亮问题恰好就是一个输入、输出都是图像的问题。在此之前,既有基于CNN的方法,也有基于GAN的方法。人们尝试构造更精巧的网络,希望网络能输出亮度更合适的图像。
可是,Zero-DCE别出心裁,返璞归真地用了一种更简单的方式来生成亮度更合适的图像。还记得本文开头提到的,PhotoShop里的那个亮度映射曲线吗?实际上,我们只需要一条简简单单的曲线,把不同亮度的像素映射到一个新的亮度上,就足以产生亮度恰好合适的图像了。Zero-DCE就是用神经网络来拟合一条亮度映射曲线,再根据曲线和原图像生成提亮图像。整个计算过程是可导的,可以轻松地用梯度下降法优化神经网络。
另外,与其他一些任务不同,「亮度」是一个很贴近数学的属性。对于物品的种类、文字的意思这种抽象信息,我们很难用数字来表达。而亮度用一个数字来表示就行了。因此,在图像提亮问题中,我们不一定需要带标签的训练数据,而是可以根据图像本身的某些性质,自动判断出一幅图像是不是“亮度合理”的。
为了让计算机自动判断生成图像的亮度、与原图像的相似度等和图像质量相关的属性,Zero-DCE在训练中使用了一些新颖的误差函数。通过用这些误差函数约束优化过程,算法既能保证生成出来的图片亮度合理,又能保证图片较为真实、贴近原图像。
拟合亮度映射的曲线、不需要标签的误差函数,这两项精巧的设计共同决定了Zero-DCE算法的优势。原论文总结了该工作的三条贡献:
这是第一个不需要参考结果的低光照增强网络,直接避免了统计学习中的过拟合问题。算法能够适应不同光照条件下的图片。
该工作设计了一种随输入图像而变的映射曲线。该曲线是高阶的。每个像素有一条单独的曲线。曲线能高效地完成映射过程。
本作的方法表明,在缺乏参考图像时,可以设计一个与任务相关而与参考图像无关的误差,以完成深度图像增强模型的训练。
除了学术上的贡献外,算法也十分易用。算法的提亮效果优于其他方法,训练速度和推理速度更是冠绝一方。
接下来,让我们详细探究一下亮度映射曲线、误差函数这两大亮点究竟是怎么设计的。
提亮曲线
本文使用的亮度映射曲线被称作提亮曲线(Light-Enhancement Curve, LE-curve)。设计该曲线时,应满足几个原则:
由于亮度值落在区间,为保证亮度值的值域不变,曲线在0处值要为0,在1处值要为1。
曲线必须是单调递增的。不然可能会出现图像中原本较亮的地方反而变暗。
曲线公式必须简单,以保证可导。
因此,本作使用了如下的公式描述曲线:
其中,是像素坐标,是可学习参数,是输入的增强图像(三个颜色通道分别处理)。这个函数非常巧妙,大家可以验证一下它是不是满足刚刚那三条原则。
是公式里唯一一个可变参数。我们来看看不同的能产生怎样的曲线;
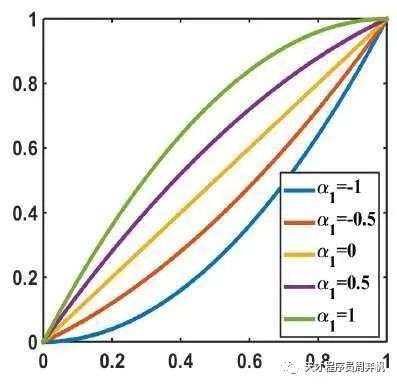
可以看出,虽然能够上下调节曲线,但由于曲线本质上是一个二次函数,曲线的变化还不够丰富。为了拟合更复杂的曲线,本作迭代嵌套了这个函数。也就是说:
一般地,
迭代嵌套开始那个二次函数,就能够表示一个更高次的函数了。每一轮迭代,都有一个新的参数。本作令最大的为8,即调用二次函数8次,拟合某个次函数。
但是,我们不希望每个像素都用同样的提亮函数。比如如果图像中某个地方亮着灯,那么这个地方的像素值就不用改变。因此,每个像素应该有独立的。最终的提亮函数为:
这一改动还是很有必要的。下图显示了某输入图片在不同像素处的的绝对值:

可以看出,在较亮的地方,图像没有变化,几乎为0;而在较暗的地方,的数值也较大。
知道了要拟合的目标曲线的公式,下面我们来看看拟合该曲线的神经网络长什么样。
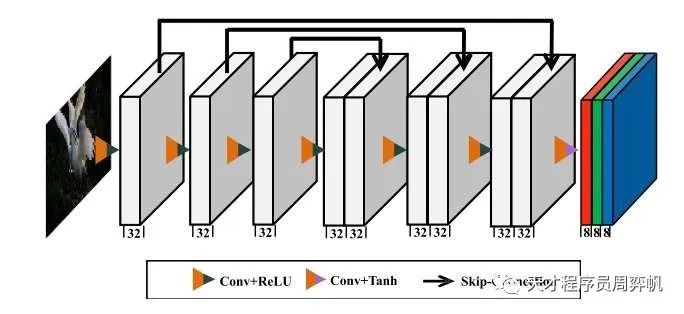
由于要拟合的数据不是很复杂,该作用到的网络DCE-Net非常简单。它一共有7层(6个隐藏层,1个输出层)。所有层都是普通的3x3等长(stride=1)卷积层。为保持相邻像素间的联系,卷积层后不使用Batch Normalization。隐藏层激活函数为ReLU,由于输出落在,输出层的激活函数是tanh。如图所示,6个隐藏层使用了和U-Net类似的对称跳连。3、4层的输出会拼接到一起再送入第5层,2、5层输出拼接送入第6层,1、6层输出拼接送入第7层。经过输出层后,每个像素有24个通道——有RGB 3个颜色通道,每个通道有8个参数。
看完了网络结构与其输出的意义,我们继续看一下误差函数是怎么设置的。
无需参考的误差函数
为了能不使用参考数据,本作精心设计了四个误差函数,以从不同的角度约束增强后的图像。
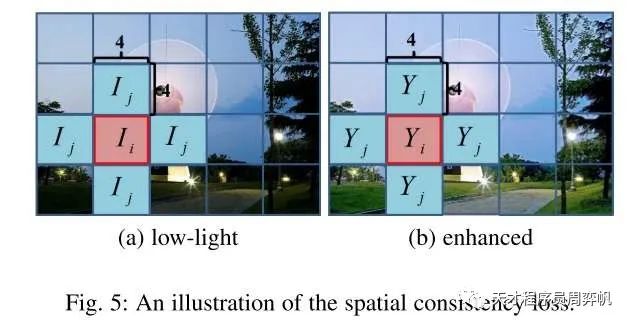
空间一致误差(Spatial Consistency Loss)
图像增强后,我们肯定不希望图像的内容发生改变。更准确一点描述,我们不希望某像素的值和其相邻像素的值的差发生过大的改变。因此,我们可以设置下述误差:
,其中是像素数,是对像素的遍历。是第个像素的4邻域。分别是增强图像和输入图像。
但实际上,我们的要求不必那么苛刻,不用要求每个像素和周围像素的相对值都不改变。在实现中,其实是一个的一个“大像素”区域,每个大像素的值是其中所有像素值的平均值。在实现时,大像素可以通过平均池化来求得。因此,上式中的其实指的是大像素的数量,分别是增强图像和输入图像经池化后得到的图像。
曝光控制误差(Exposure Control Loss)
为了不让某些地方过暗,某些地方过亮,我们可以让极端亮度更少,即让每个像素的亮度更靠近某个中间值。这个约束可以用如下的误差函数表达:
,其中常数描述了亮度的中间值,根据经验可以取0.6。和之前的类似,这里的也是一个大像素区域中亮度的平均值。大像素宽度可调,文中使用的宽度是16。是大像素的总个数。
颜色恒定误差(Color Constancy Loss)
根据前人研究中的某些结论,图像某一颜色通道的数值不应显著超出其他通道。因此,有如下误差:
,这里,遍历了三个颜色通道中所有两两组合,表示颜色通道的亮度平均值。
光照平滑误差(Illumination Smoothness Loss)
为了保持相邻像素的单调关系,即让相邻像素之间的亮度改变不是那么显著,我们需要让相邻像素间的参数更相近一点。这种要求可以这样表示:
,其中,是迭代次数,分别是水平和垂直的梯度算子。对于图像,水平梯度和垂直梯度就是和左方、上方相邻像素之间的数值的差。
总误差
总误差即上述四个误差的加权和:
在开源代码中,上述四个权重分别为
这四个误差中,有几个误差的作用十分重要。大家可以看看去掉某项误差后,网络的复原效果:

去掉后,生成出来的图像勉强还行。剩下的误差,哪怕去掉任何一个,生成图像的效果都会很差劲。
Zero-DCE是发表在CVPR会议上的。之后,Zero-DCE的拓展版Zero-DCE++发到了TPAMI期刊上。期刊版版面足够,原论文中一些来不及讲清的地方(比如空间一致误差)在期刊版中都有更详尽的说明。大家如果想读论文,建议直接读期刊版本的。论文层层递进,逻辑非常清楚,非常适合从头到尾读一遍。
Zero-DCE++在方法上主要是对性能上进行了一些增强,而没有改进原作的核心思想。拓展点有:
和MobileNet类似,把普通卷积替换成更快的逐通道可分卷积(depthwise separable convolution)。
经研究,8次迭代中,每次的参数都差不多。因此,可以让网络只输出3个值,而不是24个值。
由于该任务对图像尺寸不敏感,为了减小卷积开销,可以一开始对图像下采样,最后再上采样回来。
经优化后,参数量减少8倍,运算量在一般大小的图像上减少上百倍,训练只需20分钟。
Zero-DCE是一个简单优美的低光照增强算法。该算法巧妙地建模了光照增强问题,并创造性地使用了和参考数据无关的误差,竟然让基于深度学习的低光照增强算法做到了训练块、性能高、对数据要求低。希望这篇文章用到的思想也能启发其他图像任务。
然而,本文的第一作者在指导我们时说道:“低光图片增强问题要解决两件事:图像去模糊和亮度增强。而Zero-DCE只能完成后者。同时,低光图片的特例也非常多。现在想做一个低光照增强的商业应用是很困难的。”是啊,想让低光照增强落地,用手机瞬间点亮拍暗了的照片,任重而道远啊。
代码可以在 https://github.com/Li-Chongyi/Zero-DCE 里找到。
由于算法没那么复杂,实现所需的代码并不多。同时,这份代码也写得比较工整清楚。整份代码读起来还是非常轻松的。
安装与使用
直接clone仓库:
git clone git@github.com:Li-Chongyi/Zero-DCE.git
之后,切到内侧的文件夹:
cd Zero-DCE/Zero-DCE_code
直接运行脚本就行了:
python lowlight_test.py
注意!!这份代码对Windows不太友好,有一处路径操作写得不好。在lowlight_test.py这份文件中,有一坨完成os.makedirs()的代码,建议改成:
dir, fn = os.path.split(result_path)
if not os.path.exists(dir):
os.makedirs(dir)
同时,代码用VSCode打开后编辑,会出现莫名其妙的缩进不对齐问题。建议拿个格式化工具修一下。为了编辑这份代码,我不得不把所有缩进重新调了一遍。
这是我跑的一个结果,效果很不错:

代码选读
代码实现中有一些可以讲一讲的地方。
看一下神经网络的实现:
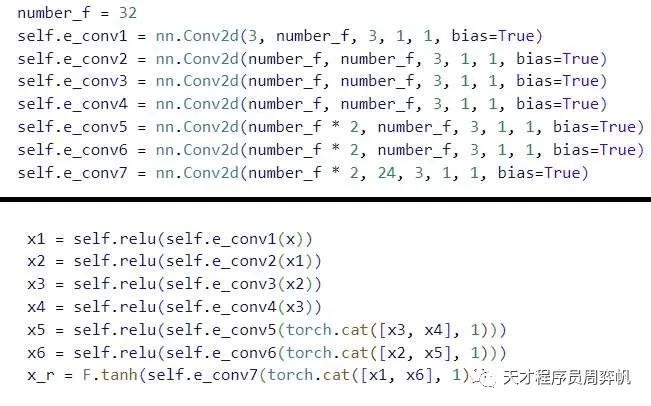
整个神经网络部分还是很简明的。
那个求第一个误差空间一致误差L_spa的代码是很炫酷的。让我们忽略掉那个合成大像素的操作,直接看一下这里和相邻像素的差是怎么实现的。
首先,这里定义了一堆“参数”。

之后,这些参数被扔进了卷积里,用来卷原图像和增强图像。这是在干什么呢?

原来啊,在深度学习时代之前,卷积本来就是图像处理里的一个普普通通的操作。开始那张图定义的不是参数,而是3x3常量卷积核。用那几个卷积核卷积图像,可以得到图像和上下左右之间的差。
这种写法很帅,但是增加了很多计算量。文件里有很多没删干净的代码,不知道是不是本来还有其他设计。
在第四个误差L_TV里,也有一个要算和相邻像素之间的差的梯度计算。这份实现就写得老实多了。
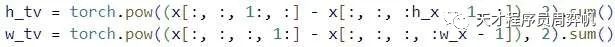
这份代码中就是这里有一点难看懂,其他地方都是非常基础的PyTorch调用,非常适合初学者用来学习PyTorch。








